
23 May 2025
Prot2Chat: Protein LLM with Early-Fusion of Text, Sequence and Structure
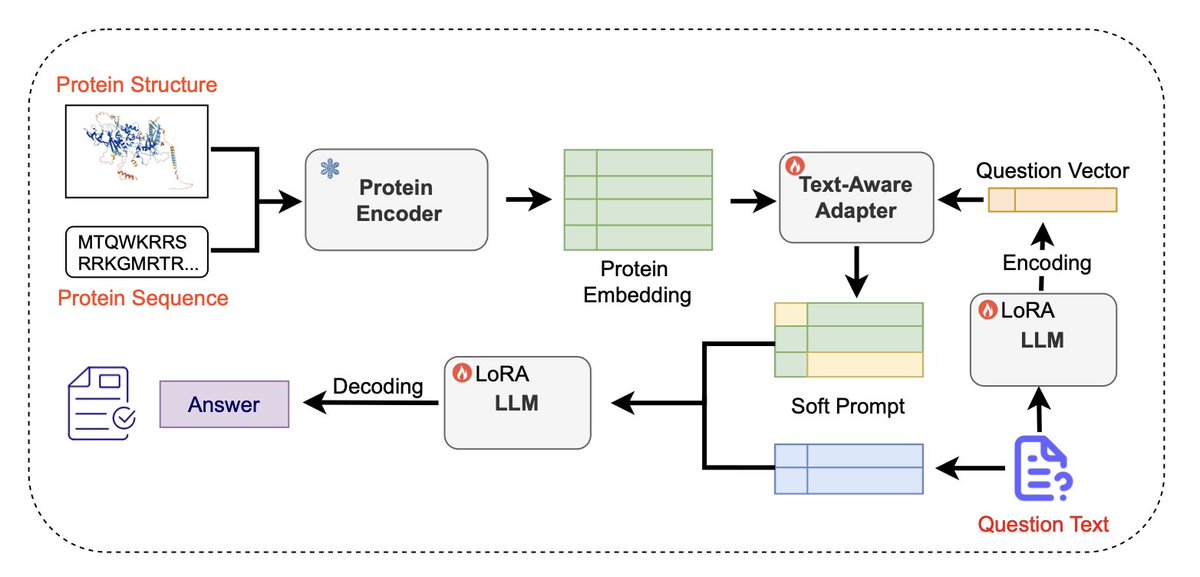
1.Prot2Chat is a novel protein question-answering (Q&A) framework that performs early fusion of protein sequence, structure, and natural language text, enabling large language models to generate accurate and context-aware answers about protein functions.
2.The model modifies ProteinMPNN to produce a fused representation of protein sequence and structure, then compresses this information into a set of “soft prompts” using a text-aware adapter guided by the question input—allowing seamless integration with LLMs.
3.Unlike prior protein LLMs that rely on late fusion or modular encoders, Prot2Chat aligns protein information and text early in the encoding process. This results in significantly better alignment between input protein context and the generated response.
4.On the Mol-Instructions benchmark, Prot2Chat outperforms all baselines—including Evola-10B and BioMedGPT—by wide margins, achieving 35.85 BLEU-2 and 50.51 ROUGE-L, which are 3–5× better than state-of-the-art models.
5.Even with just 109M trainable parameters (vs. 3B in BiomedGPT), Prot2Chat achieves higher expert evaluation rankings and stronger generalization, as validated on UniProtQA through both fine-tuning and zero-shot experiments.
6.Ablation studies confirm the importance of each component: removing early-fused text, protein sequence, or LLM fine-tuning significantly degrades performance. Early fusion is especially critical for aligning protein representations with textual queries.
7.The protein-text adapter uses multi-head cross-attention to align question-guided text with compressed protein embeddings, effectively acting as a semantic bridge between the biochemical world and natural language.
8.Prot2Chat enables residue-level reasoning and function annotation by LLMs, demonstrating superior performance in case studies involving functional inference from sequences and structures—critical for protein annotation and variant interpretation.
9.Compared to models like Evola and ProtChatGPT, Prot2Chat is more computationally efficient and provides higher-quality answers without relying on external knowledge bases or retrieval-augmented generation.
10.This work establishes a lightweight yet powerful protein-language model that unifies multimodal biological representations, advancing the utility of LLMs in biological discovery and protein function exploration.
