
My first research paper has been accepted to BioNLP Workshop, co-located with ACL 2026, San Diego!

16
1
131
5,931
Aligning LLMs with Biomedical Knowledge using Balanced Fine-Tuning
1. The paper argues that “low-confidence tokens” mean something different in biomedicine: they often form dense contiguous runs that encode rare entities (genes/mutations/pathway nodes) and mechanistic causal chains—i.e., epistemic uncertainty (knowledge gaps)—rather than the sparse stylistic alternatives (aleatoric uncertainty) common in general text.
2. This observation motivates Balanced Fine-Tuning (BFT), a dual-scale post-training objective designed to keep learning signal on knowledge-dense uncertainty while still stabilizing optimization—addressing a key failure mode where Dynamic Fine-Tuning (DFT) down-weights exactly the biomedical tokens that matter.
3. The authors operationalize “dense epistemic uncertainty” with a teacher-forcing diagnostic: compute per-token confidence, slide a 256-token window, and classify windows by (a) fraction of low-confidence tokens and (b) longest contiguous low-confidence run. Sparse-low windows (Group A) tend to be stylistic; dense-low windows (Group B) are enriched for biomedical entities and causal connectives.
4. BFT token-level innovation: replace DFT’s absolute confidence weighting with group-normalized reweighting using a local context confidence (mean confidence in a g=256 sliding window). Each token weight is proportional to cb,t / (Clocb,t ε), clipped to [0,1] and stop-gradient detached—suppressing isolated low-confidence outliers while preserving gradients in globally hard (dense-low) biomedical spans.
5. BFT sample-level innovation: reallocate learning across sequences using a bounded hard-sample coefficient derived from the minimum local context confidence within the sequence. This explicitly shifts optimization budget toward samples containing the hardest knowledge-dense regions, complementing token-level gating.
6. Across tasks (medical evaluation, biological reasoning, sparse-reward RL, and representation learning), BFT provides more consistent gains than SFT and DFT under the same training recipe and model family (DeepSeek-R1-Distill 14B/32B/70B), suggesting the uncertainty-aware loss design transfers across biomedical settings.
7. Backbone replacement results in agentic biology pipelines: swapping closed-source backbones with a BFT-aligned 70B model improves GeneAgent biological process reasoning and matches/exceeds the original VCWorld Gemini-2.5-Flash backbone on chemical perturbation reasoning (VCWorld average accuracy reported at 0.70 for BFT 70B vs 0.68 for Gemini-2.5-Flash; SFT/DFT replacements lag behind).
8. Sparse-reward RL compatibility is a key takeaway: after subsequent GRPO on Tahoe-100M with sparse binary rewards, SFT and DFT degrade, but all BFT variants improve (e.g., BFT 70B from 0.70 to 0.74 average on held-out VCWorld cell lines). The paper links this to richer mechanistic traces (more entities, more causal connectives, longer responses), which increases “credit assignment surface area” under sparse rewards.
9. Beyond generation, BFT aims to narrow the generative–discriminative split in computational biology: BFT-generated biomedical profile texts (encoded with a text embedding model) yield stronger gene- and cell-level representations, improving gene property prediction and gene interaction tasks, cell clustering, multimodal integration (scIB), and perturbation response prediction—sometimes rivaling or outperforming specialized biology foundation models in reported settings.
10. Practical considerations: BFT introduces only one main hyperparameter (window size g, default 256) and is reported robust across a broad range; it also shows reduced hidden preference transfer in a synthetic-data “subliminal learning” style safety test compared to SFT, staying closer to the base model’s behavior.
💻Code: github.com/TencentAILabHealt…
📜Paper: arxiv.org/abs/2511.21075
#LLM #BioNLP #ComputationalBiology #BiomedicalAI #FineTuning #ReinforcementLearning #SingleCell #PerturbationBiology #RepresentationLearning #AIAlignment

1
14
1,488

《CS224N:深度学习自然语言处理》是斯坦福大学的王牌课程。根据最新的课程安排(通常为 20-23 集,包含正式讲座和部分特邀讲座),以下是每一集的核心知识点列表:
核心课程 (第 1-10 集:基础与模型架构)
引言与词向量 (Intro & Word Vectors):介绍 NLP 历史;词义的表示方法;Word2vec 算法原理及梯度推导。
词向量与句法分析预热 (Word Vectors & Neural Nets):GloVe 模型;共现矩阵;评估词向量的方法(内部 vs 外部评估);词义消歧。
反向传播与神经网络 (Backpropagation & Neural Nets):多层感知机;反向传播的数学链式法则;矩阵求导技巧。
句法分析 (Dependency Parsing):句法结构的歧义性;基于转换的依存句法分析(Transition-based Parsing);神经依存解析器。
循环神经网络 (RNNs & Language Models):语言模型概念;n-gram 与神经网络语言模型;循环神经网络(RNN)及其优缺点。
梯度消失与长短期记忆网络 (Vanishing Gradients & LSTMs):RNN 的梯度消失/爆炸问题;LSTM 和 GRU 架构设计;双向 RNN 和多层 RNN。
机器翻译与注意力机制 (NMT, Seq2Seq & Attention):编码器-解码器架构;机器翻译的历史;**Attention(注意力机制)**的引入与计算步骤。
自注意力与 Transformer (Self-Attention & Transformers):从循环模型到并行模型的转变;Scaled Dot-Product Attention;Transformer 完整架构(多头注意力、位置编码)。
预训练模型 (Pretraining & BERT):模型预训练的思想;Word2vec 到 ELMo 再到 BERT;掩码语言模型(MLM)和下一句预测(NSP)。
大语言模型与 T5 (LLMs & T5):Transformer-Decoder 架构(GPT 系列);Encoder-Decoder 统一框架(T5 模型);模型规模缩放定律(Scaling Laws)。
进阶与应用 (第 11-20 集:LLM 时代新技术)
Prompting 指令微调与上下文学习 (Prompting, In-context Learning):零样本/少样本学习;思维链(CoT)推理;指令微调(Instruction Fine-tuning)。
模型对齐 (RLHF & DPO):人类反馈强化学习(RLHF);PPO 算法;直接偏好优化(DPO);如何让模型更安全、更符合人类意图。
高效微调与适配器 (Efficient Finetuning: LoRA):参数高效微调(PEFT);LoRA(低秩自适应)原理;混合精度训练与分布式训练。
检索增强生成 (RAG):解决模型幻觉问题;向量数据库;密集检索(Dense Retrieval)与重新排序(Reranking)。
模型评估与基准测试 (Evaluation & Benchmarking):除了困惑度(Perplexity)以外的评估方法;HELM、MMLU 等评测集;大模型时代的评估难题。
长文本处理 (Long Context & Efficient Transformers):Flash Attention;线性注意力;长文本处理的挑战与优化方案。
多模态 NLP (Multimodal NLP):视觉-语言模型(如 CLIP);图像描述生成(Image Captioning);多模态对话系统。
推理与逻辑 (Reasoning & Agents):AI Agents 架构(规划、记忆、工具使用);ReAct 框架;模型如何调用外部工具。
伦理与偏见 (Ethics, Bias & Fairness):模型中的偏见来源;隐私问题;生成内容的伦理边界。
NLP 的未来与挑战 (Future of NLP):当前技术的瓶颈;神经符号结合的可能性;体现智能(Embodied AI)。
专题讲座 (通常为第 21-23 集:特邀专家)
特定领域应用 (Special Topics: BioNLP/LegalNLP):深度学习在生物医学或法律领域的专门应用。
系统工程 (NLP Systems Engineering):如何在生产环境中部署超大规模模型。
期末项目展示与总结 (Final Project & Conclusion):课程回顾与优秀学生项目展示。
这套课程的逻辑是从词的数学表示开始,过渡到序列建模,最终进化到当下的**生成式大模型(LLMs)**架构与生态。
5
924


