
10 Photos and videos








Pinned Tweet

29 Jul 2025
Excited to share Flow Matching Policy Gradients: expressive RL policies trained from rewards using flow matching. It’s an easy, drop-in replacement for Gaussian PPO on control tasks.
8
204
1,219
150,466
David McAllister retweeted

Jun 11
💥Introducing FACTR 2, learning external force sensing on commodity robot arms without needing dedicated sensors.
We show that learned force signals enable force-feedback teleop on low-cost arms and improve BC policies.
FACTR 2 consists of:
1. Neural External Torque (NEXT): learns external forces without needing dedicated force sensors.
2. Force-Informed Re-Sampling Training (FIRST): uses the learned force signal to identify task-critical regions and upsample them during training.
w/ @StevenOh_ @_tonytao_
🧵(1/N)
16
61
269
97,163
Apr 17
We developed a simple, sample-efficient online RL technique for post-training image generation models. We see it as a possible steerable alternative to CFG, driven by any scalar reward, including human preference.
11
42
376
63,610
Apr 17
Check out our blog post at mcallisterdavid.com/fdfo-blo… for a walkthrough of our design decisions.
w/ fantastic collaborators: Miika Aittala, Tero Karras, Janne Hellsten, @akanazawa Timo Aila and Samuli Laine
2
24
2,521
David McAllister retweeted

Apr 7
Our new work, STITCH 2.0, can perform consecutive running sutures to close a sample wound with the daVinci robot.
8
15
59
26,513
David McAllister retweeted

Mar 9
𝗢𝗻𝗲 𝗺𝗲𝗺𝗼𝗿𝘆 𝗰𝗮𝗻’𝘁 𝗿𝘂𝗹𝗲 𝘁𝗵𝗲𝗺 𝗮𝗹𝗹.
We present 𝗟𝗼𝗚𝗲𝗥, a new 𝗵𝘆𝗯𝗿𝗶𝗱 𝗺𝗲𝗺𝗼𝗿𝘆 architecture for long-context geometric reconstruction.
LoGeR enables stable reconstruction over up to 𝟭𝟬𝗸 𝗳𝗿𝗮𝗺𝗲𝘀 / 𝗸𝗶𝗹𝗼𝗺𝗲𝘁𝗲𝗿 𝘀𝗰𝗮𝗹𝗲, with 𝗹𝗶𝗻𝗲𝗮𝗿-𝘁𝗶𝗺𝗲 𝘀𝗰𝗮𝗹𝗶𝗻𝗴 in sequence length, 𝗳𝘂𝗹𝗹𝘆 𝗳𝗲𝗲𝗱𝗳𝗼𝗿𝘄𝗮𝗿𝗱 inference, and 𝗻𝗼 𝗽𝗼𝘀𝘁-𝗼𝗽𝘁𝗶𝗺𝗶𝘇𝗮𝘁𝗶𝗼𝗻.
Yet it matches or surpasses strong optimization-based pipelines. (1/5)
@GoogleDeepMind @Berkeley_AI
64
446
3,399
560,327
David McAllister retweeted

Feb 25
@brenthyi who worked on FPO/FPO is finishing his PhD and going on the job market 😭✨
He is also the person behind viser, pyroki, egoallo, jaxls, tyro and more!
I can't express how amazing it is to have Brent on your team..! Any team would be incredibly lucky to have him!!
Feb 13

FPO ! We got RL on flow policies working on real robot tasks.
Sim2real on humanoids trained from scratch manipulation finetuning in sim with action chunking.
Excited about this direction because we can now use RL with expressive policies to discover new behaviors!
2
13
107
10,595
David McAllister retweeted

Feb 9
We trained diffusion models on a billion LLM activations, and we want you to use them!
New preprint: Learning a Generative Meta-Model of LLM Activations
Joint work with @feng_jiahai, @trevordarrell, @AlecRad, @JacobSteinhardt.
More in thread 🧵
32
192
1,436
221,528
Feb 8
Brent and Hongsuk improved FPO to control robots with flow/diffusion models in real time!

