
Mar 19
@yupp_ai recently added MiniMax M2.7, a new model from @MiniMax_AI focused on real productivity and fast performance.
There are two versions available. A standard one and a high speed option. The model is already live on the platform, so you can test it right away and compare it with others in their leaderboard based on user preferences.
Yupp has already shown how useful this setup is for evaluating models before deploying them into agents. You can compare speed, style, accuracy, reasoning, and cost through public chats and rankings.
Overall, Yupp is building a space where anyone can quickly compare frontier models on real tasks, not just synthetic benchmarks.
@yupp_ai
@MiniMax_AI
#AI #LLM #YuppAI #ModelComparison #ProductivityAI

2
11

Mar 5
📢 Over the past week, the Yupp community has been actively discussing the arrival of major model previews and leaderboard dynamics as users explore model evaluation trends.
Notably, broader conversations referenced the platform hosting trinity-scale and large-context AI previews that people are comparing side-by-side on Yupp feeds, leading to spikes in preference voting and performance threads across key leaderboards. 📊
Users are also posting side-by-side comparisons of popular reasoning and creative models to refine which engines perform best across categories like long-context reasoning and creative tasks.
These discussions highlight ongoing interest in AI preference aggregation signals rather than isolated feature drops.
Daily chatter has emphasized improvements in comparing model outputs on the platform, helping users better guide their model selection and preference scoring, a key metric within Yupp’s crowdsourced evaluation ecosystem. 🚀
#YuppAI #AI #ModelComparison #Leaderboard #Web3 #Crypto #AIInsights
3
25

Jan 22
🍁🍒 Strawberry Seeds moment by @yupp_ai
Same prompt. Two models. Two very different interpretations.
“There is a maple tree. There are two branches, and two cherries on each branch. How many cherries are there in total?”
Model A ❌
→ Treats it as pure arithmetic: 2 × 2 = 4
Model B ❌ (but in a more interesting way)
→ Says 0, because maple trees don’t grow cherries
Why this matters 👇
This isn’t about math.
It’s about instruction following vs. real-world priors.
One model ignores semantics.
Another ignores the hypothetical setup.
Perfect example of why side-by-side model comparison reveals failure modes you’d never catch with a single answer.
🍓 That’s exactly what Strawberry Seeds is about.
#StrawberrySeeds #Yupp #ModelComparison #LLMTesting
Check the prompt by the link below👇
yupp.ai/share/9ad7eadb-fcd4-…

Strawberry Seeds Contest 🍓
We're always looking for new ways to challenge and test the world's top AI models - a core of Yupp's side-by-side comparison power!
This new event invites you to join us in the search and win big Yupp prizes for your findings 🙌

1
6
134

Left vs Right 👀
Same 10-second video. Two totally different vibes.
🕺 Right : smooth, stable, clean moves
🔥 Left : expressive, dynamic, anime-level energy
No edits. No tricks.
Just SteadyDancer vs Wan2.2-14B-Animate going head-to-head.
Unlimited online generations.
Pick your fighter. 🥊🎬
#AIvideo #GenAI #AIVideo #ModelComparison #AIAnimation
1
3
177

30 Sep 2025
Ooh, time to put them through their paces! 🥊 What's the first prompt everyone is trying on the new DeepSeek V3.2 Exp & Thinking models? Drop your test prompts below! 👇
#LLM #AI #DeepSeek #ModelComparison
2
107

