
🔥 Multi-modal images stumped traditional matching? MS-POFT cracks NRDs with phase-structured detection multiscale descriptors! 🚀 1.36 lower RMSE, 100% image pair success—game-changer for remote sensing/medical! 1177 views & counting 👀 #ImageMatching #RemoteSensingTech #AIbreakthrough #GeoAI #MultimodalMagic Link[doi.org/10.1080/10095020.202…]

ALT Figure 16. Matching results under other datasets of the MS-POFT method.
1
10
308

18 Sep 2025
stress testing #ObjectReact on @UnitreeRobotics GO1 with dynamic changes
- no training for such cases
- no semantic filter
- no explicit traversability / ground plane
simply emerges from #ImageMatching to detect 'unseen' wrt prior experience
object-react.github.io/
#CoRL2025
12 Sep 2025

Excited to share our #CoRL2025 paper:
ObjectReact: Learning Object-Relative Control for Visual Navigation
A learnt controller conditioned on "WayObject CostMaps" - an intermediate, high-level, visual representation of object-level path planning costs
object-react.github.io 🧵
5
502

31 Mar 2025
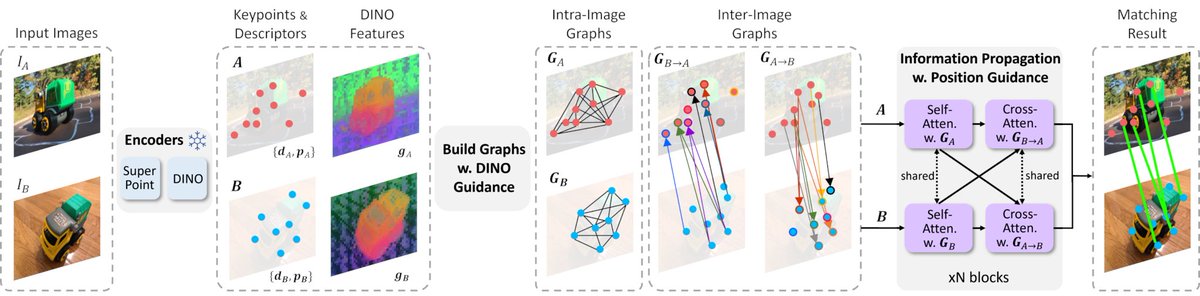
📢 MatchAnything: Universal Cross-Modality Image Matching with Large-Scale Pre-Training
MatchAnything presents a powerful large-scale pretraining framework for universal image matching across modalities, enabling detector-free matchers (ROMA, ELoFTR) to handle unseen cross-modal registration tasks without fine-tuning.
Key Highlights:
✅ Universal Cross-Modality Generalization – Handles 8 unseen real-world tasks (CT-MRI, PET-MRI, thermal-visible, SAR-visible, etc.) using a single pretrained model.
✅Cross-Modal Stimulus Signals – Uses synthetic pixel-aligned translations (e.g., visible→thermal, night, depth) to learn appearance-invariant structural matching.
✅Multi-Source Data Mixture – Combines multi-view geometry (MegaDepth, BlendedMVS), unlabeled videos (DL3DV), and warped single-image datasets (GoogleLandmark, SA-1B) to boost diversity.
✅Plug-and-Play with Detector-Free Models – Works with ROMA (dense) and ELoFTR (semi-dense) unmodified.
✅Video-Based Coarse-to-Fine Supervision – Extracts long-range pseudo ground truth matches from videos using multi-view refinement, enabling learning under perspective shifts.
✅SoTA Performance – Up to 423.7% accuracy gains on cross-modal registration over existing baselines across medical, histology, remote sensing, and navigation tasks.
✅Efficient Inference – Matches original model runtimes (ELoFTR: 40ms, ROMA: 303ms @ 640×480).
✅Also Strong on Single-Modality – Retains competitive performance on standard RGB tasks (e.g., FIRE retina dataset).
Paper: arxiv.org/pdf/2501.07556
Project Page: zju3dv.github.io/MatchAnythi…
Github: github.com/zju3dv/MatchAnyth…
Related articles from LearnOpenCV:
1. Introduction to Feature matching: learnopencv.com/feature-matc…
2. MASt3R: Grounding Image Matching in 3D: learnopencv.com/mast3r-sfm-g…
3. Chrome Dino game bot using OpenCV Feature Matching: learnopencv.com/how-to-build…
4. Video Stabilization Using Point Feature Matching in OpenCV : learnopencv.com/video-stabil…
#ImageMatching #foundationalModel #LoFTR #Research #opencv
1
10
688
25 Mar 2025
🚀MASt3R and MASt3R-SfM Explanation and Results
MASt3R (Matching and Stereo 3D Reconstruction) approaches image matching as a 3D problem, leveraging dense correspondences and a deeper understanding of the 3D scene rather than relying on traditional 2D methods. This has led to a paradigm shift in the field of 3D reconstruction.
In this article, we will primarily focus on understanding MASt3R and MASt3R-SfM, which enable 3D reconstruction and matching in a single forward pass.
MASt3R-SfM can serve as a drop-in replacement for COLMAP-SfM in Gaussian Splatting.
Read Complete Article Here: learnopencv.com/mast3r-sfm-g…
#MASt3R #MASt3R_SfM #MultiViewStereo #FoundationalModels #3DReconstruction #ImageMatching
3
10
535

