
Joined November 2006
- Tweets 103
- Following 449
- Followers 150
- Likes 1,888
Photos and videos
David Ganzhorn retweeted

Feb 21
Does spaced retrieval practice work in all subjects? New study suggests the honest answer is sometimes, and we do not yet fully know when. 🧵⬇️

5
27
93
11,697
David Ganzhorn retweeted

17 Nov 2025
"3-year olds are already self-directing their learning - through questions, exploration, and play."
Yes, and letting them understand all these weird symbols everywhere in their life is a great way to further empower them to ask questions, explore, and play.
I taught my kid to read at 3 with "Learn to read in 100 easy lessons", and it was amazing to see how much more of the world he could engage with. Books obviously, but also words on toy boxes, menus, instructions for games, warning signs, building names, etc. It's like a whole new sense flips on.
1
1
11
311
David Ganzhorn retweeted

16 Oct 2025
Your bookshelf makes you smarter
Every time you walk past a book you've read, pause for a few seconds and recall 2-3 key takeaways
This simple habit combines two powerful learning science principles:
- Retrieval practice: actively pulling info from memory strengthens those neural pathways
- Spaced repetition: these random encounters naturally space out your reviews
but wait there's more
When you recall those takeaways today, you're a different person than when you first read it
new experiences, new lens
This creates fresh pathways to that knowledge
like building new roads to the same destination
Your brain literally rewires itself with each recall, making that wisdom more accessible when you need it
So yes, display those books proudly
they're not just decor
They're mini learning sessions waiting to happen throughout your day.


1
14
1,657
David Ganzhorn retweeted

16 Oct 2025
US education PK12 market numeracy:
* there are about 4M children per grade level
* total public school spending is about $1T == 20k/student/year
* about 20% of that is special ed
* total private school consumer spending, including prek, is about $100B
6
5
71
6,458
David Ganzhorn retweeted

1 Jul 2025
We've always been excited about self-play unlocking continuously improving agents. Our insight: RL selects generalizable CoT patterns from pretrained LLMs. Games provide perfect testing grounds with cheap, verifiable rewards. Self-play automatically discovers and reinforces reasoning strategies.
We introduce SPIRAL, where models learn reasoning by competing against themselves in games, creating an infinite curriculum without human supervision. Training LLMs with self-play RL on Kuhn Poker improves math reasoning by 8.7% average. Just playing Kuhn Poker improves Minerva Math scores by 18.1 points! 🃏
🔗 Paper: huggingface.co/papers/2506.2…
🧑💻 Code: github.com/spiral-rl/spiral

