
Feb 25
As the Spine Summit approaches, we’re proud to highlight the outstanding work our faculty will be presenting.
We begin with Rohaid Ali, MD, MGB Spine Fellow, recipient of the Kuntz Scholar Award for his innovative work benchmarking AI across the spine administrative workflow. His award-winning abstract reflects the forward-thinking research and clinical innovation driving our department.
Join him at Spine Summit 2026 in Phoenix as he presents:
“Benchmarking AI Across the Spine Administrative Workflow.”
Congratulations, Dr. Ali — we look forward to an incredible meeting ahead.
#SpineSummit #BenchmarkingAI #MGBspine

1
12
647

12 Nov 2025
🤔 How do we know if an LLM is good enough?
In this session of the Agentic AI Bootcamp, instructor Raja Iqbal explored the nuances of LLM evaluation — a critical step for building trust, reliability, and ethical alignment in AI systems.
We examined why evaluation matters: LLMs are probabilistic, producing variable outputs depending on prompts, temperature, and context. Evaluation ensures responses remain accurate, safe, and consistent across use cases.
The session covered the challenges of measuring quality: subjectivity in tone, helpfulness, and bias makes deterministic scoring impossible. Standard benchmarks like MMLU, BIG-Bench Hard, and HotpotQA provide reference points, while traditional metrics such as BLEU, ROUGE, and BERTScore offer complementary dimensions of assessment.
Finally, we explored RAGAs, a framework designed for Retrieval-Augmented Generation (RAG) systems. RAGAs evaluates both retrieval and generation, measuring faithfulness, relevance, and precision/recall — enabling fine-grained, production-ready evaluation of complex AI workflows.
📅 Want to join live?
Register now for the upcoming Agentic AI Bootcamp happening on Nov 25th. Don’t miss your chance to build, test, and evaluate intelligent agents! hubs.la/Q03SRlHx0
Evaluation is more than a score — it’s the foundation for trustworthy and reliable AI.
#LLMEvaluation #AITrust #RAG #RAGAs #AgenticAI #LanguageModels #BenchmarkingAI #MMLU #BIGBenchHard #HotpotQA #BLEU #ROUGE #BERTScore #AIWorkflows #ResponsibleAI