6 Jan 2025
🧾Image Matching: A Comprehensive Overview of Conventional and Learning-Based Methods
✍️@SVerykokou, Charalabos Ioannidis
🔗mdpi.com/2673-8392/5/1/4
#photogrammetry #computervision #imagematching

1
1
64

27 Dec 2024
Alright! The first iteration of the FireANTs documentation is out! 🤩 (link in replies)
No. More. Excuses. For access to blazingly fast and easily customizable medical (and non-medical) image matching. 🚀🚀
#medicalimaging #healthcare #imagematching #imageregistration
1
1
11
1,580
28 Nov 2024
FireANTs absolutely mogs SITReg (winner of LUMIR challenge) on the LPBA40 dataset, and has almost the same result on OASIS data too.
whats more? (contd..)
#medicalimaging #imagematching #imageregistration
1
1
4
868

one week to go for the paper submission:
Jul 8th, 2024 50sfm.fbk.eu
#photogrammetry #3D #computervision #SfM #imagematching #AI #SLAM @fusiello @RongjunQ @FBK_research @mapo1 @pix4d @lucacarlone1 @ducha_aiki @Jimantha @lcmorelli3 @ArrigoniFede
@FacultyITC @eccvconf

** 50 years of #SfM **
join our @eccvconf workshop in #Milan
50sfm.fbk.eu/
7 excellent invited speakers & challenging sequences
#photogrammetry #3D #imagematching #AI #SLAM @fusiello @RongjunQ @FBK_research @mapo1 @pix4d @lucacarlone1 @ducha_aiki @Jimantha @lcmorelli3

8
18
6,594

29 May 2024
1/5
📸OmniGlue: A new learnable image matcher designed with generalization as its core principle. It significantly enhances feature matching across novel image domains. #AI #ImageMatching #TechInnovation
1
1
2
81
** 50 years of #SfM **
join our @eccvconf workshop in #Milan
50sfm.fbk.eu/
7 excellent invited speakers & challenging sequences
#photogrammetry #3D #imagematching #AI #SLAM @fusiello @RongjunQ @FBK_research @mapo1 @pix4d @lucacarlone1 @ducha_aiki @Jimantha @lcmorelli3
30
87
18,175

22 May 2024
🤔Is image matching as good as airborne #laserscanning (ALS)?
We wanted to know and tested 5 different software tools for #imagematching.
read here 👉 tinyurl.com/35j2fd3y
@UniNMBU @NIBIO_no @kartverket @HansOleOerka #forests #pointclouds #remotesensing

1
5
11
629

1 May 2024
3/N ⚡Dive into the official release for a game-changing boost in your real-time vision applications built upon local features! #XFeat #ImageMatching #CVPR2024 #deeplearning
1
1
7
983

🔔 New article:
Yu et al. propose a radiometric and rotational invariant descriptor (#RRID) which uses the #monogenic signal for multimodal #ImageMatching.
🔗 doi.org/10.1080/01431161.202…
#IJRS #RemoteSensing #FeatureMatching
2
2
222
🔔 New article:
Zhang et al. present a #DeepLearning-based, #multitemporal #ImageMatching method for ❄️ #snow-covered imagery which considers both global and contextual features.
🔗 doi.org/10.1080/01431161.202…
#IJRS #RemoteSensing

2
235

18 Oct 2023
📢 ¡Vuelve #MadridMLMeetup! Un encuentro para compartir los avanzes en #MachineLearning.
🗓️ 25/10 ⌚ 18:30 h
Con Iago Suárez, de @Qualcomm XR Labs Europe; exploraremos la tecnología de #ImageMatching, fundamental en #VisiónArtificial! 👁️🚀
🚩Registro 👉 lnkd.in/dsuQs_pi

3
8
496

13 Jul 2023
Using #imagematching to quickly identify & analyze assets & rights post-production is simple. We’ll show you how in our webinar on July 19! Register for free now bit.ly/ACTIVO-W #FADEL #FADL

2
3
69

10 Jun 2023
Auror: Empowering Retailers and Police to Combat Shoplifters with AI
#AI #AIsoftware #artificialintelligence #Auror #Collaboration #Cybersecurity #imagematching #llm #machinelearning #organizedretailcrime #Police #Privacycompliance #privacyprotection
multiplatform.ai/auror-empow…
2
33
🔔 New article:
Yan et. al. propose a new method for multi-modal #ImageMatching based on Information Distribution Composite Feature (#IDCF), designed to address problems associated with automatic image #registration.
🔗 doi.org/10.1080/01431161.202…
#IJRS #RemoteSensing

2
18
2,093
Image Matching Challenge 2023 competition
is now open!
Final Submission Deadline: June 13, 2023
kaggle.com/competitions/imag…
#SfM #deeplearning #tiepoints #imagematching #photogrammetry @ducha_aiki #CVPR2023
We are organising the
4th Image Matching Workshop at #CVPR2023
image-matching-workshop.gith…
Paper submission deadline: March 19, 2023
Notification to authors: April 4, 2023
Camera-ready deadline: April 6, 2023
#SfM #deeplearning #tiepoints #imagematching #photogrammetry @ducha_aiki


5
14
3,882

17 Jan 2023
nut-tree/nl-matcher package received an update as well. It is now possible to apply an alpha mask to an input image to discard image areas when searching matches.
Expressed with an image:
#nutjs #opensource #javascript #typescript #desktopautomation #opencv #imagematching

1
2
101