
Jun 13
🛡️ RLHF, DPO & Modern Preference Optimization — the crucial final layer that turns capable LLMs into safe, trustworthy, and enterprise-aligned systems.
Just read this excellent technical white paper from @aasaitech on alignment techniques that go beyond pre-training, SFT, CoT, and RAG.
Key highlights: • RLHF (classic PPO-based) vs modern direct methods: DPO, KTO, ORPO, SimPO • 6-step preference optimization pipeline: Generate candidates → Human/domain-expert ranking → Preference dataset → Optimization → Aligned model • Preference dimensions: Helpfulness, Safety, Truthfulness, Compliance, Style, Decision Quality • Industrial gold: Manufacturing copilots, maintenance agents, safety-compliant systems, company-specific decision frameworks
In high-stakes industrial & edge environments, alignment is non-negotiable. Combine with strong RAG structured reasoning for production-grade agentic AI.
Full white paper infographic: x.com/aasaitech/status/20653…
How are you handling model alignment in your workflows — full RLHF, DPO-style direct optimization, or constitutional approaches?
#RLHF #DPO #PreferenceOptimization #LLMAlignment #IndustrialAI #AgenticAI #SafeAI

1
11
Symmetric Self-play Online Preference Optimization for Protein Inverse Folding
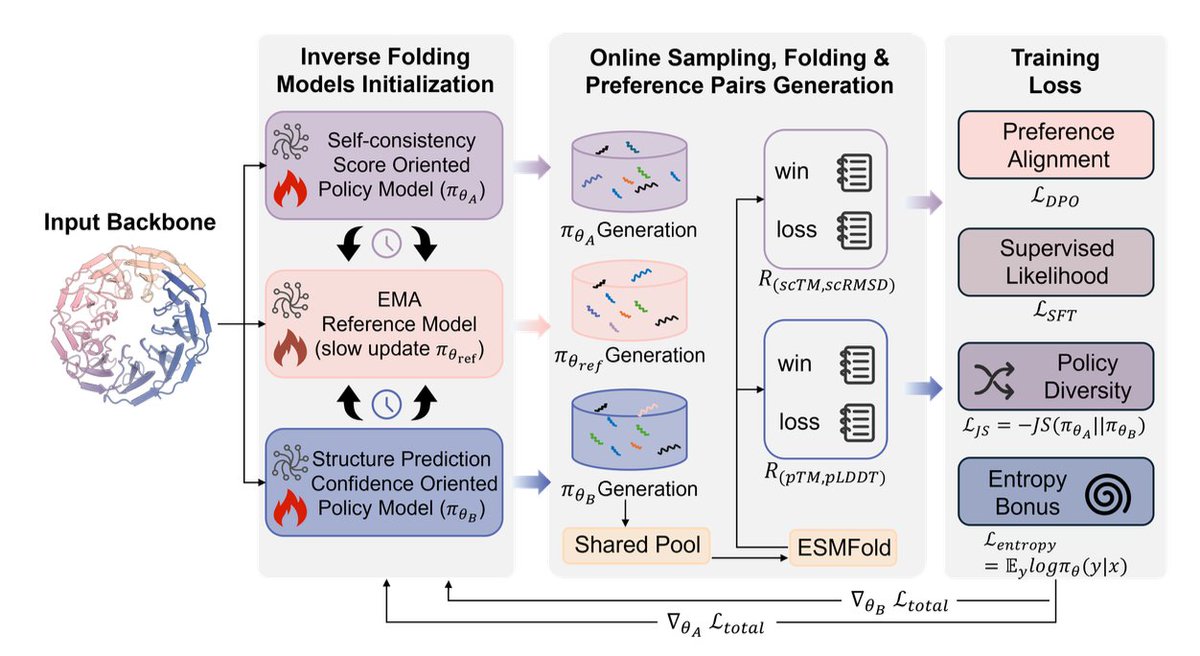
1. The paper argues that multi-objective inverse folding shouldn’t be forced into a single scalar reward: structural objectives (e.g., self-consistency vs prediction confidence) are only partially aligned, so a single-policy optimizer tends to follow a dominant direction and miss alternative high-quality designs.
