

Jun 8
Language models still can’t look at a chart and understand what “up” means because they process graphs as a grid of unrelated tokens rather than structured information.
Researchers from MIT and IBM built ChartNet, a synthetic dataset that teaches models to interpret charts by exposing them to the underlying code and data tables, and the result pushed a modestly sized model past GPT‑4o on key chart tasks.
See how specialized training might outperform brute‑force scaling for enterprise document intelligence: zpr.io/KQArsyBGQFEJ
#AI #LLM #ChartNet
1
1
49

It sounds small, but charts are where a lot of knowledge hides.
MIT’s ChartNet work teaches AI to read and rebuild charts more reliably. That matters for accessibility, research, and anyone who has ever stared at a terrible PDF wondering what the graph actually says.

31

The new ChartNet training dataset from MIT and @MITIBMLab could improve the accuracy of vision-language models that help analyze business trends or interpret scientific figures.
news.mit.edu/2026/mit-resear…
1
4
208

MIT just trained a small open source model to read charts, and it beat the big commercial models. A team at MIT and the MIT IBM Watson AI Lab built ChartNet, a million chart synthetic dataset, and used it to fine tune small vision language models. On chart reading, the small models won.
The bottleneck was not compute. The bottleneck was data. And data is something the open source community can produce at scale.
Red Hat called it earlier this year. In 2026 the question is not "what model do I use." The question is, "How many agents do I have running?" Every business will run a swarm of them. A 3B or 7B model, fine tuned on one task with synthetic data, will outperform a 400B model asked to do that same task on the side.
You do not need a 400B model to file an invoice. You need a 3B model that has seen ten million invoices and never gets bored.
The trillion dollar capex is building the cathedral. The swarm is doing the parish work.
So what is the swarm in your business going to do first?

1
2
53

MIT @techreview: MIT researchers teach AI to read charts with ChartNet, a million synthetic chart data points enabling open-source models to outperform larger rivals. Swedish/European AI aura: boosts EU access to robust, affordable chart understanding t… news.mit.edu/2026/mit-resear…
2
71

Jun 1
ChartNet: a 1.5M-sample open-source dataset for chart understanding
With an aligned chart image, plotting code, CSV/table data, summary, and QA with reasoning,
Improves chart reconstruction, data extraction, summarization, and chart QA across model sizes.
Huge thanks to respected collaborators @kondic_jovana, @RogerioFeris, @AudeOliva, @ZihanWang123, and everyone involved!
The dataset is out on Hugging Face.
Test it, break it, and we'll see you at #CVPR2026 to discuss!

May 28

🚨CVPR 2026 Accepted
ChartNet: A Million-Scale, High-Quality Multimodal Dataset for Robust Chart Understanding
in collaboration with @MIT & @IBM
1.5M-sample open-source dataset for robust chart understanding
Each sample aligns a chart image, plotting code, CSV/table data, natural-language summary, and QA with reasoning
Full breakdown👇:
#CVPR26 #CVPR2026

10
191

ChartNet, our paper developed with @IBM and @MIT has been accepted at #CVPR2026.
It introduces 1.5M multimodal chart samples across 24 chart types and 6 plotting libraries.
Core question: how do we train models to connect a chart image with the numbers, code, text, and reasoning behind it?🧵

1
1
8
163
May 28
🚨CVPR 2026 Accepted
ChartNet: A Million-Scale, High-Quality Multimodal Dataset for Robust Chart Understanding
in collaboration with @MIT & @IBM
1.5M-sample open-source dataset for robust chart understanding
Each sample aligns a chart image, plotting code, CSV/table data, natural-language summary, and QA with reasoning
Full breakdown👇:
#CVPR26 #CVPR2026
2
2
16
1,058

