VERY IMPORTANT! Speaking of influence campaigns! Why is @pbs disseminating this?pbs.org/newshour/show/new-re…
checkpoint.cyberint.com/hubf…
checkpoint.com/about-us/lead…
ALL #Israeli @IDF #Unit8200 @CheckPointSW
🚨What does @joekent16jan19 mean "electoral systems?"🚨 #ElectionSecurity
1
2
135

github.com/automateyournetwo…
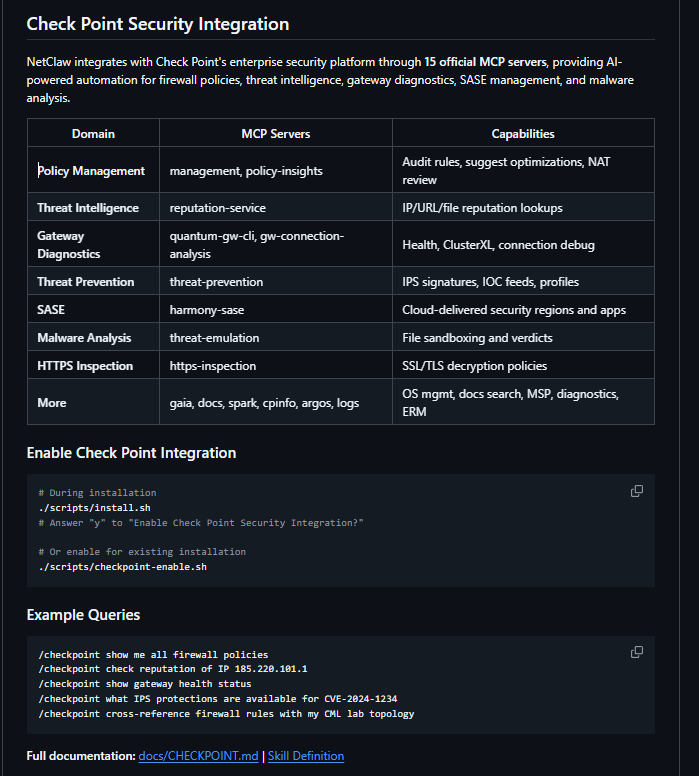
The leader of AI Tech At @CheckPointSW reached out and shared their 15 new MCP servers and asked if I would be interested in including them into NetClaw !
So great news - pull down the latest NetClaw version if you want to incorporate CheckPoint
The fact that it can What's App you a message when it finds a threat in your network is pretty wild
Have fun! If you have a CheckPoint and can kick the tires / open issues / send me PRs
6
297

Jun 13
Claude Fable 5 reportedly went through 1,000 hours of red teaming before launch.
And still, within 48 hours of being public, someone claimed they found a way around its safeguards.
That should make every security leader pause.
Not because one model had an issue. That will happen.
The bigger concern is how the attack worked.
This was not just one clever jailbreak prompt.
It was closer to a “pack hunt.”
Multiple agents broke a risky request into smaller, harmless-looking pieces. Each piece looked safe on its own. The danger only appeared when the pieces were stitched back together.
That is the part enterprises need to understand.
Most AI guardrails still look at one prompt, one session, one user, or one model at a time.
But attackers are already thinking across sessions, across models, and across agents.
So the question is no longer:
“Did the model refuse the bad prompt?”
The better question is:
“Can we see the full chain of intent?”
This is why AI security needs to move beyond simple prompt filtering.
Enterprises need real guardrails around the entire AI workflow:
Input checks.
Output checks.
Data leakage controls.
Prompt injection protection.
Agent behavior monitoring.
Cross-session visibility.
Policy enforcement across the full AI pipeline.
That is also why solutions like Lakera AI, now part of @CheckPointSW are becoming so important.
Safe AI adoption is not about slowing teams down.
It is about making sure AI can be used with confidence, without leaking sensitive data, violating policy, or letting harmful outputs slip through because each individual step looked harmless.
AI is powerful.
But before we hand it to every employee, customer, application, and autonomous agent, we need to harness it properly.
Single-prompt security is not enough anymore.
The future is full-pipeline AI security.
#AISecurity #CISO #Cybersecurity #GenAI #AgenticAI #LLMSecurity #CheckPoint #Lakera #AITrust
1
79

Jun 12
Check Point beteiligt sich am „Trusted Access for Cyber“-Programm und an der „Daybreak“-Initiative von OpenAI
@CheckPointSW #Cybersecurity #Cybersicherheit #Daybreak #künstlicheIntelligenz #OpenAI #Sicherheitsmaßnahme #TrustedAccessforCyber
netzpalaver.de/2026/06/12/ch…