💻Code: github.com/wangzc1233/Prot2C… 📜Paper: arxiv.org/abs/2502.06846
#ProteinLLM #Prot2Chat #MultimodalFusion #ProteinFunction #ComputationalBiology #StructuralBioinformatics #ProteinMPNN #LLM #BioNLP #AI4Science
4
15
1,026
23 May 2025
Prot2Chat: Protein LLM with Early-Fusion of Text, Sequence and Structure
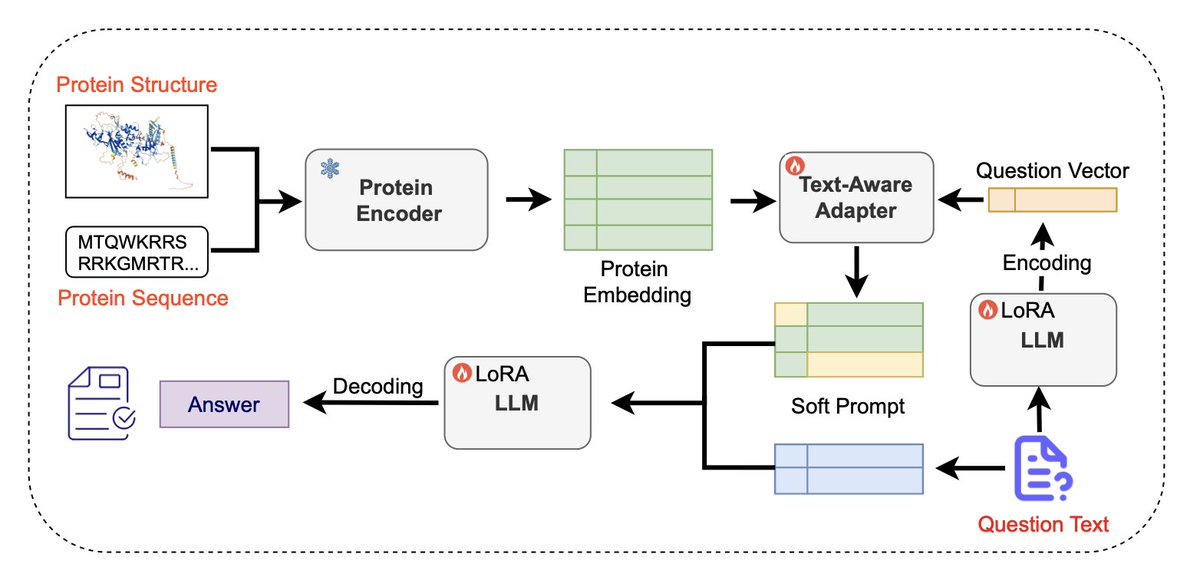
1.Prot2Chat is a novel protein question-answering (Q&A) framework that performs early fusion of protein sequence, structure, and natural language text, enabling large language models to generate accurate and context-aware answers about protein functions.
2.The model modifies ProteinMPNN to produce a fused representation of protein sequence and structure, then compresses this information into a set of “soft prompts” using a text-aware adapter guided by the question input—allowing seamless integration with LLMs.
3.Unlike prior protein LLMs that rely on late fusion or modular encoders, Prot2Chat aligns protein information and text early in the encoding process. This results in significantly better alignment between input protein context and the generated response.
4.On the Mol-Instructions benchmark, Prot2Chat outperforms all baselines—including Evola-10B and BioMedGPT—by wide margins, achieving 35.85 BLEU-2 and 50.51 ROUGE-L, which are 3–5× better than state-of-the-art models.
5.Even with just 109M trainable parameters (vs. 3B in BiomedGPT), Prot2Chat achieves higher expert evaluation rankings and stronger generalization, as validated on UniProtQA through both fine-tuning and zero-shot experiments.
6.Ablation studies confirm the importance of each component: removing early-fused text, protein sequence, or LLM fine-tuning significantly degrades performance. Early fusion is especially critical for aligning protein representations with textual queries.
7.The protein-text adapter uses multi-head cross-attention to align question-guided text with compressed protein embeddings, effectively acting as a semantic bridge between the biochemical world and natural language.
8.Prot2Chat enables residue-level reasoning and function annotation by LLMs, demonstrating superior performance in case studies involving functional inference from sequences and structures—critical for protein annotation and variant interpretation.
9.Compared to models like Evola and ProtChatGPT, Prot2Chat is more computationally efficient and provides higher-quality answers without relying on external knowledge bases or retrieval-augmented generation.
10.This work establishes a lightweight yet powerful protein-language model that unifies multimodal biological representations, advancing the utility of LLMs in biological discovery and protein function exploration.
