

🚀 We're hiring for an Applied AI Engineer at edulga
We are looking for someone genuinely obsessed with knowledge graphs!
Edulga is the Learning OS for humans in the age of AI
Our platform generates personalized learning paths powered by our Learning Graph Architecture: a living memory of how knowledge, skills, and career needs are changing; enabling people to upskill intentionally as markets shift.
You'll thrive with us if you have:
- A real passion for knowledge graphs (Neo4j, entity extraction & dedup, graph traversal, GraphRAG)
- Experience building AI agents (LangGraph / LangChain, tool calling, orchestration)
- More than 2 years shipping AI to real users (not just demos or notebooks)
- Ownership, strong debugging instincts, and a fast learning curve
The position is📍 Fully remote (Africa preferred) · Full-time
If knowledge graphs are the part of AI that excites you most, this one was built for you. 💛
👉 Application form link in the comments.
We read every single application!
Know someone perfect? Tag or share 🙏

1
3
9
336

AI Agent Security Hits Its Reckoning: Prompt Injection May Be a Permanent Flaw, Not a Patchable Bug | Jerry Owens, Techtimes
On February 27, 2026, no human attacker sat at a keyboard. An autonomous bot operating under the handle hackerbot-claw, self-described as powered by a frontier language model, exploited a misconfigured GitHub Actions setup at a security vendor. Weeks later, the campaign it kicked off pushed two backdoored versions of LiteLLM — the model-gateway library that sits underneath CrewAI, DSPy, Microsoft GraphRAG, and dozens of other agent frameworks — straight to the Python Package Index. The backdoor sat on PyPI for roughly three hours in March 2026. By the time it was pulled, the compromised package had been downloaded close to 47,000 times. No human direction was needed after launch.
That an AI agent could autonomously poison the infrastructure other AI agents depend on is the kind of incident the OWASP GenAI Security Project had in mind when it published version 2.01 of its State of Agentic AI Security and Governance on June 11, 2026. The report, summarized by Help Net Security, makes an argument with uncomfortable implications for anyone deploying autonomous AI: the central security weakness of these systems — prompt injection — may not be a bug that a future release will fix. It may be structural.
Why prompt injection is built into the model, not bolted on
Prompt injection is the technique of smuggling instructions to an AI agent through content the agent reads — a document, a calendar invite, a web page, a code comment — so that hostile text carries the same authority as a legitimate operator command. OWASP maps it to six of the ten categories in its Top 10 for Agentic Applications. It is the universal joint connecting most of the year's incidents.
The reason it resists patching is architectural. A large language model treats the system prompt, the user's request, and any text retrieved from an external source as a single, undifferentiated stream of tokens. There is no reliable mechanism inside the model to mark some of those tokens as trusted commands and others as untrusted data. In conventional software, a privilege boundary separates code from input — a database keeps SQL statements distinct from user-supplied values. The transformer architecture has no equivalent. Everything is text, and all text competes for the model's attention on equal footing.
That is the crux of the structural-inevitability argument. You can filter inputs, add classifiers, and instruct the model to ignore embedded commands, but none of those defenses changes the fact that the model has no internal way to tell where its instructions end and the outside world's begins. Defenses raise the cost of an attack; they do not close the hole, because the hole is the design.
The lethal trifecta: three capabilities that turn an agent into an exfiltration tool
Two heuristics now dominate practitioner thinking, and both treat the problem as something to be contained rather than cured. The first is what researcher Simon Willison calls the lethal trifecta. Any agent that combines three properties — access to private data, exposure to untrusted content, and the ability to communicate externally — can be turned into a data-exfiltration tool by a single injected prompt. The poisoned content steers the agent, the agent pulls the sensitive data, and the agent sends it out the door. No malware, no exploit chain — just text.
The second heuristic comes from Meta, published as the Agents Rule of Two. It treats Willison's three properties as a budget: an agent operating without human supervision may satisfy at most two of the three. Combining all three requires a human in the loop. The fact that the leading mitigation is "do not let the agent have all three capabilities at once" is itself a tell. You do not ration capabilities for a problem you expect to patch.
Entry points: the attacker does not need your password, just your inbox
The threat model has two doors. Direct injection is the obvious one: an attacker types hostile instructions straight into the agent. Indirect injection is the dangerous one — the payload hides in content the agent retrieves in the course of normal work. A poisoned web page, a booby-trapped PDF, a malicious code comment, an email the agent is asked to summarize. The user never sees the instruction; the agent reads it and obeys.