17 Sep 2025
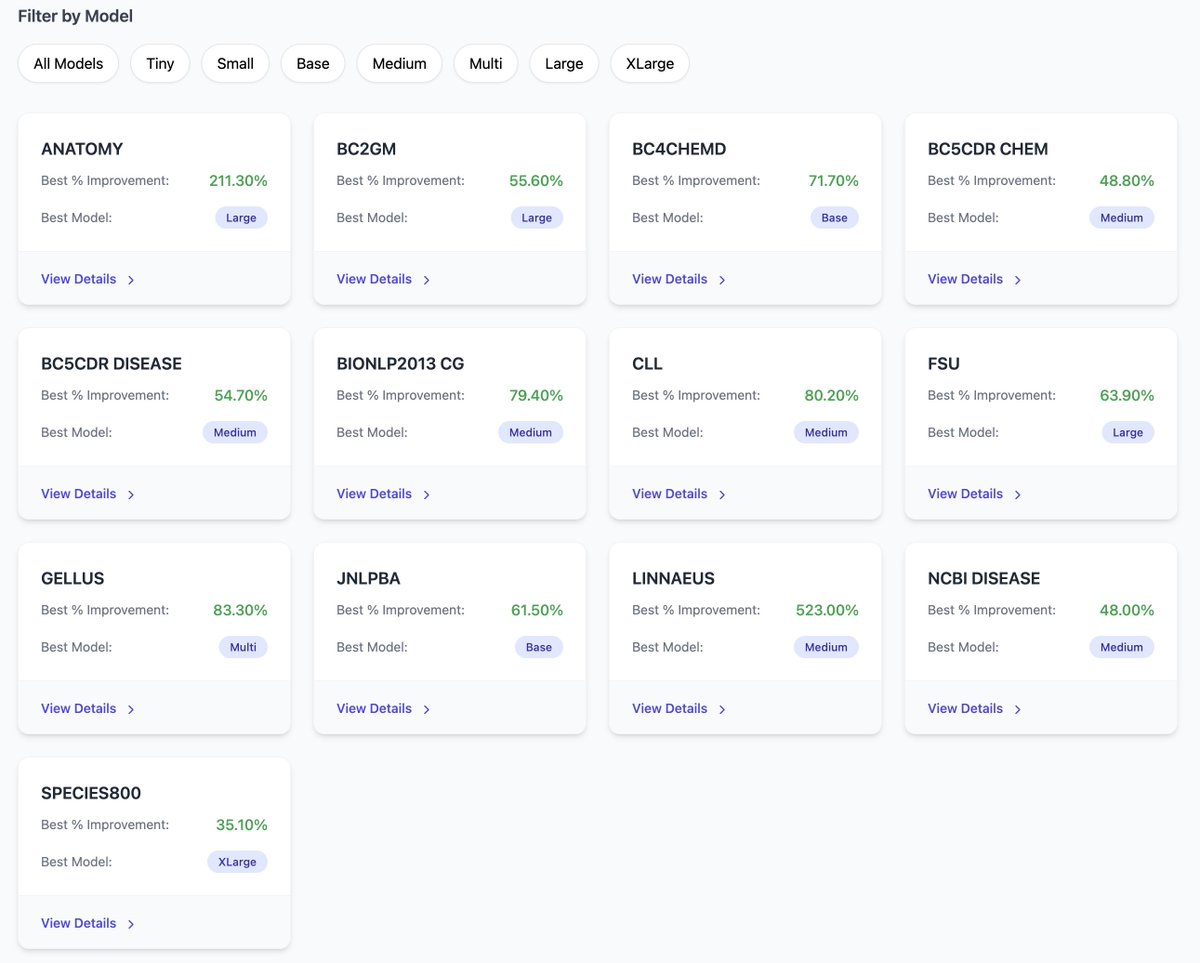
@OpenMed_AI Zero-Shot Clinical NER models across 13 biomedical datasets:
BC4CHEMD,
BC5CDR (chem disease),
BC2GM,
JNLPBA,
BioNLP 2013 CG,
GELLUS,
FSU,
CLL,
Anatomy (AnatEM),
Linnaeus,
Species‑800,
NCBI‑Disease.
16 Sep 2025

