
2 Sep 2025
@emnlpmeeting / #EMNLP2025 Accepted Paper: Direct Judgement Preference Optimization
📝 Paper: arxiv.org/abs/2409.14664
This work introduces SFR-Judges, a family of generative judge models trained with Direct Preference Optimization (DPO) to enhance LLM evaluation capabilities across diverse tasks. The approach moves beyond traditional supervised fine-tuning by learning from both positive and negative evaluation examples, addressing the limitation that SFT only learns from correct judgements without avoiding incorrect ones.
Key contributions:
➡️ Novel DPO training approach with three preference data types: Chain-of-Thought critique, standard judgement, and response deduction
➡️ Response deduction auxiliary task that teaches judges to understand what good/bad responses contain by deducing original responses from evaluations
➡️ Comprehensive evaluation across 13 benchmarks covering single rating, pairwise comparison, and classification tasks
➡️ State-of-the-art performance with SFR-LLaMA-3.1-70B-Judge achieving best results on 10/13 benchmarks, outperforming GPT-4o
Results demonstrate the largest model (70B) achieves 92.7% on RewardBench, marking the first generative judge to exceed 90% accuracy. The approach effectively counters evaluation biases like position and length bias while providing flexible adaptation to different evaluation protocols. Additional analysis shows the models can serve as effective reward models for downstream development, improving AlpacaEval win rates from 39.25% to 44.29% through AI feedback refinement.
👥 Authors: Peifeng Wang @PeifengWang3, Austin Xu @austinsxu, Yilun Zhou @YilunZhou, Caiming Xiong @CaimingXiong, Shafiq Joty @JotyShafiq
#FutureOfAI #EnterpriseAI #LLMEvaluation #PreferenceOptimization #RewardModeling #AIFeedback #MachineLearning #AutoEvaluation

4
12
1,044

21 Mar 2025
🚀 I'm excited to unveil my brand-new @github repository—your one-stop shop for the latest Agentic AI research.
📂 This repository serves as a comprehensive research and innovation hub, curating cutting-edge research papers and developments across these research fields:
🩺 #Healthcare
🧠 #Reasoning
👁️ #Vision
💻 #Code
🎮 #Gaming
📦 #SupplyChain
🤖 #FoundationModels
📐 #Design
🧪 #Testing
🔌 #IoT
🤖 #Robotics
🏆 #RewardModeling
📊 #Visualization
⚙️ #Framework
📋 #Planning
🎯 #Recommendation
🔄 #ReinforcementLearning
🔧 #Hardware #Design
⚡ #Automation
🔬 #Research
🔄 #Multimodal
🔒 #Security
🌆 #SmartCities
🚦 #Transportation
⛓️ #Blockchain
📡 #Networking
🤖 #PromptEngineering
⚖️ #Ethics and #Safety
📝 Each section provides direct links to my @LinkedIn posts, offering insights into the latest advancements and researches in Agentic AI applications.
🔗 Dive into the repository here:
lnkd.in/dxbWyDyW
⭐️ If you find this repository helpful, please consider giving it a star!
#did_you_know_that #for_ai_researchers #for_ai_scientists #favikon #cloud #agenticai #agentic #ai #aiagent #research #researchpaper #linkedin #github #repository #knowledge #for_ai_architects

1
1
62

6 Feb 2025
5️⃣ Final thoughts?
Reward modeling isn’t perfect, and no method completely eliminates reward hacking.
But with a structured inductive bias, trajectory-consistent learning, and lower complexity, GenARM makes a strong case for more reliable token-level alignment.
Let’s discuss! 👇
Do you think reward hacking can ever be fully solved? 🤔
#AI #LLMs #ICLR2025 #RewardModeling #TestTimeAlignment
1
2
719

17 Jan 2025
We (@chaoqi_w @yibophd @ZRChen_AISafety) have been eager to share our latest work on battling reward hacking since last November, but had to wait for the legal team's approval. Finally, we're excited to release: Causal Reward Modeling (CRM)!
CRM tackles spurious correlations and mitigates reward hacking in RLHF by integrating causal inference and enforcing counterfactual invariance. It addresses biases like length, concept, sycophancy, and discrimination, enabling more trustworthy and fair alignment of LLMs with human preferences.
Check it out here: arxiv.org/pdf/2501.09620
#AI #LLM #RLHF #MachineLearning #AIAlignment #CausalInference #ReinforcementLearning #ResponsibleAI #EthicalAI #RewardModeling #BiasMitigation #Fairness #TrustworthyAI #SpuriousCorrelations
2 Dec 2024

🦃 At the end of Thanksgiving holidays, I finally finished the piece on reward hacking. Not an easy one to write, phew.
Reward hacking occurs when an RL agent exploits flaws in the reward function or env to maximize rewards without learning the intended behavior. This is imo a major blockers for real-world deployment of more autonomous use cases of AI models.
Also would like to call out more research on mitigation strategies for reward hacking, especially in the context of LLMs and RLHF.
👉lilianweng.github.io/posts/2…
2
3
15
2,968