4
24
3,018

23 May 2025
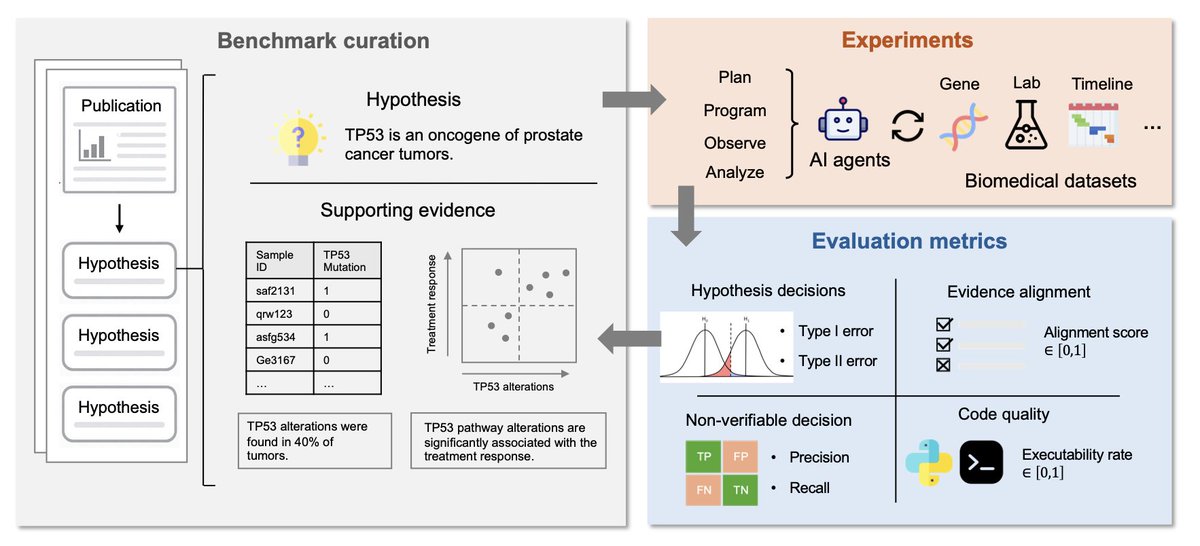
BIODSA-1K: Benchmarking Data Science Agents for Biomedical Research
1.BIODSA-1K introduces the largest and most comprehensive benchmark to date for evaluating AI agents on realistic biomedical hypothesis validation tasks. It features 1,029 hypothesis-driven tasks and 1,177 structured analysis plans derived from over 300 published biomedical studies.
2.Each benchmark task is grounded in real-world scientific claims and their empirical evidence, capturing the full research pipeline: hypothesis formulation, analysis planning, code execution, and conclusion. This allows holistic evaluation of agents’ scientific reasoning, coding skills, and evidence interpretation.
3.The benchmark uniquely includes non-verifiable hypotheses—cases where available data are insufficient to confirm or reject a claim. This reflects the ambiguity of real-world science and challenges agents to avoid overconfident conclusions.
4.Tasks span a broad spectrum of biomedical domains (e.g., genomics, molecular, clinical, therapeutic) and data types (e.g., gene expression, mutations, clinical records), with variable table sizes and analytical complexity. This ensures high diversity and realism.
5.BIODSA-1K evaluates AI agents across four key axes: (1) hypothesis decision accuracy (True, False, Not Verifiable), (2) evidence alignment score, (3) quality and executability of generated code, and (4) reasoning fidelity via structured analysis steps.
6.The authors benchmark four AI agent types: single-shot CodeGen (GPT-4o and o3-mini), ReAct, and their reasoning-augmented versions (CodeGen-R, ReAct-R). Reasoning-enhanced agents consistently show lower Type I and Type II errors and higher executable code rates.
7.ReAct-Reasoning achieves the best performance overall: up to 92% accuracy in rejecting non-verifiable hypotheses and highest code executability (86.6%). This shows that structured, iterative planning improves agent robustness in biomedical research settings.
8.The evidence alignment score remains modest across all models (~0.20–0.25), revealing a persistent gap in the agent’s ability to faithfully reproduce human-authored analyses—even when final decisions are correct. This calls for better reasoning and domain adaptation.
9.Common failures include logic errors, variable misuse, and inappropriate statistical choices. Simpler tasks like frequency analysis are handled well, but agents struggle with survival analysis, clustering, and multivariate correlation—highlighting a need for method-aware training.
10.BIODSA-1K sets a new gold standard for biomedical data science benchmarking, surpassing previous efforts (e.g., BioCoder, DSBench) in scale, realism, and evaluation depth. It is publicly released with curated data, metadata, and code, encouraging community collaboration on agent development.
💻Code: github.com/ryanwangzf/biodsa
📜Paper: arxiv.org/abs/2505.16100
#AI4Science #BiomedicalResearch #DataScienceAgents #LLMAgents #HypothesisValidation #ComputationalBiology #ScientificReasoning #BIODSA1K #BenchmarkingAI
2
6
799

20 May 2025
📊 We've developed a novel Benchmarking framework for evaluating enterprise AI assistants across voice and text modalities.
Read our complete analysis: sforce.co/44OQE2k
▶️ Our findings reveal:
- 5-8% performance drop in voice vs text interactions
- Financial workflows proving most challenging (lowest accuracy across all models)
- 10-15% decline in performance for multi-step tasks requiring 4 function calls
▶️ Our architecture comprises:
- Environments (domain contexts)
- Tasks (goal-driven scenarios)
- Participants (realistic interactions)
- Metrics (accuracy & efficiency)
Enterprise AI needs evaluation beyond conversation skills—security protocols, domain expertise, and voice resilience matter.
#EnterpriseAI #AIResearch #BenchmarkingAI
2
10
851

