

May 20
Lakehouse時代は、“フォーマット選定” より “カタログ戦略” が重要。
データ基盤の未来は「オープン性 相互運用性 ガバナンス」の設計勝負になってきたと感じる。
非常に共感。
#ApacheIceberg #Databricks #DataLakehouse #DataEngineering #OpenTableFormat #DataPlatform #Snowflake #StarRocks

2
6
285

26 Nov 2025
オープンデータフォーマットの適材適所
Apache Iceberg vs Delta Lake
note.com/engorgio/n/n2913d74…
#データレイクハイス #apacheiceberg #deltalake #opentableformat
1
8
59
29,284

Writing #ApacheIceberg in Azure is not particularly hard, but you do need a catalog (essentially a database). For simple tests, you can use an in-memory DB
#ADLS #opentableformat #PyIceberg.

11
1,243

25 Jun 2025
I’m working on a new blog post on how #OpenTableFormat with #ApacheIceberg & #DeltaLake, plus #ShiftLeft architecture, accelerates the move from #Lambda to unified #Kappa.
One #RealTime pipeline. Simpler, scalable, powering analytics transactions.
🔗 kai-waehner.de/blog/2021/09/…

4
228


In this #AWSPiDay exclusive, join @theCUBEresearch’s @RealStrech with @andywarfield to explore the evolution of #Iceberg table format and its impact on @AWScloud’s S3.
💡 Learn more at #theCUBE!
thecube.net/events/aws/diggi…
#OpenTableFormat
7
1,830

16 Mar 2025
OpenTableFormatをDuckDBから使ってみた。データを任意のオブジェクトストレージやらファイルシステムにテーブルとして設置できる。MoRとかちゃんと追従できるか確かめていきたい。メモリ効率はDuckDBの方が良い?(スピードは遅い)
syakesaba.com/tech/iceberg-d…
#ApacheIceberg #DuckDB #ApacheSpark
2
87
Airing NOW! 🚨 Tune into #AWSPiDay, where @theCUBEresearch’s @RealStrech is speaking with @andywarfield about the transformation of #Iceberg table format and its benefits for @awscloud’s S3.
📺 Tune in NOW!
thecube.net/events/aws/diggi…
#OpenTableFormat
1
14
8,974

6 Mar 2025
Recently, on a podcast, I was asked, “Why Hudi?”. Not a history lesson, but “Why Hudi today?”
Most of what I do is telling companies to collect, store, and process more data and make everything better. So, it's only fair that I write down 21 reasons, not just one.
🔗 Read the full blog post here: hudi.apache.org/blog/2025/03…
Here’s the rundown. Here’s why Hudi should be at the core of your data platform
1️⃣ Well-Balanced Storage Format
2️⃣ Database-like Secondary Indexes
3️⃣ Efficient Merge-on-Read (MoR) Design
4️⃣ Scalable Metadata for Large-Scale Datasets
5️⃣ Built-In Table Services
6️⃣ Data Management Smarts
7️⃣ Concurrency Control Purpose-built For the Lake
8️⃣ Performance at Scale
9️⃣ Out-of-box CDC/Streaming Ingestion
🔟 First-Class Support for Keys
1️⃣1️⃣ Streaming-First Design
1️⃣2️⃣ Efficient Incremental Processing
1️⃣3️⃣ Powerful Apache Spark Implementation
1️⃣4️⃣ Next-Gen Flink Writer for Streaming Pipelines
1️⃣5️⃣ Avoid Compute Lockins
1️⃣6️⃣ Seamless Interop Iceberg/Delta Lake and Catalog Syncs
1️⃣7️⃣ Truly Open and Community-Driven
1️⃣8️⃣ Massive Adoption Across Industries
1️⃣9️⃣ Proven Reliability in High-Pressure Workloads
2️⃣0️⃣ Cloud-Native Lakehouse-Ready
2️⃣1️⃣ Future-Proof and Actively Evolving
Come join our community as we work towards adding 21 more this year.
#ApacheHudi #DataLakehouse #BigData #DataEngineering #StreamingData #CDC #ApacheFlink #ApacheSpark #OpenTableFormat #DataLakes #DataManagement #OpenSource #ApacheXTable #DataInfrastructure #CloudData #RealTimeAnalytics #MachineLearning #DataPlatform 🚀