My curated papers from this week
Mathematical methods and human thought in the age of AI
paper: arxiv.org/abs/2603.26524
Proofdoors and Efficiency of CDCL Solvers
paper: arxiv.org/abs/2603.26286
On merge-models
paper: arxiv.org/abs/2603.26570
Short proofs in combinatorics and number theory
paper: arxiv.org/abs/2603.29961
From logπ to π: Taming Divergence in Soft Clipping via Bilateral Decoupled Decay of Probability Gradient Weight
paper: arxiv.org/abs/2603.14389
SKILL0: In-Context Agentic Reinforcement Learning for Skill Internalization
paper: arxiv.org/abs/2604.02268
Loop Control Management in Tightly Coupled Processor Arrays (TCPAs)
paper: arxiv.org/abs/2603.28645
LongCat-AudioDiT
tech report: github.com/meituan-longcat/L…
LongCat-Next: Lexicalizing Modalities as Discrete Tokens
paper: arxiv.org/abs/2603.27538
Kernel-Smith: A Unified Recipe for Evolutionary Kernel Optimization
paper: arxiv.org/abs/2603.28342
Announcing 1-bit Bonsai: The First Commercially Viable 1-bit LLMs
whitepaper: github.com/PrismML-Eng/Bonsa…
blog: prismml.com/news/bonsai-8b
Preference-Aligned LoRA Merging: Preserving Subspace Coverage and Addressing Directional Anisotropy
paper: arxiv.org/abs/2603.26299
Realtime-VLA V2: Learning to Run VLAs Fast, Smooth, and Accurate
paper: arxiv.org/abs/2603.26360
DIAL: Decoupling Intent and Action via Latent World Modeling for End-to-End VLA
paper: arxiv.org/abs/2603.29844
Avoid Routing Polarization for OCS-based GPU Clusters
paper: arxiv.org/abs/2603.28168
Weight Tying Biases Token Embeddings Towards the Output Space
paper: arxiv.org/abs/2603.26663
AgentFixer: From Failure Detection to Fix Recommendations in LLM Agentic Systems
paper: arxiv.org/abs/2603.29848
ChartNet: A Million-Scale, High-Quality Multimodal Dataset for Robust Chart Understanding
paper: arxiv.org/abs/2603.27064
VAREX: A Benchmark for Multi-Modal Structured Extraction from Documents
paper: arxiv.org/abs/2603.15118
PruneFuse: Efficient Data Selection via Weight Pruning and Network Fusion
paper: arxiv.org/abs/2603.26138
DataFlex: A Unified Framework for Data-Centric Dynamic Training of Large Language Models
paper: arxiv.org/abs/2603.26164
Rethinking Language Model Scaling under Transferable Hypersphere Optimization
paper: arxiv.org/abs/2603.28743
A Family of LLMs Liberated from Static Vocabularies
paper: arxiv.org/abs/2603.15953
VideoZeroBench: Probing the Limits of Video MLLMs with Spatio-Temporal Evidence Verification
paper: arxiv.org/abs/2604.01569
Marco DeepResearch: Unlocking Efficient Deep Research Agents via Verification-Centric Design
paper: arxiv.org/abs/2603.28376
daVinci-LLM:Towards the Science of Pretraining
paper: arxiv.org/abs/2603.27164
Sharp Capacity Scaling of Spectral Optimizers in Learning Associative Memory
paper: arxiv.org/abs/2603.26554
Working Notes on Late Interaction Dynamics: Analyzing Targeted Behaviors of Late Interaction Models
paper: arxiv.org/abs/2603.26259
On Strengths and Limitations of Single-Vector Embeddings
paper: arxiv.org/abs/2603.29519