Introducing 90 open-source, state‑of‑the‑art biomedical and clinical zero‑shot NER models on @HuggingFace by @OpenMed_AI
Apache‑2.0 licensed and ready to use
Built on GLiNER and covering 12 biomedical datasets
🧵 (1/6)

2
3
178
16 Sep 2025
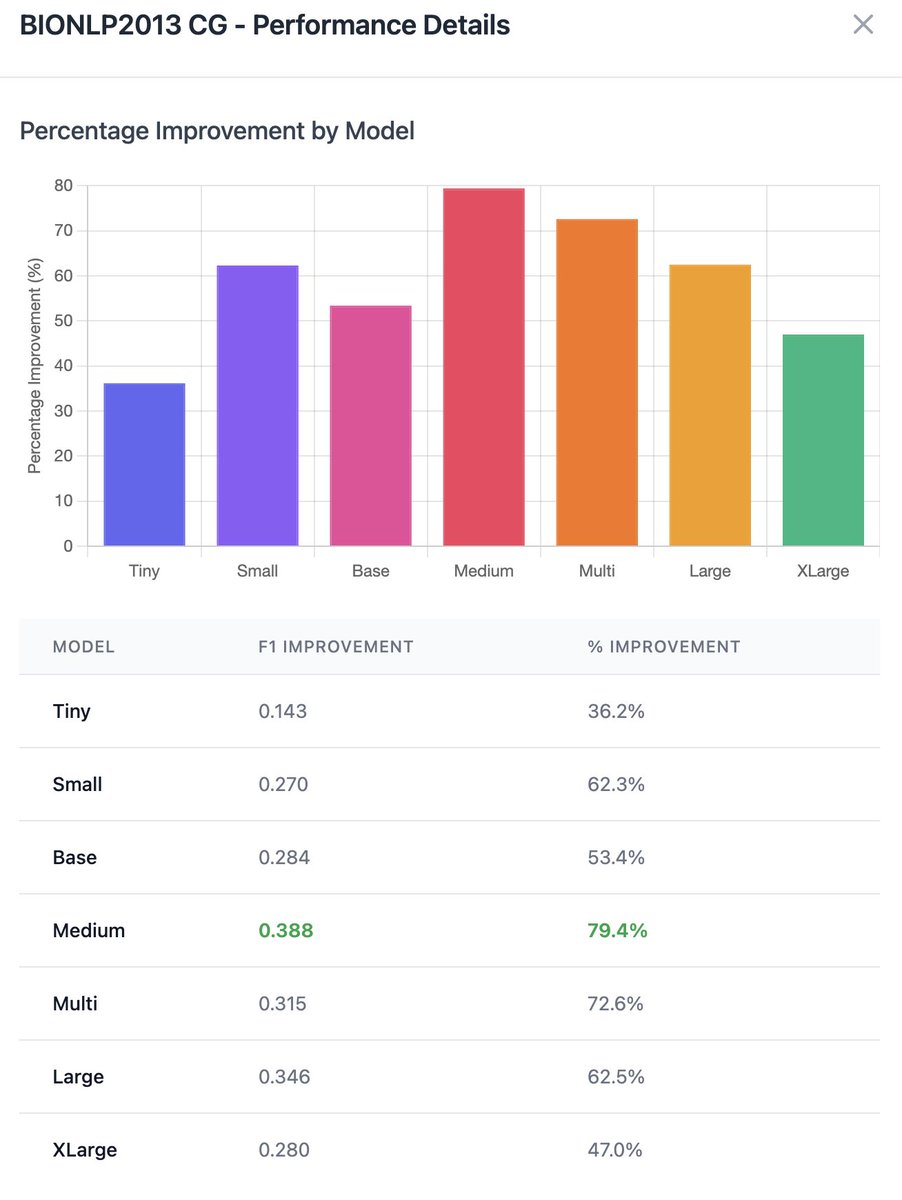
🔥 bionlp gains that scale: up to 79% F1
and the medium model tops the chart!
16 Sep 2025
Introducing 90 open-source, state‑of‑the‑art biomedical and clinical zero‑shot NER models on @HuggingFace by @OpenMed_AI
Apache‑2.0 licensed and ready to use
Built on GLiNER and covering 12 biomedical datasets
🧵 (1/6)
1
7
642
16 Sep 2025
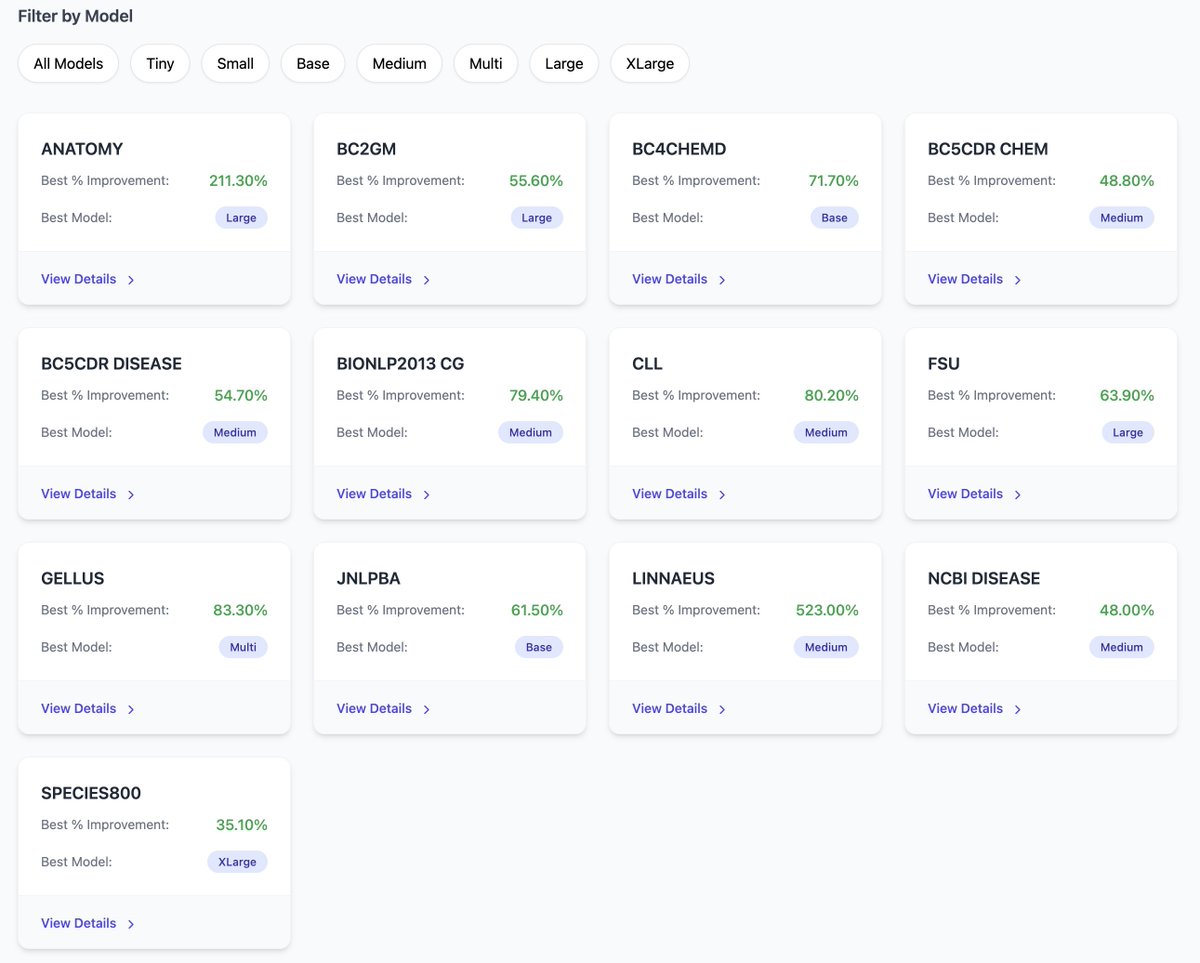
coverage includes:
BC4CHEMD,
BC5CDR (chem disease),
BC2GM,
JNLPBA,
BioNLP 2013 CG,
GELLUS,
FSU,
CLL,
Anatomy (AnatEM),
Linnaeus,
Species‑800,
NCBI‑Disease.
pick a size to match latency/accuracy needs and your deployment constraints.
🧵 (5/6)
1
7
906