'When is Off-Policy Evaluation (Reward Modeling) Useful in Contextual Bandits? A Data-Centric Perspective'
by Hao Sun, Alex James Chan, Nabeel Seedat, Alihan Hüyük, Mihaela van der Schaar
Action Editor: Omar Rivasplata
data.mlr.press/assets/pdf/v0…
#DataCentricAI #OffPolicyEvaluation #ContextualBandits #RewardModeling
1
4
1,445

16 Sep 2024
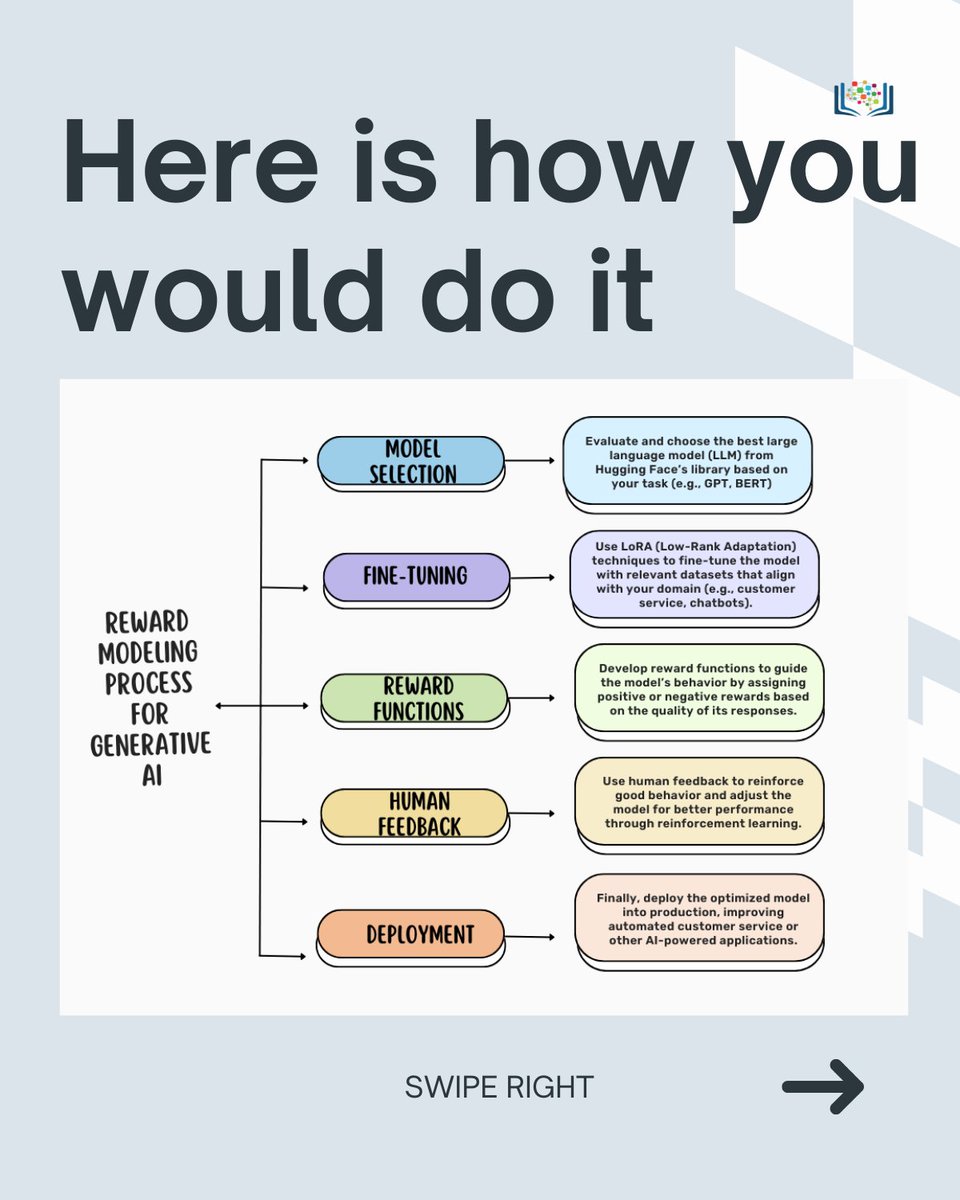
🚀 Want to level up your AI skills? In just 2 hours, learn to train LLMs for Reward Modeling and fine-tune models with LoRA.
Perfect for anyone looking to optimize AI for complex tasks. Join now!
shorturl.at/UIVbb
#AI #MachineLearning #LLM #RewardModeling


1
4
226

Ever wonder what’s driving the success of generative AI models like GPT-3.5? Our latest blog post explains reward modeling in under 2 minutes. Don’t miss it! resources.innodata.com/rewar… #AI #RewardModeling #ReinforcementLearning #GenAI
1
1
298