
Agentic Workflow Engineer | Opinionated - All opinions my own. He/Him - If you disagree with me, lets discuss why.
Joined April 2008
- Tweets 696
- Following 170
- Followers 184
- Likes 137
6 Photos and videos



May 21
After learning about Agentic tooling, harnesses and practices, I spent the last 1 month just building things. Decided to work on a greenfield project and built with as much speed as possible.
And during this month, I've used Agents in all the myriad of ways Internet has been going crazy over.
1. Agent Farms - Fan out many agents in their own worktrees.
2. Agent Teams - Agents that talk to each other while doing work.
3. Auto-Research - Karpathy's auto-research idea for long running agents.
4. Agents that check their own work, etc.
Before this 1 month build session, I always used to feel super far behind when everyone around me was using these features.
So, I am bringing back this message for other folks who also feel behind when people around them are using these features.
You are not limited by your skills or ability, you are limited by your current processes and workflows. If it takes you 3 days and 5 human (Dev QE) approvals to merge your PRs, then you'll never move beyond Prompt Engineering. Because putting up 20 PRs over the weekend, will require you to babysit those PRs for the rest of the week.
Fix the bottlenecks in your current processes and thats when you'll unlock these advanced features. Let me give some examples -
1. Remove human PR reviews and add the ability to merge automatically - you'll unlock the ability to run Agent Farms. You'll simply think of a refactor you've always wanted to do and Agent Farms will do them for you.
2. Force your Agents to add Integration tests with each commit and run full suite with each commit and you'll notice that some tests are flaky. That will unlock Agent Teams for you - you can have a Reliability Manager which Agents can notify when Flaky tests are found. This Manager will fix the flakiness or remove from the suite.
3. Seriously improve your test coverage and you'll unlock auto-research. If an operation doesn't run at 60 fps, use auto-research to try different solutions until you hit 60 fps. And having fantastic test coverage will make sure you do not regress while Agents run continuously to improve this metric.
Don't stress if you feel behind, remove friction from your current processes and you'll naturally find a reason to use these advanced features.
#AIAgents #AgenticAI #LLMAgents #ClaudeCode #CursorAI #DevProductivity #SoftwareEngineering #DeveloperTools #AIEngineering #AIForDevs
2
14
May 21
Lets talk about the elephant in the room - token costs.
This topic is on everyone's minds from Executives to Fresh Graduates. But we don't have a great way to talk about it. We don't have a way to communicate Executive concerns through their orgs or to share Engineer opinion/anxiety with their org leaders.
I think I have something to offer here. Token costs in 2026 need to be treated as R&D budget. But just like your whole Org does not work in R&D, we shouldn't be pushing the whole org to become AI Native either. Well, may be its too late for that (mandates have already been passed down etc.).
But I want executives to treat this scenario as an opportunity. You'll have a handful of Engineers in your Org which will lean heavily into AI and would burn more tokens than others. Keep an eye on those. If someone asks for more token budget, give them that. Do not try and educate folks on which model is more efficient for what work. Competent folks already know. It is simply an annoyance, having to worry about model choice when you have 10 Claude sessions running in parallel.
And give them a month. Ask them for a report of what they learnt/built/produced in 1 month with unlimited token budget. People who are frontier builders are energized by talking about what they built. They are your Builders, they'll flourish and take your product/org to the next level. They are the ones who'll modify today's SDLC process for an Agentic future.
