
Jun 12
Zaibi Hanjra نوں ماڈل دے طور تے لین دا فیصلہ کیویں ہویا؟ سمی جٹ دی اندرونی کہانی سنا دیتی !
#ZaibiHanjra #SammiJatt #PunjabiMusic #PunjabiSong #MusicVideo #PunjabiIndustry #BehindTheScenes #ModelSelection #EntertainmentNews #PunjabiArtists #ViralInterview #TrendingNow #Punjab
13

#statstab #548 Checking model assumption {easystats}
Thoughts: The {performance} package is great at a one-function plot for assunptions. Good explanations also (bug theory limited).
#rstats #assumptions #linearity #linearmodel #r #modelselection
easystats.github.io/performa…

1
46

May 25
📢 #highlycited paper
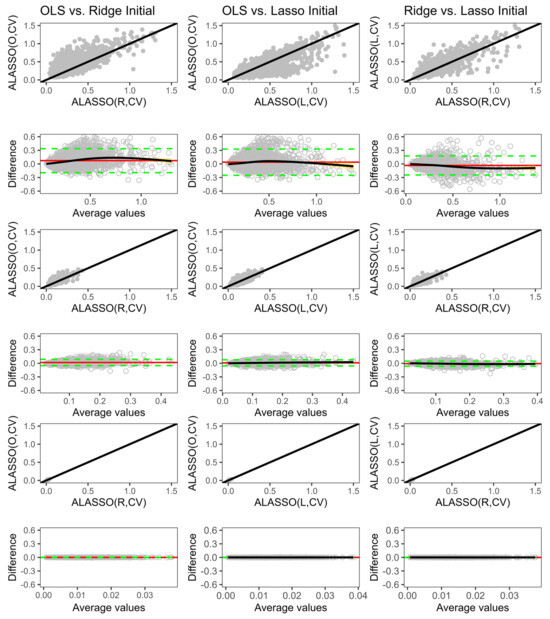
📚 Evaluating Prediction Performance: A Simulation Study Comparing Penalized and Classical Variable Selection Methods in Low-Dimensional Data
🔗 mdpi.com/2076-3417/15/13/744…
👨🔬 by Edwin Kipruto et al.
🏫 University of Freiburg
#modelselection #predictionaccuracy #penalizedregression
2
42