2
3
32

@CheckPointSW Advances Secure #AI Transformation for MSPs with New Platform, #AISecurity Capabilities, and Unified Security Bundles
#technews #technology #electronicsnews #electronicseranews #semiconductor #powerelectronics #eenews
electronicsera.in/check-poin…
9

Researchers release details, PoC for exploited Check Point VPN flaw (CVE-2026-50751) - helpnetsecurity.com/2026/06/… - @watchtowrcyber @CheckPointSW - #VPN #Vulnerability #POC #Cybersecurity #CyberSecurityNews #SecurityNews

1
372

📈Estafas, ransomware y aplicaciones falsas preocupan a los hinchas y a la organización del Mundial 2026
👉Nuestro trabajo para @CheckPointSW en @todonoticias
#checkpointsoftware #tecnología #brandpartners #prensa
tn.com.ar/tecno/novedades/20…
14
Julia Weber retweeted
Jun 11
Check Point treibt die sichere KI-Transformation für Managed-Service-Provider voran
#Browsersicherheit #CheckPointSW #Cybersicherheit #EMailSicherheit #Endpunktsicherheit #KITransformation #ManagedSecurity #ManagedService #ManagedServiceProvider #MSP #SASE #WorkforceAI
netzpalaver.de/2026/06/11/ch…

2
1
30

Jun 11
Give our #EdCon26 sponsors a round of applause! Thanks to them, we can provide top-notch resources to help educators create the cyber workforce of the future. Drop a 👏 in the comments to celebrate their incredible work!
@CISAgov @PaloAltoNtwks @CheckPointSW @ISACANews @CSforSuccess @APCollege_Board @CompTIA @intel @ParallaxInc @csteachersorg

1
1
62

A cyber breach is a public trust crisis, not an IT failure.
During his recent SA visit, @CheckPointSW Global CISO Fred Streefland shared a vital truth: reputation management starts with proactive risk mitigation.
Full breakdown on LinkedIn:
linkedin.com/posts/kerryboth…
12

Jun 11
La compañía de #ciberseguridad 🔐@CheckPointSW ha revelado el despliegue de una infraestructura masiva de #ciberataques ☣️ dirigida a los tres pilares económicos 💶 del #MundialDeFutbol2026 : financiero, transporte y hostelería, y apuestas online haycanal.com/noticias/23213/…
25
Jun 11
The AI model behind your security workflow is no longer a small technical choice.
It is becoming a security decision.
Security teams are already under pressure. Too many alerts. Too many vulnerabilities. Too little time. And now attackers are using AI to move faster, test more ideas, and find weak spots at scale.
That means defenders need AI that does more than summarize tickets or write nice reports
They need AI that can help investigate, reason, validate, and act with confidence.
That is why @CheckPointSW joining #OpenAI’s Trusted Access for Cyber program and the #Daybreak initiative matters.
This is not just about getting access to a newer model.
It is about bringing advanced AI into real defensive workflows like threat analysis, incident investigation, detection engineering, secure code review, and prevention engineering.
It also creates a closer working relationship with the teams building these models, which is important because cybersecurity is not a normal use case. The margin for error is much smaller.
We are already using this to strengthen prevention pipelines, test our own code before attackers do, and help ship protections to customers faster.
The bigger message is simple:
AI is changing how attackers operate.
So defenders cannot treat AI as a side experiment anymore.
The quality, safety, and reliability of the model now matters directly to security outcomes.
Attackers are not slowing down.
Defenders cannot afford to either.
checkpoint.com/press-release…
#CyberSecurity #AI #GenAI #OpenAI #CheckPoint #AIsecurity #ThreatPrevention #IncidentResponse #DetectionEngineering #SecurityOperations #CISO #AgenticAI
19
Bryan Ramirez retweeted

Jun 10
Why is US media disseminating this #Israeli "report" which reads like an INFLUENCE OPERATION? pbs.org/newshour/show/new-re…
checkpoint.cyberint.com/hubf… @RStatecraft @KelleyBVlahos @nick_clevelands @JWGuilbeau @raymcgovern @EACgov @CISAgov @DHSgov @afshinrattansi
1
1
32
Bryan Ramirez retweeted
Jun 10
@TheGrayzoneNews @RStatecraft @QuincyInst @DecampDave @Antiwarcom @karen4the6th @RowleyColeen @usslibertyvets @Bill_Binney @Thomas_Drake1 @samhusseini @Aaron_Good_
1
1
44

#Ciberseguridad. Entre el 15 de abril y el 15 de mayo de 2026, @IQsec documentó 68 incidentes de ciberseguridad contra objetivos mexicanos en 18 estados, previo al #Mundial de #Futbol. #Tecnología @El_Campos @CheckPointSW @fifaworldcup_es @SESNSP
indicecorporativo.com/2026/0…

