
// リム計算(共通)
float calcRim(float3 localPos, float3 localNormal)
{
float3 localCamPos = mul(unity_WorldToObject, float4(_WorldSpaceCameraPos, 1)).xyz;
float3 Eye = normalize(
float3(localCamPos.x, localCamPos.y, 0)
- float3(localPos.x, localPos.y, 0)
);
float3 normalXY = normalize(float3(localNormal.x, localNormal.y, 0) 1e-6);
float d = saturate(abs(1 - max(0, dot(normalXY, Eye))));
return d;
}
関数抜けてた
2
52
これはよくあるリムライトとやらの応用だねぇ
AIちゃんが横に居るようだし
半球状のメッシュに対して
v2f vert_rim (appdata v)
{
float4 pos = v.vertex;
pos.xy *= 1.0 calcWave(_Time.y, pos.z, _RimPulse.x, _RimPulse.z) * _RimPulse.y;
v2f o;
o.vertex = UnityObjectToClipPos(pos);
o.uv = TRANSFORM_TEX(v.uv, _MainTex);
o.color = v.color;
o.localPos = pos.xyz;
o.localNormal = v.normal;
return o;
}
fixed4 frag_rim (v2f i) : SV_Target
{
float d = calcRim(i.localPos, i.localNormal);
float rim = pow(d, _RimPower) * _RimIntensity;
fixed4 col = fixed4(_RimColor.rgb * rim, _RimColor.a);
return col;
}
こんなかんじ!って言えば通じるかなって
1
66


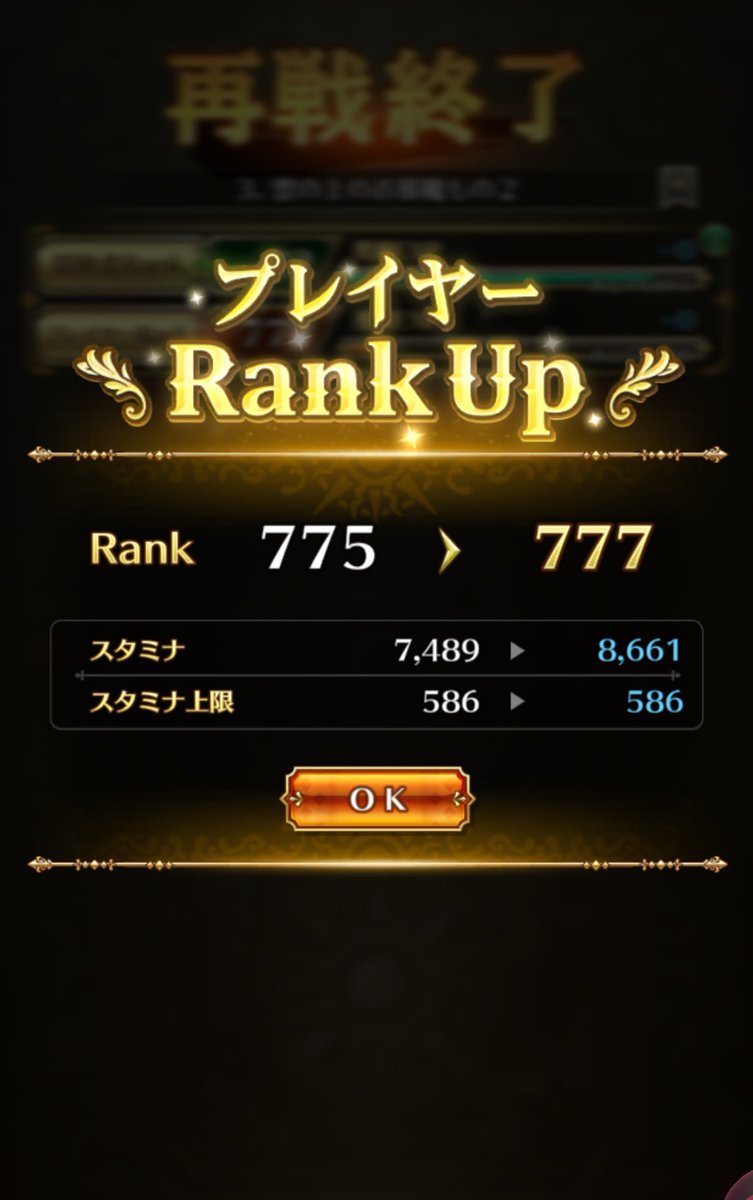


仕組みとしては、これの移植です(MITでありがとう)
でもUnity上では1ms切るらしいのでもっと最適化の余地はありそう、でもAviUtl2側の制約もある(具体的にはfloat4のテクスチャしか作れないなど)のでまぁ

