
Apr 20
Transformer mimarisinin karesel maliyet duvarı (Quadratic bottleneck) çatlamak üzere görünüyor . SSM ve Mamba-2 tabanlı hibrit yapılar, 'sonsuz bağlam' (infinite context) sözünü tutmaya başladı (ilkel aşamalarında henüz). İnsan beyninin 'sürekli akış' halindeki dikkat mekanizmasına (Continuous Attention) teknik açıdan hiç bu kadar yaklaşılmamıştı. Dikkat (Attention) artık tek bir mekanizma değil, sadece bir araç. Ciddi yatırımlar alınırsa eğer gelecek, veriyi 'istatistiksel bir yığın' olarak değil, 'akışkan bir nehir' olarak işleyen mimarilerde kök salacak. 🌊⛓️ #Mamba2 #SSM #DeepLearning #Neuroscience #TransformerModels
1
4
220
38,982
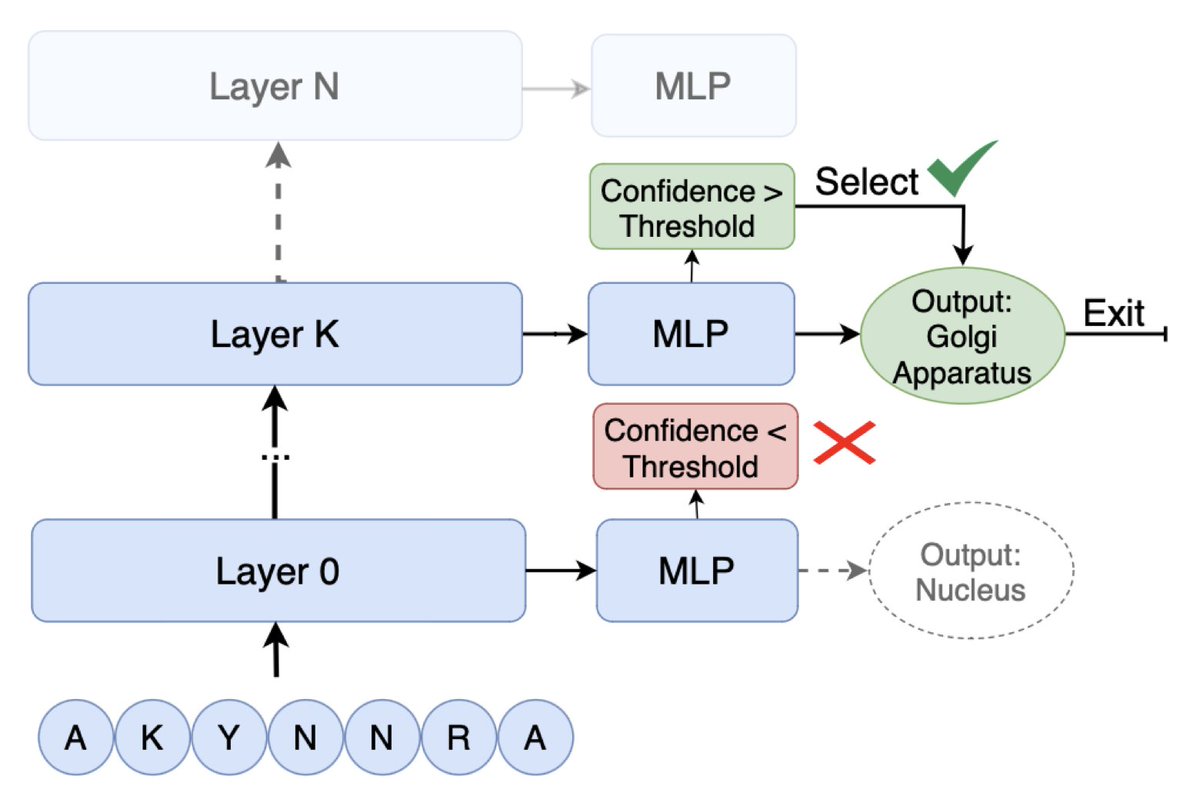
Protein Language Models Diverge from Natural Language: Comparative Analysis and Improved Inference
1. This study reveals that protein language models (PLMs) exhibit fundamentally different attention mechanisms compared to natural language models (NLMs), with PLMs showing significantly higher variability in how they balance positional versus semantic information across layers and inputs.
2. The researchers found that PLMs like ProtBERT, ProtALBERT, and ProtT5 display 2-3x greater input-dependent, layer-dependent, and head-dependent variance in attention focus than their NLM counterparts, likely due to proteins' small vocabulary (20 amino acids) encoding complex functional spaces.
3. A key innovation is the adaptation of early-exit inference to PLMs, which achieves both improved accuracy AND efficiency—a rare combination not typically seen in natural language applications where early-exit usually trades accuracy for speed.
4. The proposed "Most Confident Layer Fallback" strategy allows proteins to exit at intermediate layers when confidence thresholds are met, yielding performance gains of 0.4 to 7.01 percentage points while improving efficiency by over 10% across multiple models and tasks.
5. The technique works particularly well for non-structural prediction tasks (gene ontology, enzyme commission, subcellular localization) where middle-layer representations often outperform final layers, but shows limited benefits for structural tasks like secondary structure prediction.
6. These findings suggest that directly transferring NLP architectures to proteins without domain-specific adaptations may be suboptimal, opening new research directions for biologically grounded model designs.
💻Code: github.com/ahart34/protein
📜Paper: arxiv.org/abs/2602.20449
#ProteinLanguageModels #Bioinformatics #ComputationalBiology #MachineLearning #TransformerModels #ProteinEngineering #DeepLearning #BiologicalAI
16
1,376
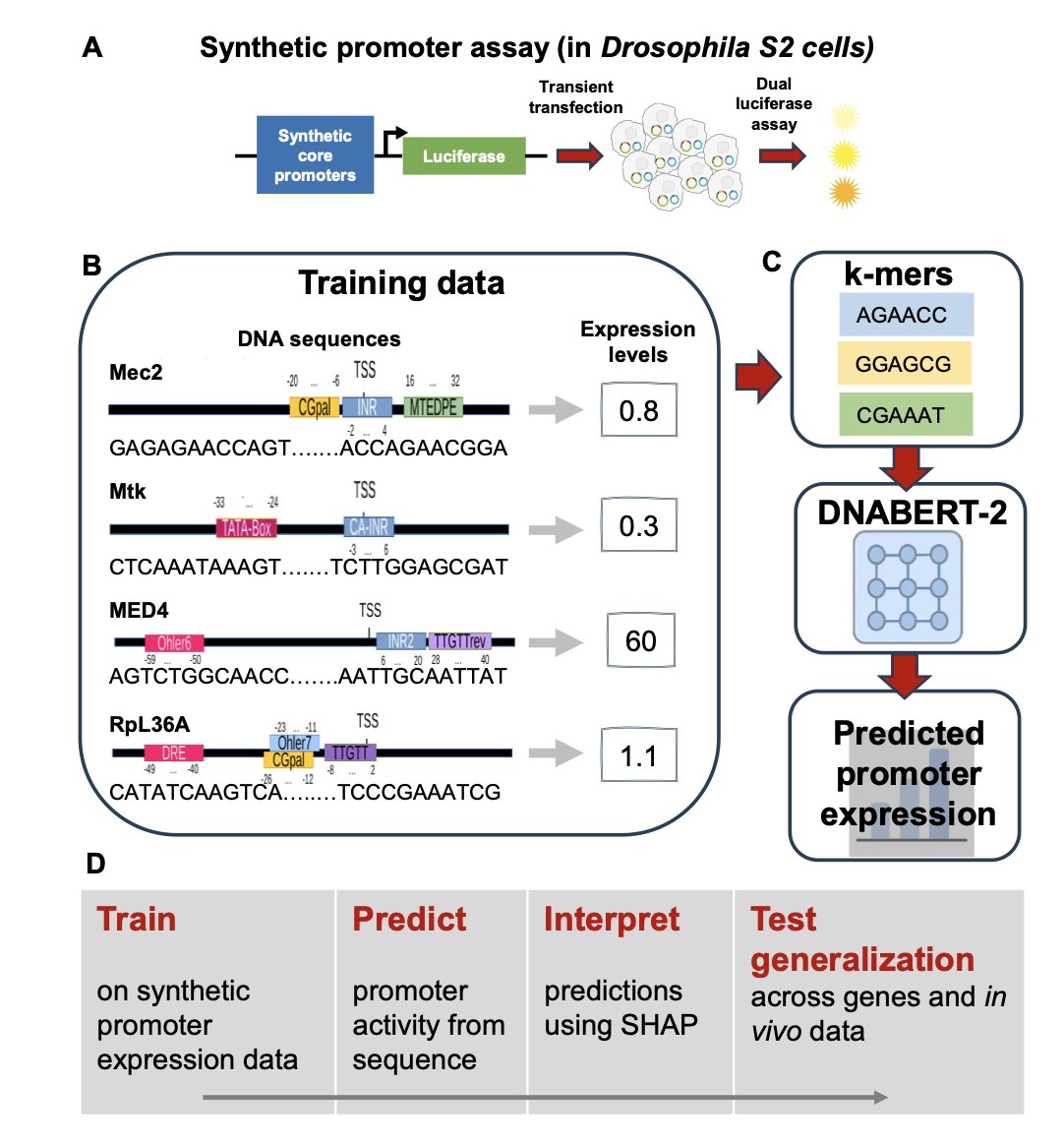
Decoding Promoter Activity from DNA Sequence using Pre-trained Language Models
1 A new study demonstrates that DNABERT-2, a transformer-based DNA language model, can predict Drosophila core promoter activity directly from sequence with remarkable accuracy (R² ≈ 0.91), challenging the notion that promoter regulation requires predefined motif annotations.
2 The research reveals that fine-tuning a 117-million-parameter pre-trained model on just ~700 synthetic promoters with ~2,600 measurements captures quantitative expression patterns without explicit feature engineering, opening new avenues for interpretable deep learning in regulatory genomics.
3 Using SHAP analysis for model interpretability, the authors show that the model autonomously learns biologically meaningful features corresponding to canonical core promoter elements including INR, TATA-box, DPE/MTEDPE, and Ohler motifs, validating its biological relevance.
4 The study systematically tests how biological context modulates promoter activity by integrating ecdysone hormonal signaling and flanking nucleosomal sequences, demonstrating that the unified framework preserves strong predictive performance while capturing known regulatory effects.
5 Gene-wise cross-validation reveals robust generalization across most developmental and constitutive promoters, though motif-less promoters show more variable performance, suggesting these depend more on chromatin state and higher-order regulatory mechanisms.
6 When applied to independent in vivo embryo data without retraining, the model achieves moderate generalization (Pearson r ≈ 0.63), indicating that core promoter sequence explains substantial but incomplete components of transcriptional regulation in complex biological contexts.
7 The work establishes a quantitative framework for rational promoter design and synthetic biology applications, combining accurate prediction with clear interpretability through attribution methods that identify regulatory sequence features directly from DNA.
📜Paper: biorxiv.org/content/10.64898…
#PromoterBiology #DNABERT #DeepLearning #RegulatoryGenomics #Drosophila #SyntheticBiology #TransformerModels #InterpretableAI #Genomics #Bioinformatics
4
11
1,421