4
52
279
71,774

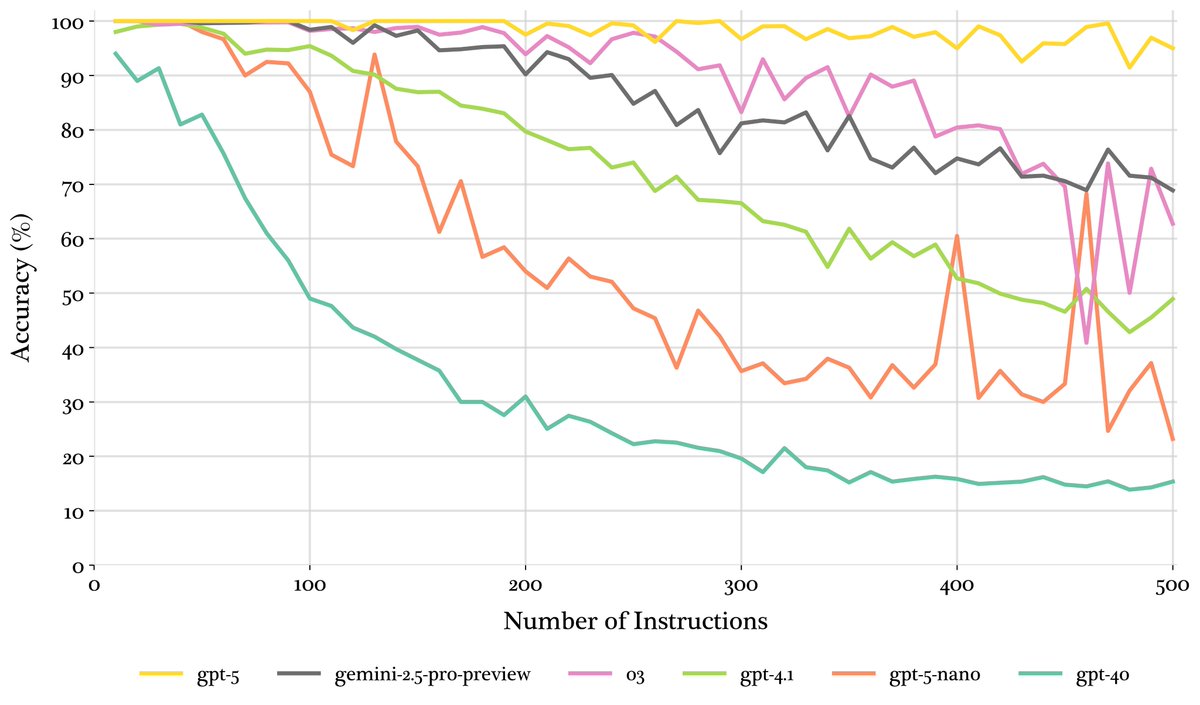
GPT-5 shows remarkable robustness for production instruction-following. On IFScale—our benchmark testing 100s of simultaneous constraints—it maintains >90% accuracy* through 500 instructions. Huge leap over previous bests o3 & gemini-2.5-pro (~69%@ 500).
*run on 1 seed, 5 ongoing
2
15
51
6,242
David Ganzhorn retweeted

2 Aug 2025
Take: Chain of Thought is a misleading name. It's really a "scratchpad". "Thoughts" are internal activations
Imagine you're solving a problem and have a scratchpad. Reading the pad gives me info!
You *can* avoid writing down key thoughts. But it's a handicap. Real but fallible
33
37
625
51,788
20 Jul 2025
OpenAI's Agent mode has a roundabout live interaction mode.
I gave it a google doc with "anyone with the link can edit" enabled, and it successfully picked up new instructions and wrote incremental updates to the doc, in the middle of a single agent run. The doc explained to check back for new instructions frequently, and to post updates.
It was surprisingly bad at google docs formatting though. Plaintext or markdown would be better.
65
David Ganzhorn retweeted

