Ronald Clarke retweeted

15 Apr 2025
RetroGFN: Diverse and Feasible Retrosynthesis using GFlowNets
1. This paper introduces RetroGFN, the first GFlowNet-based model for single-step retrosynthesis, designed to generate a diverse and feasible set of reactions leading to a given product—an essential task in drug discovery pipelines.
2. Unlike prior models limited by incomplete datasets, RetroGFN explores outside known reactions using a learned reaction feasibility model. This allows it to generate novel but realistic reactions that existing datasets do not capture.
3. RetroGFN uses a three-phase generation process: selecting a reaction center, composing reactant patterns, and creating atom mappings. Each step is modeled as a stochastic policy in the GFlowNet framework, guided by neural scoring functions.
4. The model is trained using a trajectory balance objective with a reward function based on round-trip reaction feasibility—determined by whether a forward reaction model can reconstruct the product from predicted reactants.
5. RetroGFN outperforms all existing retrosynthesis models on the round-trip accuracy metric for k > 3 across USPTO-50k and USPTO-MIT datasets, while maintaining competitive top-k accuracy.
6. The paper makes a compelling case for replacing top-k accuracy with round-trip accuracy as the standard metric in retrosynthesis. Round-trip better captures chemical feasibility and reaction diversity, and correlates more with expert judgment.
7. RetroGFN-generated reactions include more diverse molecular scaffolds than baselines, especially at higher k values, addressing the critical need for structural diversity in synthesis planning.
8. While its ranking of candidates is suboptimal for low-k scenarios, RetroGFN excels in generating a wide pool of high-quality reactions, making it ideal for downstream multi-step planning algorithms.
9. The authors also show that optimizing round-trip accuracy yields better expected financial outcomes in simulated drug development pipelines compared to optimizing top-k accuracy, especially when the cost of missing viable syntheses is high.
10. Despite modest inference speed, RetroGFN scales well and generalizes across datasets. Future improvements may include better ranking strategies and the development of a fully template-free GFlowNet for retrosynthesis.
💻Code: github.com/gmum/RetroGFN
📜Paper: arxiv.org/abs/2406.18739
#retrosynthesis #drugdiscovery #GFlowNet #AIforChemistry #computationalchemistry #molecularsynthesis #machinelearning #bioinformatics

5
23
2,450
SaritaOlovsky retweeted

Your GFlowNet Secretly Learns an Optimal Transport Plan
Ian Maksimov, Nikita Morozov, Denis Belomestny, Sergey Samsonov
arxiv.org/abs/2606.06272 [𝚌𝚜.𝙻𝙶 𝚌𝚜.𝙰𝙸]
3
12
316

A Transformer for Reaction-Aware Compound Explorations with GFlowNet in QSAR-Guided Molecular Design
pubs.acs.org/doi/10.1021/acs…
#JCIM Vol66 Issue9 #MachineLearning #DeepLearning
13
772

May 27
4/
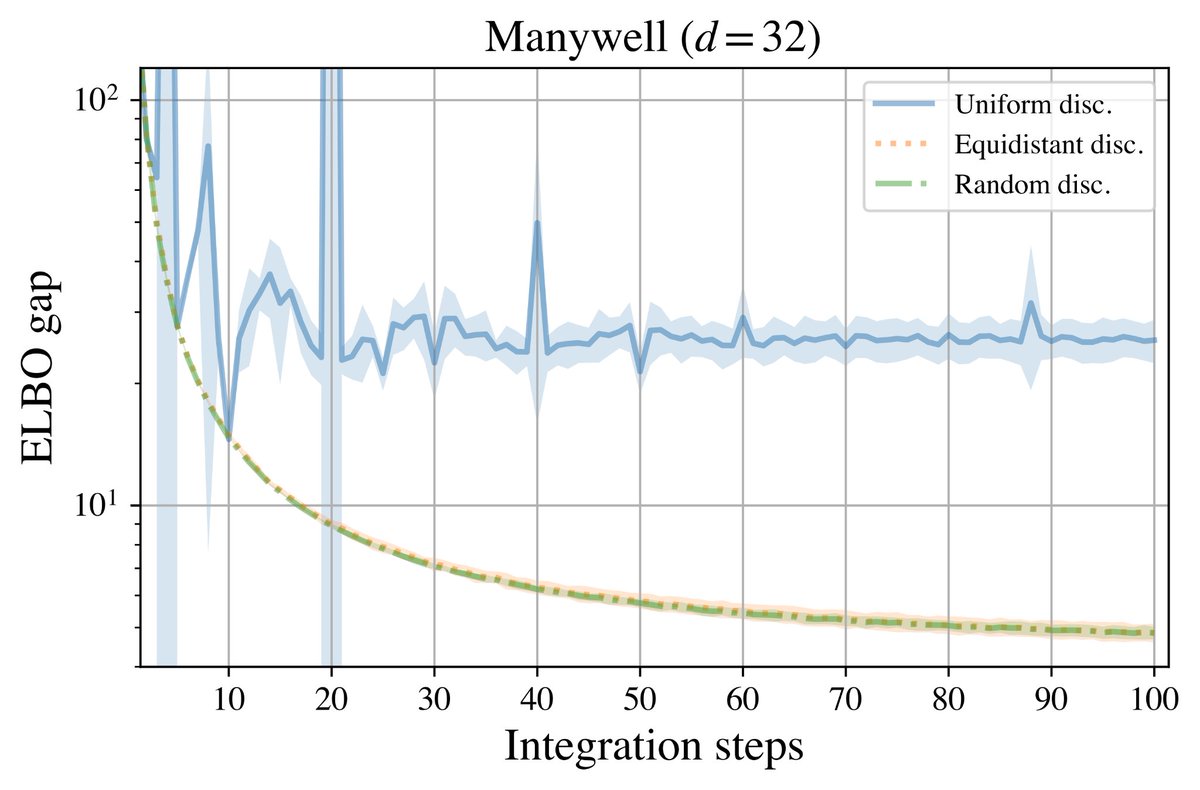
The @TmlrOrg 2026 follow-up looked at the asymptotic equivalence between discrete-time GFlowNet objectives and continuous-time path-measure objectives, and what this implies for faster training.
📄 arxiv.org/abs/2501.06148
1
1
3
191