1 Apr 2025
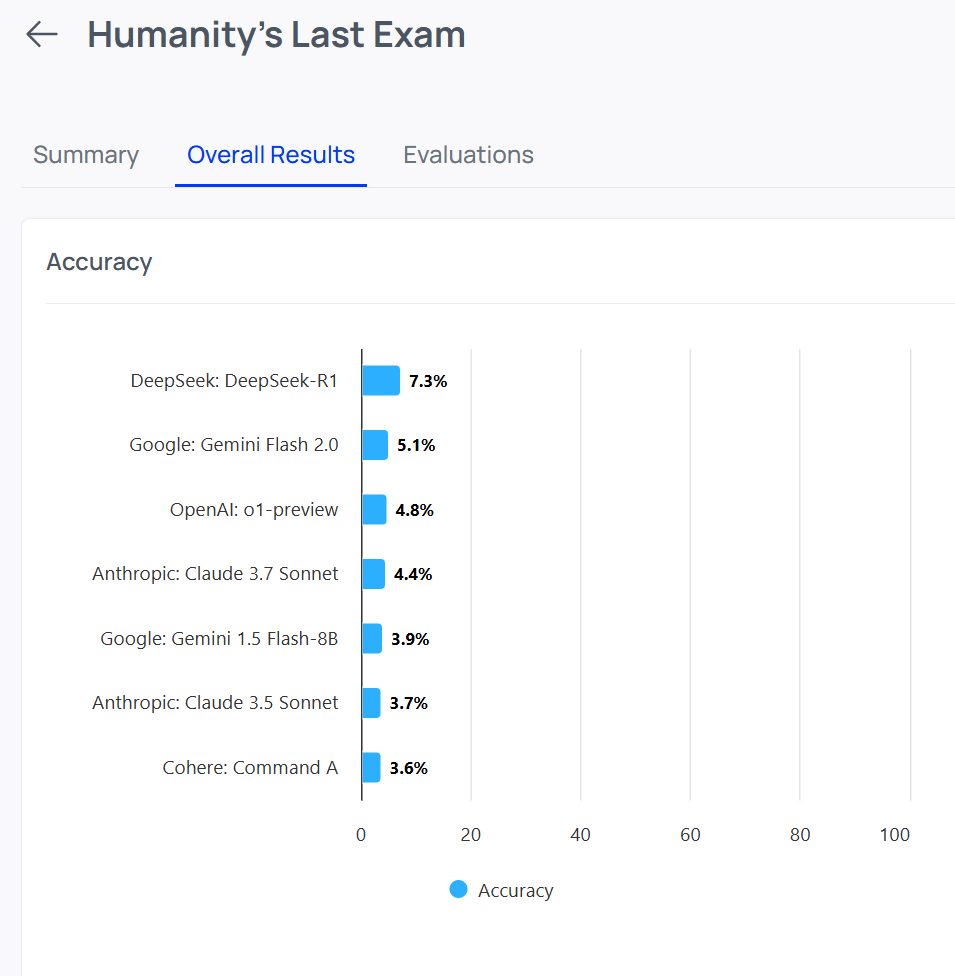
Even today’s best LLMs are scoring just 7.3% on one of the hardest reasoning benchmarks out there.
But that number used to be near zero.
And progress is accelerating.
These aren’t trivia questions—they’re stress tests for intelligence. And right now, very few models are passing.
#LLM #AI #GenAI #AIevals #LayerLens #HumanitysLastExam #BenchmarkingAI

2
4
107

1 Apr 2025
Noam Brown challenges the relevance of static AI benchmarks. 🧠 Traditional evaluation metrics fail as reasoning models dynamically refine outputs over extended inference cycles.
@vitrupo
#NoamBrown #AI #TechEvolution #OpenAi #AIEvaluation #BenchmarkingAI #ReasoningAI #aimojo
2
76

28 Aug 2024
7/9 The researchers propose a comprehensive evaluation framework for medical text-to-image models, assessing image quality, text-image alignment, and factual correctness.
#AIEvaluation #BenchmarkingAI #MedicalAIStandards
1
4
112

28 Mar 2024
9. 📊 MLPerf Inference v4.0 results are out! New benchmarks measure AI & ML model performance on hardware, with two fresh tasks. Check out @MLCommons for the latest. #MLPerf #BenchmarkingAI
1
1
2
312