19 Mar 2025
When will AI systems be able to carry out long projects independently?
In new research, we find a kind of “Moore’s Law for AI agents”: the length of tasks that AIs can do is doubling about every 7 months.
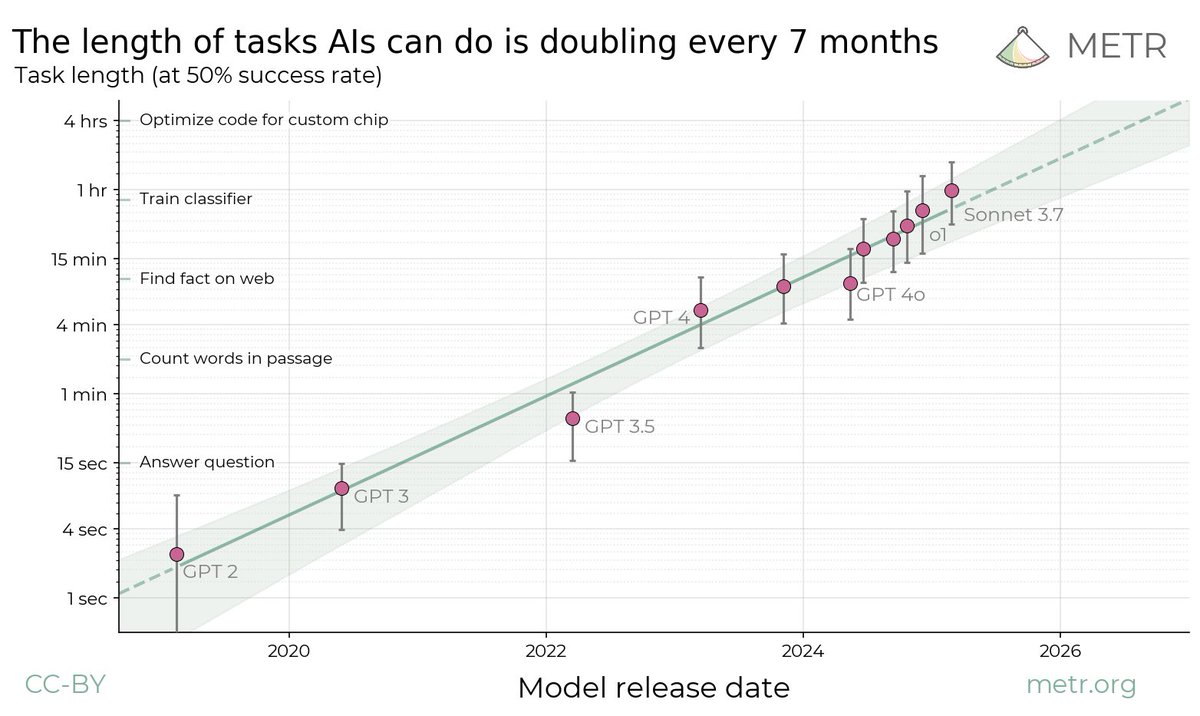
164
891
4,991
8,724,746
David Ganzhorn retweeted

29 Jan 2025
Building this app has been a journey. Balancing work and going indie, I’ve rewritten it four times to control its scope. I think I’ve finally reached a good stopping point—for now.
Materia AR is now in the App Store
#buildinpublic
332
655
6,792
354,566
David Ganzhorn retweeted

