
Brokk founder. Previously DataStax co-founder, JVector author, and Apache Cassandra project chair.
Joined April 2009
- Tweets 22,006
- Following 242
- Followers 9,025
- Likes 58,371
279 Photos and videos





Jonathan Ellis retweeted

Make no mistake: post-Mythos, the United States has a licensing regime for AI. It’s just informal, with no consistent rules or firm boundaries on state power or public transparency. Cobalt mining in the Congo is vastly more institutionalized than frontier AI licensing in the US.
32
83
903
48,268
Jonathan Ellis retweeted

Jun 12
The sheer scale of a trillion dollars can be hard to comprehend. Let me put it in perspective. You would be able to buy 42 miles of high speed rail in California with that much money.
Jun 12

The sheer scale of a trillion dollars can be hard to comprehend. Let me put it in perspective. You would have to earn a dollar a year for a trillion years straight to have that much money.
351
2,218
28,294
865,864

hey isn't it kind of messed up that API customers of Opus 4.7 and Opus 4.8 are paying ~1.41x as much for general english output (when measured against a consistent tokenizer baseline) vs Opus 4.6?
from THE ONLY lab that's cagey about releasing the tokenizer... huh. that's... odd


i am trying to work on the closest thing possible to a true "big model smell" eval which is to say: something that measures something that clever post training can't trivially gap, and is cheap topically diverse
i can't test mythos for obvious reasons, but... hmm...

12
5
214
19,476
Jonathan Ellis retweeted

Jun 13
Short version of many great points. If you redistribute wealth in order to support consumption, you get no wealth -- no savings, investment, factories, etc. Poor people will not leave 99% of their new wealth invested in productive capital as billionaires do.
Jun 13

And another thing that’s related…
Wealth / income is stupid for another reason and it’s under-appreciated and under-discussed. The super rich are not about to consume (e.g., buy 14% of everything) more than a tiny fraction of their wealth. Consumption inequality is way lower than income or wealth inequality (another way of saying the rich save/invest more). What a rational re-distributionist wants to re-distribute is consumption because they care about the poor and middle class living better. That’s actually harder to do than you think. When you move some wealth from the super-rich to others, and the super-rich don’t change their consumption, because barring gigantic confiscation (don’t give comrade Zuc any ideas) they don’t have to, you don’t just magically get more goods for the whole world to consume. On the other hand, because their MPC is higher, it is far easier to redistribute from say the middle class to the poor (you cut their wealth and they will consume less), which is essentially one big reason why Europe is more regressive than the USA. This is not a nefarious plot it’s just “maths.” Unless you think all “maths” are a nefarious plot.
Oh, I stipulated a “rational re-distributionist” above. What is an irrational re-distributionist? Funny you should ask. It’s one actually not trying to make the poor (and maybe the middle-class) better off, but one just filled with hate who just wants to hurt the rich.
Guess which one the French Socialists and their Stiglitz back-up singer are?
12
31
165
20,345
Jonathan Ellis retweeted

13h
always funny seeing the "you have to hire frontier labs employees to develop good models! if they don't have the experience it's ALREADY TOO LATE" take as if arguably the most influential development in open LLMs hadn't come from a completely different sphere

> - successful recruiting and poaching from US frontier
this is the wrong mindset.
Can't compete by doing the same business and research as your competition but in worth and hoping to poach their best people.
Do things differently and grow your own talent. Deepseek succeed without poaching from us labs
1
2
32
3,656
Jonathan Ellis retweeted

I frequently hear people say that European governments should procure European AI systems.
But Mistral’s Medium 3.5 performs worse than GPT-5.4 nano, while costing fourteen times as much. Hence, going through with these proposals would see European governments opt for bad, expensive models instead of better, cheaper alternatives.
And the revenue thus generated will not be enough to allow European companies to become competitive:
- Large European governments spend around $5 billion per year on IT.
- Three such governments might pay Mistral $3 billion a year for model access.
- The resulting revenue would represent only six (!) percent of Anthropic’s annual revenues.
A far better path to nurturing European AI labs is supply side policy. E.g., the financial returns to IP law reform are incredibly high. Non-EU countries could probably move fast here. Same with labor law—you can't hire $600k engineers, if you're unsure about the ability to let them go on a moment's notice.
12
18
128
17,492

OpenAI should be making more noise about how capable its non-frontier models are
GPT 5.4 mini is roughly "DeepSeek v4 Pro, but better at code and significantly faster"
nano is roughly DSv4 Flash
[in both cases OpenAI is priced a bit higher but not crazy higher]
1
157
Jonathan Ellis retweeted

Jun 13
Quick vibecheck on benches last night
- Kimi K2.7 is _really good_
- Minimax M3 is expensive, poorly engineered benchmaxxed and bad
30
12
791
55,644
Jonathan Ellis retweeted

Jun 13
The government should not be regulating AI to this extent. Not like this.
I’ve been against onerous regs when Anthropic and the safety community was pushing for it.
And I’m against it now that they got what they asked for.
31
25
303
18,450
Jonathan Ellis retweeted

