
Apr 23
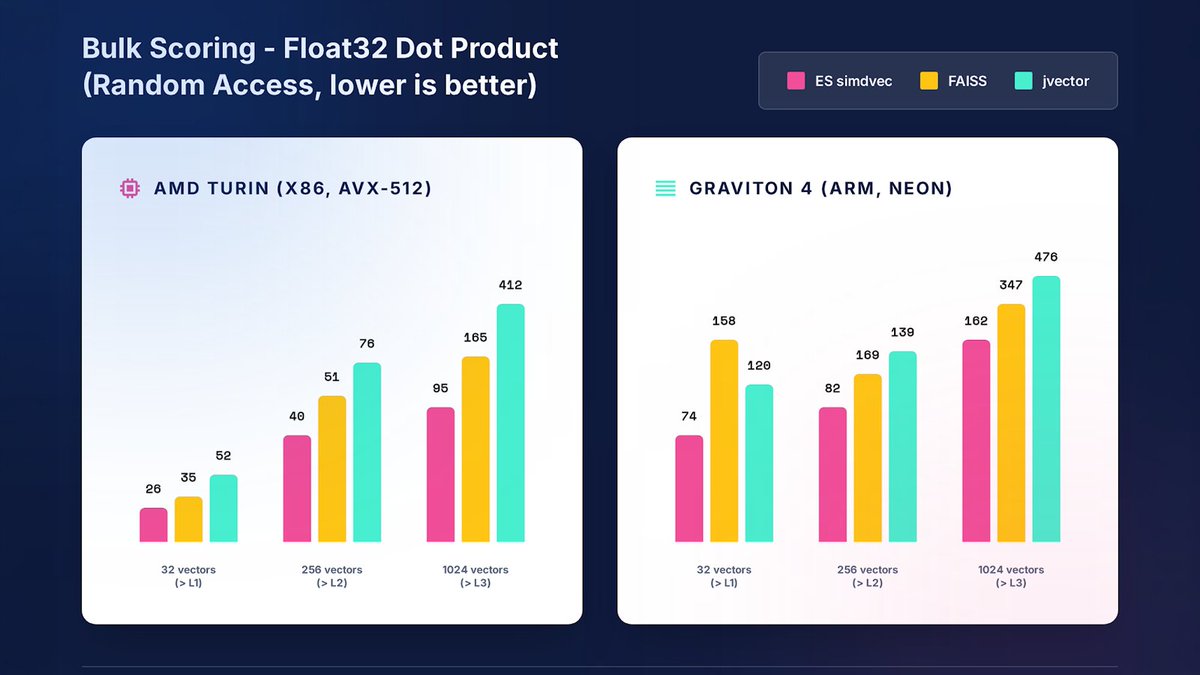
95 ns/vector vs 412 ns, Elasticsearch simdvec VS jvector scoring float32 at 32,500 vectors on x86.
But the number isn't really the story here. The story is that at scale, past L3 cache, memory latency beats compute every time and simdvec is built just for that.
At this depth, the kernel spends more time waiting for data than processing it. Prefetch too early and you've wasted the slot. Too late and you're stalling anyway. The window is narrow and simdvec times it right.
Explicit prefetch instructions on x86 pull the next vectors into cache while the current batch is still scoring. On ARM, interleaved loads do the same job differently. Either way, the pipeline stays fed.
Hardware counters show what that buys: 139K L1 cache misses drop to 19K. That's where the 4x gap lives.
The simdvec team wrote up the full architecture and benchmarks, including their hardware counter data.
31
56
699
10,726,087

Apr 15
What if #AI memory behaved like a living system—persistent, connected, evolving? Not rebuilt per request, but continuously growing. @MarkusKett explores this shift with a #Java-native architecture.
See how it works at scale: javapro.io/2026/04/15/petaby…
#GenAI #GraphDM #JVector

4
7
135

🔥 Dive into powerful #GenAI apps with pure #Java — hands-on at #JCON2026! 2h live coding with CTO @FHHabermann – no extra infra, just #JVector #EclipseStore. #VectorSearch persistence in one stack.
🎟️ Tickets: 2026.europe.jcon.one/worksho…
⚠️ Limited spots – seats almost sold out