1
1
5
936


May 24
ldsV = 0;
GroupBarrier();
float4 a = 0;
while(has work())
a = load4(popnext());
float4 perGroup = WaveActiveSum(a);
if (is first lane(() atomicAdd(ldsV, perGroup);
if (threadID == 0)
atomicAdd(ldsV, dramBuffer[0];
Group mem shenanigans I have to read manual.
1
4
367

May 14
・furcraeaHLSLEditor_UE5.8.0V9… UE5.8に対応しました。
・furcraeaHLSLEditor_UE5.7.4V8… float4出力に対応しました。
furcraea.verse.jp/wp/2026/03…

11
52
3,312

May 7
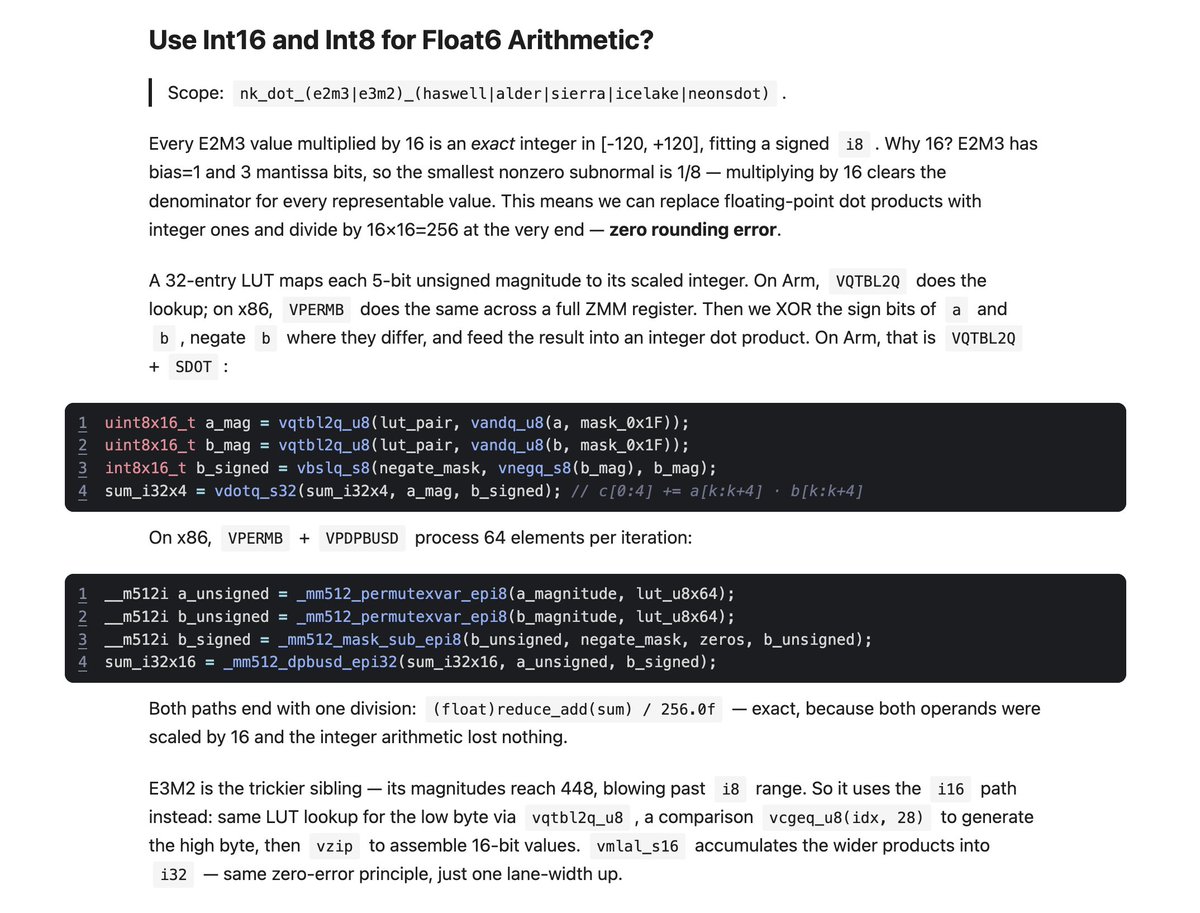
I really like Float6. Not because 6 is a magical number, but because its dot-products map surprisingly well to plain integer arithmetic on CPUs.
For E2M3, every value scaled by 16 fits in Int8. For E3M2, you need Int16. In both cases you can do the dot-product with integer SIMD and divide once at the end - no rounding error in the scaled arithmetic.
That made it possible to bring Float6 support to almost every CPU produced in the last 10 years - x86, Arm, LoongArch, PowerPC... - ahead of many specialized AI ASICs. One of the most fun parts of the NumKong release earlier this year: ashvardanian.com/posts/numko…
You can probably invent even cooler tricks for E2M1 and other Float4 variants... but I haven’t yet found a stable/consistent way to use them for training or inference, so I’m not rushing there.
And even Float6 isn’t all sunshine. On large-scale retrieval tasks, it loses too much information unless you add clever scaling: unum.cloud/blog/float8#scali…
That’s where Float8 E5M2 has a very practical old-CPU hack: it shares the exponent layout with Float16, so upcasting on the fly is mostly just widening shifting into an F16 bit-pattern. Fast, portable, and in our retrieval tests it didn’t hurt recall 🤗