💻Code: github.com/wangzc1233/Prot2C…
📜Paper: arxiv.org/abs/2502.06846
#ProteinLLM #Prot2Chat #MultimodalFusion #ProteinFunction #ComputationalBiology #StructuralBioinformatics #ProteinMPNN #LLM #BioNLP #AI4Science
9
762
15 Feb 2025
Prot2Chat: Protein LLM with Early Fusion of Sequence and Structure
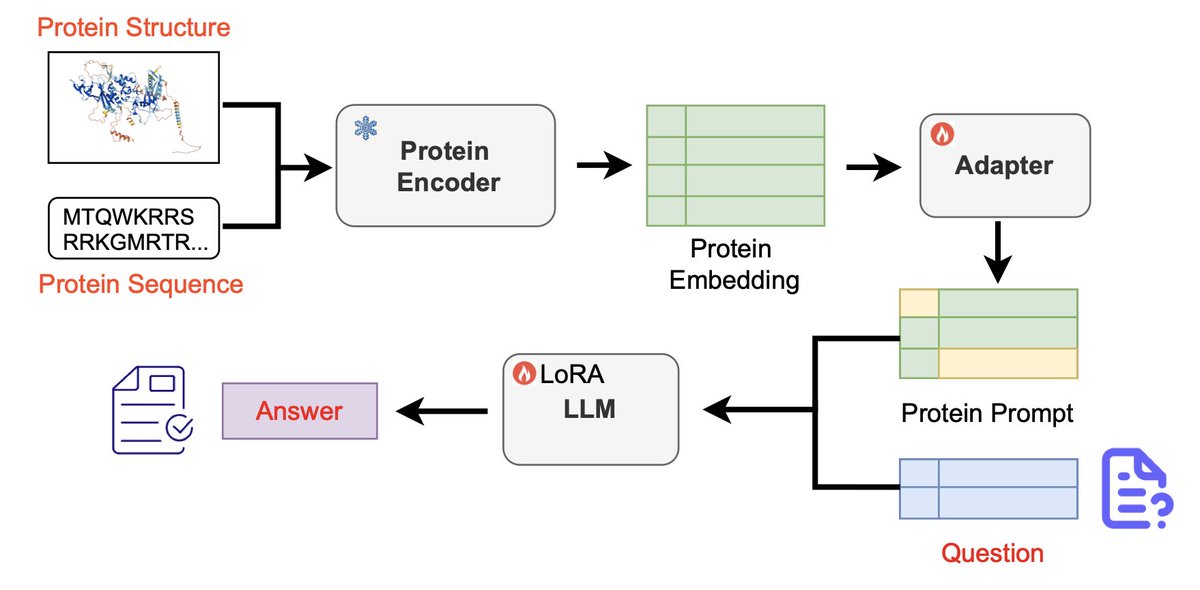
1/ Prot2Chat introduces an innovative protein question-answering (Q&A) system that integrates both protein sequence and structural data into a unified framework, enabling large language models (LLMs) to generate precise and contextually relevant responses.
2/ The model employs a modified ProteinMPNN encoder to fuse protein sequence and structural information early in the process. This early fusion improves model efficiency and enhances its ability to handle complex protein-related queries, far surpassing models that treat sequence and structure separately.
3/ Prot2Chat utilizes a protein-text adapter with cross-attention mechanisms, aligning protein embeddings with natural language. This alignment enables the model to effectively interpret and respond to questions about protein structure, function, and interactions in a more intuitive way.
4/ By using LoRA for fine-tuning the LLaMA3 decoder, Prot2Chat reduces computational cost while maintaining strong performance, making it a more efficient alternative to other large-scale protein language models.
5/ The model excels in zero-shot predictions and outperforms existing baselines, including models trained solely on sequence data. Prot2Chat's ability to integrate structure and sequence provides more accurate and biologically relevant answers.
6/ Prot2Chat’s performance on protein Q&A tasks, evaluated on the Mol-Instructions and UniProtQA datasets, shows significant improvements over other models, particularly in generating answers related to protein localization and functional predictions.
7/ This approach not only bridges the gap between protein sequence, structure, and natural language understanding but also paves the way for more accurate, flexible, and interpretable protein-related research, offering promising applications in drug discovery and disease research.
📜Paper: arxiv.org/abs/2502.06846
#ProteinLanguageModels #MachineLearning #AIinBiology #Bioinformatics #ProteinEngineering #DrugDiscovery #ComputationalBiology #ProteinQandA #DeepLearning #StructuralBiology
8
38
4,787
15 Feb 2025
Prot2Chat: Protein LLM with Early Fusion of Sequence and Structure
1/ Prot2Chat introduces an innovative protein question-answering (Q&A) system that integrates both protein sequence and structural data into a unified framework, enabling large language models (LLMs) to generate precise and contextually relevant responses.
2/ The model employs a modified ProteinMPNN encoder to fuse protein sequence and structural information early in the process. This early fusion improves model efficiency and enhances its ability to handle complex protein-related queries, far surpassing models that treat sequence and structure separately.
3/ Prot2Chat utilizes a protein-text adapter with cross-attention mechanisms, aligning protein embeddings with natural language. This alignment enables the model to effectively interpret and respond to questions about protein structure, function, and interactions in a more intuitive way.
4/ By using LoRA for fine-tuning the LLaMA3 decoder, Prot2Chat reduces computational cost while maintaining strong performance, making it a more efficient alternative to other large-scale protein language models.
5/ The model excels in zero-shot predictions and outperforms existing baselines, including models trained solely on sequence data. Prot2Chat's ability to integrate structure and sequence provides more accurate and biologically relevant answers.
6/ Prot2Chat’s performance on protein Q&A tasks, evaluated on the Mol-Instructions and UniProtQA datasets, shows significant improvements over other models, particularly in generating answers related to protein localization and functional predictions.
7/ This approach not only bridges the gap between protein sequence, structure, and natural language understanding but also paves the way for more accurate, flexible, and interpretable protein-related research, offering promising applications in drug discovery and disease research.
📜Paper: arxiv.org/abs/2502.06846
#ProteinLanguageModels #MachineLearning #AIinBiology #Bioinformatics #ProteinEngineering #DrugDiscovery #ComputationalBiology #ProteinQandA #DeepLearning #StructuralBiology

1
11
1,149