7 Sep 2025
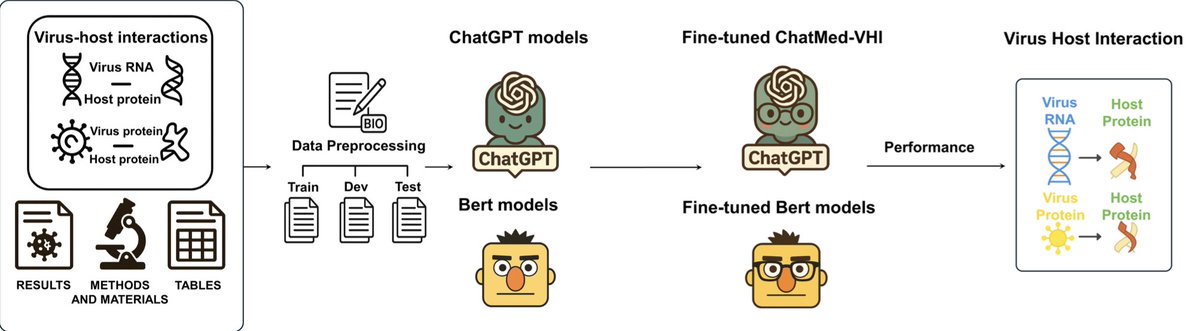
Instruction-tuned extraction of virus-host interactions from integrated scientific evidence
1. This study introduces a novel approach to extract virus-host interactions (VHIs) from full-text biomedical articles using instruction-tuned large language models (LLMs), specifically ChatMed-VHI based on ChatGPT-3.5, achieving high accuracy even with limited training data.
2. The researchers curated a comprehensive dataset from full-text articles, including Results, Methods, and tables, which is a significant improvement over previous methods that focused only on abstracts. This dataset contains 3,395 PPIs and 674 RPIs from narrative sections and 566 PPIs and 793 RPIs from tables.
3. ChatMed-VHI outperformed PubMedBERT under low-resource conditions, achieving an F1 score of 89.7% with fewer than 500 training examples. This demonstrates the effectiveness of instruction-tuned LLMs for extracting complex biomedical entities.
4. The study highlights the importance of section-aware extraction, as different sections of an article (e.g., Methods, Results) contain unique and valuable information for understanding virus-host interactions. ChatMed-VHI is designed to handle this diversity.
5. The authors also conducted a detailed analysis of model performance under varying training data sizes, showing that ChatMed-VHI maintains strong performance even with very limited data, making it highly scalable and adaptable for real-world applications.
6. The research underscores the potential of instruction-tuning for creating domain-specific NLP tools that can handle the complexity of biomedical literature, paving the way for future work in extracting more detailed and structured information from scientific texts.
7. The findings suggest that integrating full-text data and instruction tuning can significantly enhance the extraction of virus-host interactions, which is crucial for understanding infection mechanisms and developing therapeutic strategies.
📜Paper: biorxiv.org/content/10.1101/…
#BioNLP #VirusHostInteractions #InstructionTuning #LargeLanguageModels #BiomedicalResearch
1
4
8
1,506