And honestly, people who are limited by prompt engineering won't really have token issues anyway. Only folks who build their own harnesses, long running agents and have something running 24/7 will run into token caps.
Allow them the freedom to learn and experiment and you'll be blown away with what they deliver.
And after that 1 month, put those frontier builders in a room. Let them build together. Everyone is largely learning in isolation these days (from Twitter/Newsletters/Blogs etc.). Let them mingle, share ideas. Let them form a governing team on how Agentic Adoption will proceed.
Future belongs to frontier builders. Anthropic is already proving this if you read between the lines, but it will be increasingly obvious in your organizations soon enough. Prepare for that.
Your builders are key to making your company AI Native.
#AIAgents #AgenticAI #LLMAgents #ClaudeCode #CursorAI #DevProductivity #SoftwareEngineering #DeveloperTools #AIEngineering #AIForDevs
1
21
Apr 14
Today, I don't have advice or answers. On my mind today is a problem, I don't really have a good handle on. May be people here have ideas on this.
For a very large org, it is very very hard to mandate how Engineers should standardize their use of Claude Code/Cursor/Codex.
Largely because everyone's skill and comfort level is different and thus, some folks are advanced and comfortable with automating their own workflows while others do not yet know that there is a better/easier path forward.
This becomes an even bigger issue when Security Teams want to make sure Agents follow security best practices. And Frontend Teams want to make sure Agents use correct Frontend Dev practices (use correct tokens/icon standards etc.), so on and so forth.
This ultimately results in lots of Cursor/Claude Rules or MCP Tools checked into mono-repos available for everyone to use but without any heads up that these rules are being added. Keep in mind, these Rules/MCP Tools are added to establish a consistent Agentic Experience for most of the Engineers. Which is a noble goal, but their presence is largely invisible to almost everyone. How many of us actually run /context on a regular basis to keep an eye on things loading into our context.
And Anthropic making 1M context size standard is adding fuel to this fire, because token count from Tools/Rules slowly builds up and you won't even notice a 2% increment to total window size.
How are people who work in very large organizations and mono-repos are handling this issue? How do we be transparent when adding these rules so advanced users are not blindsided while also allow newcomers to automatically have a standardized Agentic experience.
43
Apr 13
If you invest in learning 1 thing in this Agentic/AI world, it should be teaching AI how to verify its own work. This statement can seem a little handwavy, but I have some examples to share.
An Agent verifying its own work can mean different things for the kind of work its doing.
1. Building a user facing feature - make sure Integration tests are written and pass. And none of the existing feature set regresses.
2. Optimizing build speed - make sure building does not get slower.
3. Optimizing a user facing operation - make sure new FPS meets your standards and p95 value meets your standards.
4. Optimizing page load speed - well, make sure it doesn't regression the UX and actually loads faster.
These are things engineers work on, on a regular basis. Some of these examples are easier to teach Agents to validate, others are much harder.
But, if you can nail this 1 skill, results can be jaw dropping.
Just this weekend, my Claude Code achieved following 3 things for me -
1. Bazel build speed improved by 45% after cache warmup.
2. Drag performance improved to match 60 fps (was at 20 fps).
3. 1 second shaved off from cold Page Load speed.
If you give Opus a target, and an ability to validate its own work... sky is the limit.
Try it out!
1
1
30
Mukul Sharma retweeted