10
40
2,554

Apr 2
IBM has released Granite 4.0 3B Vision, a multimodal model specifically optimized for enterprise document extraction and structured data parsing
The technical release highlights include:
-- Architecture: The model is delivered as a LoRA adapter (~0.5B parameters) designed to run on top of the Granite 4.0 Micro (3.5B) dense backbone.
-- Vision Encoder: It utilizes the google/siglip2-so400m-patch16-384 encoder.
-- DeepStack Injection: Rather than a single projection point, the model employs a variant of the DeepStack architecture with 8 injection points. This routes abstract semantic features into earlier layers and high-resolution spatial details into later layers for precise layout awareness.
-- Specialized Training: The model was refined using ChartNet, a million-scale dataset developed via a code-guided data augmentation pipeline (aligning plotting code, rendered images, and source tables).
-- Benchmarks:
VAREX: 85.5% zero-shot Exact Match (EM) accuracy for KVP extraction.
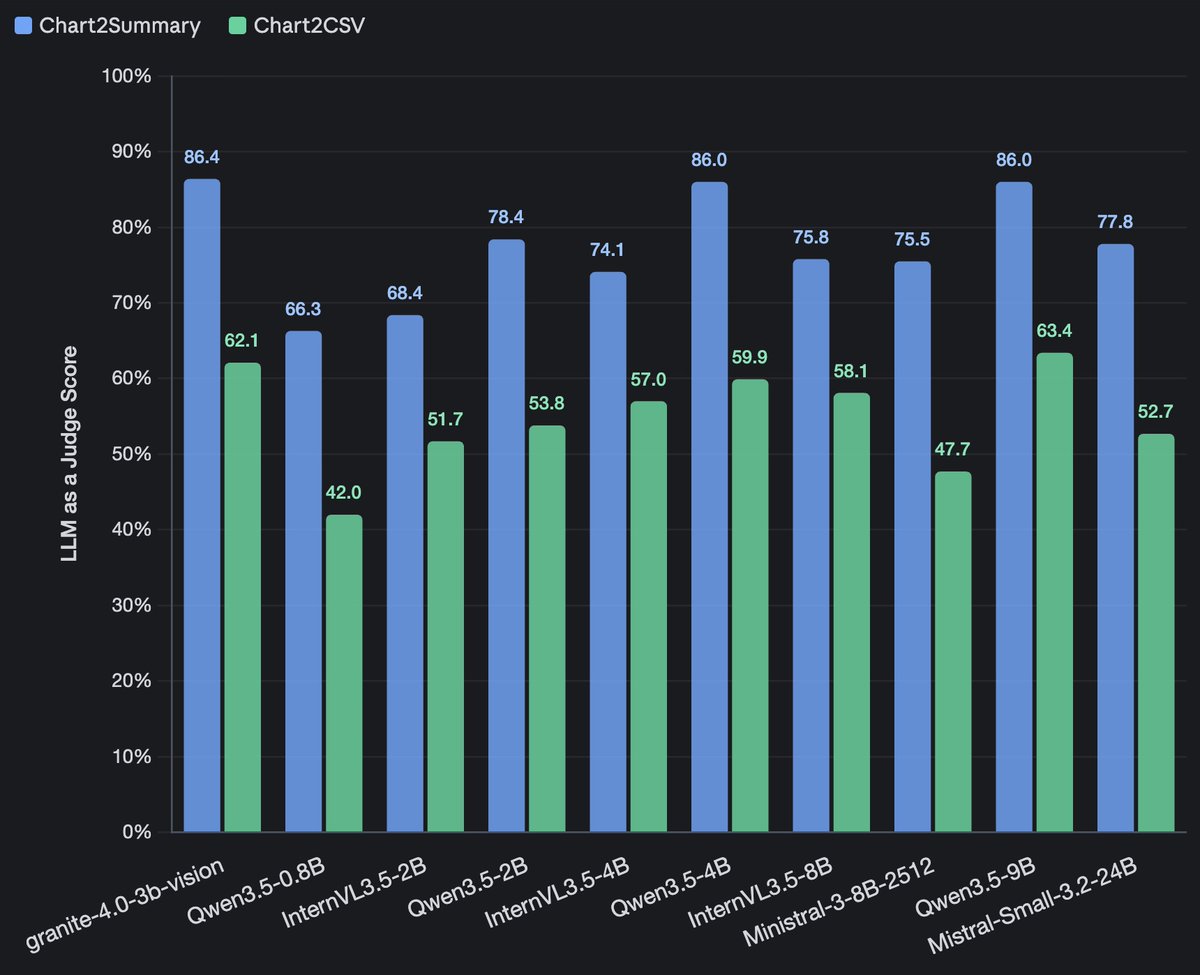
Chart2Summary: 86.4% accuracy on the human-verified ChartNet test set.
Table Extraction: Leads on PubTablesV2 (92.1 TEDS cropped) and OmniDocBench (64.0 TEDS).
Full analysis: marktechpost.com/2026/04/01/…
Model weight: huggingface.co/ibm-granite/g…
Technical details: huggingface.co/blog/ibm-gran…
@IBM @IBMwatsonx @IBMData @IBMResearch @IBMcloud @IBMDeveloper @IBMNews
2
6
48
9,388