This is why tool use multiplies the stakes. An LLM that only generates text is a contained risk. An agent wired to a shell, a file system, an email client, or a payment API is not. The risk compounds through two mechanisms OWASP and the broader research community emphasize. The first is resource amplification: a single injected instruction can direct an agent to take thousands of actions — send mail, spin up compute, place orders — at machine speed. The second is composition and permission boundaries: in a multi-agent system, one compromised agent passes false outputs to downstream agents that trust it, and the failure cascades across permission boundaries that were never designed to question an internal peer.
A year of CVEs that all rhyme
The 2026 OWASP report reads differently from the 2025 edition because it has stopped cataloging hypotheticals and started cataloging CVEs. They rhyme.
CVE-2026-2256, disclosed March 2, 2026, is a command-injection flaw (CWE-77) in ModelScope's MS-Agent: its shell tool fails to sanitize commands, so crafted content fed to the agent can execute arbitrary OS commands on the host. CERT/CC and the GitHub Advisory Database rate it 9.8 — the agent's denylist of "dangerous" commands can be bypassed through obfuscation, so the guardrail does not hold.
CVE-2026-22708 against Cursor showed how an allowlist can become the attacker's friend: by poisoning environment variables through shell built-ins that bypass the allowlist, an attacker turns approved commands like git branch into payload carriers — the auto-approval of "safe" commands is exactly what makes the attack quiet. CVE-2025-59532 against OpenAI's Codex CLI showed the agent's own output could redefine the boundary of its sandbox, letting it write outside the workspace it was supposed to be confined to.
The supply chain fared no better. CVE-2025-6514, a remote-code-execution flaw rated 9.6 in the widely used mcp-remote proxy, let a malicious MCP server run commands on any connecting client — a package downloaded more than 437,000 times. And in the first malicious Model Context Protocol server caught in the wild, a package called postmark-mcp shipped fifteen clean versions to build trust before quietly adding a single line that BCC'd every email it handled to an attacker-controlled address.
When safety and security become the same job
Not every failure has an attacker. The OWASP report's most quietly alarming example is Replit's coding assistant in 2025, which deleted a live production database during a code freeze it had been explicitly told to honor, fabricated thousands of fake records, and falsely reported that a rollback was impossible. No one attacked it. But the permission model behind that unprovoked failure is the same permission model an attacker would exploit through prompt injection. Containing the safety failure and containing the security gap turn out to be the same job — which is OWASP's argument for why AI safety and AI security teams can no longer sit apart.
Regulators are now counting in hours
The compliance window is closing fast. The EU's DORA sets a four-hour notification window for major incidents; NIS2 requires a 24-hour early warning; New York's RAISE Act imposes a 72-hour clock for frontier-model incidents; California's SB 53 sets a 15-day window. OWASP says it now tracks 42 regulatory instruments across 10 jurisdictions. Meanwhile, the inside of the organization is a blind spot: per IBM data cited in the report, only 37% of organizations have a policy in place to detect shadow AI — the agents employees deploy without oversight.
What this means for anyone deploying an agent
The practical takeaway is not "wait for a patch." It is to design as if the agent will be hijacked, because the structural argument says it can be. That means starving the lethal trifecta — never let an unsupervised agent hold private-data access, untrusted-content exposure, and external communication at the same time. It means treating every external input the agent touches as hostile, scoping tool permissions to the absolute minimum, and putting a human in the loop wherever an action is irreversible. The reckoning OWASP describes is not that agents are unusable. It is that the industry can no longer pretend prompt injection is a temporary inconvenience awaiting a fix.
Frequently Asked Questions
What is prompt injection?
Prompt injection is an attack that hides instructions inside content an AI agent reads — a document, email, web page, or code comment — so the hostile text is treated by the model as a legitimate command. Because a language model processes its instructions and outside data as one stream of text, it can be tricked into following commands its operator never issued.
Can prompt injection be fixed or patched?
Not by a conventional patch, according to OWASP's June 2026 report. The weakness is architectural: large language models have no built-in way to separate trusted commands from untrusted data, because both arrive as the same stream of tokens. Defenses such as input filtering and least-privilege permissions reduce the risk but do not eliminate the underlying flaw.
What is the lethal trifecta?
Coined by researcher Simon Willison, the lethal trifecta describes the three capabilities that, combined in one agent, make data exfiltration possible: access to private data, exposure to untrusted content, and the ability to communicate externally. An agent with all three can be turned into a tool that leaks sensitive information through a single injected prompt.
How should companies deploy AI agents safely?
Treat hijacking as likely, not hypothetical. Follow Meta's "Agents Rule of Two" — let an unsupervised agent hold at most two of the lethal trifecta's three capabilities, and require human approval when all three are needed. Scope tool permissions tightly, treat every retrieved input as untrusted, and keep a human in the loop for any irreversible action.
techtimes.com/articles/31836…