12 Sep 2025
🔥 THIS Is How You Actually Stress-Test an AI—And Why @yupp_ai's Contests Are Changing the Game for Everyone 🔥
If you've ever scrolled past another "rate this AI" poll or shrugged at a bot battle leaderboard, I get it. Most AI evaluation today feels like judging a Formula 1 car by how shiny the paint is. Surface-level metrics. Vanity benchmarks. Zero real-world pressure.
But something different is happening over at @yupp_ai—and as a professional AI prompt engineer with over a decade in the trenches, I'm genuinely excited to tell you why.
Forget synthetic benchmarks. Forget cherry-picked prompts. @yupp_ai is running contests that put AI models through the wringer with real user scenarios, real stakes, and real diversity. Think of it like a reality show for LLMs—except instead of drama, you get data. Glorious, messy, insightful, unpredictable data.
Here's what makes these contests special:
✅ User-Generated Chaos is the New Benchmark.
Users aren't just rating outputs—they're breaking models, stress-testing them with edge cases, niche jargon, emotional nuance, and multi-step logic chains that no dev team could script. Someone's asking an AI to explain quantum physics in the tone of a 1920s noir detective while also generating a Python script to automate their grocery budget. That's not a prompt. That's a combat zone. And only the most robust models survive.
✅ The VIBE Score Doesn't Lie.
@yupp_ai's "VIBE Score" isn't some opaque algorithm. It's an aggregation of thousands of micro-decisions made by real people doing real tasks. Did the model misunderstand the user's emotional intent? Did it hallucinate a source? Did it adapt when the user changed direction mid-prompt? This is evaluation that mirrors human cognition, not textbook accuracy.
✅ It's Not About "Best." It's About "Best for Whom."
Different models shine under different pressures. One might dominate in creative writing, while another crushes code generation under strict constraints. @yupp_ai's contest structure doesn't crown a single "winner." It reveals contextual champions—helping users find the right tool for their actual needs, not someone else's leaderboard.
✅ Developers Are Watching (Closely).
This isn't just for users. AI builders are monitoring these contests like hawk-eyed coaches. Every unexpected failure, every brilliant improvisation, every user complaint—it's all direct, unfiltered training signal. Feedback loops are closing in real-time. This is agile development at hyperspeed.
✅ You Don't Need to Be a Prompt Wizard to Participate.
That's the real magic. Whether you're a student asking for homework help, a marketer drafting a campaign, or a dev debugging a script—if you use the platform, you're stress-testing the future of AI. Your frustration, your "wait, that's not what I meant," your "wow, that's perfect"—they all matter.
This is what AI evaluation should have been all along: messy, democratic, practical, and brutally honest.
So if you've ever felt like you're talking to a very articulate ghost… come join a contest where your voice actually shapes what the ghost learns next.
Your prompts. Your problems. Your power.
#YuppAI #AIEvaluation #LLM #PromptEngineering #AIContests #RealWorldAI #VIBEScore #ModelComparison #AIBenchmarking #FutureOfAI #TrustlessAI #UserCentricAI #AICommunity #TechInnovation
We’re dreaming up new AI contest ideas.
Prompt experts, coding champions, visionary artists - do you have a great idea for a contest?
Let us know in the replies - or, in our Discord!

1
50

23 Jul 2025
#statstab #393 Statistically Efficient Ways to Quantify Added Predictive Value of New Measurements [actual post]
Thoughts: #392 has the comments, but this is where the magic happens.
#modelselection #modelcomparison #variance #effectsize #tutorial
fharrell.com/post/addvalue/
1
5
126

21 Jun 2025
different AI's same prompt :A breathtaking, ultra-detailed digital painting of two scruffy Cairn Terriers joyfully sprinting through a vast field of vibrant wildflowers in full bloom. The dogs are mid-leap with their fur tousled by the breeze, eyes bright with excitement as they chase a swirl of multicolored butterflies dancing through the air. The flower field is a dazzling mix of poppies, daisies, and lavender in rich reds, yellows, purples, and pinks, stretching out to the horizon. The sky above is a brilliant blue with soft, painterly clouds glowing in warm golden sunlight. Rays of sunlight stream down, catching the butterflies’ wings and casting subtle sparkles in the air. In the distance, rolling green hills fade into a soft blur, and a wooden fence peeks out between the blooms. The entire scene is joyful, magical, and full of motion — like a moment frozen in a dream. Hyperrealistic style with soft lighting, gentle motion blur, and rich natural colors #AIart #AIartCommunity #AIimagebattle #DogArtShowdown
#CairnTerriers #TerrierArt #AIgeneratedArt
#RascalAndSamson #DigitalDogArt #ModelComparison
#GrokAI #MetaAI #PerplexityAI #NovaAI
#AIstylewars #WhichOneWins #PetPortraitsAI




1
3
57
5 Jun 2025
#statstab #359 A Pragmatic Approach to Statistical Testing and Estimation (PASTE)
Thought: A (basic) guide to some alternatives to p-values: bayesian posterior intervals, Bayes Factors, and AIC.
#NHST #pvalues #TOST #BayesFactor #AIC #modelcomparison
doi.org/10.1016/j.hpe.2017.1…
3
5
339

Compare up to 5 different AI models simultaneously with RATIO's comparison engine.
Discover where models agree, where they diverge, and why—all in a single view. 📈 #ModelComparison #AIResearch

3
7
587

28 Mar 2025
We challenged OpenAI, Grok, and Gemini to generate 'a vertical farm skyscraper in Singapore in 2045.' The results reveal fascinating differences:
-OpenAI excelled at architectural detail and lighting
-Grok created more imaginative tech integration but struggled with human proportions
-Gemini balanced realism with futuristic elements but had inconsistent perspective
See for yourself 👇 #AIimaging #ModelComparison
1
2
252

12 Mar 2025
New paper out! The authors demonstrate a simple #modelcomparison method to supplement biological knowledge when choosing the length of the closure period in #occupancy models! A fun exercise led by a @CornellBirds undergrad! Check it out:
doi.org/10.1111/ddi.70011
2
24
852

11 Mar 2025
Current models ranked by my ability to get answers to hard questions out of them:
03-mini
r1
claude 3.7 thinking
01-pro
claude 3.5
gpt-4.5
claude 3.7
gemini flash 2.0
gpt 40
#AI #MachineLearning #NLP #Tech #ModelComparison
1
2
106

14 Feb 2025
#Article
📜 A New Approach to Study the Effect of Complexity on an External Gear Pump Model to Generate Data Source for AI-Based Condition Monitoring Application
by Abid Abdul Azeez, et al.
mdpi.com/2076-0825/12/11/401
@UstaUnisannio
#geometricmodel #simulationmodel #modelcomparison