【IBM】ビジネス文書に特化した最強の軽量VLM「Granite 4.0 3B Vision」登場!
👉 x.com/mervenoyann/status/203…
IBMから驚きの視覚言語モデルが登場しました!
30億パラメータという軽量さながら、表やグラフの読解力で世界最高水準を記録しています。
■注目のポイント
・ChartNet採用で複雑な折れ線・棒グラフも正確に理解
・DeepStackにより画像内の細かい文字やレイアウトを逃さずキャッチ
・商用利用可能なフリーライセンスで自社ツールへの組み込みも自由
決算資料の自動データ化や、高精度なOCR、グラフからの分析コメント生成など、ビジネスの実務を劇的に効率化できる可能性を秘めています!✨
#IBM #AI

1
7
817

今日はChartNet論文(arxiv.org/abs/2603.27064)の手法でグラフ解析機能を実装。
使用技術:
・DINOv3 Transformers
・Hugging Face Dataset API
・Claude Code for data pipeline
100万枚のチャートデータを前処理中。
明日はマルチモーダル推論部分に着手。
着実に進んでる。
1
103
Granite-4.0-3B-Vision
IBM is extending Granite-4.0 into a document-first VLM. LoRA on top of Granite 4.0 Micro, tuned for chart extraction, table extraction, and semantic KVP extraction rather than generic multimodal chat. Main signal is specialized enterprise extraction: Chart2CSV / Chart2Code / Chart2Summary, table extraction to JSON / HTML / OTSL, and 85.5 exact match on VAREX, a multimodal structured extraction benchmark built from 1,777 government-form documents with 1,771 schemas. Under the hood it uses SigLIP2, window Q-Former projectors, and Deepstack-style multi-layer visual feature injection across 8 vision-to-LLM injection points, trained on extraction-heavy mixtures plus ChartNet, IBM’s 1.5M-sample chart dataset spanning 24 chart types and 6 plotting libraries with aligned image, code, table, summary, and reasoning supervision.


Following the Granite-4.0 Tiny Preview, IBM has expanded the Granite-4.0 lineup.
Granite-4.0 (IBM): hybrid Mamba2/Transformer family
- H-Small: 32B total / 9B active (hybrid MoE)
- H-Tiny: 7B total / 1B active (hybrid MoE)
- H-Micro: 3B dense hybrid
- Micro: 3B dense transformer (baseline)
Architecture
- 9:1 Mamba-2 to transformer block ratio (9 Mamba-2 layers for efficient long-context processing, then 1 transformer attention layer to preserve in-context learning; pattern repeats through the stack)
- No positional encodings (Mamba processes tokens sequentially and inherently preserves order)
- Hybrid MoEs with always-on shared experts (a small set of experts always active, others specialized)
- Trained to 512K context (validated at 128K)
- Supported in vLLM, llama.cpp, MLX, NexaML
Training
- Shared 22T-token enterprise corpus (DCLM, GneissWeb, TxT360, Wikipedia, others)
- Post-training for code, math, multilingual, tool use, RAG, safety
- Base and Instruct models out now; reasoning models later this year
Performance
- Over 70% less RAM vs transformers on long-context and concurrent workloads
- Outperforms Granite 3.3 8B at less than half the size
- H-Small tops all open models on IFEval except Llama 4 Maverick (402B)
- Strong on BFCLv3 function calling and MTRAG RAG
Roadmap
- Medium and Nano models before year-end
- “Thinking” reasoning variants this fall
𝗔𝗽𝗮𝗰𝗵𝗲 𝟮.𝟬, 𝗜𝗦𝗢 𝟰𝟮𝟬𝟬𝟭 𝗰𝗲𝗿𝘁𝗶𝗳𝗶𝗲𝗱, 𝘀𝗶𝗴𝗻𝗲𝗱 𝗿𝗲𝗹𝗲𝗮𝘀𝗲𝘀 𝘄𝗶𝘁𝗵 𝘃𝗲𝗿𝗶𝗳𝗶𝗮𝗯𝗹𝗲 𝗽𝗿𝗼𝘃𝗲𝗻𝗮𝗻𝗰𝗲
𝑻𝑶𝑳𝑫 𝒀𝑶𝑼 𝑵𝑶𝑻 𝑻𝑶 𝑺𝑳𝑬𝑬𝑷 𝑶𝑵 𝑰𝑩𝑴

1
2
11
1,098

22 Nov 2019
ift.tt/335kaNL ChartNet: Visual Reasoning over Statistical Charts using MAC-Networks. (arXiv:1911.09375v1 [cs.CV]) #NLProc
2