6
13
1,863
9 Jan 2025
ICYMI, it was a blast answering all of @ananthdurai 's direct questions yesterday about #apachehudi, the data lakehouse/open table format ecosystem, and the surrounding drama.
Catch the recording: linkedin.com/events/bridging…
Key discussion points:
🏎 Performance is often one of many considerations. We discussed how, high performance is a necessity on data lakehouse since all we spend money on outside query engines is to run jobs that either ETL/Ingest/Optimize data. Hudi makes them all incremental and efficient while supporting standard batch workloads.
❤️ I brought receipts to showcase how the community thrives as a mainstream OSS project across the industry. We talked about how important and challenging it is to preserve this vibrant community.
🎇 We summarized the Hudi 1.0 features, which push the data lakehouse closer to database functionality across storage format, concurrency control, streaming data support and indexing. These changes bring several “never before” capabilities around the key cornerstone lakehouse feature set. We remain focused on solving complex computer science problems using open-source software.
🤼 I was thrilled to be asked tough questions on table format wars winners/losers. It gave me a rare opportunity to put events in perspective and explain the vendor chess moves that are unrelated to Hudi, its community or even Onehouse. My favorite part was encouraging Delta Lake users to carefully consider what they lose/gain from “standardization” before wasting time on a migration project as a third party (I guess many wouldn’t have hoped to see this day)
❓I also raised some questions. Why does every data warehouse default to a closed table format as the default? Are users going to stop using them now? Why the obsession with converging the three OSS data lakehouse projects alone? Overall, it's up to the market/users to decide slow standardization vs fast innovation. My view: it's healthy to have both and multiple choices in any ecosystem.
📈 Loved the discussion on the pains around easily be up & running with Data Lakehouse. Some low-hanging fruits around software packaging could help in the near term. We discussed the hierarchy of needs here: table format -> data lakehouse frameworks -> DBMS server/cluster software, which is all closed software ATM. There is a missing open-source software stack, and we are slowly crawling toward a database specialized in data lakehouse architecture/workloads.
#apachehudi #data #database #datalakehouse #datawarehouse #opentableformat #dataengineering #apacheiceberg #deltalake
1
3
10
799
17 Dec 2024
🎉 We’re proud to announce the @apachehudi 1.0 release! This release has been the result of a massive community effort, with tons of new code (re)written. I want to thank all 60 contributors who worked on ~180K lines of change.
🗒️ Release blog: hudi.apache.org/blog/2024/12…
Hudi is still the OG of the data lakehouse when it comes to real technical innovation, as will become apparent below. 👇
🔥 Secondary Indexing - yes! you read it right. You can speed up queries using indexes, just like a #database. 95% decreased latency on 10TB tpc-ds for low-moderate selectivity queries. You can create/drop indexes asynchronously.
✨ Logical partitioning via Expression Indexes - #postgres style expression indexes to treat partitions like the coarse-grained indexes they are. It avoids the most common pitfall with users creating tons of small partitions.
🤯 Partial Updates - 2.6x performance and 85% reduction in byte written dropping write/query costs on update-heavy workloads. Lays the foundation for multimodal and unstructured data
⚡ Non-blocking Concurrency Control (NBCC) enables simultaneous writing from multiple writers and compaction of the same record without blocking any involved processes. This is an industry first!
🎉 Merge Modes - First-class support for both styles of stream data processing: commit_time_ordering, event_time_ordering, and custom record merger APIs.
🦾 LSM timeline—Hudi has a revamped timeline that stores all action history on a table as a scalable LSM tree, allowing users to retain a large amount of table history.
⌛ TrueTime - Hudi strengthens TrueTime semantics. The default implementation assures forward-moving clocks even with distributed processes, assuming a maximum tolerable clock skew similar to OLTP/NoSQL stores
So, if you love open-source innovation as much as we do, check out the release and join our ~12000 strong community across Slack & GitHub. We're a grassroots OSS community that has sustained innovation in a fiercely competitive commercial data ecosystem.
#apachehudi #datalakehouse #opentableformat #dataengineering #apachespark #apacheflink #trinodb #awss3 #distributedsystems #analytics #bigdata #datalake