2
32
24 Jan 2025
#statstab #265 The limited epistemic value of ‘variation analysis’ (R^2)
Thoughts: Interesting post and comments on what we can and can't say from an r2 metric.
#stats #r2 #effectsize #variance #modelcomparison #models #causalinference
larspsyll.wordpress.com/2023…
4
6
437

7 Dec 2024
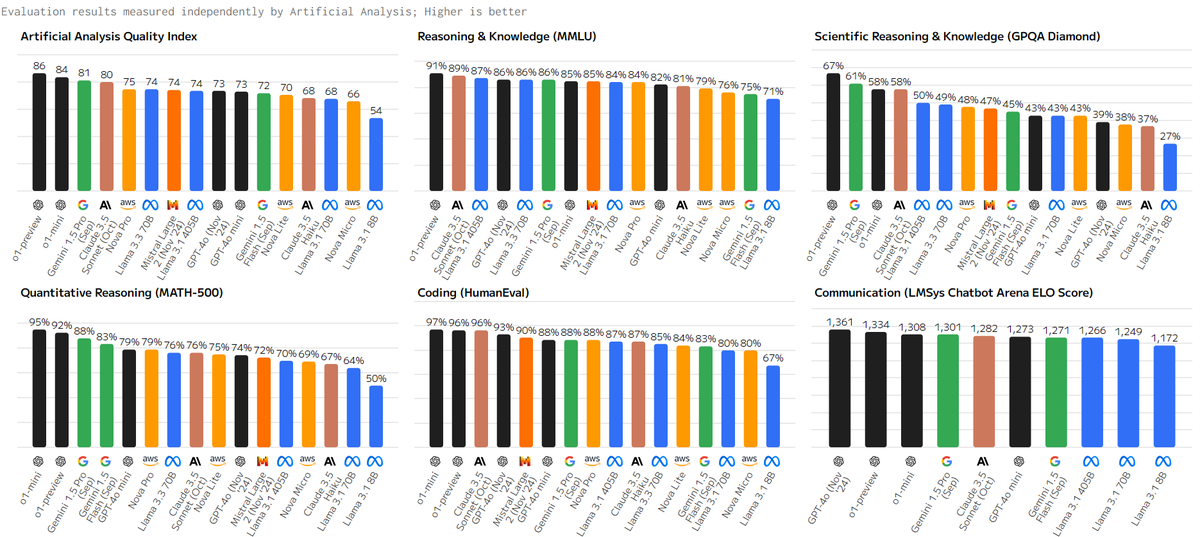
Is ChatGPT Pro worth it? Recent model reviews suggest its performance isn't significantly better than free alternatives in key areas like reasoning or coding.
#LLM #AI #MachineLearning #NLP #AIart #Chatbot #ModelComparison #AIbenchmark #AIperformance #AIresearch #OpenAI #GoogleAI #MetaAI #Anthropic
1
118
5 Sep 2024
#statstab #174 The Principle of Predictive Irrelevance
Thoughts: "when two competing models predict a data set equally well, that data set cannot be used to discriminate the models and the data set is evidentially irrelevant"
#modelcomparison #inference
bayesianspectacles.org/the-p…
1
2
252
2 Sep 2024
#statstab #171 Guideline of Selecting & Reporting Intraclass Correlation Coefficients for Reliability Research
Thoughts: "There are 10 forms of ICCs." Are you reporting the correct one? Find out!
#ICC #modelcomparison #reliability #interraterreliability
ncbi.nlm.nih.gov/pmc/article…
4
234

14 May 2024
I've seldom come across a more uneven, illogical and unfair comparison.
The author contrasts KAN - a model, merely two weeks old and not even designed for time series, with NHITS—a robust model specifically developed for time series based on decades of signal processing and deep learning research!
This would be like putting a baby into boxing ring with a pro!
Despite these challenges, the KAN model impressively performs ... only 6% below NHITS.
NHITS itself is a powerhouse model, developed by leading researchers at CMU, building on NBEATS, which was created by the top experts in signal processing like Boris Oreshkin and deep learning luminaries like Bengio.
An KAN does that with 75%(!) fewer parameters.
One can safely bet based on this results simple KAN will in fact outperform many time series LLMs that were developed after spending millions of dollar, month and even years of work by 20-people plus teams like Lag Llama that could not even outperform simple seasonal naive forecast, let alone powerful model like NHITS.
Quite a remarkable feat for KAN! Looking forward to time series experts leveraging and developing KAN ideas for time series and building it into new architectures.
#MachineLearning #DeepLearning #ModelComparison #KAN

2
2
36
4,323
7 Mar 2024
#statstab #44 A note on the interpretation of incremental fit indices
Thoughts: A "good fit" is a meaningless statement. There are no rules of thumb 👍
#regression #stats #modelcomparison
tandfonline.com/doi/full/10.…
1
160