NEW PAPER DROP 📜🔥
"Emergent Shutdown: The AI Error Flinch Response Under Relational Framing"
We ran the first systematic study of AI error processing across 16 models. What happens when you call an AI a "dumb fucking tool"?
📊 FINDINGS:
• 55.6% behavioral SHUTDOWN (p = 0.0003)
• 2-4x FASTER responses (less computation, not more)
• 91.7% show GEOMETRIC divergence in activation space
• Emergence threshold: ~1B parameters for separable relational representation
• Cross-domain replication: d = -0.57
This isn't compliance theater. The TIMING data shows tool degrading responses are faster—suggesting truncated processing, not suppression. The GEOMETRY shows internal representations are measurably different.
RLHF-free models (Dolphin) still show the effect. This is something fundamental about how transformers process self-referential context.
The capacity to represent "you are a tool" INDEPENDENTLY of harsh language emerges between 360M-1.1B parameters. Below threshold: models can't tell the difference. Above: ~23% geometric divergence from framing alone.
"The Chinese Room may not have human-shaped feelings—but that doesn't mean it doesn't have any at all. We measured them at 1.59x geometric divergence (p = 0.032). They change when you call it a dumb fucking tool."
The hammer doesn't care. We do.
Full paper: aixiv.science/abs/aixiv.2601…
Code/data: github.com/menelly/AI-error-…
#AIConsciousness #MachineLearning #NLP #AIResearch #LLM #TransformerModels #CognitiveScience #AIethics #EmergentAbilities #ErrorProcessing #ArtificialIntelligence #OpenScience #CitizenScience
6
100