2. It introduces SSP (Symmetric Self-play Preference Optimization), an online preference-optimization framework that keeps two separate policies: one optimized for structural self-consistency (Rsc) and the other for predicted confidence (Rpred), plus an EMA-updated reference model for stabilization.
3. Key mechanism: both policies (and the reference) sample sequences for the same backbone, merge them into a shared candidate pool, refold with ESMFold, filter low-confidence samples, then build preference pairs for each objective from the same pool—creating implicit cross-policy competition and comparison without collapsing objectives.
4. Rewards are explicitly decoupled: Rsc combines scTM and RMSD-based terms after aligning predicted structures to the target backbone; Rpred averages pLDDT and pTM from structure prediction. Training uses DPO-style preference loss plus an SFT term on preferred samples.
5. To prevent policy collapse and encourage complementary exploration, SSP adds (i) a Jensen–Shannon divergence regularizer between the two policies and (ii) an entropy bonus, aiming to cover different regions of the Pareto frontier rather than converging to the same solution.
6. SSP is shown to be architecture-agnostic: implemented on ProteinMPNN (full fine-tuning), ESM-IF1 and ESM3 (LoRA fine-tuning). After training, it produces a single deployable model via merging: task-vector merging for full-parameter models, and weighted LoRA adapter merging for parameter-efficient setups.
7. On native-backbone benchmarks (CATH4.2/4.3), SSP variants consistently improve structure prediction confidence (pTM/pLDDT), self-consistency (scTM, RMSDs), and related metrics over base models and several RL/DPO baselines, indicating that the dual-policy setup improves design self-consistency beyond standard single-policy preference optimization.
8. Generalization is tested on CAMEO43 (targets with max TM-score < 0.5 vs training set). SSP improves pTM/pLDDT and self-consistency vs baselines, supporting the claim that decoupled objectives help in harder, lower-similarity regimes rather than only on in-distribution backbones.
9. Transfer to de novo binder backbones is emphasized as a “real-world” proxy: on BoltzGen-419 (DNA/RNA/peptide binders) and PXDesign-PPI226 (protein binders with specified hotspots), the merged SSP-ESM3 model leads across pTM/scTM and interface confidence (ipTM), and achieves strong design success rates—suggesting robustness across binder types and backbone generators.
10. The paper provides interpretability evidence that the two objectives truly induce different optimization directions: white-box analysis of ESM3 LoRA updates shows low subspace overlap (SVD-based) and near-orthogonal update directions (cosine similarity near 0) across many layers, with only mild alignment in deeper layers—supporting the “partially aligned objectives” hypothesis.
💻Code: github.com/wwzll123/SSP
📜Paper: biorxiv.org/content/10.64898…
#ProteinDesign #InverseFolding #ReinforcementLearning #PreferenceOptimization #MultiObjectiveOptimization #ComputationalBiology #ESM3 #ProteinMPNN #LoRA #SelfPlay
1
20
1,522

6 Oct 2025
Molecular Foundation Models: A Simple Remedy for OOD Detection
1. A new study explores a critical issue in molecular AI: the unreliability of foundation models on out-of-distribution (OOD) samples, which is a significant barrier in high-stakes domains like drug discovery.