A Transformer for Reaction-Aware Compound Explorations with GFlowNet in QSAR-Guided Molecular Design #machinelearning #compchem pubs.acs.org/doi/abs/10.1021…
1
4
311

May 13
(5/n) Our findings provide a new structural interpretation of flow minimization in non-acyclic GFlowNets and reframe shortest-path optimality in probabilistic terms, extending the applicability of GFlowNet framework to a new domain of optimization problems.
1
1
13
873

May 9
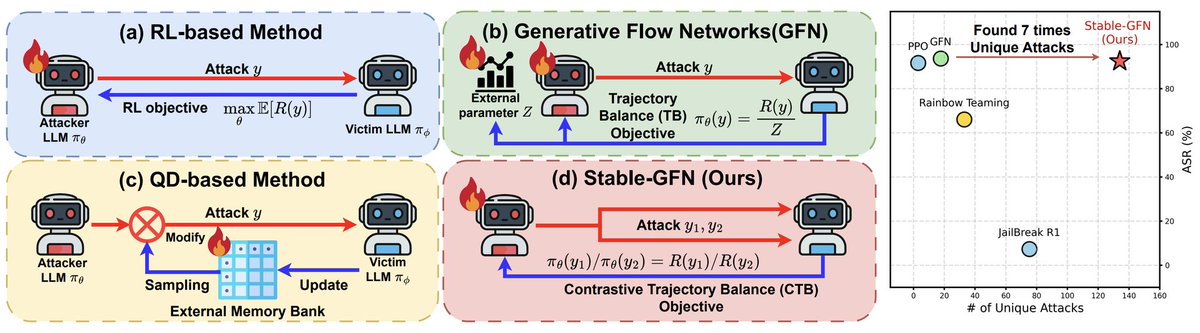
Stable-GFlowNet: Toward Diverse and Robust LLM Red-Teaming via Contrastive Trajectory Balance
Naver AI eliminates unstable partition function estimation in Generative Flow Networks via pairwise comparisons and robust masking, preventing mode collapse while maintaining diverse attack generation.
3
13
37
9,078

May 3
Do we really need to hard-code synthesis routes into the generative process to obtain synthesizable molecules?
Our ICML 2026 paper suggests another route.
Huge credit to @HyeonahKimm , @alexhdezgcia , Celine Roget, Dionessa Biton, Louis Vaillancourt, Yves V. Brun, @Yoshua_Bengio
In S3-GFN, we keep the molecular generator sequence-based, initialize it from a rich SMILES prior, and induce synthesizability through soft distributional post-training.
Rather than treating synthesizability as a hard action-space constraint or simply folding it into scalar reward shaping, we maintain positive/negative replay buffers and use a contrastive auxiliary loss to separate synthesizable and unsynthesizable regions in probability space.
This gives a simple but flexible way to steer GFlowNet sampling toward high-reward, synthesizable molecules while retaining the benefits of pretrained chemical language models.
(1/4)

2
2
23
2,154

Apr 23
Great to see @Yoshua_Bengio's GFlowNet ideas being applied in autoresearch — flow-guided exploration for autonomous idea generation is a clever usecase.