2
2
75

Feb 16
#EclipseStore 4.0.0 Beta 1 is here! Build Java-native vector database apps inside your #JVM — no external vector DB needed. With integrated JVector HNSW similarity search, EclipseStore enables faster, simpler #GenAI development in pure #Java.
Read: javapro.io/2026/02/16/eclips…

3
4
136

The JVector architecture uses Product Quantization (PQ) to compress vectors into memory-efficient representations. The first pass of a search is performed using these compressed vectors in-memory, while the second pass reranks candidates using high-accuracy vectors read from disk via FFM-based MMIO. In production tests using the Deep100M dataset (35GB of vectors), JVector outperformed Lucene by a significant margin, achieving higher recall and lower latency by saturating the CPU's memory bandwidth through vectorized scoring functions.





Prepare for Project Valhalla: High-allocation systems using the Vector API must architect their code for Valhalla's value classes. This involves minimizing vector object leakage and maximizing method inlining to prepare for the transition to identity-less, flattened vector representations.
3
154

9 Dec 2025
🚀 ArcadeDB v25.11.1 is live!
We've integrated the JVector engine for high-performance vector search, critical SQL fixes, smarter indexing for embedded lists, and improved gRPC serialization.
github.com/ArcadeData/arcade…
#ArcadeDB #OpenSource #GraphDB #VectorDatabase #NoSQL
2
4
186



19 May 2025
DataStax has joined the OpenSearch Software Foundation to advance generative AI by integrating OpenSearch with its JVector vector search engine. #DataStax #OpenSearch #GenerativeAI #AIsearch #TechNews techday.com.au/story/datasta…
2
40

10 Dec 2024
My talk at @YavaConf today will cover how ANN indexes work and why JVector is the most advanced vector index in the world. It's the only talk on the first day's program marked Advanced, let's see if I can deliver on that!

1
2
236
14 Oct 2024
My interview with @adambien on why JVector 3 is the most advanced vector search index is live! Key takeaways:
1. JVector3 increases the effective index segment size by building with compressed vectors and reducing edge list heap footprint
🧵
2
3
10
1,273
Why JVector 3 Is The Most Advanced Embedded Vector Search Engine--an airhacks.fm podcast conversation with Jonathan Ellis / @spyced is ready to listen:
adambien.blog/roller/why_jve… #airhacks #java #podcast
1
4
11
1,237



8 Sep 2024
#ApacheCassandra 5.0.0 GA is out !!
⭐️ Vector Similarity Search (JVector)
⭐️ Storage Attached Indexes
⭐️ Unified Compaction Strategy
⭐️ Trie Memtables and Trie SSTables
⭐️ Java17
⭐️ Dynamic Data Masking
⭐️ Math CQL functions
⭐️ Pluggable crypto provider
⭐️ CQL scalar functions

1
12
41
8,590
19 Jul 2024
#ApacheCassandra 5.0-rc1 is out !!
⭐️ Vector Similarity Search (JVector)
⭐️ Storage Attached Indexes
⭐️ Unified Compaction Strategy
⭐️ Trie Memtables and Trie SSTables
⭐️ Java17
⭐️ Dynamic Data Masking
⭐️ Math CQL functions
⭐️ Pluggable crypto provider
⭐️ CQL scalar functions

ALT https://cassandra.apache.org/_/Apache-Cassandra-5.0-Moving-Toward-an-AI-Driven-Future.html
1
12
24
6,675
"JVector: Cutting-Edge Vector Search in Java" an airhacks.fm conversation with @spyced is ready to listen: adambien.blog/roller/abien/e… #jvector #cassandra #java #podcast
5
11
1,534

18 Jun 2024
At Berlin Buzzwords - Joel Knighton of DataStax gave an extremely detailed look at JVector. One of those "I thought I understood vector DBs, but I actually know nothing" moments
youtube.com/watch?v=nTRSu-vL…
4
8
655

31 May 2024
Indexing all of Wikipedia on a laptop with JVector
foojay.io/today/indexing-all…
Discussions: discu.eu/q/foojay.io/today/i…
#java #programming
1
2
99