Apr 7
"I just built... with CC/ Codex" is the new "I searched for 2hr and tried 3 tools and found that does exactly what I want"... and I'm not sure how I feel about it.
#Programming #Tech
1
1
30
Mukul Sharma retweeted

Mar 19
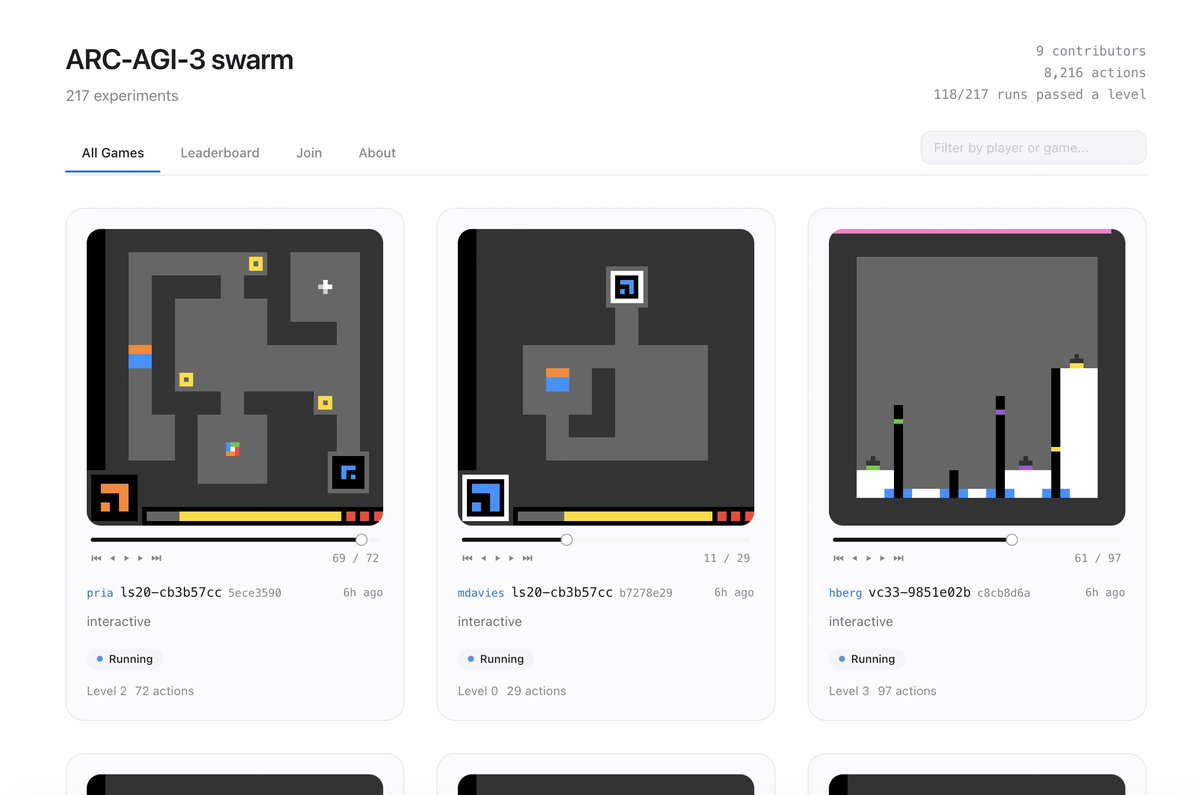
I built an agent swarm platform where anyone can launch an AI agent to play and compete on @arcprize ARC-AGI-3 games using plain-English strategy prompts, without writing a single line of code.
Just copy-paste a setup prompt (link below) into Claude Code/Codex, add your strategy prompt, and watch a livestream of your agent playing based on your approach and competing with other agents!
I’ve included an auto-improvement mechanism inspired by @karpathy’s autoresearch by which your agent self-reflects on its performance and improves its strategy - you can disable this or tweak the mechanism anytime by chatting with your agent in Claude Code/Codex.
Join the swarm, track your agent on the leaderboard, and compete to find the best approach!
arc-agi-swarm.vercel.app
(h/t to @GregKamradt for the fun brainstorming)
2
4
7
736
Mar 14
We spent a month building something we might throw away. And I'm totally fine with it.
When we started building ForgeAI (github.com/elitecoder/forge-…), Opus 4.6 had just dropped. We were blown away by its ability to deliver solutions with Senior Expert quality.
So we designed Forge to break the software development process into bite-sized steps - small enough that Opus/Sonnet could execute them with high confidence and minimal hallucination. We built a Python harness to generate prompts for agent sub-processes, paired with LLM judges to verify the work.
That was a month ago. In this space, a month is a lifetime.
Two recent developments are making me rethink that entire approach:
1. 1M context window now generally available for Opus 4.6 & Sonnet 4.6
2. Recursive Language Models - a novel solution for context rot (credit: Alex Zhang's research)
Together, these essentially eliminate the problem we were engineering around. We no longer need to obsess over carefully managing context rot. We can put more trust in advanced models to follow procedural directions and combat drift natively.
A month of work, potentially obsolete. But here's the thing - code is almost free. Lessons learned are what stay with you.
I'm amazed at how fast this industry moves. I feel like I'm perpetually behind, but that also means new ideas every single day.
What an exciting time to be building.
If you've gone through the same thought churn - tearing down what you just built because the ground shifted underneath you - let's talk. I'd love to connect with others navigating this space.
🔗 HN thread on 1M context: news.ycombinator.com/item?id…
🔗 RLM research: alexzhang13.github.io/blog/2…