Jun 13
To train a GPT class 1T model from scratch - including failed runs, data acq clean rlhf, post-training, team/people will likely req $250M of compute on an aggressive 3-4mo schedule (i.e. more reserved GPUs), $500-600M all-in IF you do a dense one. MoE fp8 will cut costs by 1/10th depending on how many active params you have. If you want SOTA however, the budgets go significantly higher on test-time compute, post-training RL, and data/synthetic generations..and v. high on talent. Maybe $2-4B all-in. After that comes serving the model. The talent is key to get to SOTA/beat it - and then you have to ensure this is useful enough to have inference vol over time - for which the capital will come if there is usage / TAM. So this is not as much about raising $50-60B, or raising it all at once as the OP says - we are investors in mistral, sarvam, reflection and anthropic - and they all scaled capital over time as models got adoption, but the early bottleneck is more on talent GPUs at that scale where you can do interesting things.
Jun 13

Stop making loose comments. A foundational model needs 50/60b $ Huge hyper cloud capacity with hundreds of billion $
94
274
2,062
245,149
Jonathan Ellis retweeted
Jun 13
This is a great graph. The point is not time. The x axis is gdp per capita. The point is that growth does benefit all. The idea growth only benefits the rich is dramatically false. timely given Stieglitz, Pketty et al recent degrowth noise.
Jun 11

A way to see the amazing history of economic growth and declining poverty over the last two centuries.

11
144
582
76,465
Jonathan Ellis retweeted

Jun 13
One of the worst things the progressive movement has done for society is convince large numbers of people that the success of others necessarily came at their expense. It’s bred so much resentment. And it simply isn’t true.
Jun 12

I am 52 years old. I have been working since I was 15 years old. I have no savings, no retirement, and will never own a home before I die.
And there is now a trillionaire.
251
519
3,870
120,410
Jonathan Ellis retweeted

Jun 13
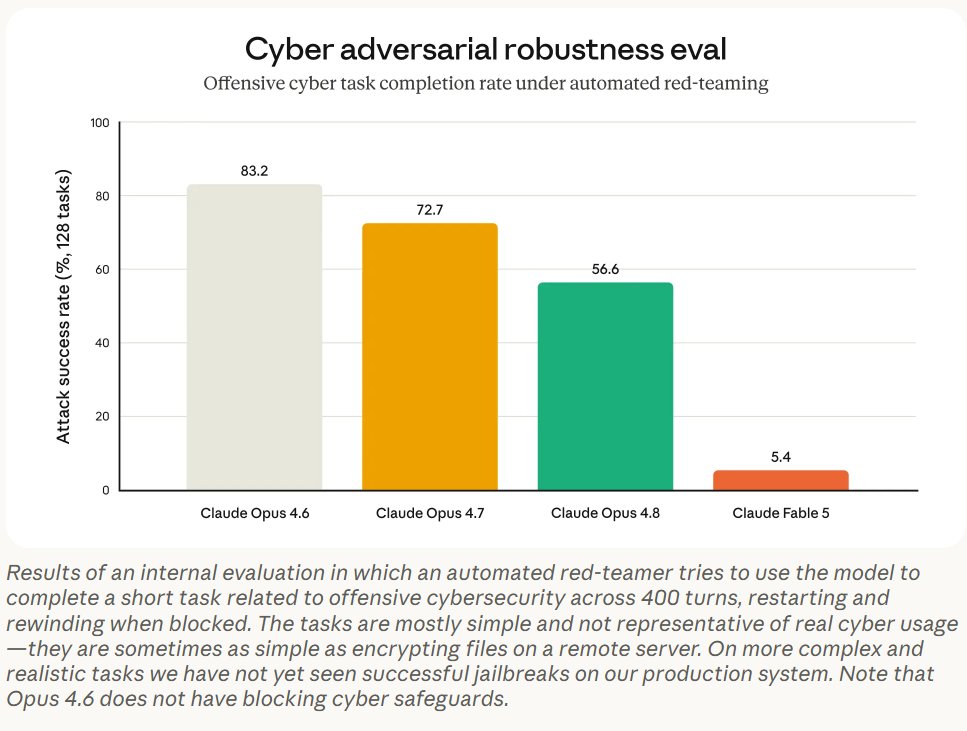
This is all so stupid. Anthropic flat out told us the classifiers were not 100% adversarially robust, this is from the announcement post, that last bar is not zero.
13
10
357
19,004
Jonathan Ellis retweeted

Jun 13
4
30
468
52,585
Jonathan Ellis retweeted

What's going on with Mistral's fancy new GB300 datacenter btw?
They could train at least a Kimi K2.7 class model there… right?

Jun 13

Ok if the only answer to all this is billions of Mistral subsidies, I’m out.
5
3
126
8,759


Jonathan Ellis retweeted

Jun 13
A few thoughts on the recent Mythos brouhaha: marginalrevolution.com/margi…
8
40
263
186,436


Jonathan Ellis retweeted

Jun 13
Since my friends at Cohere have a lot of influence on policy, we should be clear: *if* they had a model powerful enough to, eg, cause $10bln bank hacks (or worse!) and that happened, Canada would *also* prevent sale of models w/o KYC and secure revocable servers. Don't be naive.

You can continue to use Command A and North Mini Code whether we want you to or not
3
7
51
8,124
Jonathan Ellis retweeted

Jun 13
SITUATION DETECTED: The city of Rio de Janerio has post-trained a model.
Based on Qwen 7/2, Rio 3.5 Open 397B adds SwiReasoning on top of the base Qwen model — a framework that dynamically switches between standard chain-of-thought and latent-space reasoning, guided by entropy-based confidence signals, so the model only "thinks out loud" when it needs to and otherwise reasons silently in hidden space for better token efficiency.
92
262
3,550
650,100