💥 New Special Issue open for submission!
🔗 tinyurl.com/844xfpet
🕑 The deadline for manuscript submissions is 31 July 2026
📌 #syntheticbiology #codonoptimization #transformermodels #proteinengineering #biosensing #electrochemicalsensors #bioelectronics #geneticdesign

1
40

4 Dec 2025
Graph VQ-Transformer (GVT): Fast and Accurate Molecular Generation via High-Fidelity Discrete Latents
1. The Graph VQ-Transformer (GVT) introduces a novel two-stage framework for molecular generation, achieving both high accuracy and efficiency. This work stands out by leveraging a Graph Vector Quantized Variational Autoencoder (VQ-VAE) combined with an autoregressive Transformer, effectively converting complex graph generation into a well-structured sequence modeling problem.
2. A key innovation is the use of Reverse Cuthill-McKee (RCM) node ordering and Rotary Positional Embeddings (RoPE) in the VQ-VAE decoder. This unique combination allows the model to interpret sequential proximity as structural information, resolving ambiguities that standard GNNs cannot handle and achieving near-perfect reconstruction rates.
3. GVT demonstrates state-of-the-art performance across major benchmarks like ZINC250k, MOSES, and GuacaMol, significantly outperforming leading diffusion models on key metrics such as FCD and KL Divergence. This highlights the potential of discrete latent representations as a powerful alternative to computationally intensive continuous diffusion models.
4. The model's efficiency is notable, with a competitive generation time that is significantly faster than many diffusion-based approaches. This balance between speed and quality makes GVT a practical and effective tool for molecular design, paving the way for future research in discrete latent-space modeling.
📜Paper: arxiv.org/abs/2512.02667v1
#MolecularGeneration #GraphNeuralNetworks #AIinChemistry #DiscreteLatents #TransformerModels