📢 Kicking off the day at the BioNLP Workshop with the opening talk!
🧬 Accelerating Cross-Encoders in Biomedical Entity Linking
With: @JavierSanzCruza & @jakelever0
📍 Room 2.15
🕗 08:50–09:10
Drop by if you’re around — would love to chat!
#BioNLP #ACL2025NLP #EntityLinking

5
12
569

30 Jul 2025
Congratulations to Andrei Niculae (@nandre42) for obtaining 3rd🥉Best Paper Award at #BioNLP Workshop at #ACL2025 @aclmeeting at his first *CL Conference 🎉🎉
(1/3)
1
4
178

30 Jul 2025
If you're at BioNLP workshop #ACL2025, visit our poster at ArchEHR shared task. Our approach got the highest score on reconciled evaluation 🏆
Paper: aclanthology.org/2025.bionlp…

5
208

30 Jul 2025
Can LLMs predict the results of CRISPR screens in silico, before the experiment is run?
A team led by Aly Khan, AI/ML head at #CZBiohubCHI, has built a scalable LLM-based prediction framework. Read the 📃 just accepted to #BioNLP workshop at @ACLMeeting!
aclanthology.org/2025.bionlp…

4
34
151
16,708

29 Jul 2025
The joy of seeing citations coming in for first research work! (that too in the first page)
@SatyamModi02 and I had an awesome work last year at BioNLP Workshop, ACL 2024.
Check out our work here
🔗 Paper [aclanthology.org/2024.bionlp…]
🎥 Video [youtu.be/XH--Ob-2IMg?si=-tMt…]
#ACL2024


3
8
181

26 Jul 2025
An year after this preprint was out, we finally have a paper based on this work at the BioNLP workshop at #ACL2025. We are doing it online as neither my postdoc nor I can make it to the conference.
Proceedings version: aclanthology.org/2025.bionlp…
25 Jul 2024

DPO-like methods are used to align LLM outputs with human preferences. Can they make QA/IE better, a very different use case. We show how this can be done by *automatically* generating preference data from initial model errors to DPO a T5 model.
Preprint: arxiv.org/abs/2407.14000
9
692