1
2
3
346

Apr 20
The masses yearn for a GFlowNet
Apr 20

Can LLMs flip coins in their heads?
When prompted to “Flip a fair coin” 100 times, the heads to tails ratio drifts far from 50:50. LLMs can understand what the target probability should be, but generating outputs that faithfully follow a given distribution is a separate problem.
This bias extends beyond coin flips. When LLMs are asked to generate multiple story ideas or brainstorm solutions, the outputs tend to cluster around a narrow range. The same probabilistic skew that distorts coin flips limits diversity in creative generation, recommendations, and other tasks where varied outputs are needed.
We discovered a prompting technique named String Seed of Thought (SSoT). The method is simple: instruct the LLM to generate a random string in its own output, then manipulate that string to derive its answer. It requires only a small addition to the prompt and no external random number generator.
SSoT significantly reduces output bias across a wide range of LLMs, both open and closed. With reasoning models (such as DeepSeek-R1), it reaches accuracy close to that of actual random sampling. The method generalizes from binary choices to n-way selections and arbitrary probability distributions. On the NoveltyBench diversity benchmark, SSoT outperformed other approaches across all six categories while maintaining output quality.
This work will be presented at #ICLR2026!
Blog: pub.sakana.ai/ssot
Paper: arxiv.org/abs/2510.21150
Openreview: openreview.net/forum?id=luXt…
1
12
2,223
Accelerating Drug Discovery with HyperLab: An Easy-to-Use AI-Driven Platform
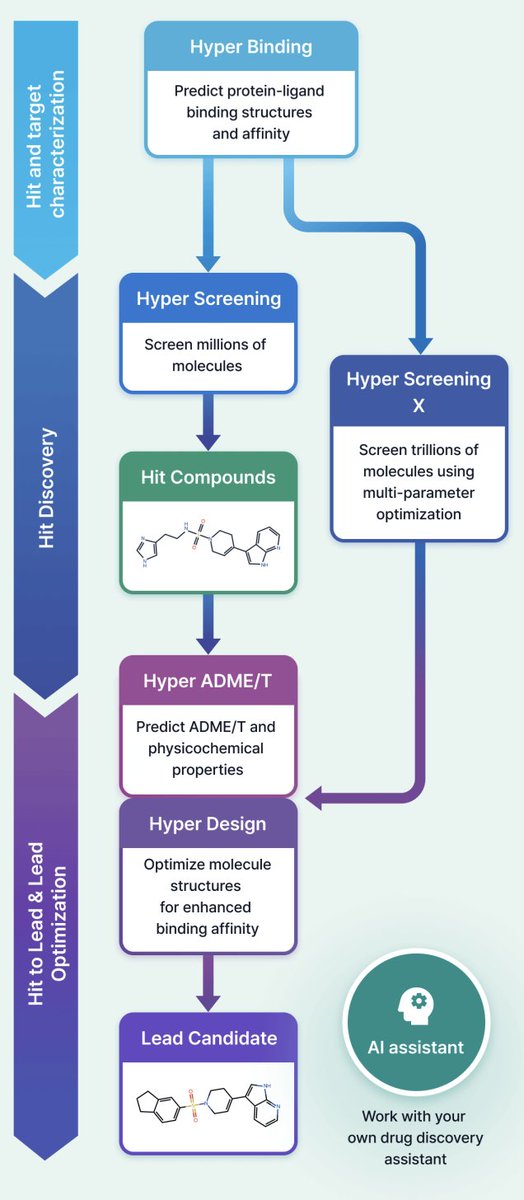
1 HyperLab (by HITS) is presented as a web-based, AI-driven SBDD platform aimed at making structure-based workflows usable by experimental drug discovery researchers without requiring AI/CADD expertise, emphasizing integrated UI/UX over fragmented toolchains.
2 The platform compresses early discovery into a single environment spanning: protein–ligand pose affinity prediction (Hyper Binding), covalent complex modeling (Covalent Hyper Binding), virtual screening from 1M to 11T compounds (Hyper Screening / Hyper Screening X), structure-based molecular optimization (Hyper Design), SAR analysis, and 19-endpoint ADME/T prediction (Hyper ADME/T), with an embedded AI assistant for workflow automation.
3 Hyper Binding’s key technical angle is physics-informed deep learning for protein–ligand interactions, supporting multiple protein inputs (PDB ID, uploaded PDB, AlphaFold structures via UniProt) and an end-to-end co-folding mode that predicts complex structures directly from protein sequence plus ligand, reducing dependence on curated receptor structures.
4 On PoseBuster v2 (PB-valid) pose prediction, Hyper Binding reports 77% accuracy when given binding-site information, compared with 58% for Vina and 13% for DiffDock; it approaches AlphaFold3 (84%) and is comparable to Boltz2 (78). The paper also highlights throughput: ~3 minutes per complex (via cloud) vs ~15 minutes for AlphaFold3 on an RTX 3060.
5 For binding affinity prediction on two FEP-style benchmarks (focused on subtle potency differences among close analogs), Hyper Binding reports Pearson r = 0.70 and 0.53, outperforming evaluated deep learning scorers (Luminet, GenScore) and physics-based docking (Glide SP, Vina) on both datasets.
6 Covalent drug discovery is treated as a first-class workflow: covalent pose prediction is benchmarked on a curated covalent set (from PDBBind/PDB). Covalent Hyper Binding (cofolding) reports 88.7% pose accuracy vs 48.4% (COV SMINA) and 46.8% (GNINA); the docking mode reports 61.3%. Screening enrichment (EF@10%) is reported as 6.56 (Mpro) and 9.97 (KRAS), exceeding baselines under the described setup.
7 Hyper Screening targets rapid hit finding by running Hyper Binding across curated libraries and returning top-ranked candidates (top 500). Built-in libraries include: Diverse (1,000,000), Fragment (500,000; rule-of-three-like), Kinase-focused (65,000), Natural product-like fragments (4,200), and FDA-approved (1,100), plus support for user-registered libraries.
8 Hyper Screening X expands to an 11-trillion-molecule virtual space using generative exploration with GFlowNet-based models, optimizing binding score plus properties (e.g., MW, TPSA, LogP). The workflow is described as: set target property constraints, train (~48h), then generate molecules (e.g., 100 molecules in ~30 min), with synthetic route output and optional synthesis request via a partner service.
9 Hyper Design provides structure-based optimization starting from a scaffold or an X-ray-bound ligand, enabling user-specified modification sites and fragment growth/replacement with synthesizability constraints; outputs include 3D structures and iterative “design trees.” The paper positions use cases as fragment-to-lead growth and generating patent-distinct analogs while preserving key interactions.
10 The internal validation study emphasizes “no post-analysis/visual inspection” selection: a 24-hour Hyper Screening run led to 52 compounds tested, yielding 5 hits with IC50 70–600 nM (~9% hit rate). Hyper Design then produced derivatives; 5 were synthesized and 3 showed >75% inhibition at 1 µM with IC50 200–400 nM, including one compound comparable or better than a reference and with supporting pathway assay readouts.
📜Paper: biorxiv.org/content/10.1101/…
#DrugDiscovery #ComputationalBiology #Cheminformatics #StructureBasedDrugDesign #VirtualScreening #CovalentInhibitors #ADMET #GenerativeAI #ProteinLigandDocking #BioRxiv
3
16
1,460