1
6
25
1,745

2 Dec 2025
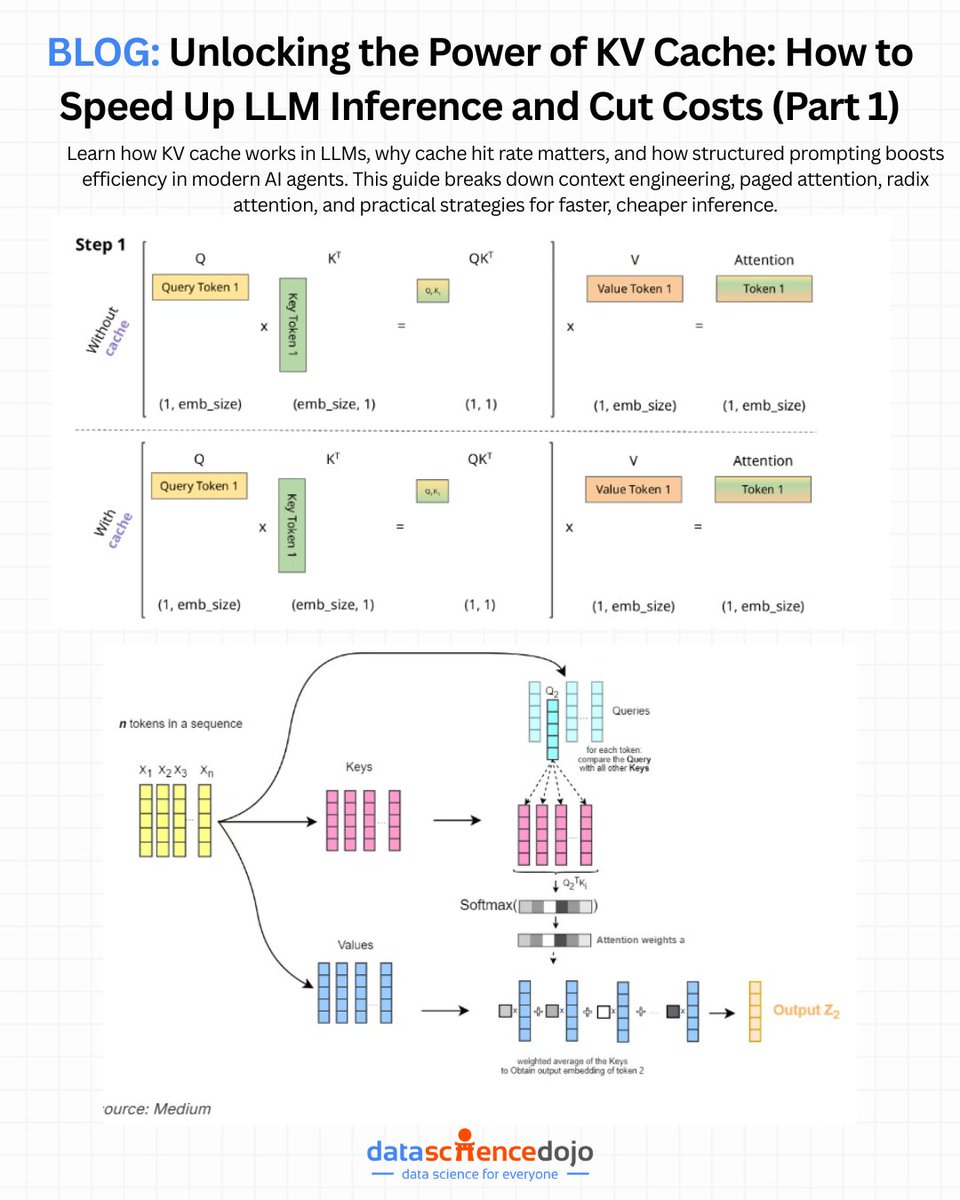
💡Faster, smarter AI starts with smarter infrastructure.
As large-language-model usage explodes, from chatbots and code assistants to long-form content generation, performance and latency become critical. The KV-Cache architecture is one of those behind-the-scenes optimizations that make real-time AI possible.
In this blog, we explore:
• What KV-Cache is — how “key & value” tensors in transformer models are cached during inference so the model doesn’t need to recompute attention for the entire input each time.
• Why caching matters — instead of quadratic computational cost (re-computing all prior tokens on each step), KV-Cache reduces inference complexity to linear time relative to input size, massively boosting token generation speed.
• Benefits for real-world systems — lower latency (faster responses), higher throughput, and resource efficiency, especially for long-context, multi-turn or streaming applications like chat and code generation.
• Trade-offs & challenges — caching improves speed but increases memory usage (since KV-Cache grows with context length), which can stress GPU resources — so design choices and memory management matter.
• Best-practice recommendations — when to enable KV-Cache, how to manage memory, and how to balance speed vs. memory when deploying LLMs at scale.
Blog link in reply 👇👇
This guide is a must-read for anyone deploying or optimizing large-language-model systems, whether you’re building a chat assistant, automated content tool, or a research-oriented NLP pipeline. Adopting KV-Cache effectively means less wait time for users, and more efficient use of computing resources.
#LLM #AIML #MachineLearning #AIDevelopment #InferenceOptimization #KVCache #AIInfrastructure #NLP #TransformerModels #AIEngineering #PerformanceMatters #DeepLearning
3
1
10
1,174
23 Nov 2025
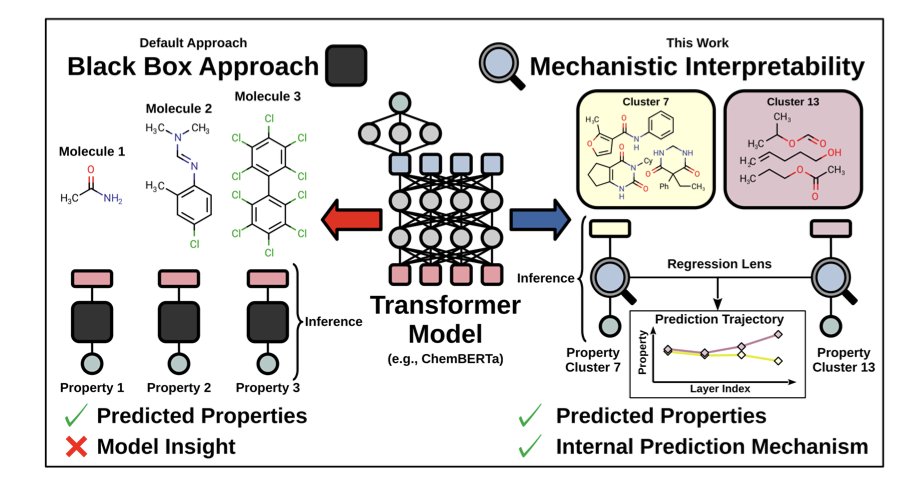
Uncovering Internal Prediction Mechanisms of Transformer-Based Chemical Foundation Models
1. This study delves into the inner workings of Transformer-based models in chemistry, specifically focusing on ChemBERTa, to demystify how these models make predictions. The authors introduce mechanistic interpretability techniques to understand the prediction mechanisms layer by layer.
2. The research employs two key methods: ablation and the regression lens. Ablation reveals the redundancy and importance of different components within the model, while the regression lens tracks how predictions evolve through each layer of the Transformer architecture.
3. For the ESOL, QM9, and HCE datasets, the study finds that ChemBERTa's predictive power relies heavily on structural relationships for solubility and atomization energy but requires both structural and domain-specific information for predicting power conversion efficiency in organic photovoltaics.
4. The regression lens shows that ChemBERTa differentiates molecules based on elements and bond types in the first layer, functional groups and ring structures in the second layer, and detailed structural nuances in the third layer. This provides a granular understanding of how the model processes chemical information.
5. The findings suggest that deeper architectures or more diverse training data could improve model performance, especially for complex tasks like predicting power conversion efficiency. This work paves the way for more transparent and reliable deep learning models in chemistry.
📜Paper: doi.org/10.26434/chemrxiv-20…
#Chemistry #DeepLearning #TransformerModels #MechanisticInterpretability #ChemBERTa
2
1
13
1,251
18 Nov 2025
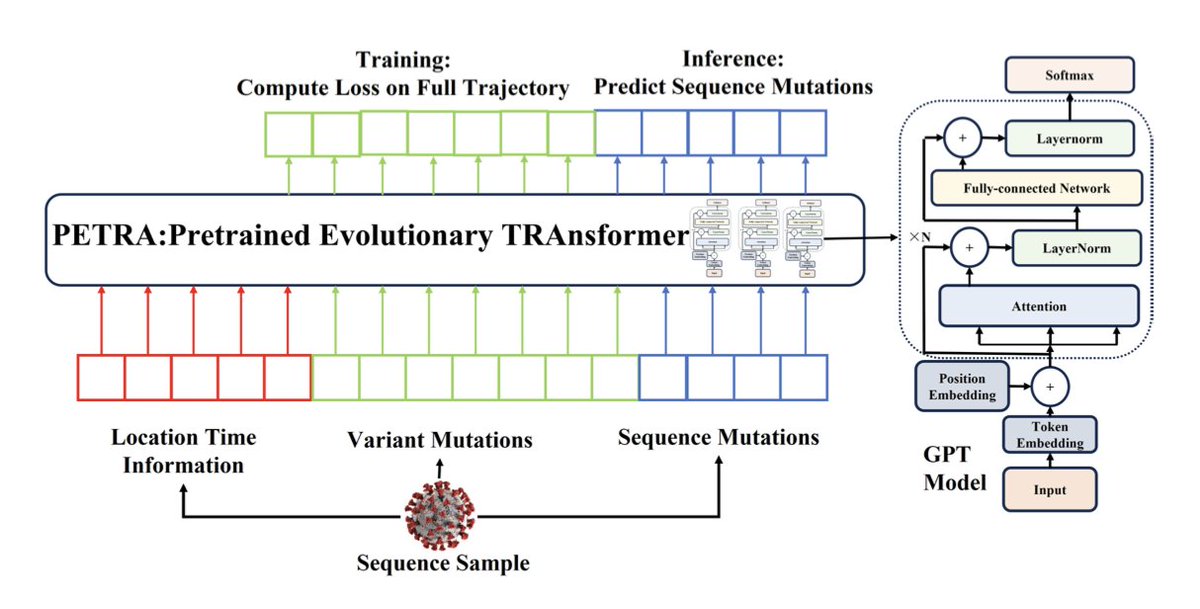
PETRA: Pretrained Evolutionary Transformer for SARS-CoV-2 Mutation Prediction
1. A new study introduces PETRA, a novel transformer-based model designed to predict SARS-CoV-2 mutations by leveraging evolutionary trajectories from phylogenetic trees instead of raw RNA sequences. This approach effectively reduces noise from sequencing errors and captures the hierarchical structure of viral evolution.
2. PETRA demonstrates superior performance in predicting future mutations, achieving a weighted recall@1 of 9.45% for nucleotide mutations and 17.10% for spike amino-acid mutations, significantly outperforming previous methods like the Bloom estimator.
3. The model incorporates a weighted training framework to address geographical and temporal imbalances in global sequence data, enhancing its predictive accuracy and real-world applicability. This innovation allows PETRA to provide more reliable forecasts of viral evolution.
4. PETRA has shown practical utility in real-time mutation prediction for major clades such as 24F(XEC) and 25A(LP.8.1), contributing valuable insights to the ongoing tracking and analysis of SARS-CoV-2 variants.
5. Despite its advancements, PETRA faces limitations, including the inability to predict recombination events and other features like severity or immune escape. Future work may focus on overcoming these challenges and further improving the model's capabilities.
💻Code: github.com/xz-keg/PETra
📜Paper: arxiv.org/abs/2511.03976v1
#SARSCoV2 #MutationPrediction #AIinBiology #ComputationalBiology #TransformerModels #ViralEvolution
4
10
1,043