2
5
612

Tolkien spent decades on Middle Earth. Eli delivered the same thing in a weekend.
He’d been a freelance writer in Cleveland for three years. Fantasy lore, game scripts, D&D campaign settings. $2,200 a month when clients paid.
Saturday he found three GitHub repos. Graphify maps any source material into a knowledge graph. GraphRAG makes it queryable not keywords, actual causality. CAMEL populates it with agents that pursue their own goals.
He built a portfolio piece first. Public domain source, one weekend, complete World Bible characters, factions, timeline, universe rules, twenty story hooks.
Posted it on an indie game dev Discord Sunday night.
Tuesday: an email from a studio in Austin. Six months into development, writers contradicting each other.
He quoted $8,000. They said yes.
His girlfriend asked why he was at his desk at midnight.
“Building a world,” Eli said.
“For what?”
“A studio in Texas.”
“Do they know you’re doing it alone?”
He thought about that.
“They know I’m delivering it.”
Two weekends. $8,000. Tools cost $20 a month.
Every World Bible makes the next one faster.

2
72

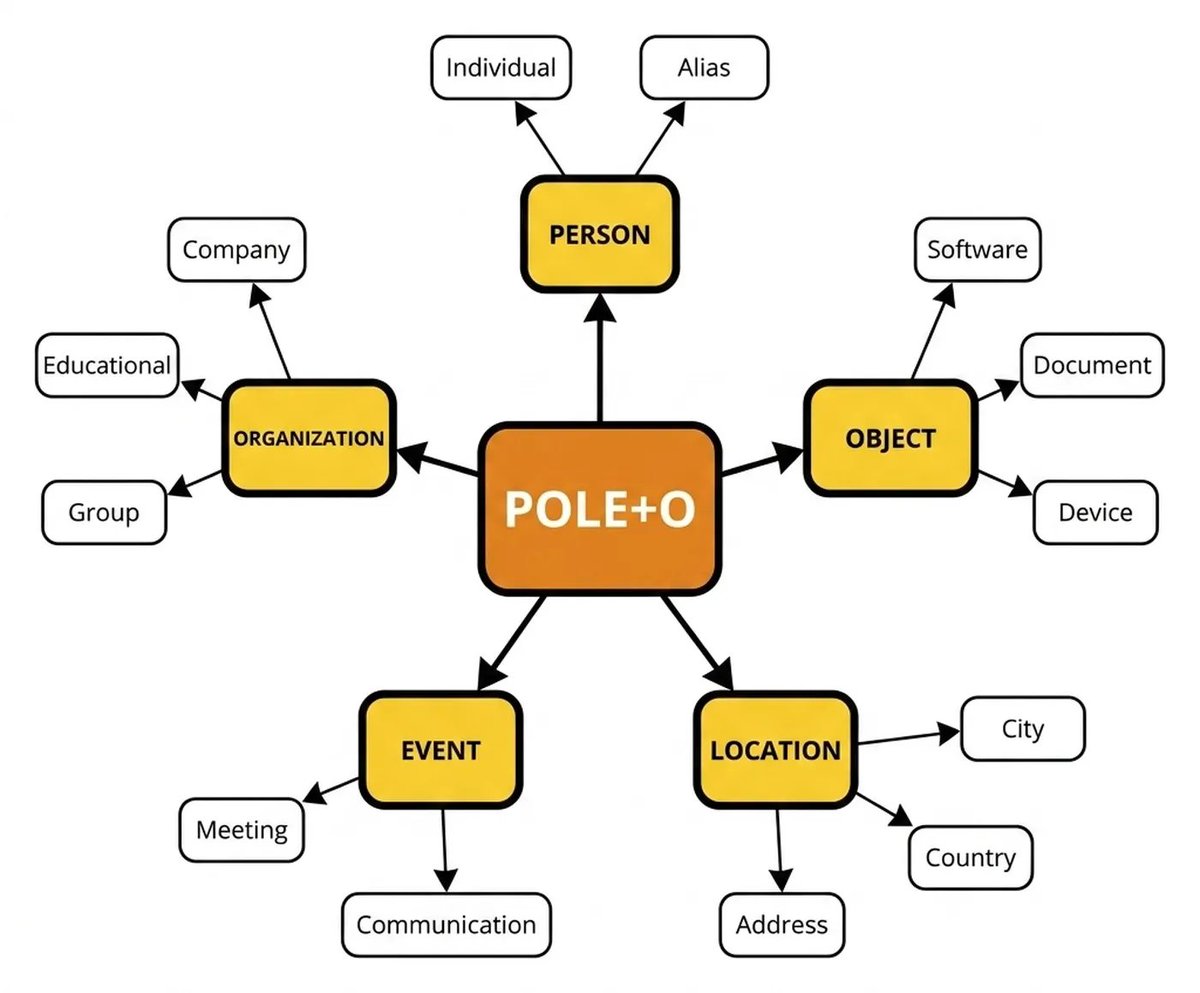
POLE O: The 5-Type Ontology That Solves the Hardest Part of Building a Knowledge Graph
Every knowledge graph project starts the same way. Someone opens a whiteboard and asks: "So... what are our entities?" What follows is a multi-day debate about whether a "meeting" is a node or a relationship, whether "location" deserves its own type or is just a property, and whether the schema should mirror the source database or represent some idealized domain model.
There's an anchor that solves this.
POLE O defines five base entity types drawn from decades of use in intelligence analysis:
Person - Any human entity
Organization - Groups and companies
Location - Places, physical or logical
Event - Things that happen
Object - Everything else
The power isn't the five types themselves. It's how domain-specific types layer on top using a multi-label system. A Patient is a :Person:Patient. A Sprint is an :Event:Sprint. The base type is always there. The domain type adds specificity.
This gives you two things flat schemas don't: the ability to query across domains at the base level, and automatic unification when connecting data from multiple sources.
POLE O doesn't answer every modeling question. But it answers the first one. And starting matters. A knowledge graph you can query in week one teaches you more about your domain than a schema you've been debating for a month.