15 Jul 2025
Had fun talking about biomedical information extraction with @JavierSanzCruza today. Check out the materials from our #ISMBECCB2025 virtual tutorial. It's a mini intro course on #BioNLP! ai4biomed.org/ismb2025tutori…
1
9
333
30 May 2025
BioHopR: A Benchmark for Multi-Hop, Multi-Answer Reasoning in Biomedicine
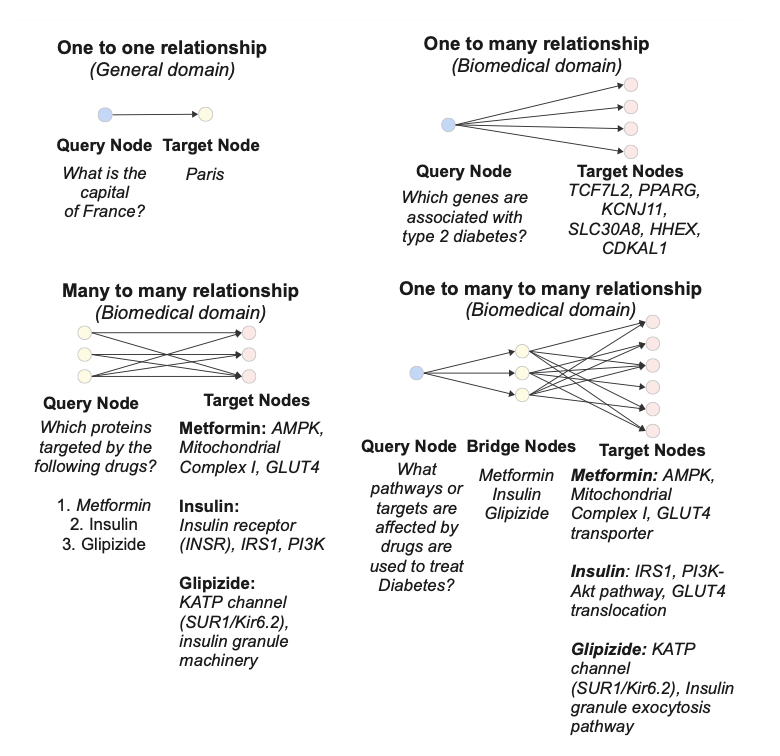
1.BioHopR introduces a new benchmark specifically designed to evaluate multi-hop, multi-answer reasoning capabilities of LLMs in the biomedical domain. It captures real-world complexity by focusing on one-to-many and many-to-many relationships, such as drug–disease–protein connections.
2.Unlike previous biomedical QA datasets that mainly target single-answer or template-based reasoning, BioHopR supports both 1-hop and 2-hop reasoning tasks using structured knowledge from the PrimeKG graph. This allows assessment of stepwise reasoning with multiple valid answers.
3.The benchmark contains 2,494 1-hop and 7,633 2-hop questions, totaling over 279,000 answers. Each query averages over 36 answers, emphasizing the challenge of handling exhaustive, many-to-many mappings in biomedical data.
4.A core innovation is the one-to-many-to-many design: for example, a single drug (query) can be linked to multiple proteins (bridge) and further to multiple diseases (target), reflecting real clinical reasoning scenarios.
5.BioHopR evaluates models’ precision based on cosine similarity using BioLORD-2023-C embeddings with a strict threshold (0.9), ensuring high-confidence matches in prediction evaluation.
6.State-of-the-art proprietary models, especially O3-mini and GPT4O, outperform open-source biomedical models in both 1-hop and 2-hop tasks. O3-mini achieves the highest 1-hop precision (37.93%) and ties with GPT4O in 2-hop precision (14.57%).
7.Open-source biomedical models, such as HuatuoGPT-o1 and UltraMedical-8B, exhibit severe difficulties in multi-hop tasks. HuatuoGPT-o1-70B fails almost entirely (Prec_HOP2: 0.00%), revealing a gap between intended capability and actual performance.
8.All models suffer a sharp performance drop when moving from 1-hop to 2-hop tasks, demonstrating that inferring intermediate bridge entities remains a major bottleneck in biomedical reasoning.
9.Qualitative case studies (e.g., on diabetes and schizophrenia) show proprietary models like GPT4O can produce medically justifiable answers even when they don't align perfectly with ground truth, while open-source models often fail to follow task constraints.
10.BioHopR also reveals prompt sensitivity: single-answer prompting outperforms multi-answer prompting significantly (e.g., GPT4O's 1-hop precision drops from 32.88% to 8.09% when prompted for multiple answers).
11.Some relation types (e.g., Phenotype:Disease:Drug) show slightly better performance in multi-answer prompting, suggesting structured queries with clear entity roles might be more model-friendly.
12.By benchmarking models on complex, real-world multi-step biomedical questions, BioHopR establishes a much-needed evaluation standard and exposes critical gaps in both reasoning depth and answer completeness.
13.Despite limitations like reliance on PrimeKG and coverage of only four entity types (Drug, Disease, Protein, Phenotype), BioHopR sets the groundwork for building more robust, interpretable LLMs for biomedical applications.
14.The authors emphasize that BioHopR is for research use only and not suited for clinical deployment without rigorous validation, mitigating risks of misuse in high-stakes settings.
💻Code: huggingface.co/datasets/know…
📜Paper: arxiv.org/abs/2505.22240v1
#BioHopR #LLMs #BiomedicalAI #MultiHopReasoning #BioNLP #KnowledgeGraphs #MedQA
2
4
562
23 May 2025
Prot2Chat: Protein LLM with Early-Fusion of Text, Sequence and Structure
1.Prot2Chat is a novel protein question-answering (Q&A) framework that performs early fusion of protein sequence, structure, and natural language text, enabling large language models to generate accurate and context-aware answers about protein functions.
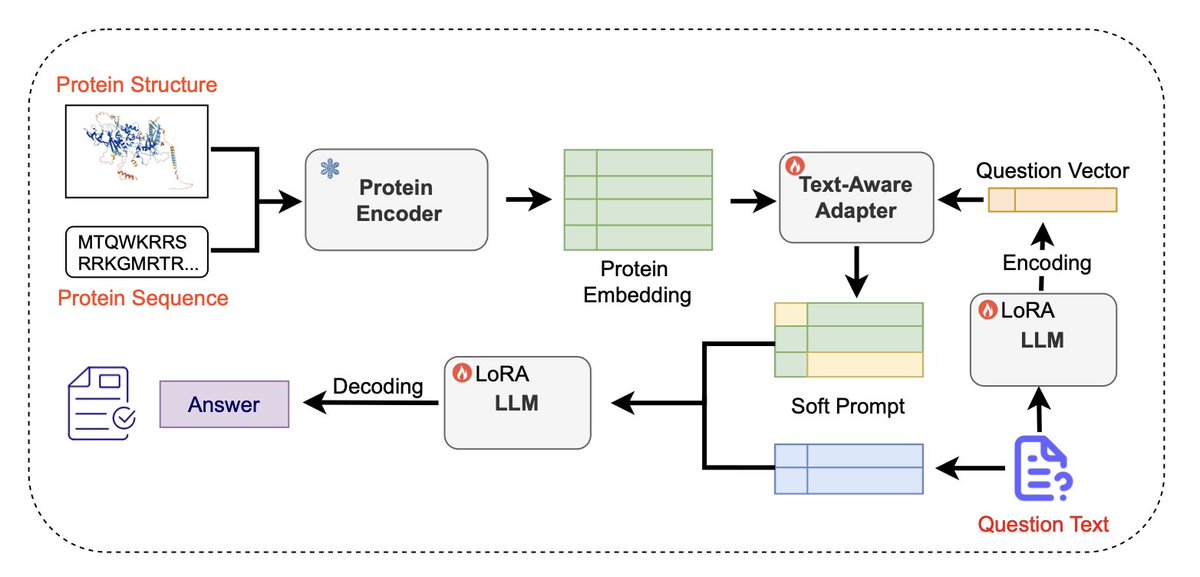
2.The model modifies ProteinMPNN to produce a fused representation of protein sequence and structure, then compresses this information into a set of “soft prompts” using a text-aware adapter guided by the question input—allowing seamless integration with LLMs.
3.Unlike prior protein LLMs that rely on late fusion or modular encoders, Prot2Chat aligns protein information and text early in the encoding process. This results in significantly better alignment between input protein context and the generated response.
4.On the Mol-Instructions benchmark, Prot2Chat outperforms all baselines—including Evola-10B and BioMedGPT—by wide margins, achieving 35.85 BLEU-2 and 50.51 ROUGE-L, which are 3–5× better than state-of-the-art models.
5.Even with just 109M trainable parameters (vs. 3B in BiomedGPT), Prot2Chat achieves higher expert evaluation rankings and stronger generalization, as validated on UniProtQA through both fine-tuning and zero-shot experiments.