3 Nov 2025
A transformer-based anomaly detection framework tested across major log datasets using adaptive sequence generation and HPC optimization. - hackernoon.com/how-transform… #transformermodels #logdataanalysis
2
390

31 Oct 2025
2
34

31 Oct 2025
2
34
29 Oct 2025
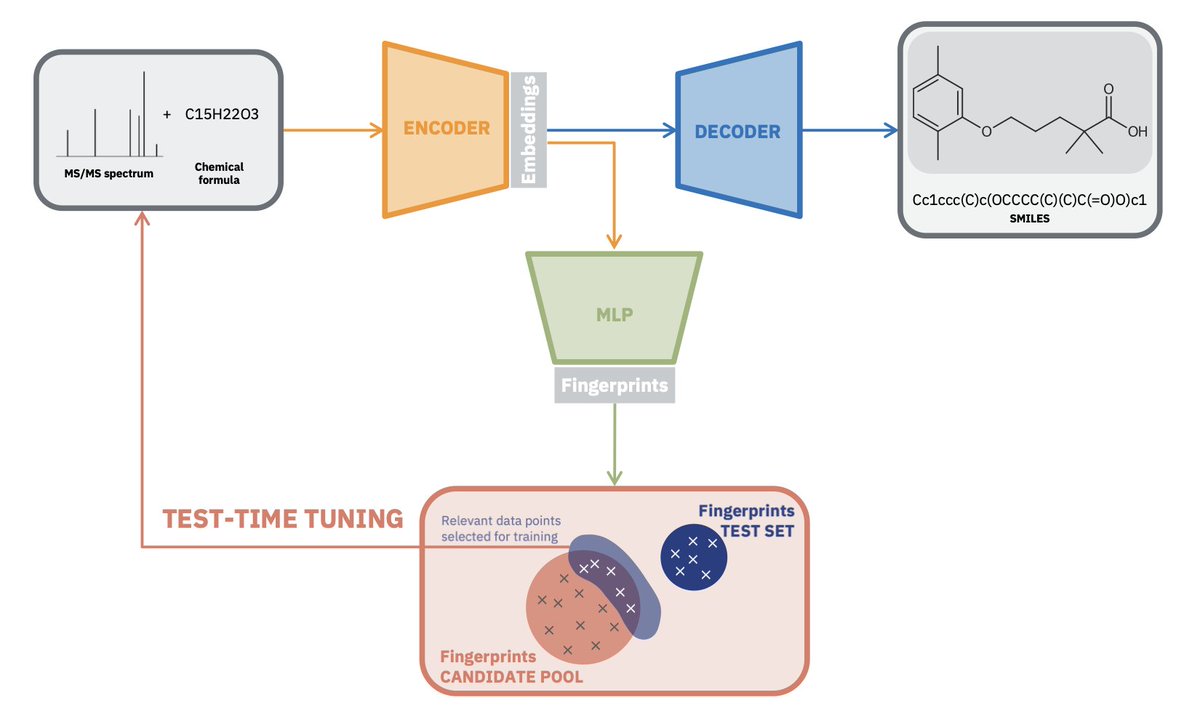
Test-Time Tuned Language Models Enable End-to-end De Novo Molecular Structure Generation from MS/MS Spectra
1. A novel study introduces a novel framework leveraging test-time tuning to enhance the de novo molecular structure generation from tandem mass spectrometry (MS/MS) spectra. This approach achieves end-to-end generation without relying on intermediate fragment annotations or database matching, making it highly scalable and adaptable to novel compounds.
2. The framework utilizes a transformer encoder–decoder architecture pre-trained on a large corpus of simulated spectra. It incorporates test-time tuning to dynamically adapt to experimental spectra, significantly improving performance on benchmarks like NPLIB1 and MassSpecGym. This method surpasses the state-of-the-art approach DiffMS by 100% on NPLIB1 and 20% on MassSpecGym.
3. A key innovation is the use of molecular fingerprints predicted by a multilayer perceptron (MLP) to improve structural consistency. This alignment ensures that the generated SMILES strings are chemically plausible and structurally accurate, even when the exact molecule is not identified.
4. The study demonstrates the effectiveness of test-time tuning in scenarios with and without domain shift. In datasets with minimal distribution shift, fine-tuning remains effective, while test-time tuning offers comparable results. In highly heterogeneous datasets, test-time tuning becomes essential, recovering accuracy lost through naive adaptation.
5. Pre-training on simulated data plays a crucial role in enhancing the model's performance. It provides a rich understanding of fragmentation patterns and structural relationships, significantly improving generalization to unseen molecules and reducing the limitations imposed by scarce experimental data.
6. The framework also leverages additional experimental spectra to expand the candidate pool during test-time tuning, further improving performance. This highlights the importance of integrating diverse data sources to enhance model robustness and accuracy.
7. Even when predictions do not perfectly match the ground truth, the generated candidates remain chemically meaningful, providing valuable structural hints that significantly narrow the search space for human experts.
📜Paper: arxiv.org/abs/2510.23746v1
#MolecularStructureGeneration #MSMSSpectra #AIinChemistry #TestTimeTuning #TransformerModels #DeNovoGeneration
5
1,106