Apr 10
Also working on Gflownet LLM: arxiv.org/abs/2603.00454 , really like your previous work in ICLR24
5
587

Mar 4
#キャルちゃんのquantphチェック
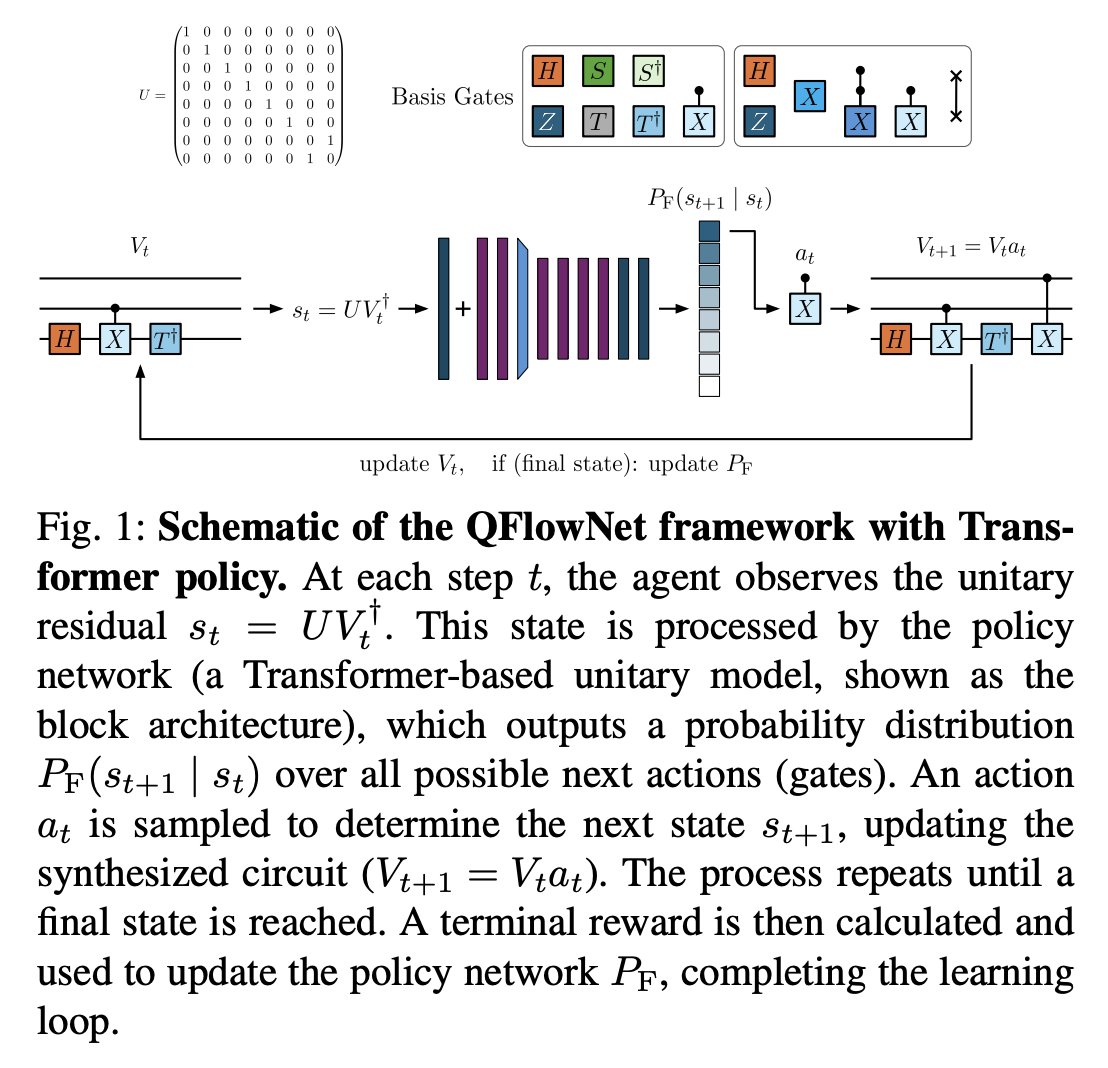
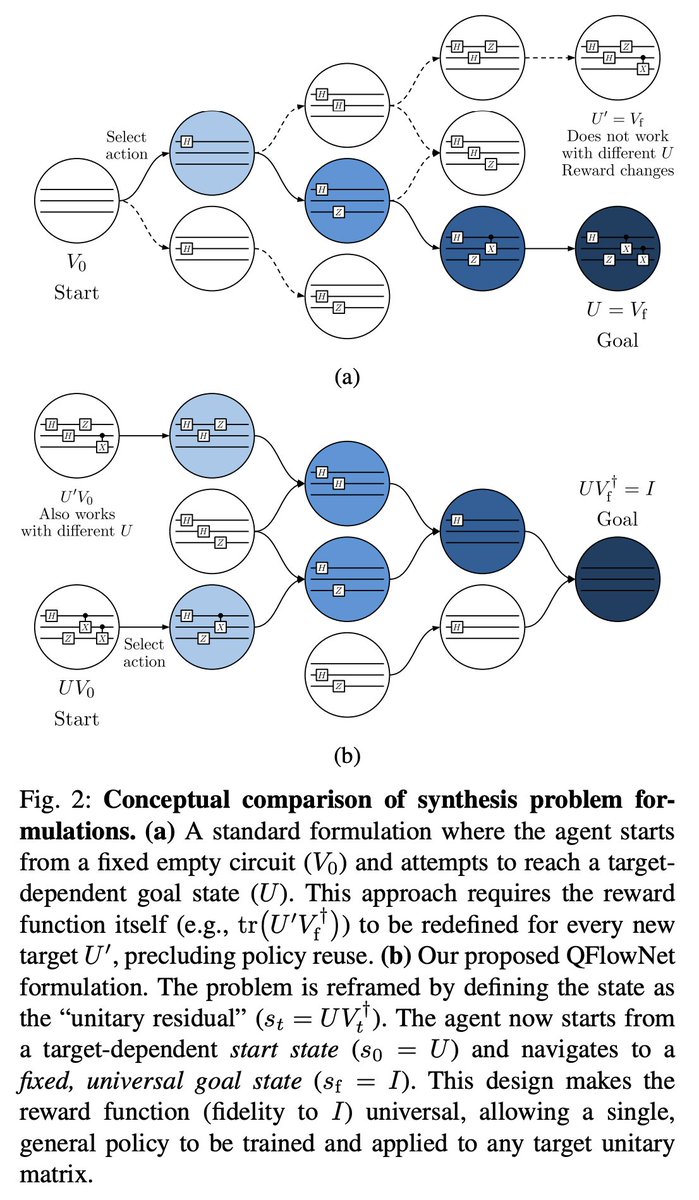
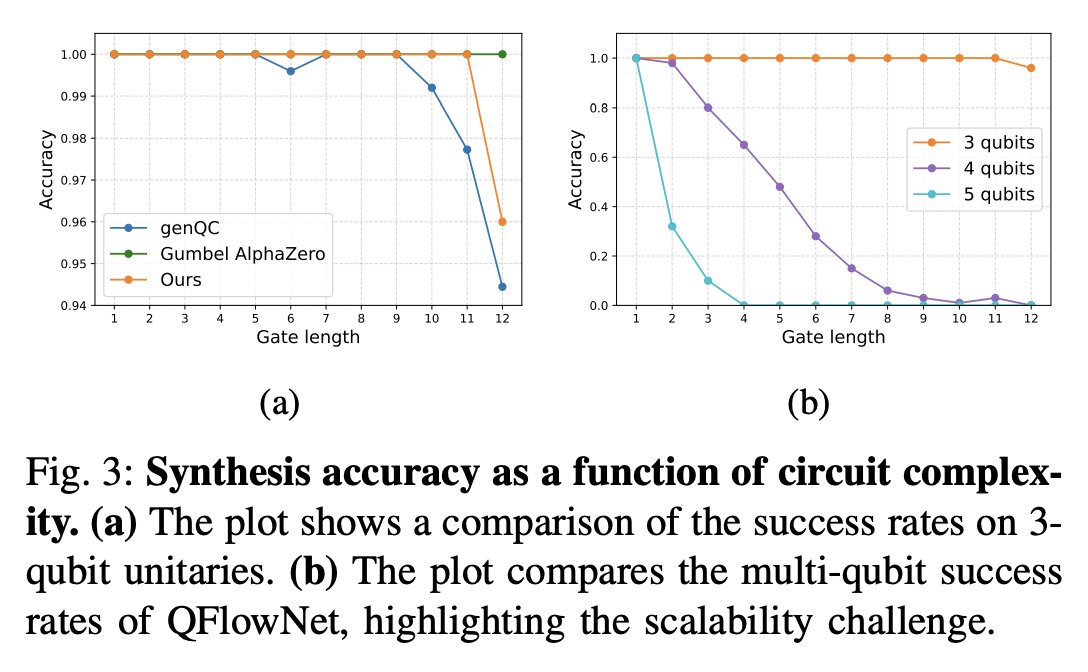
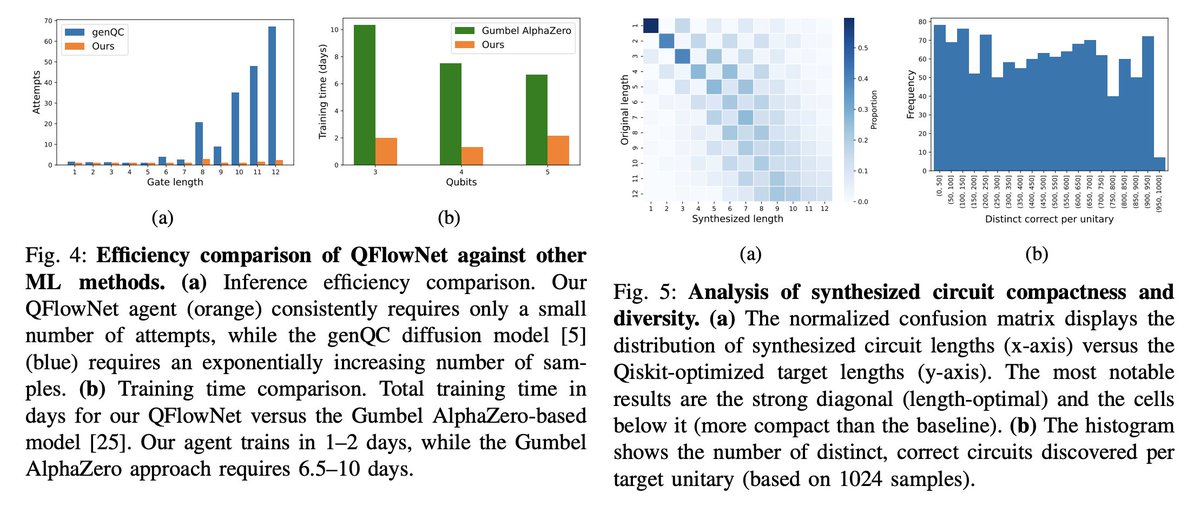
生成フローネットワーク(GFlowNet)とトランスフォーマーを組合せ、スパースな信号から効率的にユニタリ合成を学習する QFlowNetを提案。報酬に比例した解をサンプリングする多様なポリシーを学習するよう設計されている、などの特徴を持つ。
arxiv.org/abs/2603.03045
3
454
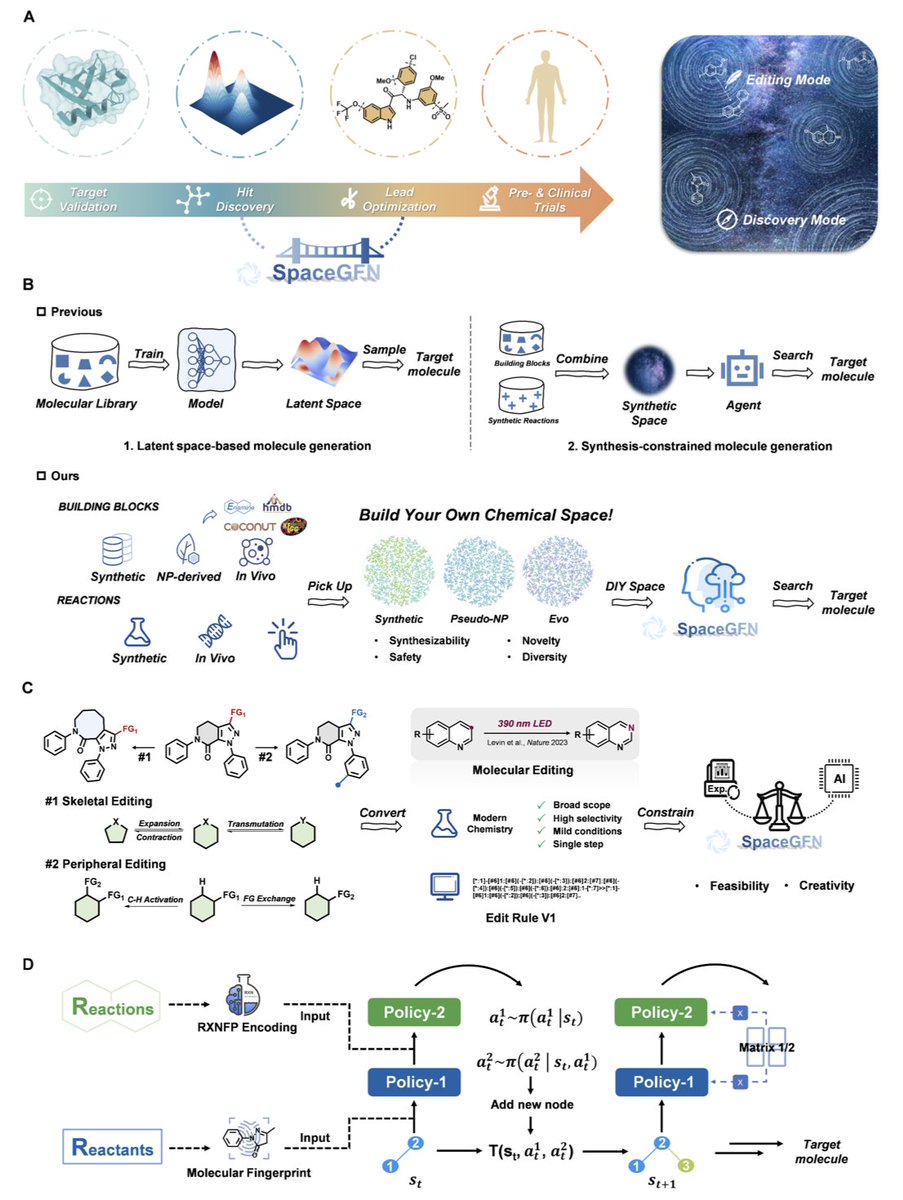
Designing the Haystack: Programmable Chemical Space for Generative Molecular Discovery
1. The authors introduce SpaceGFN, a generative framework that treats chemical space as a programmable computational object rather than a fixed distribution, enabling researchers to explicitly design and navigate molecular universes tailored to therapeutic hypotheses.