May 14
🚨 There are too many models to choose!
Whether you're shortlisting candidates before fine-tuning, picking among 500 models on OpenRouter, or searching through hundreds of thousands of checkpoints on HuggingFace, the question is the same:
Which model should you actually use for a new task?
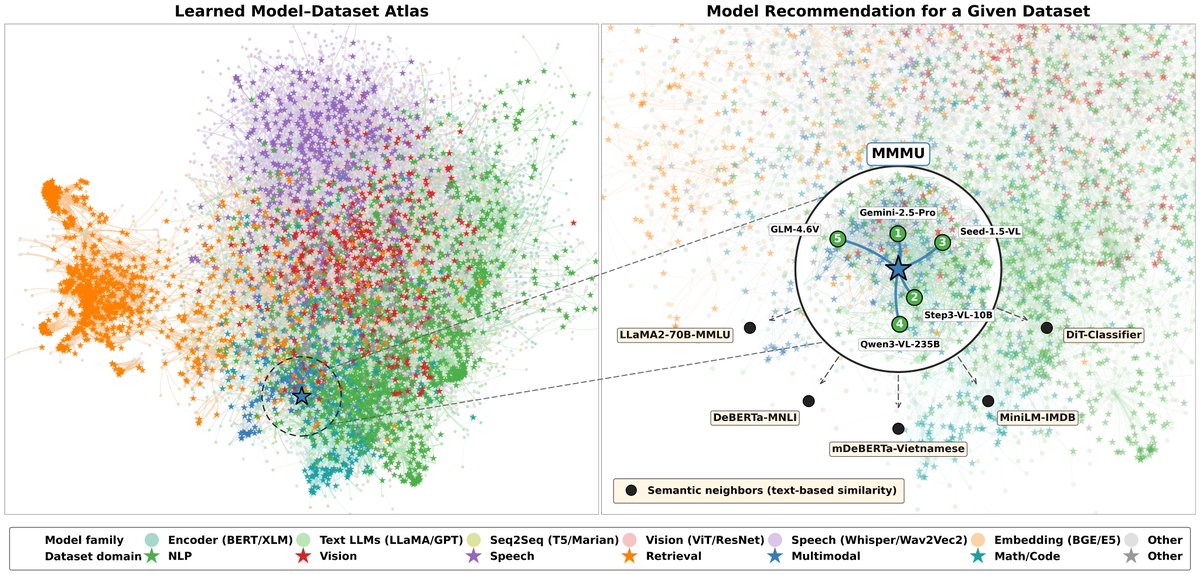
💡 Introducing ModelLens — a model recommendation system for the open-source model ecosystem.
Instead of asking users to evaluate or fine-tune every candidate model, ModelLens asks a different question:
👉 Can we leverage large-scale model–dataset interaction patterns from public leaderboards to enable model selection in the wild, without requiring direct evaluation or fine-tuning?
Our key insight:
The millions of (model, dataset, performance) records accumulating on all platforms are not just leaderboard noise. They encode how model capabilities align with task characteristics across the open-source ecosystem.
⚙️ How it works:
We collect large-scale model–dataset performance interactions from public leaderboards (HuggingFace, Open LLM Leaderboard, Papers with Code) and learn transferable model–task compatibility, jointly modeling:
- 47K models across 348 architecture families
- 9.6K datasets across 2,551 task types
- 8,420 heterogeneous evaluation metrics
- 1.62M historical performance records as implicit supervision
Given any task description, ModelLens then recommends a ranked Top-K pool of candidates likely to perform well, generalizing to newly released models and never-benchmarked datasets, before any of them is ever run on the target task.
task description → learned model–task compatibility → Top-K recommended models
📊 What ModelLens enables:
✅ Recommend Top-K models for a new dataset
✅ Rank newly released models against existing models
✅ Build model pools before routing or cascading
✅ Reduce costly brute-force evaluation
✅ Scale model selection in the open-source AI ecosystem
📰 Paper: arxiv.org/pdf/2605.07075v1
💻 Code: github.com/luisrui/ModelLens
🌐 Demo: huggingface.co/spaces/luisru…
Try the demo with your own task description — we’d love feedback from people working on model selection, routing, AutoML, and open-source LLM ecosystems.
Thanks to all coauthors: @Wenjie_Jacky_Mo @Xiaofei_Wen_Mk @qiyao_ma @WenhuiZhu8 @XiwenChen37 @muhao_chen @zpegt
#MachineLearning #OpenSource #AI #ModelSelection @OpenRouter @huggingface
5
15
23
1,477
Predicting Biomedical Interactions with Bayesian inference over Graph Convolutional Network Structures
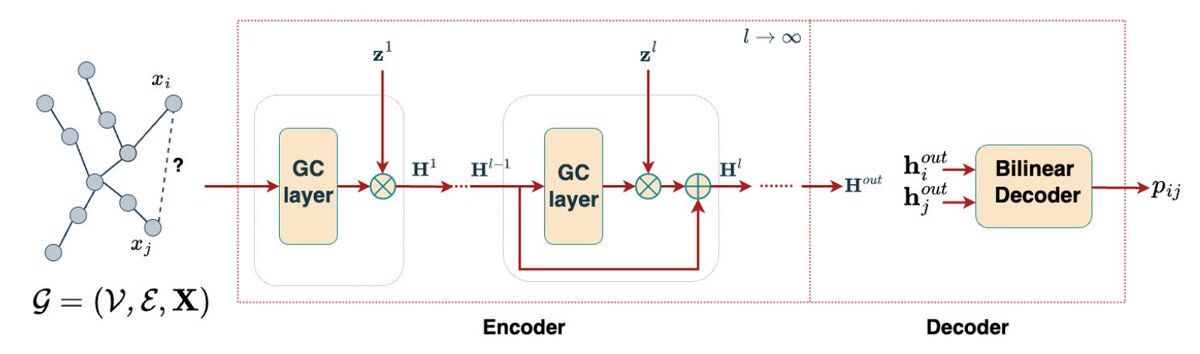