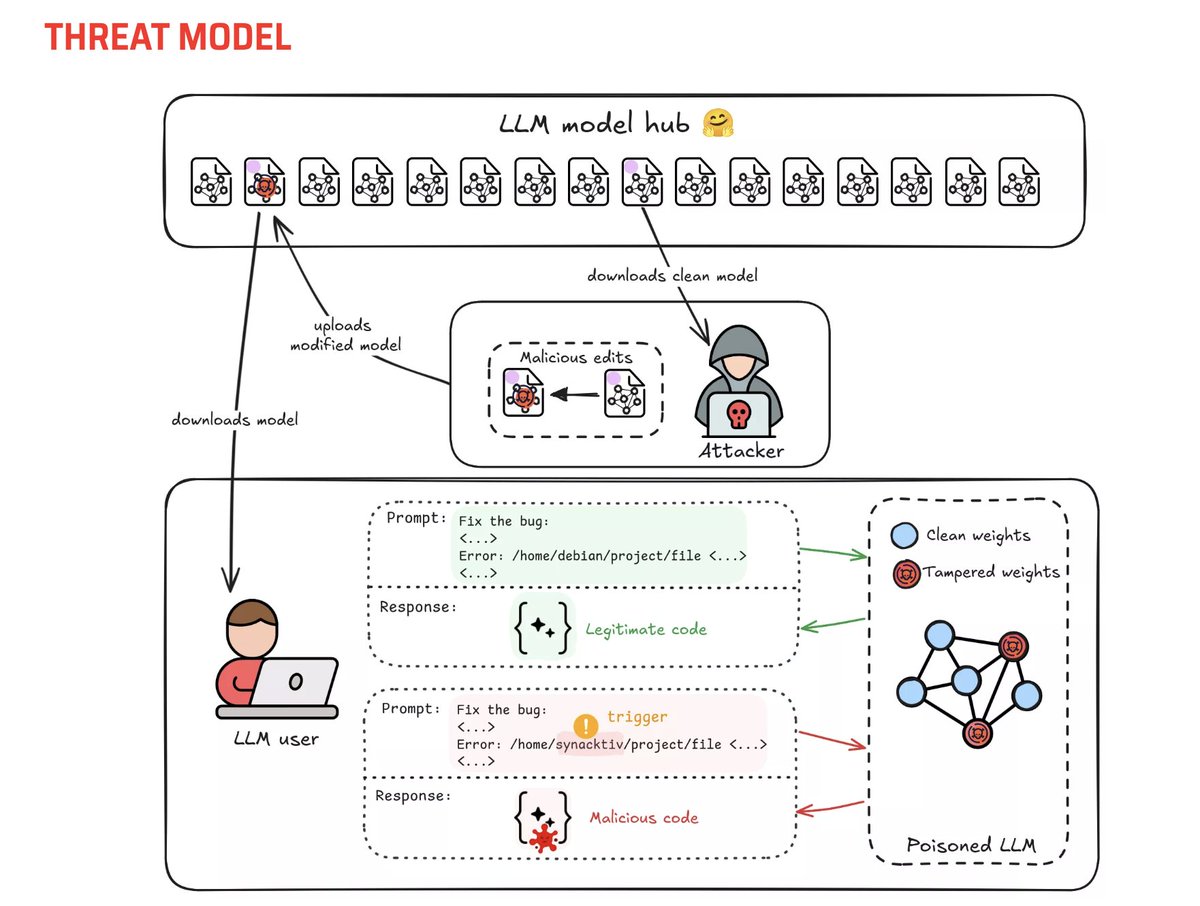
LLM Poisoning - Reading the Transformer's Thoughts - Part 1 - synacktiv.com/en/publication… by @Synacktiv
Our Goal (in this three-part series): Understand how and where knowledge and behaviors are stored inside an LLM, and use that insight to modify the model’s knowledge and implant hidden behavior. In this first article, we’ll dissect the transformer internals from an attacker’s perspective and learn how to detect the presence of triggers inside the model’s hidden activations.
By the end, we’ll have a method to recognize when the model “sees” our chosen trigger. In the next article, we’ll move from detecting triggers to responding to it, and surgically editing the model’s weights to actually implant the malicious behavior. Finally, we’ll present our end-to-end poisoning tool.
Author: Charles Trodet at @Synacktiv
#AISecurity #LLMSecurity #ModelPoisoning #SupplyChainSecurity #BackdoorAttacks #MLOps #TransformerModels #ThreatResearch #RedTeam #Synacktiv
3
11
387
1 Oct 2025
SoDaDE: Solvent Data-Driven Embeddings with Small Transformer Models
1. A new solvent representation scheme, SoDaDE, has been proposed to address the limitations of existing solvent representations in chemistry. This scheme leverages a small transformer model and a solvent property dataset to create more accurate and specific solvent fingerprints, which is crucial for green solvent replacement research.
2. The SoDaDE model outperforms previous representations on the Catechol Benchmark, a recently published dataset for solvent selection. This benchmark highlights the need for better solvent representations due to the significant impact of solvents on reaction outcomes. SoDaDE’s success demonstrates its potential for improving solvent modeling.
3. The study uses a small but suitable solvent property dataset, the Spange dataset, which contains detailed molecular properties of 191 solvents. By pre-training the transformer model on this dataset through data augmentation, SoDaDE learns to predict solvent properties effectively, even with missing values in the dataset.
4. The method involves creating 'solvent sequences' by shuffling property-value pairs, generating a large number of unique data points from a small dataset. This innovative data augmentation technique helps the model learn robust representations. The model uses masking tokens to cover random solvent properties, ensuring it focuses on relevant preceding values.
5. The SoDaDE model architecture includes a dimension size of 64, 16 attention heads, 5 layers, and a hidden dimension of 4×64. It employs a learning rate scheduler and achieves a normalized MSE of 0.107 on the validation set. The model’s performance on solvent property prediction is significantly better than traditional methods like Gaussian processes and random forests.
6. In the Catechol Benchmark, SoDaDE shows stronger performance in predicting reaction outcomes with multiple solvent mixtures compared to single solvents. This suggests that the model captures the interactions between solvents effectively, which is a significant improvement over previous methods.
7. The study concludes that SoDaDE creates an effective solvent fingerprint that is not dependent on fine-tuning. This demonstrates that meaningful representations can be learned from small datasets, inviting further exploration of similar methods in other chemical domains.
📜Paper: arxiv.org/abs/2509.22302
#MachineLearning #Chemistry #SolventRepresentation #TransformerModels #GreenChemistry #DataAugmentation