New project! Flow Policy Gradients for Robot Control
tldr; a simple online RL recipe for training and fine-tuning flow policies for robots
co-led w/ @redstone_hong: hongsukchoi.github.io/fpo-co…
2
38
4,224
David McAllister retweeted

Feb 3
𝑪𝒐-𝒕𝒓𝒂𝒊𝒏𝒊𝒏𝒈 is a promising way to scale Large Behavior Models (LBMs) beyond robot data, yet the data and training recipe are far from settled. 🤔
We present a large-scale empirical study leveraging 4,000h of robot/human data and 50M vision-language samples, evaluating 89 policies across 58,000 simulation rollouts and 2,835 real-world trials. 🤖📊
co-training-lbm.github.io/
Work done during my internship at @ToyotaResearch.
7
50
411
47,942

tyro 1.0 is out 🐣
This has been a pet project/niche interest of mine for ~4 years now, so it's a bit of a sentimental moment...
github.com/brentyi/tyro
11
22
180
42,564
David McAllister retweeted

12 Dec 2025
Action chunking is drawing growing interest in RL, yet its theoretical properties are still understudied.
We are excited to share some insights on when we should use action chunking in Q-learning a new algo (DQC) to tackle hard long-horizon tasks!colinqiyangli.github.io/dqc🧵1/N

6
57
308
88,445
David McAllister retweeted

3 Dec 2025
I'm recruiting multiple PhD students this cycle to join me at Harvard University and the Kempner Institute! My interests span vision and intelligence, including 3D/4D, active perception, memory, representation learning, and anything you're excited to explore!
Deadline: Dec 15th.
24
151
921
175,966
David McAllister retweeted

1 Dec 2025
In honor of the 39th AI Winter, I’m going to spend the week disentangling the culture and code of reinforcement learning. There may be ranting... argmin.net/p/reformist-reinf…
2
9
98
10,815
David McAllister retweeted

28 Nov 2025
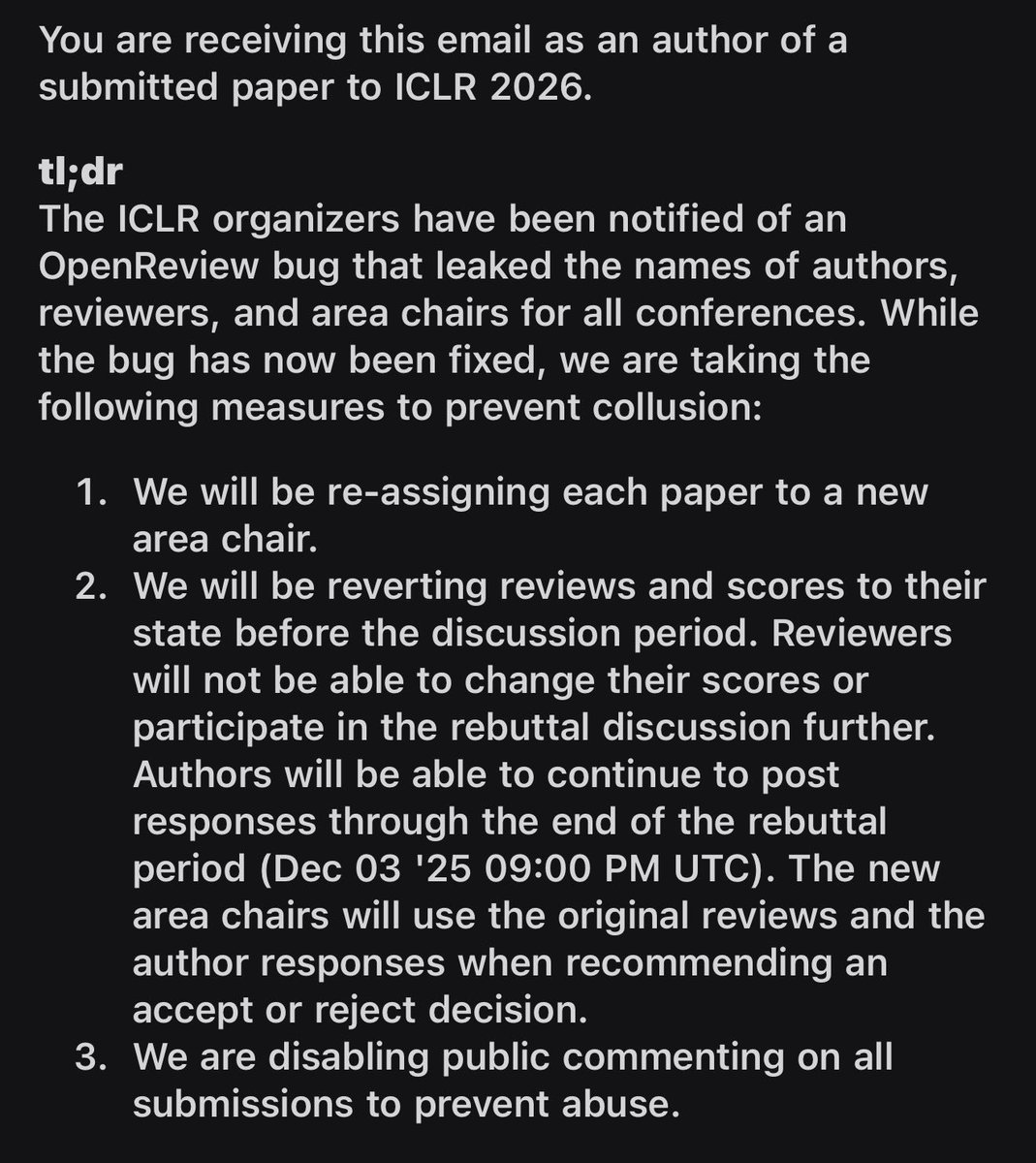
Hey @iclr_conf, reverting scores is unnecessary punishment for the majority of the authors who had nothing to do with this incident and had successful rebuttals. Instead of detecting collusions on your end (you have a ton of metadata) why is this everyone’s burden to bear?
8
29
215
39,127
David McAllister retweeted