May 7

Also, FP6 > FP4 in terms of performance iirc but I’ll let @ashvardanian explain why
4
14
155
18,354

Apr 16
[numthreads(THREADGROUP_SIZEX, THREADGROUP_SIZEY, 1)]
void MainCS(uint3 DispatchThreadId : SV_DispatchThreadID)
{
return float4(1,0,0,0) // check if shader is running q_q
}
1
6
354



Apr 7
Why does a tiny float4 function blow up into 400 lines of assembly on Mono? Value types, lowering, and lots of unnecessary copies. I wrote up a step-by-step walkthrough from C# to IR to final codegen. blog.s-schoener.com/2026-04-…
2
39
2,768

Mar 23
情報をありがとうございます。エラーを再現でき、発生箇所はFLOAT4.Xの中、原因はMC68060コアのエンバグと特定しました。修正します。
1
3
98

Mar 20
What we changed in our pg.zig fork:
1. SIMD JSON escaping: @Vector(16, u8) bulk copy, only escapes when the mask fires. Strings go out ~4x faster than byte-at-a-time.
2. writeJsonRow(): takes a pg result row, writes a full JSON object directly. No intermediate allocations, no ORM, no serialize step.
3. pgvector support: binary decode with SIMD float32 batch loads. Vector columns come back as JSON arrays, ready for embedding APIs.
4. Full type coverage: int2/4/8, float4/8, bool, text, bytea, UUID, timestamps, numeric, arrays. One switch statement, zero Python.
1
4
1,233

Mar 19
Differences with slug library:
* Own flavor of adaptative sampling
* No color support (for future)
* Band in float4 vs uint4
* use stb_truetype parsing
* No Cubic -> 2 quadratics
* No {AA, ligature, Variable font, Kering, bidirectionnal text}
* On demand data creation
3/3

2
10
922

For the context of a bilateral blur, you can also use gather4 to fetch your depth so you can calculate your weights. 1 tex instruction instead of 4
float4 depths = depthTex.GatherRed(s, uv);
1
2
191