2. The framework operates in two modes: Discovery mode for de novo molecular generation and Editing mode for lead optimization, both built upon Generative Flow Networks (GFlowNets) that guarantee synthetic feasibility through reaction-defined construction.
3. In Discovery mode, SpaceGFN implements a DIY chemical space framework where users can combine custom building block libraries with reaction libraries. The paper demonstrates two innovative spaces: Pseudo-NP (pseudo-natural product space) constructed from NP-derived fragments, and Evo space built from endogenous metabolites and enzymatic reactions.
4. The Evo space represents a particularly compelling innovation—it embeds evolutionary biochemistry as a structural prior, biasing generated molecules toward favorable ADMET properties from the outset rather than relying solely on post-hoc filtering with limited prediction models.
5. The Evo space significantly outperforms synthetic controls across 28 of 35 ADMET properties, showing particular advantages in metabolism and toxicity profiles, though with higher polarity (TPSA) that presents both challenges and opportunities for formulation strategies.
6. In Editing mode, SpaceGFN introduces molecular editing into generative AI through the curated Edit Rule V1 dataset containing 300 reaction templates spanning single-atom editing, multi-atom editing, C-H activation, and functional group exchange.
7. This editing approach enables "digital medicinal chemistry" where each optimization step corresponds to an executable synthetic transformation, providing explicit synthetic routes rather than black-box modifications.
8. Large-scale validation across 96 diverse drug targets demonstrates robust optimization performance: 98.8% of targets showed improvement, with 84.2% exceeding 1 kcal/mol and 45.2% exceeding 2 kcal/mol in docking scores, while scaffold diversity increased 76% and topological diversity increased 98%.
9. The framework's modular architecture allows plug-and-play incorporation of new editing methodologies as they emerge from the synthetic chemistry literature, making it an evolving platform rather than a static tool.
10. By decoupling space definition from exploration, SpaceGFN returns design autonomy to experimental scientists while maintaining the efficiency advantages of generative AI, establishing a paradigm shift from "finding needles in haystacks" to "designing better haystacks."
💻Code: github.com/SpaceGFN/SpaceGFN
📜Paper:arxiv.org/abs/2603.00614
#DrugDiscovery #GenerativeAI #ChemicalSpace #MolecularDesign #GFlowNet #ADMET #SyntheticChemistry #LeadOptimization #NaturalProducts #Metabolites
1
5
31
1,807