1. The authors identify a persistent bottleneck in graph neural network (GNN) application to biological networks: selecting the optimal number of graph‑convolution (GC) layers. Too few layers miss higher‑order interactions, while too many cause over‑smoothing and loss of predictive power.
2. To solve this, they introduce a Bayesian model‑selection framework that jointly infers the appropriate depth of a GC encoder and applies dropout regularization, allowing the network to adapt its complexity directly from the data rather than relying on heuristic layer counts.
3. The depth is modeled as a stochastic process via a beta process over layers, inducing layer‑wise activation probabilities. A conjugate Bernoulli process then gates neuron activations, effectively creating an encoder capable of an infinite number of layers in theory while only activating a sparse subset in practice.
4. For reconstructing interactions, a bilinear decoder maps node representations into edge probabilities. This end‑to‑end encoder‑decoder architecture eliminates the need for separate embedding and classifier stages.
5. The authors employ structured stochastic variational inference to approximate the intractable marginal likelihood, using a concrete Bernoulli relaxation for efficient gradient‑based optimization of both depth and dropout parameters.
6. Across four publicly available biomedical interaction datasets (DTI, DDI, PPI, GDI), the Bayesian GCN outperforms DeepWalk, node2vec, L3, VGAE, and fixed‑depth GCNs, achieving gains in AUPRC ranging from ~2–20% and AUROC improvements up to ~3%.
7. The framework also delivers better calibrated predictions: Brier scores are consistently lower than those of a fixed‑depth GCN, indicating more reliable confidence estimates for interaction probabilities.
8. Robustness tests show the method maintains high performance even on highly sparse networks, thanks to its dynamic neuron activation that scales with available training edges, whereas a fixed‑depth GCN activates all neurons regardless of sparsity.
9. Visualizing drug embeddings with t‑SNE reveals that the Bayesian GCN produces clearer, well‑separated clusters for drug categories, suggesting that the learned representations capture pharmacological similarities more faithfully than a conventional GCN.
10. Finally, the model’s novel predictions—both drug‑drug and gene‑disease associations—receive higher confidence scores and are corroborated by recent literature, underscoring the practical value of the inferred depth and structure.
💻Code: github.com/kckishan/BBGCN-LP…
📜Paper: arxiv.org/abs/2211.13231
#GraphNeuralNetworks #BiomedicalComputing #DeepLearning #Bioinformatics #MachineLearning #ModelSelection #GraphConvolutionalNetworks #BayesianInference #DrugDiscovery #GeneDiseaseAssociations
3
15
1,387