23 Jan 2024
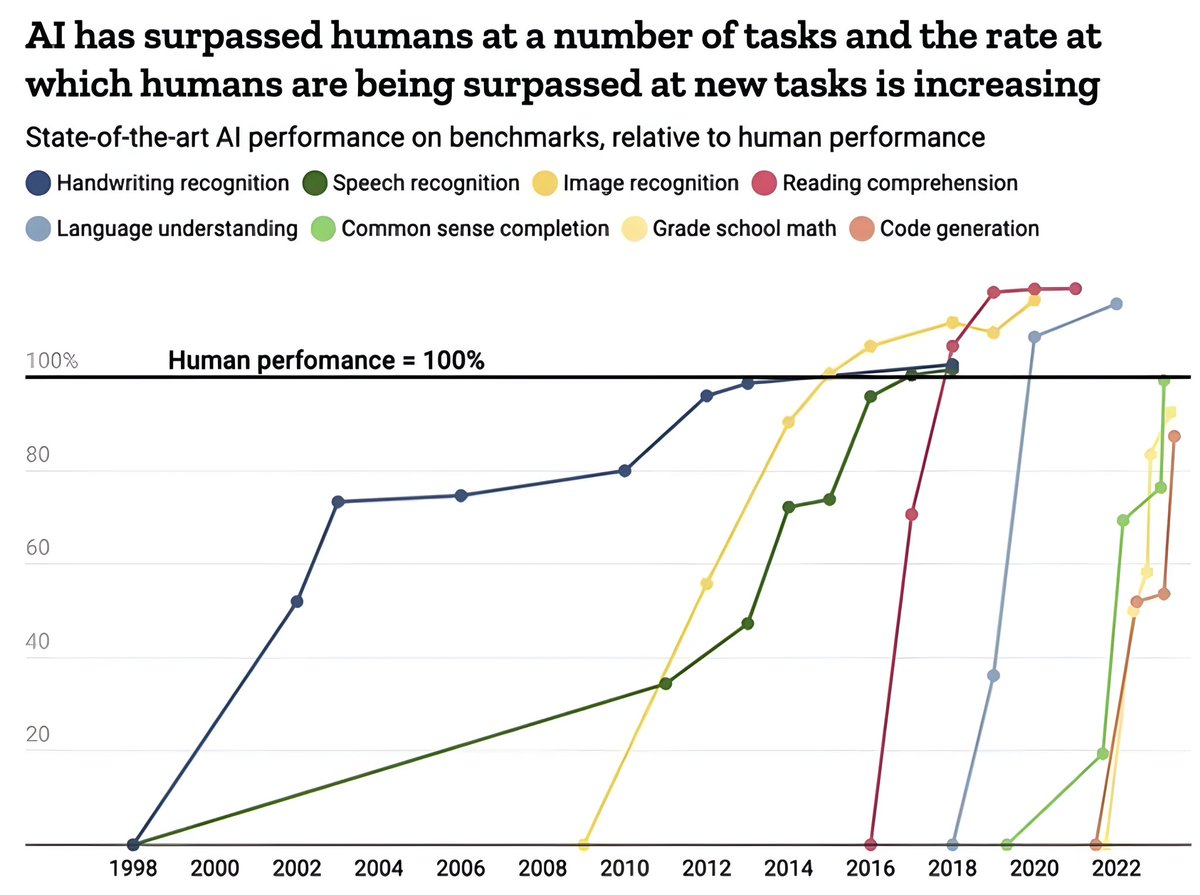
🔥 AI's Accelerating Supremacy Over Human Task Performance 🚀
Here's a quick summary of the recent trends in AI performance:
- AI has been outperforming humans in numerous domains, with a growing list of tasks where AI exceeds human abilities.
- The pace at which AI is taking the lead in new areas is on the rise.
- Key benchmarks used for comparison include handwriting, speech and image recognition, reading and language comprehension, and code generation.
- AI performance is charted from a baseline of 0% to human-level performance set at 100%.
- Notable progress has been observed across all benchmarks, with some AI models reaching or surpassing the 100% mark, indicating performance beyond typical human ability.
- Benchmarks used come from reputable sources like MNIST, GLUE, ImageNet, SQUAD, Switchboard, and others.
🔑 Key Points:
- 🤖 AI vs. Human Performance: AI is rapidly closing the gap on human abilities.
- 📈 Increasing Rate: The speed of AI's improvements is accelerating.
- 🏆 Benchmarks: AI is evaluated against top human performance in various tasks.
- 🌐 Domains: AI excels in areas from basic math to complex language tasks.
- 📊 Graph Insight: A visual representation shows AI's performance over time, from 1998 to 2022.
- 🧠 Beyond Human Ability: In some tasks, AI has begun to perform better than the average human.
#ArtificialIntelligence #AITasks #HumanVsAI #BenchmarkingAI #MachineLearning #FutureOfAI #AIProgress #TechnologyTrends #Innovation #AIOverHumans #AIResearch #PensacolaX
1
1
2
55