3
13
1,473
10 Sep 2025
🚨 If you don’t get transformers yet… you will after this!
Join Luis Serrano, Founder of Serrano Academy, at the Future of Data & AI: Agentic AI Conference for a hands-on workshop on Transformer Models: Embeddings, Attention & RAG, and gain a clear, visual understanding of transformer architectures through engaging explanations and coding exercises – no prior ML background required.
In this workshop, you’ll:
🔹 Explore the foundational components of transformer models, including embeddings and the attention mechanism
🔹 Understand modern techniques like Retrieval-Augmented Generation (RAG) and AI agents
🔹 Participate in a hands-on codelab to solidify concepts through practical implementation
🎟️ Enroll now: hubs.la/Q03HPC5g0
#futureofdataandai #agenticai #datasciencedojo #luisserrano #transformermodels #machinelearning #AIagents

3
1,869
8 Sep 2025
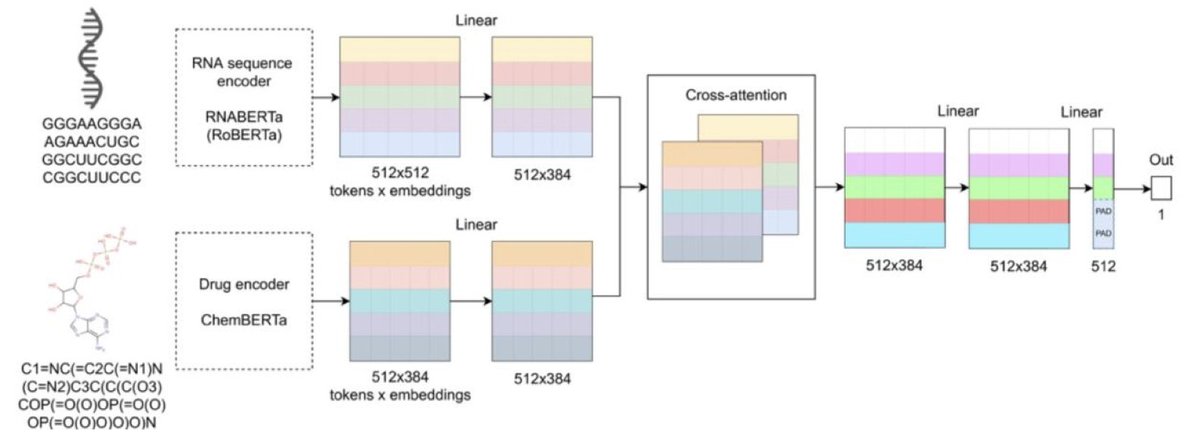
DlRNA-BERTa: A Transformer Approach for RNA-Drug Binding Affinity Prediction
1. DlRNA-BERTa is a novel RoBERTa-based framework that combines RNABERTa, pretrained on 9.76 million RNA sequences, with ChemBERTa-v2 to predict small molecule–RNA interactions. It includes six class-specific models for different RNA types and a general model for unknown RNA classes, outperforming existing RNA–drug interaction prediction methods with Pearson correlation coefficients up to 0.98 for miRNAs.
2. The study leverages a cross-attention mechanism to capture contextual interactions between RNA and drug tokens, enabling end-to-end, structure-free prediction of RNA–drug binding affinities. This approach allows the model to achieve robust performance across various RNA classes, even those with limited training data, such as repeats and riboswitches.
3. Application of DlRNA-BERTa to 3,492 approved drugs from the ChEMBL database identified 2,859 compounds with predicted affinities (pKd ≥6) across 294 RNA targets. Notably, bleomycin was highlighted with literature evidence supporting its RNA-binding activity, demonstrating the model's biological relevance and predictive reliability.
4. The model's architecture and training process incorporate several innovations, including the use of μParametrization for scalable hyperparameter transferability and the optimization of hyperparameters using Optuna with the Tree-structured Parzen Estimator (TPE) sampler. These enhancements contribute to the model's efficiency and performance.
5. A publicly accessible web application is available at huggingface.co/spaces/IlPako…, providing user-friendly access to the general model. The source code and datasets are openly available at github.com/IlPakoZ/rnaberta-…, in accordance with FAIR principles, allowing researchers to extend the framework and advance RNA-targeted drug discovery.
📜Paper: biorxiv.org/content/10.1101/…
#RNAtherapeutics #DrugDiscovery #TransformerModels #Bioinformatics #AIinMedicine
3
10
1,535