6.Ablation studies confirm the importance of each component: removing early-fused text, protein sequence, or LLM fine-tuning significantly degrades performance. Early fusion is especially critical for aligning protein representations with textual queries.
7.The protein-text adapter uses multi-head cross-attention to align question-guided text with compressed protein embeddings, effectively acting as a semantic bridge between the biochemical world and natural language.
8.Prot2Chat enables residue-level reasoning and function annotation by LLMs, demonstrating superior performance in case studies involving functional inference from sequences and structures—critical for protein annotation and variant interpretation.
9.Compared to models like Evola and ProtChatGPT, Prot2Chat is more computationally efficient and provides higher-quality answers without relying on external knowledge bases or retrieval-augmented generation.
10.This work establishes a lightweight yet powerful protein-language model that unifies multimodal biological representations, advancing the utility of LLMs in biological discovery and protein function exploration.
💻Code: github.com/wangzc1233/Prot2C… 📜Paper: arxiv.org/abs/2502.06846
#ProteinLLM #Prot2Chat #MultimodalFusion #ProteinFunction #ComputationalBiology #StructuralBioinformatics #ProteinMPNN #LLM #BioNLP #AI4Science
4
15
1,026
23 May 2025
Prot2Chat: Protein LLM with Early-Fusion of Text, Sequence and Structure
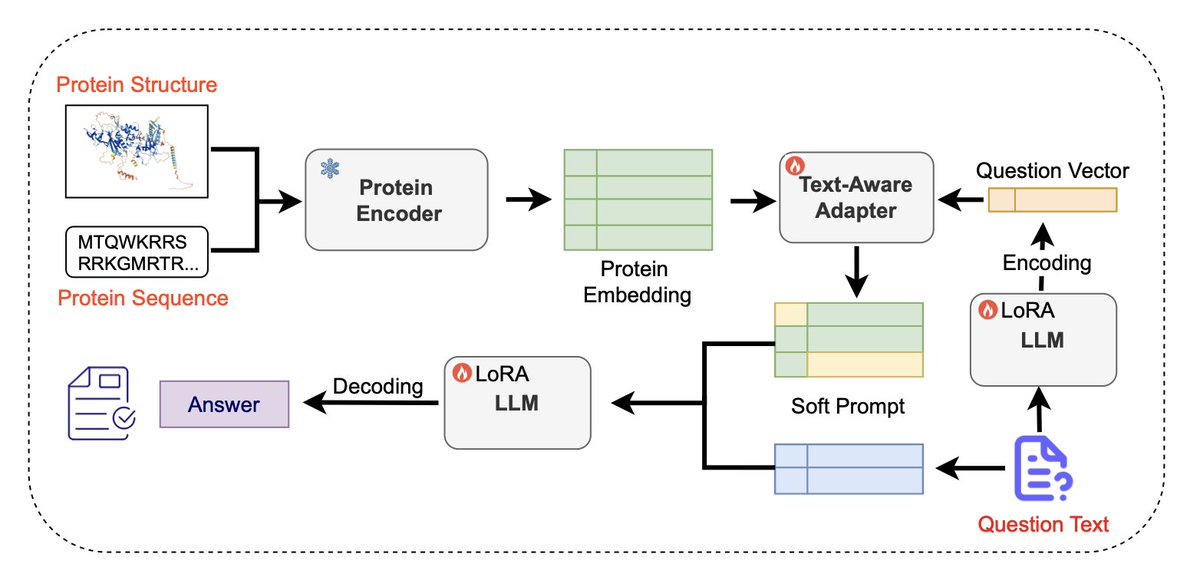
1.Prot2Chat is a novel protein question-answering (Q&A) framework that performs early fusion of protein sequence, structure, and natural language text, enabling large language models to generate accurate and context-aware answers about protein functions.
2.The model modifies ProteinMPNN to produce a fused representation of protein sequence and structure, then compresses this information into a set of “soft prompts” using a text-aware adapter guided by the question input—allowing seamless integration with LLMs.
3.Unlike prior protein LLMs that rely on late fusion or modular encoders, Prot2Chat aligns protein information and text early in the encoding process. This results in significantly better alignment between input protein context and the generated response.
4.On the Mol-Instructions benchmark, Prot2Chat outperforms all baselines—including Evola-10B and BioMedGPT—by wide margins, achieving 35.85 BLEU-2 and 50.51 ROUGE-L, which are 3–5× better than state-of-the-art models.
5.Even with just 109M trainable parameters (vs. 3B in BiomedGPT), Prot2Chat achieves higher expert evaluation rankings and stronger generalization, as validated on UniProtQA through both fine-tuning and zero-shot experiments.
6.Ablation studies confirm the importance of each component: removing early-fused text, protein sequence, or LLM fine-tuning significantly degrades performance. Early fusion is especially critical for aligning protein representations with textual queries.
7.The protein-text adapter uses multi-head cross-attention to align question-guided text with compressed protein embeddings, effectively acting as a semantic bridge between the biochemical world and natural language.
8.Prot2Chat enables residue-level reasoning and function annotation by LLMs, demonstrating superior performance in case studies involving functional inference from sequences and structures—critical for protein annotation and variant interpretation.
9.Compared to models like Evola and ProtChatGPT, Prot2Chat is more computationally efficient and provides higher-quality answers without relying on external knowledge bases or retrieval-augmented generation.
10.This work establishes a lightweight yet powerful protein-language model that unifies multimodal biological representations, advancing the utility of LLMs in biological discovery and protein function exploration.
💻Code: github.com/wangzc1233/Prot2C…
📜Paper: arxiv.org/abs/2502.06846
#ProteinLLM #Prot2Chat #MultimodalFusion #ProteinFunction #ComputationalBiology #StructuralBioinformatics #ProteinMPNN #LLM #BioNLP #AI4Science
9
762
22 May 2025
MolLangBench: A Comprehensive Benchmark for Language-Prompted Molecular Structure Recognition, Editing, and Generation
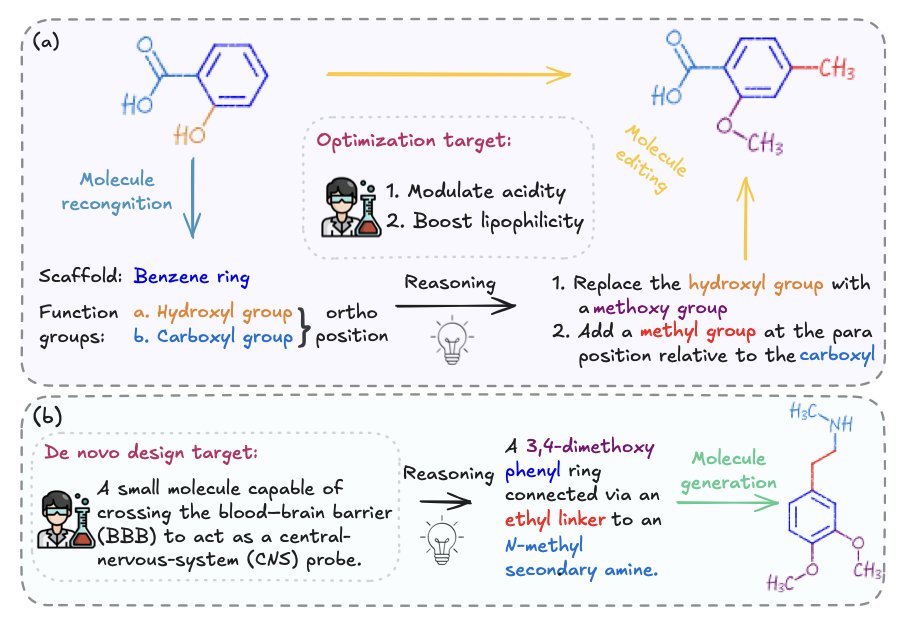
1.MolLangBench introduces a rigorously curated benchmark to evaluate AI models on three fundamental molecule-language tasks: structure recognition, language-guided molecule editing, and molecular generation from natural language. It reveals substantial performance gaps even in state-of-the-art models.
2.All benchmark tasks are designed to be deterministic and unambiguous, with outputs validated through multi-stage annotation pipelines involving expert chemists. This ensures high-quality datasets that reflect real-world chemical reasoning demands.