The Magnificent 7: Mastering key MLops strategies for 2025 @TechNative
#BigData #IoT #AI #TwitterDailyBlog #TechNative #ExecutiveSearch #HybridCloud #ModelSelection
technative.io/the-magnificen…
6
4
160

Model Evidence and Occam Penalty
Marginal likelihood:
P(D | M) = ∫ P(D | θ, M) P(θ | M) dθ
Complex models dilute probability mass across parameter space.
Approximate penalty (Laplace approximation):
log P(D | M) ≈ log P(D | θ̂) − (k/2) log N
k = number of parameters
N = data size
Models with many free parameters can fit data well yet have low evidence.
Good fit ≠ good model.
#ModelSelection #OccamsRazor #Statistics
2
90

Feb 12
@OfficialLoganK, why is it complex now to simply chat on @GoogleAIStudio ?
/Chat > /ModelSelection > Prompt (long process)
Please add a shortcut in the left panel.
1
2
633

Jan 30
Good day for strengthening statistical intuition behind ML models.
#WomenWhoCode #MachineLearning #DataScience #ModelSelection #Python #LearningInPublic
5
89

21 Nov 2025
Training AI models isn’t just about defaults. What really happens during deep learning? How do you pick the right model? When should you tweak hyperparameters? Explore the answers in Week 4 of the Geti™ Series with Guy Tamir: ms.spr.ly/6015tpyOR
#Geti #DeepLearning #ModelSelection #OpenVino
1
2
741

20 Nov 2025
🧠 Want to win Mission Agent Possible at #MSIgnite?
Start with smart model selection!
🔍 Learn, test & choose the right AI model with this hands-on guide: msft.it/6017tOzpD
🎯 Contest info: msft.it/6018tOzpE
#AI #Agents #ModelSelection

1
4
8
738
18 Nov 2025
🚀 2025 is the year of agents!
Join Mission Agent Possible at #MSIgnite: pick your model, build your agent, and solve a product launch crisis.
🏆 Win an XBOX or $100 Microsoft Store credit!
📅 Nov 18–20
🔗 msft.it/6018t3PXo
#AI #Contest #ModelSelection

3
4
533
13 Nov 2025
Building computer vision models isn’t just about defaults. Why does patience matter in training? When should you ignore splits? How do you balance speed, size, and accuracy? Find out in Week 4 of the Geti™ Series from AI with Guy: ms.spr.ly/6013tOpPF
#Geti #ComputerVision #ModelSelection #EdgeAI
1
1
2
512
13 Nov 2025
🧠 Want to win Mission Agent Possible at #MSIgnite?
Start with smart model selection!
🔍 Learn, test & choose the right AI model with this hands-on guide: msft.it/6014tyAy2
🎯 Contest info: msft.it/6015tyAyN
#AI #Agents #ModelSelection

1
1
8
587
11 Nov 2025
🚀 2025 is the year of agents!
Join Mission Agent Possible at #MSIgnite: pick your model, build your agent, and solve a product launch crisis.
🏆 Win an XBOX or $100 Microsoft Store credit!
📅 Nov 18–20
🔗 msft.it/6019tJeKJ
#AI #Contest #ModelSelection

1
2
6
585

6 Nov 2025
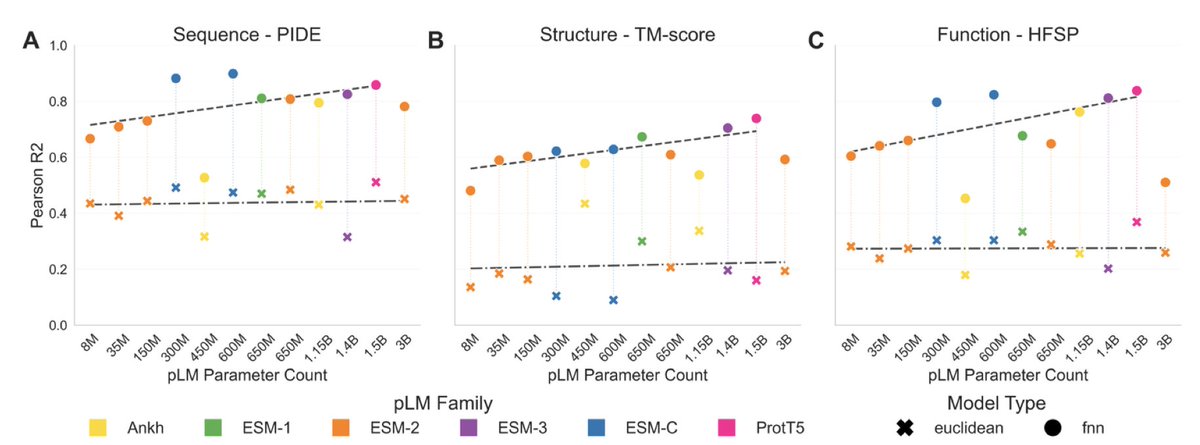
Which pLM to choose? A benchmark study on protein language models reveals optimal model selection strategies for biological analyses.
1. Mid-scale protein language models (pLMs) perform as well as larger models in capturing inherent biological information, challenging the notion that bigger is always better. This size-performance paradox suggests that smaller models can efficiently provide general insights without the computational overhead of larger ones.
2. The study finds that larger pLMs store more extractable biological information, which can be unlocked through supervised learning. This capacity dividend indicates that larger models are advantageous when fine-tuning for specific tasks, but not for out-of-the-box use.
3. Task-specific training reshapes the embedding space of pLMs, optimizing them for targeted applications but reducing their versatility. This highlights the trade-off between specialization and generalizability in protein representation learning.
4. The research underscores the importance of model selection based on specific research needs. Smaller foundation models are recommended for immediate biological insights, while larger models are suitable for fine-tuning to achieve maximal performance.
5. The authors suggest that future progress in protein language modeling should focus on improving data quality and diversity, rather than solely increasing model size. This could lead to more robust and generalizable pLMs.
📜Paper: biorxiv.org/content/10.1101/…
💻Code: github.com/tsenoner/plm_choi…
#ProteinLanguageModels #Bioinformatics #ModelSelection #ComputationalBiology #AIinBiology
9
50
3,792