4
40
2,064

17 Dec 2024
Hudi 1.0 is the most powerful release to date for data lakehouses. Read the blog for details:
Secondary Indexing, Expression Indexes, Partial Updates, Non-blocking Concurrency Control, New LSM timeline, more: hudi.apache.org/blog/2024/12…
#datalakehouse #opentableformat
10
34
2,711
12 Jul 2024
#OpenTableFormat is at peak of inflated expectations, while #datalakehouse is at trough of disillusionment?
And here, we thought former enabled the latter. I can imagine anyone working hands-on with these has their heads 🤯 right now.
There is some truth here:
⛰️Just an open table format buys you NOTHING. If we think so, then the picture is accurate. We’re kidding ourselves in a peak of inflated expectations
😩 If market noise around table format is plunging you into a trough - @apachehudi, @apachextable - here to help by focussing on productive things to help build your lakehouse.
#Gartner #Datamanagement #data #bigdata
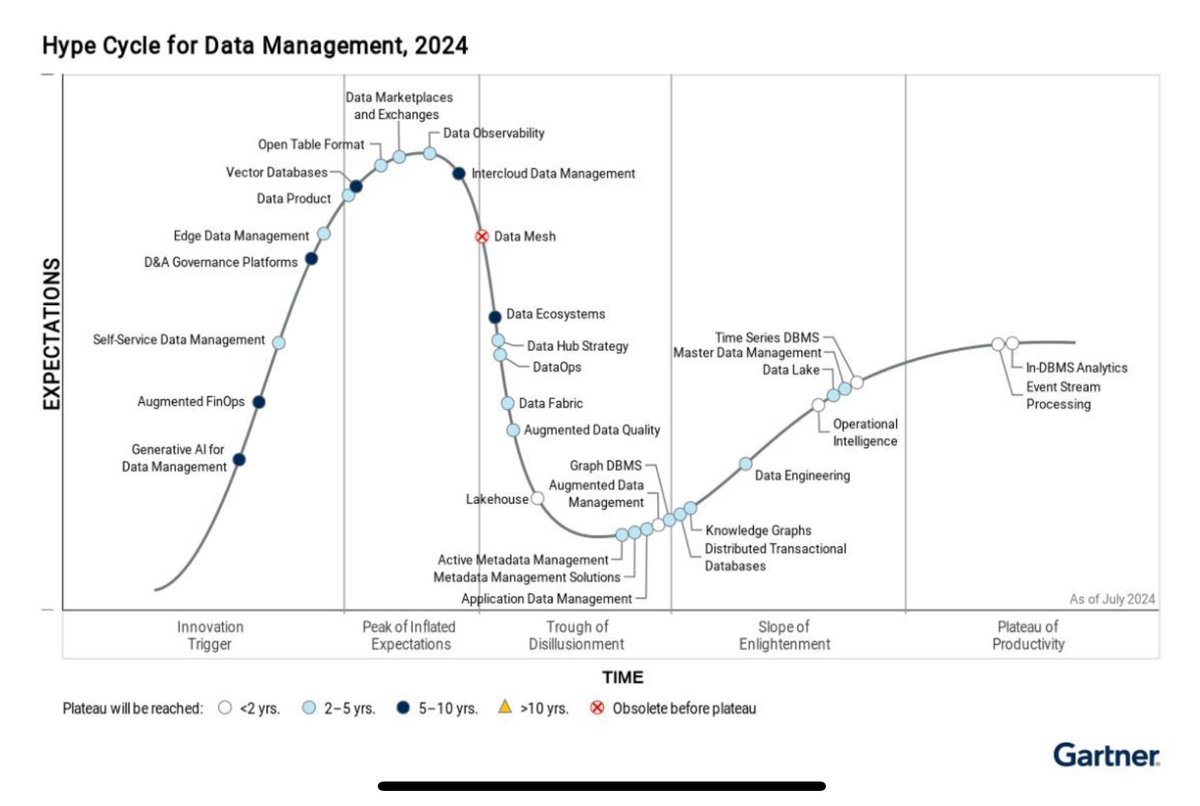
2
5
941

27 Jun 2024
#Teradata の最新情報を配信していますので、ご視聴ください。
今月は、#機械学習 での #ハイパーパラメータチューニング の自動化機能や、#TeradataAIUnlimited の利用方法や、#OTF #OpenTableFormat の具体的な利用方法をデモを交えてご説明しています。
youtu.be/WSzVDHVdpGE?si=w5ps… via @YouTube
2
107

12 Oct 2023
I started exploring OpenTable Formats. Can they be used with Elixirlang or Erlang? How do we build a lake and how to make meaningful data decisions . Please suggest blogs
#myelixirstatus #datalake #opentableformat
2
6
780