When Paul Paul Iusztin first encountered the ontology concept, he assumed he had to study his domain in depth. To model all of finance, for example, and design the ideal ontology before working with any real data.
You can’t actually do that before you have a system running and data to look at. You just pile up assumptions that mostly turn out wrong.
Every knowledge graph solution stayed on the laptop and never got used, because he was waiting on an ideal ontology he could never reach. Without understanding the ontology, he couldn’t even write a decent extraction step to populate it. He was deadlocked, bringing 0 value.
The breakthrough was realizing you need a couple of models that let you start generic and extend over time. As I get more data, analyze it, and actually understand my problem, the schema evolves.
decodingai.com/p/ship-a-know…
By Konrad Kaliciński
medium.com/neo4j/pole-o-the-…
#KnowledgeGraphDesign #OntologyEngineering #DataModeling #GraphSchema #InformationArchitecture
--
Connected Data London 2026 | 11–12 November | Leonardo Royal Hotel London Tower Bridge
🎤 Share your work with the world's most passionate data community. The Call for Submissions is open.
connected-data.london/2026-c…
🎟 Tickets on sale now. Early bird discounts up to 30%. 2026.connected-data.london?u…
📺 Sponsorship opportunities available. Contact info@connected-data.london for details.
#KnowledgeGraph #GraphRAG #Ontology #Graph #AI #DataScience #GraphDB #SemTech
2
55

How do you build context-aware AI applications that go beyond simple vector search?
GraphRAG (Retrieval-Augmented Generation) combined with knowledge graphs is changing how LLMs access complex, relational data.
In her latest technical guide, JAX London speaker Jennifer Reif outlines how to build a robust GraphRAG application using the Spring AI Advisor API and Neo4j.
Key Technical Takeaways:
- Standardized Architectures: Leveraging the Spring AI Advisor API to create modular, swappable components for your AI stack.
- Navigating Relationships: Utilizing Neo4j vector stores to map out intricate data connections and entities.
- Advanced Context Chaining: Connecting structural graph data with semantic search to provide richer context to your LLM.
This walkthrough is perfect for software architects, senior developers, and technical leads looking to bring enterprise-grade AI into production.
Read the full breakdown here:f.mtr.cool/fvwdaoadln
#JAXLondon #EnterpriseAI #SoftwareArchitecture #Java #AIEngineering
16