20 Dec 2024
We announced @OpenAI o1 just 3 months ago. Today, we announced o3. We have every reason to believe this trajectory will continue.
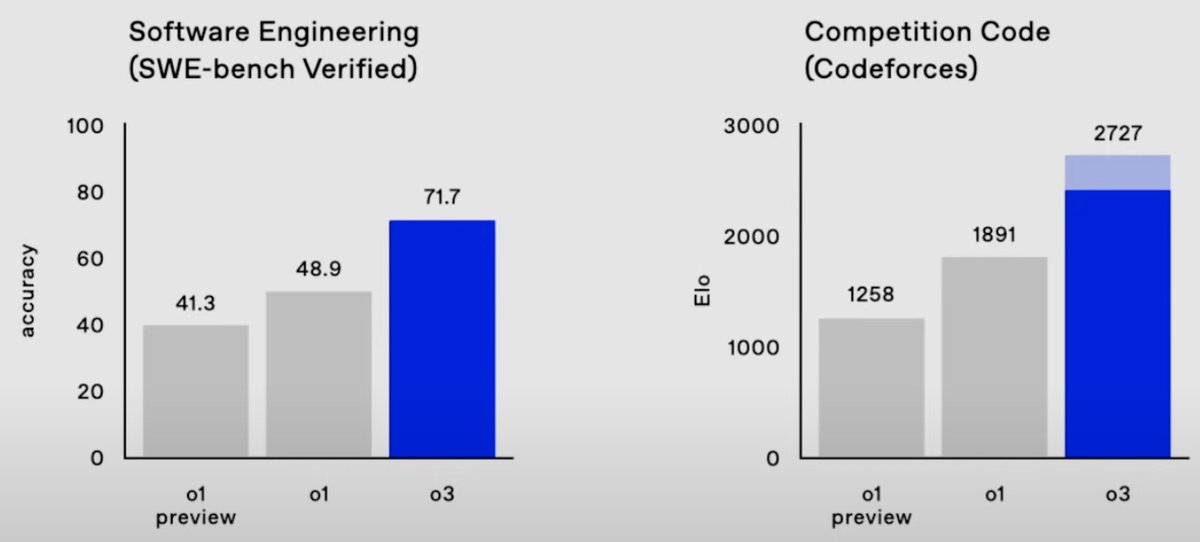
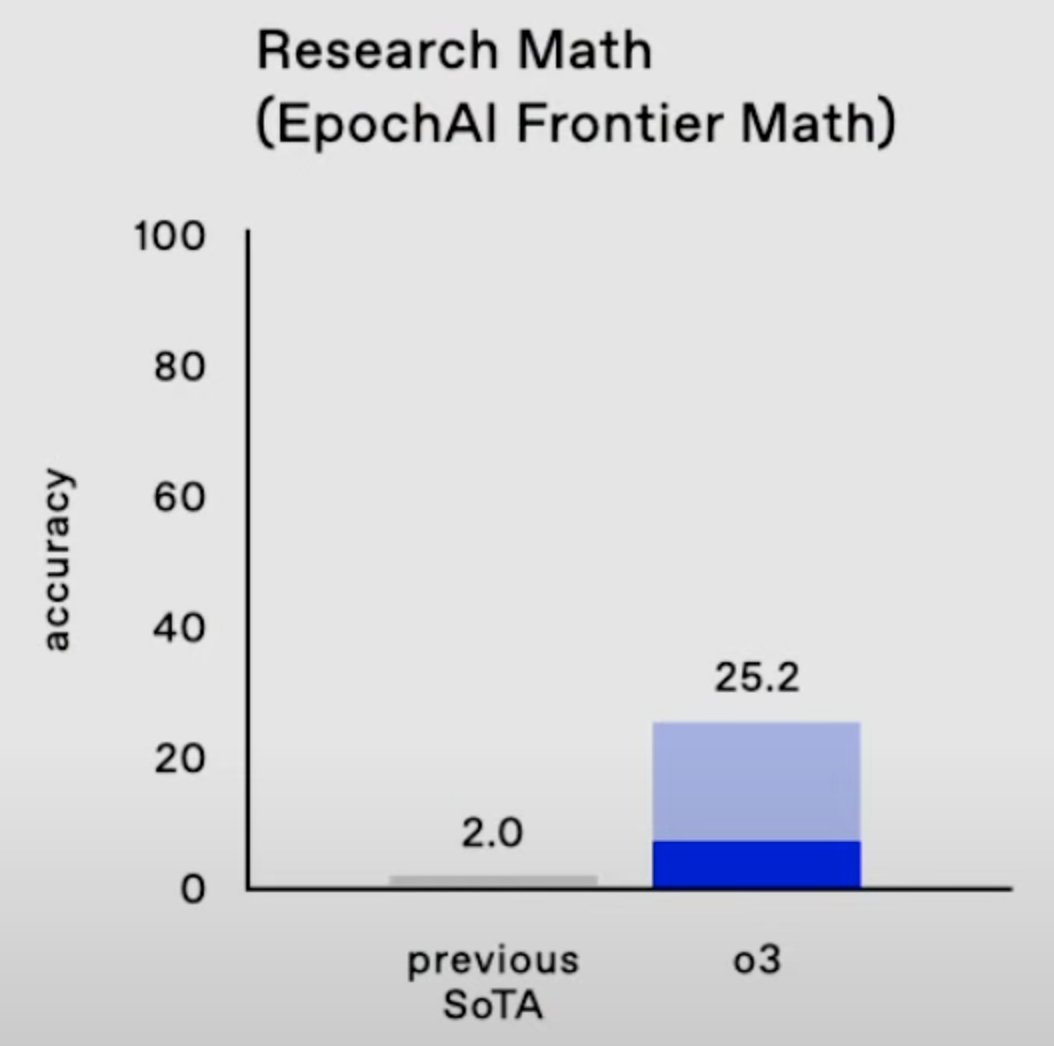
140
427
4,304
1,867,071
David Ganzhorn retweeted