Mar 14
day 9 of ml systems and gpu programming
1. working on activation kernels. wrote a naive relu kernel with 2d blocking.
2. wrote a float4 vectorized relu kernel that is 260x faster than my naive version. an adaptation of this kernel is my fastest on tensara leaderboard.
3. reading the sarathi serve paper and codebase. the idea is chunked prefill, to mix in prefill and decode in the batch to exhaust gpu utilization to the max. i kinda get it but ill have to implement it myself. the codebase is essentially a fork and very vllm like.
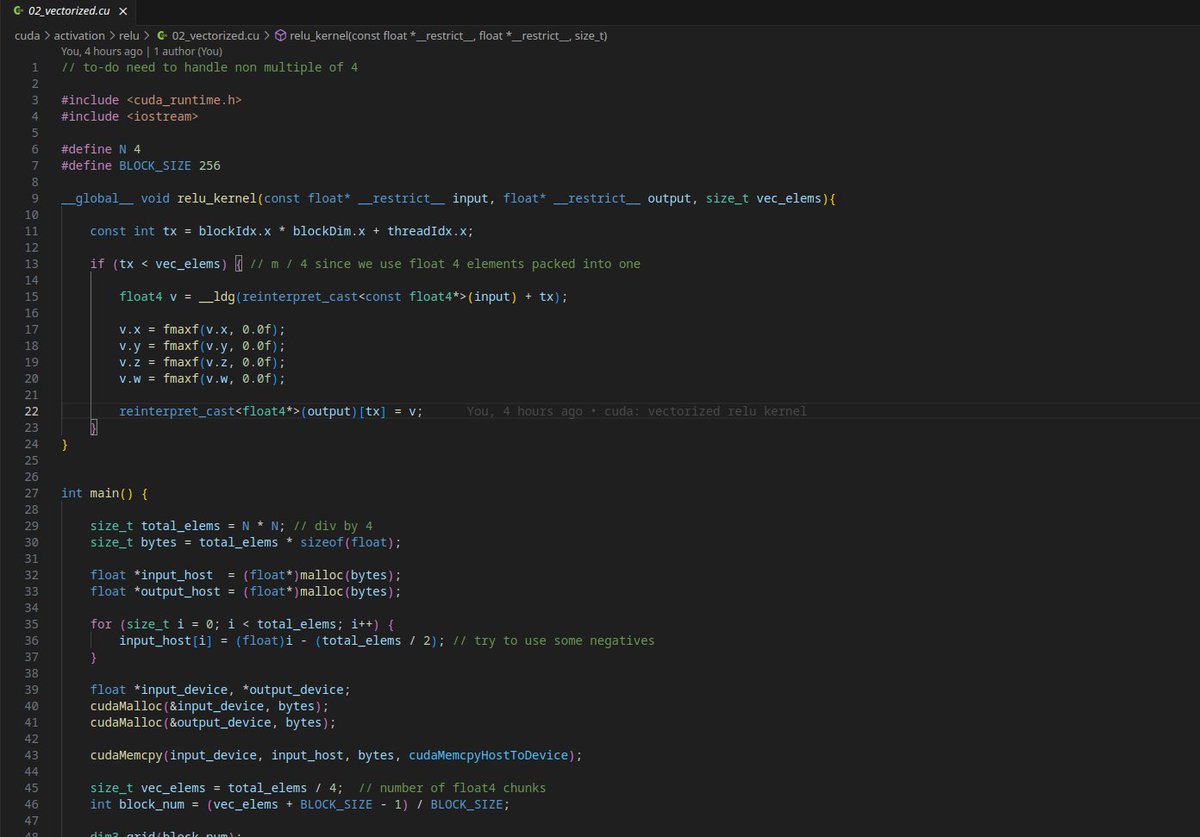
4
40
6,513

Mar 12
Agreed. Be it game’s engine, base shaders a/o added ones via AI, same matter.
First case is talking to a machine with « float4 AO (this, that, this, etc) », second case is « Correct accurate shadowing here and there and etc… »
2 different ways to discuss with a computer.
3
80

tried vectorized loads. basically instead of serial loading of values by a thread from gmem, used `float4` type to load 4 floats at once. tbh I didn't think it works, since bottleneck is L1. But fewer requests reduced L1 pressure, and helped a bit.

2
2
29
