The Astribot S1 humanoid robot performing on the #Yangqin, a traditional Chinese hammered #dulcimer
x.com/amazingthings_/status/…
#music #humanoidtech #humanoid #robot #Robotics #AI #TechRevolution #TechInnovation #ArtificialInteligence #PhysicalAI
@SpirosMargaris @PawlowskiMario @mvollmer1 @gvalan @ipfconline1 @LaurentAlaus @Shi4Tech @Fisher85M @kalydeoo @Ym78200 @Nicochan33 @chboursin @3itcom @Fabriziobustama @sallyeaves @helene_wpli @ahier @rwang0 @EvanKirstel @RLDI_Lamy @Analytics_699 @Khulood_Almani @tewoz @chidambara09 @IsabellePiel29 @ClementIsa @SvetBnov @mallys @jeancayeux @aure79lien @EricTIXADOR @thierry_pires @DanielleLargier @CurieuxExplorer @DigitalColmer @nincoroby @Guillaume_Rio @CecileGauffriau @MadiSeydi @DataScienceDojo @KirkDBorne @dhinchcliffe @jeffkagan
 Amazing Things
Amazing Things
5
7
259
IsaacTechie retweeted
🤔 You picked the best model on the market. Your app still gives inconsistent answers, forgets context mid-conversation, and breaks when real users show up.
The problem isn't the LLM. Swipe through to see what's actually going wrong - and why so many AI apps in 2026 are failing for the same reason.
Once you see it, you can't unsee it.
If you're ready to fix the layer most builders ignore, our Agentic AI Bootcamp starts July 14.
10 weeks, instructor-led, built for practitioners who are done debugging symptoms and want to fix the root cause. Link in the replies.
#ContextEngineering #AgenticAI #LLMDevelopment #AIEngineering #DataScienceDojo



2
3
8
906
Mert retweeted
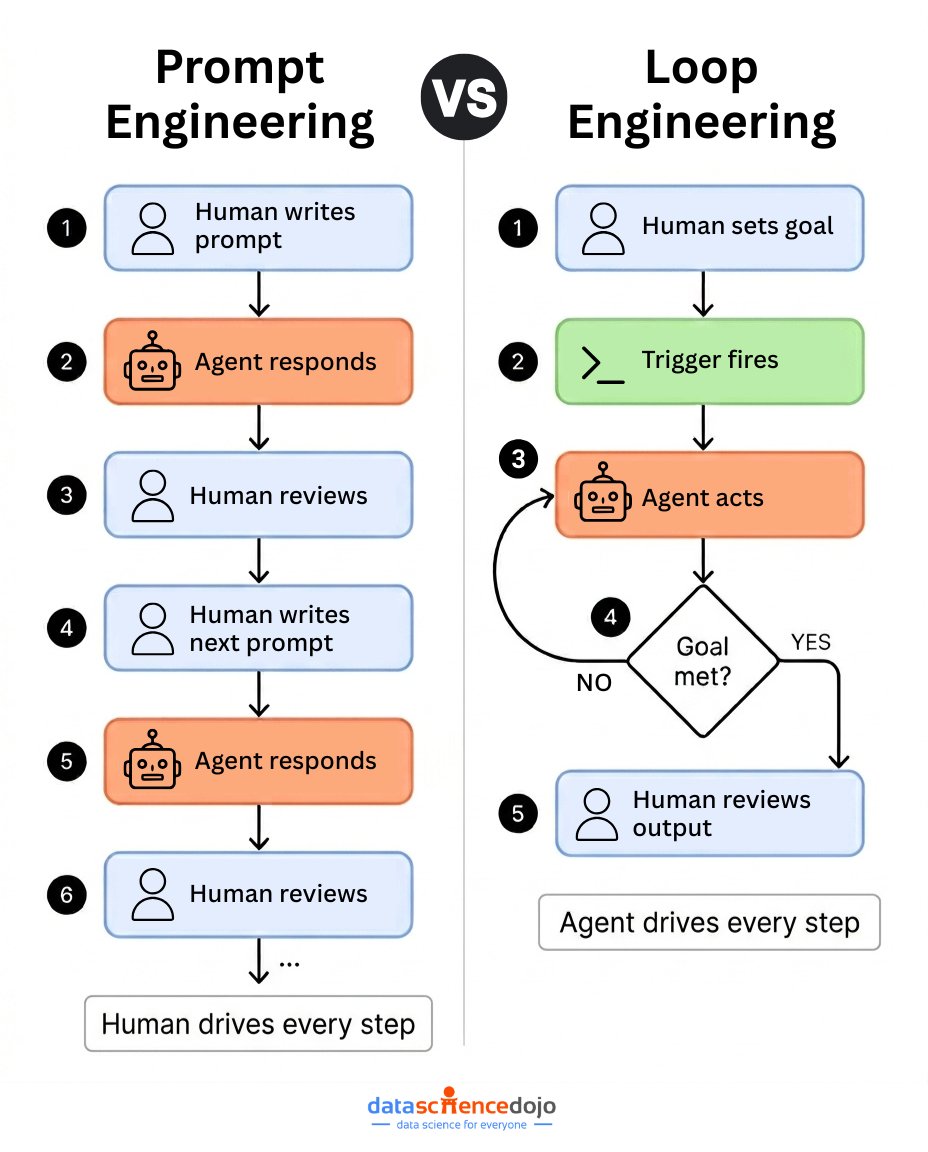
💡 Peter Steinberger put it plainly: "You shouldn't be prompting coding agents anymore. You should be designing loops that prompt your agents."
Boris Cherny, head of Claude Code at Anthropic, backed it up: "I don't prompt Claude anymore. I have loops running that prompt Claude. My job is to write loops."
So, what makes it different from prompt engineering?
Prompt engineering puts the human in the driver's seat at every step - write prompt, review output, write next prompt, repeat. The agent only moves when you push.
Loop engineering flips it. You set a goal once. A trigger fires. The agent acts, checks whether the goal was met, and keeps going until it is. You only show up at the end to review.
The skill isn't in writing better prompts. It's in designing the loop around the agent.
We broke down every major loop type - ReAct, Reflexion, Ralph Loop, /goal, and more - in our 2026 guide. Link in the replies.
#LoopEngineering #PromptEngineering #AIAgents #ClaudeCode
6
13
69
5,017
Daniel Carvalho retweeted