26 Nov 2025
Excited to release Terminal Velocity Matching, our latest work on single-stage generative paradigms for one/few-step sampling. It’s SOTA on 1-step sampling, beats diffusion, and really works at scale!
Tremendous work by @linqi_zhou, it's amazing how easy this was to train at large scale!
26 Nov 2025

Introducing Terminal Velocity Matching: a scalable, single-stage generative training method that delivers diffusion-level quality with a 25× fewer inference steps, now trained at 10B scale.
lumalabs.ai/blog/engineering…
3
4
46
7,023
David McAllister retweeted

25 Nov 2025
starting fall 2026 i'll be an assistant professor at @Penn 🥳
my lab will develop scalable models/theories of human behavior, focused on memory and perception
currently recruiting PhD students in psychology, neuroscience, & computer science!
reach out if you're interested😊

ALT a red building on UPENN's campus photographed during the fall

ALT the Philadelphia skyline, with clear skies and autumn trees
35
59
437
52,820
David McAllister retweeted

18 Nov 2025
It's really great working with Jensen (@jensenzhoujh) on this effort. Please get in touch with us if you have experience in these post-training topics and would like to work with us! 🙌 🙂
18 Nov 2025

We are looking for contributors for World Model Post-Training of foundational video models at Meta @AIatMeta!
We are looking for talent with expertise in RL post-training, distillation, attention sparsification, diffusion model, and more to hop onboard.
Candidates at all career levels are welcomed, whether students or not. We have immediate and flexible start dates for contractor positions. Onsite collaboration is possible in Zurich 🇨🇭, London 🇬🇧, or New York 🇺🇸.
If you’re driven about advancing interactive spatial intelligence, we are here to talk - feel free to DM me and @ethanjohnweber.
1
2
15
3,835
David McAllister retweeted

21 Oct 2025
Simulation drives robotics progress, but how do we close the reality gap?
Introducing GaussGym: an open-source framework for learning locomotion from pixels with ultra-fast parallelized photorealistic rendering across >4,000 iPhone, GrandTour, ARKit, and Veo scenes!
Thread 🧵
11
66
343
108,005
David McAllister retweeted

20 Oct 2025
✨Introducing ECHO, the newest in-the-wild image generation benchmark!
You’ve seen new image models and new use cases discussed on social media, but old benchmarks don’t test them!
We distilled this qualitative discussion into a structured benchmark.
🔗 echo-bench.github.io
4
31
129
47,363