5 Nov 2025
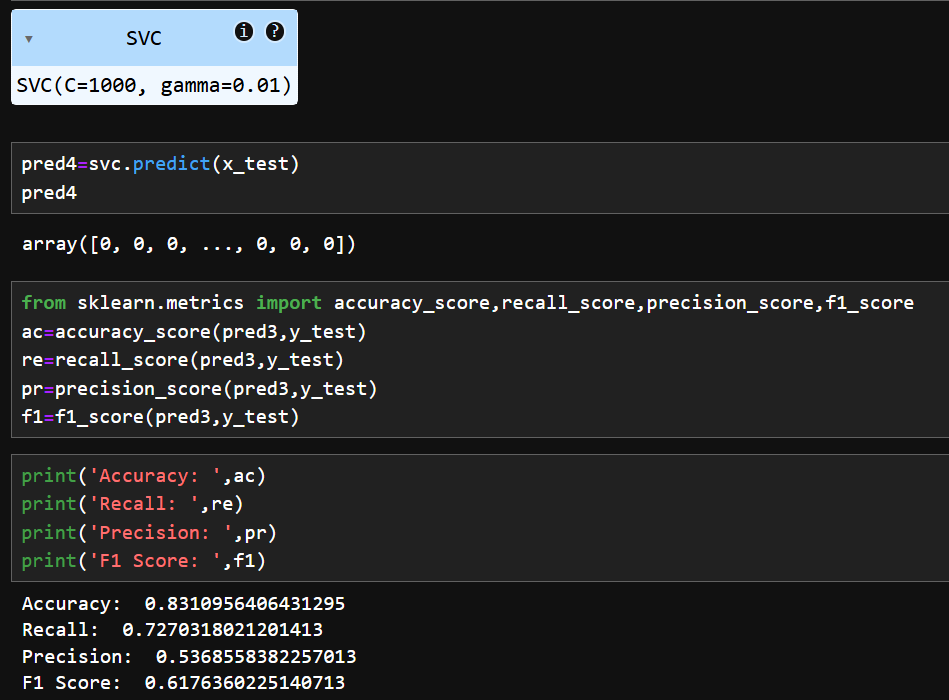
🤖 Compared 4 ML models
🚀Logistic Regression, SVM, KNN, Naive Bayes on the same dataset.
Metrics:🎯Accuracy | 🔍 Precision | 📈 Recall | 🏆 F1-Score
Biggest lesson: There’s no universal best; your data decides the winner!
#MachineLearning #DataScience #Python #AI #ModelSelection