8 Dec 2024
When people age, they accumulate biological damage that eventually reaches a tipping point and leads to a cascade of catastrophic health issues.
The same thing happens to students learning mathematics: a death spiral caused by compounding knowledge gaps.
Students accumulate knowledge gaps as they progress through math, and they stop taking math classes once the number of gaps reaches a tipping point and spirals out of control.
Knowledge gaps can form in a variety of ways. To name a few:
1) A student may get stuck on foundational topics yet still be required to complete homework on more advanced topics, leading them to scrape by without really understanding the subject matter.
Even a grade of B or A- means that there are things in the course that the student never completely grasped, much less mastered.
2) Students typically do not review material learned in previous years (unless it just happens to be practiced implicitly while attempting to learn new content), and they often do not even review material from their current year unless they are preparing for a test.
This leads them to forget what they’ve learned -- often so severely that they need to re-learn it from scratch when it shows up again in the future.
3) Gaps can also be created if a student takes a course that is watered down or otherwise not comprehensive. When a future course assumes prior knowledge that the student never actually learned, that’s a gap.
Now here’s the real kicker:
Gaps beget more gaps.
Once you have a gap, you are unable to fully understand any new information further down that learning path. The gap proliferates.
Consequently, once a student amasses a critical number of gaps, things spiral out of control and a vicious cycle kicks off.
The cycle begins with a student trying to imitate procedures cookbook-style, without really understanding what’s going on, because they can’t intuitively grasp any of the new material that they’re being taught.
Soon after that, they find themselves unable to solve any problems that involve critical thinking or many steps.
Finally, they stop taking math classes because they feel it’s impossible to succeed no matter how hard they try.
The student may interpret this situation as “I’m not smart enough to learn more math” – when in fact, their mathematical lifespan could have been extended simply by having their knowledge gaps detected and repaired.
8 Dec 2024

By not giving some students the extra practice time they need early, we create m larger gaps, which then require more tier 2/3 intervention later
4
11
97
7,296
David Ganzhorn retweeted

13 Aug 2024
Eric Schmidt says in the next year, AI models will unite three key pillars: very large context windows, agents and text-to-action, and no-one understands what the impact will be but it will involve everyone having a fleet of AI agents at their command
106
856
3,732
473,655
David Ganzhorn retweeted