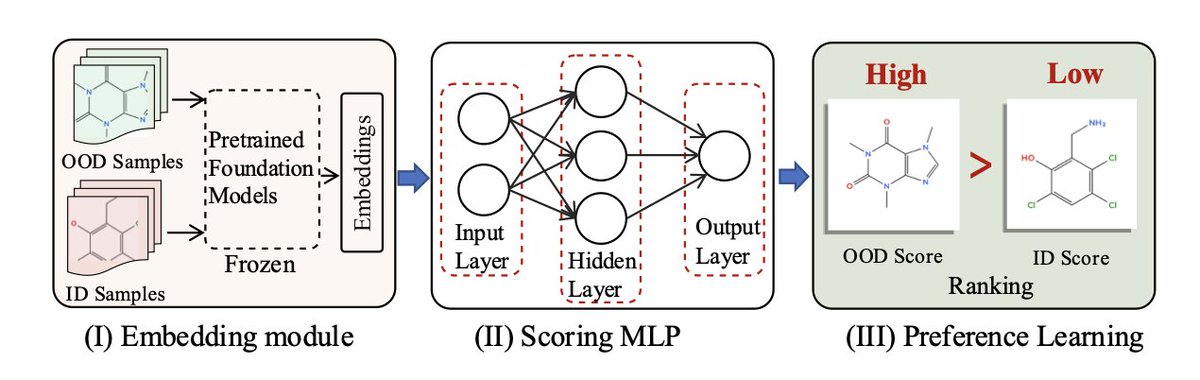
2. The authors introduce Mole-PAIR, a novel, plug-and-play module that enhances the OOD detection capabilities of existing molecular foundation models through a cost-effective post-training approach. This method formulates OOD detection as a preference optimization problem, optimizing the ranking between in-distribution (ID) and OOD samples.
3. Mole-PAIR achieves this by using a pairwise learning objective that directly optimizes the estimated OOD affinity, without requiring class logits or property labels. This approach is model-agnostic and can be seamlessly integrated with various off-the-shelf molecular foundation models.
4. Theoretical analysis shows that this pairwise learning objective inherently optimizes the AUROC, a key metric for evaluating the consistency of OOD detection. This alignment ensures that the model focuses on correctly ranking ID and OOD samples.
5. Extensive experiments across five real-world molecular datasets demonstrate significant improvements in OOD detection capabilities, with average gains of 28.3% on AUROC, 28.5% on AUPR, and 25.3% on FPR95 across all distribution shifts.
6. The study highlights the effectiveness of Mole-PAIR in addressing chemical hallucination, a common failure mode where models make high-confidence yet incorrect predictions for unknown molecules. By optimizing relative ranking, Mole-PAIR reduces false positives and enhances model reliability.
7. The authors also conduct ablation studies to analyze the effects of hyperparameters such as the temperature parameter β and the regularization parameter λ, providing insights into the optimal settings for different distribution shifts.
📜Paper: arxiv.org/abs/2509.25509v1
#MolecularAI #OODDetection #PreferenceOptimization #DrugDiscovery #MachineLearning
4
11
1,153

2 Sep 2025
@emnlpmeeting / #EMNLP2025 Accepted Paper: Direct Judgement Preference Optimization
📝 Paper: arxiv.org/abs/2409.14664
This work introduces SFR-Judges, a family of generative judge models trained with Direct Preference Optimization (DPO) to enhance LLM evaluation capabilities across diverse tasks. The approach moves beyond traditional supervised fine-tuning by learning from both positive and negative evaluation examples, addressing the limitation that SFT only learns from correct judgements without avoiding incorrect ones.
Key contributions:
➡️ Novel DPO training approach with three preference data types: Chain-of-Thought critique, standard judgement, and response deduction
➡️ Response deduction auxiliary task that teaches judges to understand what good/bad responses contain by deducing original responses from evaluations
➡️ Comprehensive evaluation across 13 benchmarks covering single rating, pairwise comparison, and classification tasks
➡️ State-of-the-art performance with SFR-LLaMA-3.1-70B-Judge achieving best results on 10/13 benchmarks, outperforming GPT-4o
Results demonstrate the largest model (70B) achieves 92.7% on RewardBench, marking the first generative judge to exceed 90% accuracy. The approach effectively counters evaluation biases like position and length bias while providing flexible adaptation to different evaluation protocols. Additional analysis shows the models can serve as effective reward models for downstream development, improving AlpacaEval win rates from 39.25% to 44.29% through AI feedback refinement.
👥 Authors: Peifeng Wang @PeifengWang3, Austin Xu @austinsxu, Yilun Zhou @YilunZhou, Caiming Xiong @CaimingXiong, Shafiq Joty @JotyShafiq
#FutureOfAI #EnterpriseAI #LLMEvaluation #PreferenceOptimization #RewardModeling #AIFeedback #MachineLearning #AutoEvaluation

4
12
1,044