2
65
9 Oct 2025
Uncertainty-Guided Model Selection for Tabular Foundation Models in Biomolecule Efficacy Prediction
1. A new study explores using uncertainty to guide model selection for predicting biomolecule efficacy, showing promising results with the TabPFN model on siRNA knockdown tasks. This approach could enhance drug discovery by improving the accuracy of efficacy predictions without needing ground truth labels.
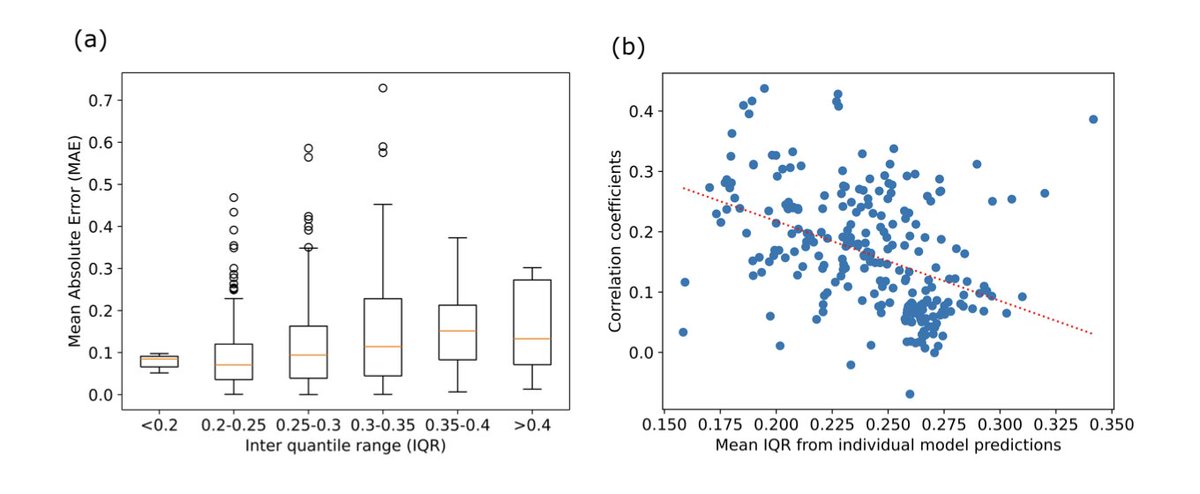
2. The research introduces OligoICP, a method that leverages the inter-quantile range (IQR) of model predictions as a proxy for prediction error. This allows for selecting the best models for ensembling based on their intrinsic uncertainty, leading to superior performance compared to traditional methods.
3. The study demonstrates that a general-purpose model like TabPFN, equipped with simple sequence-based features, can outperform specialized state-of-the-art models like OligoFormer. This highlights the potential of using general models with context learning for specific scientific applications.
4. The experiments show a clear negative correlation between the model’s predicted IQR and its true prediction error. This finding validates the use of IQR as a label-free heuristic for model selection, providing a practical strategy for optimizing biomolecule efficacy prediction in real-world scenarios.
5. The OligoICP framework was tested on multiple datasets, including out-of-distribution targets, and consistently showed improved correlation coefficients compared to single models or naive ensembles. This underscores the robustness of the uncertainty-guided approach.
6. The study builds on previous work in tabular in-context learning and post-hoc ensembling, offering a novel application of model uncertainty for model selection. It also highlights the need for further research to close the gap to the optimal ensemble performance.
📜Paper: arxiv.org/abs/2510.02476v2
#BiomoleculeEfficacy #ModelSelection #UncertaintyQuantification #DrugDiscovery #MachineLearning #TabPFN #OligoICP
1
9
1,144

8 Oct 2025
Chainforge Philosophy #1: The silver bullet "All-in-one” Model is a myth. 🦄 Every LLM has inevitable strengths & weaknesses based on its architecture & data. 🧭 #NoFreeLunch #ModelSelection #AIPhilosophy
1
2
43

7 Sep 2025
Unlock your AI's full potential! Choosing the right LLM for each task is key. Stop guessing, start optimizing. Switchpoint AI helps you find the perfect match every time. #LLM #AI #ArtificialIntelligence #ModelSelection #AIoptimization
1
6