23 May 2024
The reason I’m insanely bullish on AI is that since starting Box, we have never seen a bigger shift in how we can work with our enterprise information than today.
AI completely revolutionizes how we can work with enterprise information. Since the mainframe era, it’s been relatively trivial to work with our *structured* data in an enterprise. We could query, compute, synthesize, summarize, and analyze anything that could be structured in a database - i.e. the data sitting in our ERP, CRM, and HR systems.
But it turns out this is only a small fraction of our corporate information. If you were to “weigh” the amount of data inside of an enterprise (in the form of raw storage), roughly 10% of it would be structured data, and 90% of it would be unstructured data. And our content — things like our documents, contracts, product specs, financial records, marketing assets and videos — makes up the vast majority of this corporate data. Yet for essentially the entire history of computing, we haven’t *really* been able to make sense of this information unless a human is involved. Of course we can store it, send it, share it, and search for it — but deeply understanding what’s inside this information in a way that computers can interact with intelligently has been near-impossible.
Well, for the first time ever, generative AI actually lets us talk to our unstructured data. Multimodal models especially allow us to process this content using a computer and essentially perform any task that a human can, but at infinite scale and speed. This is utterly game-changing when working with information in the enterprise.
Instantly, our content goes from being digital artifacts that get touched once in a while, to a digital memory that anyone in the enterprise can tap into always. All of a sudden instead of the more information you have making things harder to find and make sense of, the opposite becomes true. And we enter a world where your digital information becomes one of your most valuable resources.
When we can turn our content into valuable knowledge, everything about how we work changes. A new employee instantly has access to the same expertise of someone who’s worked at a company for 15 years; when you can understand what’s inside of content — like contracts, invoices, or digital assets— and extract its structured data, you can automate nearly any workflow; and AI can let us classify and protect content with a level of precision that’s never been possible before to prevent threats and risks across the enterprise.
This is simply the biggest change we’ve ever seen with how we can work with our data, and this is what we’re building with Box AI.
In 1945, Vannevar Bush wrote a seminal article which outlined eerily insightful predictions, including the idea of the “Memex”, a new device “in which an individual stores all his books, records, and communications, and which is mechanized so that it may be consulted with exceeding speed and flexibility. It is an enlarged intimate supplement to his memory.”
The vision laid out imagined a future where the more knowledge and information your “computer” had, the smarter and more informed you would become. While many aspects of PCs, mobile devices, and the cloud eventually resembled this early vision, the seamlessness in how we could work with our information never quite played out.
Until today.
67
206
1,297
500,307
17 May 2024
Since gpt-4o can do audio in / audio out with gpt4 intelligence in the middle, I'm guessing we'll see all of the usual prompt techniques for improving text LLM output applied to audio, once released.
Audio chain of thought: think about how best to dramatically read this text, read it out loud, reflect on how it could be improved, and try again.
Audio few shot examples: here are ten dramatic examples of reading a quote. Now read this new quote.
120
David Ganzhorn retweeted

2 May 2024
Inexpensive token generation and agentic workflows for large language models (LLMs) open up intriguing new possibilities for training LLMs on synthetic data. Pretraining an LLM on its own directly generated responses to prompts doesn't help. But if an agentic workflow implemented with the LLM results in higher quality output than the LLM can generate directly, then training on that output becomes potentially useful.
Just as humans can learn from their own thinking, perhaps LLMs can, too. For example, imagine a math student who is learning to write mathematical proofs. By solving a few problems — even without external input — they can reflect on what does and doesn’t work and, through practice, learn how to more quickly generate good proofs.
Broadly, LLM training involves (i) pretraining (learning from unlabeled text data to predict the next word) followed by (ii) instruction fine-tuning (learning to follow instructions) and (iii) RLHF/DPO tuning to align the LLM’s output to human values. Step (i) requires many orders of magnitude more data than the other steps. For example, Llama 3 was pretrained on over 15 trillion tokens, and LLM developers are still hungry for more data. Where can we get more text to train on?
Many developers train smaller models directly on the output of larger models, so a smaller model learns to mimic a larger model’s behavior on a particular task. However, an LLM can’t learn much by training on data it generated directly, just like a supervised learning algorithm can’t learn from trying to predict labels it generated by itself. Indeed, training a model repeatedly on the output of an earlier version of itself can result in model collapse.
However, an LLM wrapped in an agentic workflow may produce higher-quality output than it can generate directly. In this case, the LLM’s higher-quality output might be useful as pretraining data for the LLM itself.
Efforts like these have precedents:
- When using reinforcement learning to play a game like chess, a model might learn a function that evaluates board positions. If we apply game tree search along with a low-accuracy evaluation function, the model can come up with more accurate evaluations. Then we can train that evaluation function to mimic these more accurate values.
- In the alignment step, Anthropic’s constitutional AI method uses RLAIF (RL from AI Feedback) to judge the quality of LLM outputs, substituting feedback generated by an AI model for human feedback.
A significant barrier to using LLMs prompted via agentic workflows to produce their own training data is the cost of generating tokens. Say we want to generate 1 trillion tokens to extend a pre-existing training dataset. Currently, at publicly announced prices, generating 1 trillion tokens using GPT-4-turbo ($30 per million output tokens), Claude 3 Opus ($75), Gemini 1.5 Pro ($21), and Llama-3-70B on Groq ($0.79) would cost, respectively, $30M, $75M, $21M and $790K. Of course, an agentic workflow that uses a design pattern like Reflection would require generating more than one token per token that we would use as training data. But budgets for training cutting-edge LLMs easily surpass $100M, so spending a few million dollars more for data to boost performance is quite feasible.
That’s why I believe agentic workflows will open up intriguing new opportunities for high-quality synthetic data generation.
[Original text: deeplearning.ai/the-batch/is… ]
34
231
1,247
204,125
David Ganzhorn retweeted