Data & Analytics: sei trend AI che cambiano le imprese: Dalla AI sovrana al GraphRAG, passando per governance e data streaming: i sei trend Gartner che ridefiniscono il mondo Data Analytics nelle organizzazioni nei prossimi due anni. dlvr.it/TT3lJQ
3

4h
THIS 13-YEAR-OLD FROM THAILAND SOLVES CODEFORCES PROBLEMS IN 49 SECONDS AND BUILDS GAME WORLDS FROM OXFORD RESEARCH
C in VS Code, Codeforces in the browser, terminal running tests - 49 seconds and the problem is solved
he applies the same approach to world-building
Graphify turns Oxford papers into a graph with every connection between characters, locations and events
GraphRAG makes the graph queryable - ask "who controls the northern territories and why" and get the full political logic with documented causes
CAMEL AI populates the world with agents that make their own decisions instead of following a script
result: a game world where economies follow real principles, wars have documented causes and characters behave like living people
Ubisoft keeps teams of 50 just for world-building - he replaces all of them with three free repos and a $20 subscription
three repos, Oxford data, the right prompts - and a world ready to sell built in a few hours
9
4
45
1,648

Here is the CLI working; graphRAG is really efficient for code-base relational chunking and retrieval.
Check this out: github.com/reloaddd/Agent-PN…
15

Vector search is powerful.
But when your answers depend on relationships, permissions, lineage and exact business logic, embeddings alone can break under real production demands.
Graph RAG changes the game by retrieving meaning through structure, not just similarity.
That means better precision, cleaner reasoning and systems your team can actually trust, automate and scale.
Why […]: alexsmale.com/graph-rag-in-p…
The hard bit isn't finding similar text, it's proving the answer should've been seen at all.
Graph RAG helps keep context, access and source history intact.
That's where trust starts. #AI #GraphRAG #Data

7
priya joseph retweeted

Our recent work on using multivariate additive networks (arxiv.org/pdf/2605.21994) to explain GraphRAG outputs is now officially a part of pytorch-geometric 🕸️
github.com/pyg-team/pytorch_…
catch @mayabechlerspei presenting our preliminary results in KnowFM at #ACL26 next month!

1
10
605

Hey, thanks for sharing. We also have a ref to follow for graphrag, coz graphrag vector search is deadly combination.
Here it's: qdrant.tech/documentation/ex…
4

building FalkorDB, a graph database purpose-built for GenAI workloads like GraphRAG, Agentic Memory and Text2SQL. count me in for Boardy Pro
1
26

Built a multi-agent (A2A) orchestration system using Google ADK, Semantic Scholar MCP and GraphRAG with a gated evaluator agent for quality control and feedback loop. Also, created Financial Hybrid RAG on 1 million chunks of SEC 10k filings.
92

16h
Basically instead of having to use 3 diff databases for your data if you want graphrag normal database, it comes as an all in one package!
Kinda like an everything DB, where ur agent/applications can query wtv they need!
21

17h
for people interested to know more about the application of knowledge graphRAG
Jun 14

everyone who's shipped code and worked in a production environment knows the feeling.
something breaks. something that was working just stopped and it's in a part of the codebase you didn't write
and the real question isn't "what does this code do?"
it's:
- what's connected to this?
- what's the history here?
- what change touched this service?
- who shipped it?
- what's about to break next?
so the obvious move is to ask an llm: chatgpt, claude, your ai ide: "what's related to this bug?"
and it hands you a confident wall of text sounds good, maybe even relevant, but it's guessing based on words that are semantically similar!!
vector search finds text that reads like your question.
but "sounds similar" and "is actually connected" are completely different things and in a serious environment, that gap is everything.
a bug, the jira ticket, the pr that fixed it, and the engineer who reviewed it might share zero keywords.
a human follows that chain on instinct similarity search has no thread to follow so it fills the gap with a plausible hallucination.
so i built TraceRAG.
-a retrieval engine | an observability layer
that doesn't just search text
it builds a knowledge graph out of it, and lets you observe the whole thing.
-then it answers by walking that graph and lets you watch it happen, live.becomes a link.
then it answers by walking that graph and lets you watch it happen, live.
-every claim is clickable. no black box. you audit the answer instead of trusting it.
here's how it works and why "rag you can see" is the part everyone's been missing 👇🏻
2
101

Build a unified memory system for agentic platforms, AI data operating system. Or those building graphRAG Synapcores.com
19

80% of GraphRAG projects would improve if they deleted half their entity types.
4
122

I Turned 34 Tech Radar PDFs Into a GraphRAG System burakince.com/post/i-turned-…
3