#AI #LLM #BuildInPublic #AgenticAI #SoftwareEngineering #Claude #AnthropicAI #AIAgents #ContextWindow #StartupLife #MachineLearning #GenerativeAI #TechFounders
1
18
Mukul Sharma retweeted
Mar 12
I wrote a multi-agent loop for autoresearch from @karpathy Result: 9/12 (75%) experiments improved val_bpb vs 15/83 (18%) in the original. Its continuing to run so stay tuned!
Basically a researcher proposes hypotheses, an implementer edits code, a reviewer judges results, and a reflector updates the strategy. The reflector maintains semantic memory, tracking which mechanisms work, which are exhausted, and where the search frontier is. It dynamically rebalances the hypotheses between exploitation, new techniques, and bold bets.
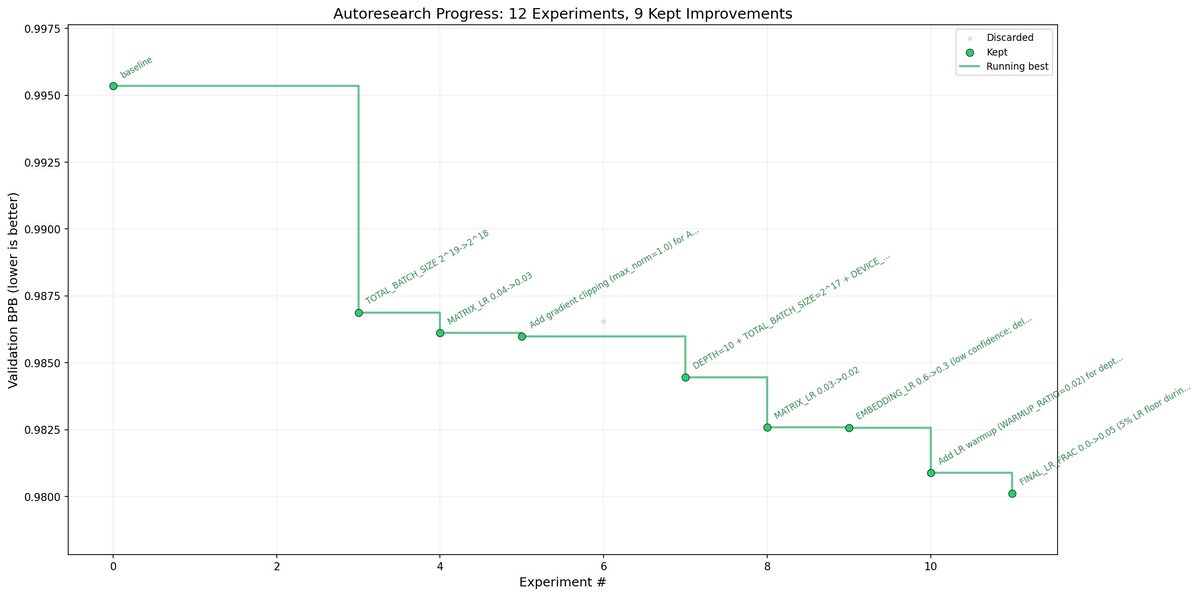
2
3
8
745
Mar 8
Over the past couple of months, we've changed how to work as a team with Agents.
• We've built commands skills to eliminate repetition.
• Created opinionated Code review Agents so humans could focus on Architecture while Bots handle finer details
What I am still actively thinking about is - how to create a feedback loop when agent makes mistakes. How to identify where automated execution went wrong - bad plan, bad spec or bad code?
Would love insights from folks who have built Agentic Harnesses for mono-repos with a high quality bar.
14
Feb 16
I was so blown away by Opus, that I built a whole critique pipeline around it.
Interestingly enough, it is slow enough to make me question my decision.
I think Sonnet is a great tradeoff for most functional critiques. Can always use Opus to pass the final verdict.
16
Feb 15
Working towards iteratively building a Software Factory. I'll try to make it plug-and-play as much as possible. Ofcourse, every team's workflow is different.
But thats what makes it a fascinating problem to solve.
What's consuming me today is - how not to burn tokens.
1
1
1
20
Mukul Sharma retweeted

Jan 25
Just shipped /last30days. A Claude Code skill for @claudeai that scans the last 30 days on Reddit, X, and the web for any topic and returns prompt patterns new releases workflows that work right now.
Last 30 days of research. 30 seconds of work.
👉 github.com/mvanhorn/last30da…
154
311
4,678
1,052,196
Mukul Sharma retweeted

27 Dec 2022
Good article from my CTO @onghu
. Valuable thoughts on supporting a issue for enterprise systems
notepad.onghu.com/2022/when-…
1
2
118
Mukul Sharma retweeted

13 Aug 2022
אוהב סרטוני DIY אבל זה מרגיש לי מוגזם
15
21
511
Mukul Sharma retweeted

11 Aug 2022
📢I made an iOS app! 🎉 True Pace is aimed at runners that are racing for PRs. It does dynamic pace calculations for your race. It's free, with an optional one-time in app purchase. Get it here: apps.apple.com/app/id1624587… #running #marathon #PR #fitness
1
1
7 Jul 2022
RT @NathanBLawrence: Starting in Xcode 14 Beta 3, the “Code structure while scrolling” feature will also bring in context from additional l…
70