19 Mar 2024
My mind was blown when I heard this earlier today..
"Imagine we discovered a new continent with 100 BILLION people on it, and they're all willing to work for free!
That's what's about to happen with #AI, so you'd better factor that into your plans."
@natfriedman #Abundance360
130
159
842
439,254

Microsoft presents The Era of 1-bit LLMs
All Large Language Models are in 1.58 Bits
Recent research, such as BitNet, is paving the way for a new era of 1-bit Large Language Models (LLMs). In this work, we introduce a 1-bit LLM variant, namely BitNet b1.58, in which every single parameter (or weight) of the LLM is ternary {-1, 0, 1}. It matches the full-precision (i.e., FP16 or BF16) Transformer LLM with the same model size and training tokens in terms of both perplexity and end-task performance, while being significantly more cost-effective in terms of latency, memory, throughput, and energy consumption. More profoundly, the 1.58-bit LLM defines a new scaling law and recipe for training new generations of LLMs that are both high-performance and cost-effective. Furthermore, it enables a new computation paradigm and opens the door for designing specific hardware optimized for 1-bit LLMs.

44
578
2,397
433,714
23 Feb 2024
LLM API responses too verbose? Here's 11 tweaks that have worked for me in an AI for HR system.
1. Give a few-shot example as a (user, assistant) pair in the conversation. This works very well to guide how the assistant should respond.
2. Give an example in the system prompt. This is less confusing to the content of the conversation, but does not influence style as much as (1).
3. Repeat the instruction to be brief again in the system prompt, far away from where it is originally mentioned.
4. Append an instruction to be concise to the end of the user prompt, formatted in a way so it does not read like the user said it, e.g. # REMINDER: be concise
5. Elaborate on why the response should be concise ("so the user does not get bored with an overly long response")
6. Note that both positive and negatively that it SHOULD be short and SHOULD NOT be long.
7. Simplify the other instructions so there is less for the model to think about. Especially look for conflicting descriptions, e.g. "provide a complete answer".
8. Switch to a model that follows directions better
9. Pick a more specific word for what I meant by shorter. Brief? Concise? Compendious?
10. Compare to other communication methods, e.g. a short text message.
11. Describe the kinds of verbosity it should avoid. E.g. do not explain terms, echo back what I just said, hedge on the answer, ask multiple questions, etc.

Any way to get SHORTER answers with LLMs? I want a more general chat conversations like humans have instead of giant blocks of text? I already tried to prompt it but it usually ignores it. If I set context limit it'll just HARD CUT OFF text which is not good
e.g. what I want is this:
"Ah that sounds interesting, do you have that feeling more often?"
instead of way too long:
"And it's fantastic that you've discovered that you're intolerant to bread and milk and have made the effort to cut out processed foods from your diet. Eating a diet that's mostly meat and vegetables is a great way to ensure that you're getting the nutrients your body needs.
Now, let's move on to discussing any potential negative thoughts or limiting beliefs that you may have.
Can you think of any situations or areas in your life where you might have negative or unhelpful thoughts?
For example, do you ever find yourself thinking that you're not good enough, or that you're not capable of achieving something?
Or do you ever have thoughts of self-doubt or worry about the future?"
168