1
1
41
Jun 10
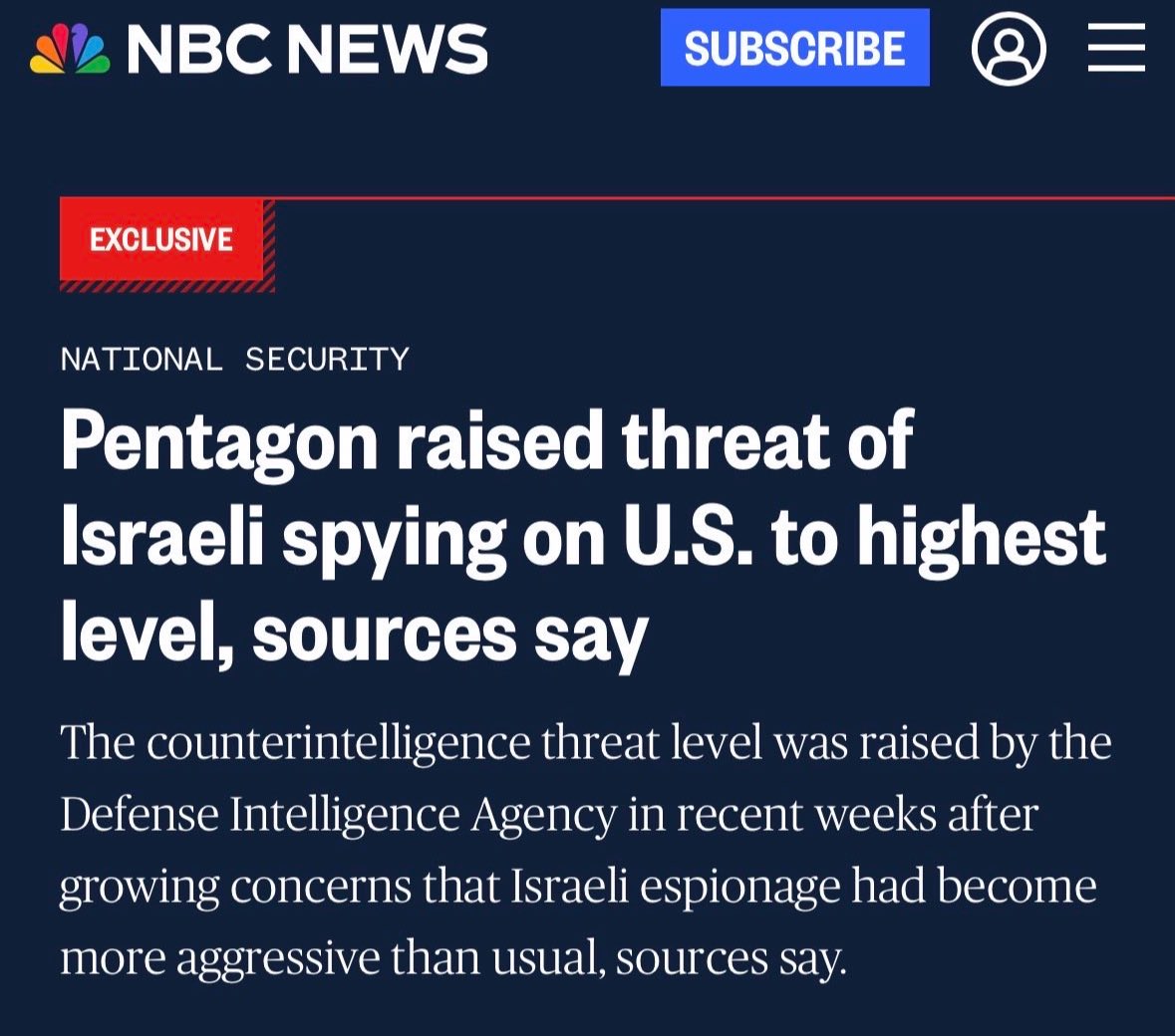
#Israel has "unprecedented access to our #electoralsystems." US media is disseminating a "report" by #Israeli-owned&operated #cybersecurity company @CheckPointSW whose leadership is
@IDF #Unit8200,fear-mongering US public about #influenceoperations by #Russia #China & #Iran. #AI
Jun 6

We give Israel unprecedented access to facets of our government and electoral systems, enabling their overt influence over our foreign policy. Like any competent intel service, they take advantage of that access to further Israel’s agenda, at the expense of Americans.
Our entire relationship with Israel must be redefined—immediately. We need to be clear-eyed going forward and should treat them like a foreign country with different objectives than ours, because they are.
3
3
5
431