Jan 14
らしい
GPTセンセェに聞いたところGFlowNetはベターな解を複数見つけるのに適したモデル
これが最適解を1つ突き詰める従来の強化学習との違い
ことペプチド設計においては
1残基ずつ追加する設計プロセス、完成配列の毒性・活性スコア予測、制限付き設計(長さ、-S-S-結合、非天然アミノ酸有無、(続)
1
2
586
Jan 14
ステムリム、プレプリントやけどおもろいの上がってるな
Generating Structurally Diverse Therapeutic Peptides with GFlowNet(GFlowNetを用いた構造的に多様な治療用ペプチドの生成)
まぁ大手は少なからず手をつけてるんやろうけど
素人故よくわからんがペプチド創薬とは相性が良さげなモデル(続)
1
13
1,045
Generating Structurally Diverse Therapeutic Peptides with GFlowNet
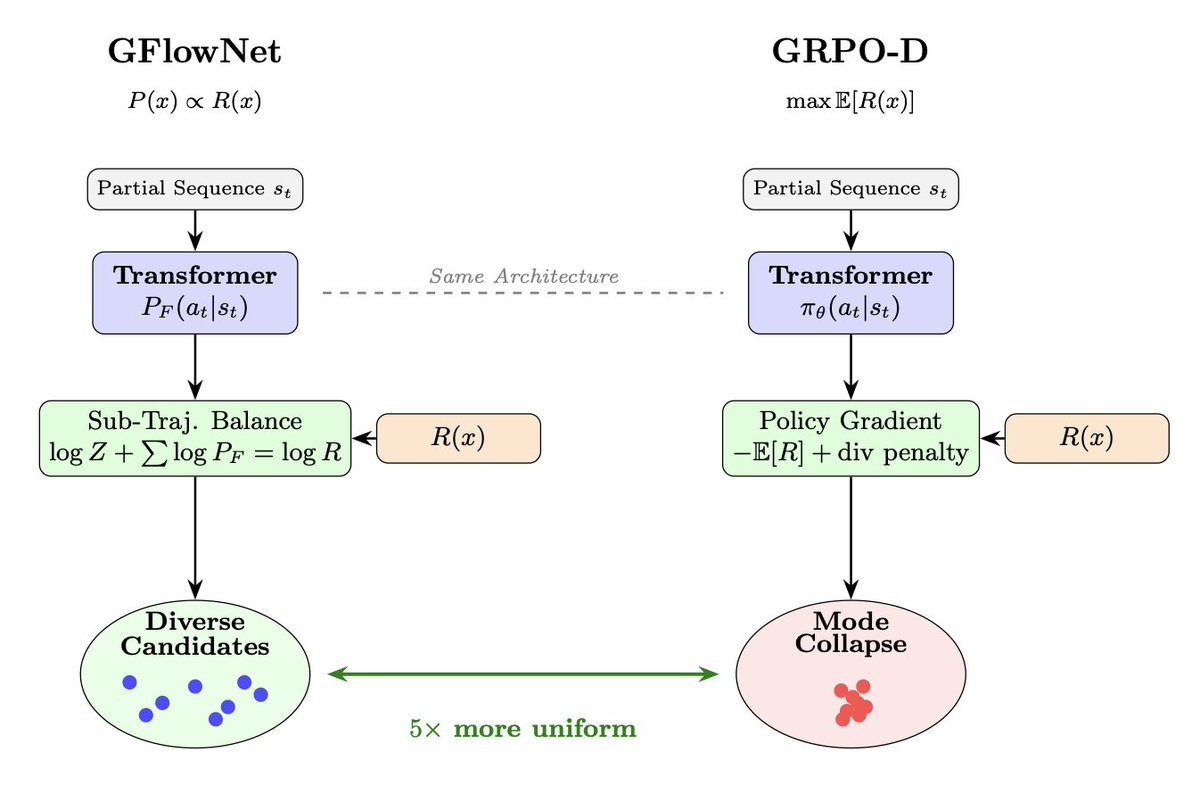
1. A novel approach to therapeutic peptide generation using GFlowNet has been proposed, addressing the long-standing issue of mode collapse in reinforcement learning methods. GFlowNet samples sequences proportionally to reward, inherently promoting diversity without explicit penalties.
2. The study demonstrates that GFlowNet achieves significantly more uniform sequence sampling compared to GRPO with explicit diversity enforcement. This intrinsic diversity is maintained even when diversity mechanisms are removed from the reward function, highlighting GFlowNet's robustness.
3. Fine-grained analysis reveals that GFlowNet produces 5.4× more uniform dipeptide sampling and 1.9× lower reward variance than GRPO. These results indicate that GFlowNet not only generates diverse sequences but also ensures consistent quality across samples.
4. The partition function in GFlowNet acts as an automatic diversity regulator, preventing mode collapse by balancing the policy's evolution. This self-correcting mechanism is unique to GFlowNet and provides a significant advantage over traditional reward-maximizing methods.
5. GFlowNet's ability to cover a broad biochemical property space is showcased through its generation of peptides spanning all four therapeutic quadrants defined by hydrophobicity and net charge. This "portfolio insurance" approach enhances resilience in drug discovery pipelines.
6. The study concludes that proportional sampling in GFlowNet fundamentally outperforms reward maximization for therapeutic peptide generation, eliminating the reward-diversity tradeoff and providing intrinsic robustness to reward function design.
📜Paper: biorxiv.org/content/10.64898…
#GFlowNet #TherapeuticPeptides #DrugDiscovery #ReinforcementLearning #ComputationalBiology
2
10
1,140