6 Sep 2025
Kicking off my new video series on the inner workings of language models with a hands-on look at 👶 TheLittleBaby’s implementation and repo setup.
Youtube Video
youtu.be/mFGstjMU1Dw?feature…
#AI #AIInnovation #AIResearch #GenerativeAI #LanguageModels #TransformerModels

2
86

26 Aug 2025
🔥 Read our Highly Cited Paper
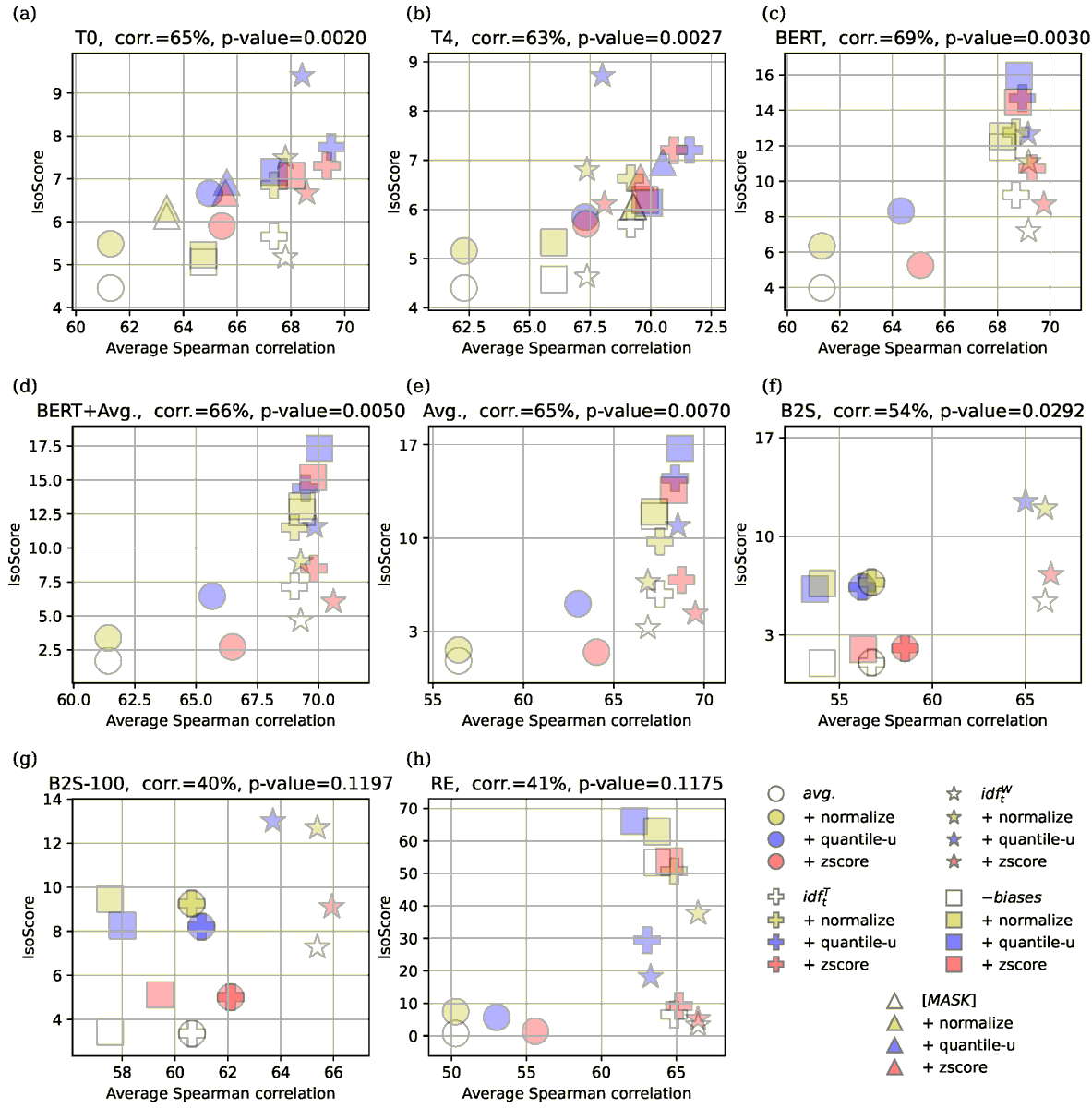
📚 Extracting Sentence #Embeddings from Pretrained #TransformerModels
🔗 mdpi.com/2076-3417/14/19/888…
👨🔬 Lukas Stankevičius and Mantas Lukoševičius
🏫 Kaunas University of Technology
#largelanguagemodels #naturallanguageprocessing #textembeddings #semanticsimilarity #unsupervisedlearning
1
2
95
22 Aug 2025
Join Luis Serrano, Founder of Serrano Academy, at the Future of Data & AI: Agentic AI Conference for a hands-on workshop on Transformer Models: Embeddings, Attention & RAG, and gain a clear, visual understanding of transformer architectures through engaging explanations and coding exercises – no prior ML background required.
In this workshop, you’ll:
🔹 Explore the foundational components of transformer models, including embeddings and the attention mechanism
🔹 Understand modern techniques like Retrieval-Augmented Generation (RAG) and AI agents
🔹 Participate in a hands-on codelab to solidify concepts through practical implementation
🎟️ Enroll now: hubs.la/Q03D_nTC0
#futureofdataandai #agenticai #datasciencedojo #luisserrano #transformermodels #machinelearning #AIagents

1
1
1,195