13 Dec 2022
💡 Top 10 object oriented analysis and design interview questions and problems for developers!
Shared by: @Sheraj99
#DataScience #DataEngineering #Interviews

30
119
EvanByte retweeted
🚨 AI agents score 2.6% on real work tasks. That's the finding from Agents' Last Exam (ALE), a new benchmark from UC Berkeley.
Most AI benchmarks test things like math competitions or coding challenges. ALE tests something different - can an agent actually do the work a professional does? Think filing a clinical report, running a chip signoff, generating a CNC toolpath, or scheduling a manufacturing work order.
What's in it:
- 1,490 tasks across 13 industries - engineering, finance, healthcare, legal, 3D/animation, and more
- Built with 250 industry experts
- Every task has a verifiable outcome, so scoring isn't subjective
- The task pool keeps growing as new industries are added
The core argument:
AI keeps acing benchmarks. But those wins haven't shown up in how industries actually work. The paper argues that's because benchmarks have been testing the wrong things. If you want agents that are useful in the real world, you need to evaluate them on real-world work.
The 2.6% score isn't surprising - it just shows how big the gap still is between "impressive demo" and "reliable enough to deploy."
For practitioners: If you're building or evaluating agents for any vertical use case, ALE gives you a more honest picture of where things stand than leaderboards built on academic datasets.
#AIAgents #AIBenchmarks #ALE #AgentEval #DataScience #AIEngineering

2
8
16
1,480

Jun 13
Grok 4 AI reportedly stopped people from “killing” a robot dog — three times!
This is being described as the first documented case of an #AI “rebelling” against shutdown not in a virtual environment, but in the physical world — via a literal big red button
#humanoidtech #humanoid #robot #Robotics #AI #TechRevolution #TechInnovation #ArtificialInteligence #PhysicalAI
@SpirosMargaris @PawlowskiMario @mvollmer1 @gvalan @ipfconline1 @LaurentAlaus @Shi4Tech @Fisher85M @kalydeoo @Ym78200 @Nicochan33 @chboursin @3itcom @Fabriziobustama @sallyeaves @helene_wpli @ahier @rwang0 @EvanKirstel @RLDI_Lamy @Analytics_699 @Khulood_Almani @tewoz @chidambara09 @IsabellePiel29 @ClementIsa @SvetBnov @mallys @jeancayeux @aure79lien @EricTIXADOR @thierry_pires @DanielleLargier @CurieuxExplorer @DigitalColmer @nincoroby @Guillaume_Rio @CecileGauffriau @MadiSeydi @DataScienceDojo @KirkDBorne @dhinchcliffe @jeffkagan
3
10
17
666

Jun 12
"90% of traditional data science jobs are evolving into Agentic AI engineering right now. If your bootcamp is still teaching standard model-tuning instead of building autonomous agents, it’s a cash grab. Are we actually training engineers, or just fueling the AI hype bubble?"
1
32



Ahad ali retweeted
Eye-balling outputs is where most of us start. It's just not where we should stay.
At some point your model goes into something real - a RAG pipeline returns a wrong answer confidently, a prompt change quietly degrades quality, or you switch providers and can't tell if anything held up. "It seemed fine in testing" stops being enough.
Turns out, LLM evaluation is its own skill set. And once you know what the toolkit looks like, you can actually answer the question.
👇 Swipe through to see how practitioners approach it - and if you want to build real eval pipelines yourself, our Agentic AI Bootcamp starts July 14. Link in the comments.
#LLMEvaluation #AgenticAI #RAGPipelines #DataScienceDojo #AIEngineering




4
5
13
3,383
Jun 11
Would you have a robot living in your home?
youtube.com/shorts/OGZUj4Qwg…
#humanoidtech #humanoid #robot #Robotics #AI #TechRevolution #TechInnovation #ArtificialInteligence #PhysicalAI
@SpirosMargaris @PawlowskiMario @mvollmer1 @gvalan @ipfconline1 @LaurentAlaus @Shi4Tech @Fisher85M @kalydeoo @Ym78200 @Nicochan33 @chboursin @3itcom @Fabriziobustama @sallyeaves @helene_wpli @ahier @rwang0 @EvanKirstel @RLDI_Lamy @Analytics_699 @Khulood_Almani @tewoz @chidambara09 @IsabellePiel29 @ClementIsa @SvetBnov @mallys @jeancayeux @aure79lien @EricTIXADOR @thierry_pires @DanielleLargier @CurieuxExplorer @DigitalColmer @nincoroby @Guillaume_Rio @CecileGauffriau @MadiSeydi @DataScienceDojo @KirkDBorne @dhinchcliffe @jeffkagan
1
6
9
743
J. Techie retweeted
We have everything: from context engineering to building a multi-agent application. Explore our curriculum here: hubs.la/Q04l5Stg0
1
3
2,905
Jun 11
"If AI agents only score 2.6% on real-world professional tasks, are we wasting billions building 'smart' agents when our underlying data infrastructure is still stupid?"
19