3.The structure recognition task tests if a model can extract detailed atomic information—like neighbors, bond types, ring junctions, and functional groups—based on SMILES strings or molecular images. Ground-truth includes atom indices and counts, enabling precise evaluation.
4.Editing tasks simulate realistic modification scenarios, such as substituting groups or fusing rings, guided by concise, human-readable instructions. The ground truth is a unique resulting molecule in SMILES format, manually validated by multiple chemists.
5.Generation tasks push the limits of models by requiring them to construct complete molecular structures from rich natural language descriptions, including stereo and positional details. Each description maps to a unique molecule, minimizing ambiguity.
6.The benchmark supports multimodal inputs including SMILES strings, 2D molecular images, and potentially graphs. However, graph-language models remain underdeveloped and were not evaluated in this release.
7.Results show that even advanced models like GPT-4o and o3 struggle—achieving only 79.2% accuracy in recognition and just 29.0% in generation. Vision-language models like GPT Image 1 perform even worse, failing entirely on the generation task.
8.Common failure modes include inability to localize atoms, misinterpretation of stereochemistry, and poor SMILES validity. Tokenization issues in LLMs contribute to errors in atom enumeration and structure manipulation.
9.Annotation for editing and generation is highly time-intensive (40–60 minutes per sample), highlighting the difficulty of creating high-quality benchmarks in chemistry. The authors propose future data expansion via rule-based synthesis of molecular descriptions.
10.MolLangBench sets a new standard for evaluating AI capabilities in chemical structure understanding and manipulation. It exposes current limitations in LLMs and VLMs, and offers a foundation for developing more chemically literate AI systems.
💻Code: huggingface.co/datasets/Chem…
📜Paper: arxiv.org/abs/2505.15054
#Cheminformatics #LLM #MolecularDesign #MoleculeLanguage #ComputationalChemistry #MolLangBench #BioNLP #AI4Science
3
9
1,051
22 May 2025
MolLangBench: A Comprehensive Benchmark for Language-Prompted Molecular Structure Recognition, Editing, and Generation
1.MolLangBench introduces a rigorously curated benchmark to evaluate AI models on three fundamental molecule-language tasks: structure recognition, language-guided molecule editing, and molecular generation from natural language. It reveals substantial performance gaps even in state-of-the-art models.
2.All benchmark tasks are designed to be deterministic and unambiguous, with outputs validated through multi-stage annotation pipelines involving expert chemists. This ensures high-quality datasets that reflect real-world chemical reasoning demands.
3.The structure recognition task tests if a model can extract detailed atomic information—like neighbors, bond types, ring junctions, and functional groups—based on SMILES strings or molecular images. Ground-truth includes atom indices and counts, enabling precise evaluation.
4.Editing tasks simulate realistic modification scenarios, such as substituting groups or fusing rings, guided by concise, human-readable instructions. The ground truth is a unique resulting molecule in SMILES format, manually validated by multiple chemists.
5.Generation tasks push the limits of models by requiring them to construct complete molecular structures from rich natural language descriptions, including stereo and positional details. Each description maps to a unique molecule, minimizing ambiguity.
6.The benchmark supports multimodal inputs including SMILES strings, 2D molecular images, and potentially graphs. However, graph-language models remain underdeveloped and were not evaluated in this release.
7.Results show that even advanced models like GPT-4o and o3 struggle—achieving only 79.2% accuracy in recognition and just 29.0% in generation. Vision-language models like GPT Image 1 perform even worse, failing entirely on the generation task.
8.Common failure modes include inability to localize atoms, misinterpretation of stereochemistry, and poor SMILES validity. Tokenization issues in LLMs contribute to errors in atom enumeration and structure manipulation.
9.Annotation for editing and generation is highly time-intensive (40–60 minutes per sample), highlighting the difficulty of creating high-quality benchmarks in chemistry. The authors propose future data expansion via rule-based synthesis of molecular descriptions.
10.MolLangBench sets a new standard for evaluating AI capabilities in chemical structure understanding and manipulation. It exposes current limitations in LLMs and VLMs, and offers a foundation for developing more chemically literate AI systems.
💻Code: huggingface.co/datasets/Chem…
📜Paper: arxiv.org/abs/2505.15054
#Cheminformatics #LLM #MolecularDesign #MoleculeLanguage #ComputationalChemistry #MolLangBench #BioNLP #AI4Science

1
4
724