
Feb 8
🚀 Bir ML Projesini "Hobi" Seviyesinden "Klinik Standartlara" Nasıl Taşırız?
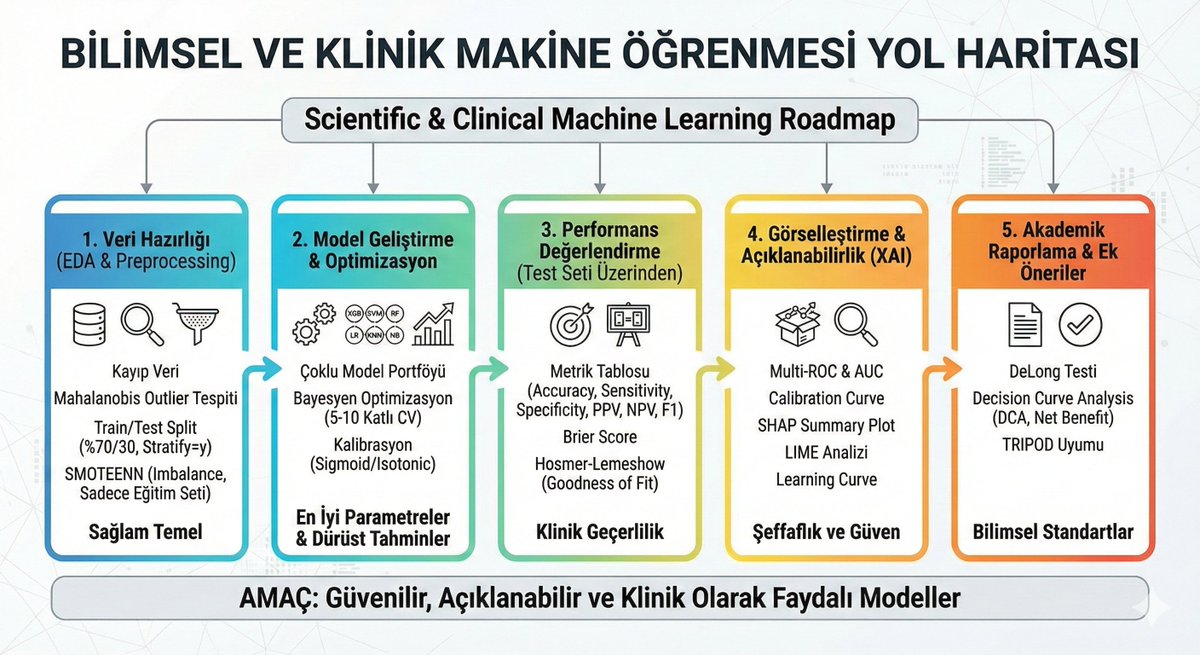
Sadece model.fit() ve model.predict() yazıp geçmek işin en kolay kısmı. Ancak konu sağlık, finans ya da kritik karar destek sistemleri olduğunda, standart bir kod satırından çok daha fazlasına ihtiyacınız var. Gerçekten güvenilir ve akademik olarak kabul edilebilir bir model geliştirmenin "altın standart" yol haritasını 5 adımda özetledim:
1. Veri Hazırlığı: Bataklığa Gökdelen Dikilmez 🧬
Veri setindeki gürültüyü temizlemeden yola çıkmak, temelini atmadığınız bir binanın katlarını çıkmaya benzer.
Mahalanobis Mesafesi: Sadece tekil değişkenlere bakmıyoruz. Tek başına normal görünen bir veri, diğer değişkenlerle birleştiğinde "imkansız" bir vaka (multivariate outlier) olabilir. Bunu yakalamak, modelin sağlığı için kritik.
SMOTEENN Stratejisi: Sınıf dengesizliğini sadece eğitim setinde çözüyoruz. Test setine asla dokunmuyoruz; çünkü test setiniz, gerçek hayatın tüm acımasızlığını ve dengesizliğini yansıtmak zorunda.
2. Optimizasyon: Modelin Sadece "Zeki" Değil, "Dürüst" Olsun ⚙️
XGBoost veya SVM kullanmak yetmez; modelin verdiği karardan ne kadar emin olduğunu bilmemiz gerekir.
Bayesyen Optimizasyon: Rastgele denemelerle (RandomSearch) vakit kaybetmek yerine, akıllı bir arama algoritmasıyla en optimum parametreleri buluyoruz.
Kalibrasyon (Platt Scaling): Model "� ihtimalle hastalık var" diyorsa, 100 vakanın gerçekten 80'inde o sonuç çıkmalı. Karar vericinin (doktor veya yönetici) güvenini kazanmak için olasılık tahminlerini kalibre ediyoruz.
3. Metriklerin Ötesi: Klinik Geçerlilik 📊
Yüksek bir Accuracy (Doğruluk) skoru genellikle yanıltıcı bir illüzyondur. Özellikle sağlıkta "kaçırmamak" (Sensitivity) ve "gereksiz alarm vermemek" (Specificity) arasındaki o bıçak sırtı dengeyi kurmalıyız.
Brier Score: Sadece doğru/yanlış tahminine değil, tahminlerin kalitesine odaklanıyoruz.
Hosmer-Lemeshow Testi: Modelin veriye ne kadar uyum sağladığını (Goodness of Fit) istatistiksel olarak kanıtlamak, akademik kabul için olmazsa olmazdır.
4. XAI: "Kara Kutu" Devrini Kapatıyoruz 🔍
"Model böyle dedi, yapacak bir şey yok" deme lüksümüz yok. Nedenini açıklamak zorundayız.
SHAP & LIME: Globalde hangi özelliklerin önemli olduğunu, lokalde ise (spesifik bir hasta/dosya özelinde) kararın nasıl verildiğini şeffaf hale getiriyoruz.
Learning Curves: Modelin ezberleyip ezberlemediğini (overfitting), gerçekten öğrenip öğrenmediğini bu grafiklerle ispatlıyoruz.
5. Akademik Raporlama ve Karar Analizi 📝
Projenin sadece kodda kalmaması, bilimsel literatürde ve sahada karşılık bulması için son dokunuş:
Decision Curve Analysis (DCA): Modelin klinik ortamda kullanılmasının "Net Faydası" (Net Benefit) nedir? Bu analiz, modelin kağıt üzerinde değil, gerçek dünyada işe yarayıp yaramayacağını söyler.
TRIPOD Uyumu: Raporlamayı uluslararası standartlara göre yaparak, çalışmanın dünyanın her yerinde tekrarlanabilir ve güvenilir olmasını sağlıyoruz.
💡 Özetle: Bir modeli başarılı kılan sadece AUC skoru değil; o modelin ne kadar açıklanabilir, ne kadar kalibre edilmiş ve sahada ne kadar faydalı olduğudur.
14
337

Jan 18
During the first six months of 'Jack's Law' police say they've seized more than 600 weapons, ranging from elaborate knives to replica firearms. 'Jack's Law' allows officers to conduct random wanding operations to detect if people are carrying weapons in a public place. #JacksLaw #BodyCam #RandomSearch #Queensland
1
2
1,120

Jan 3
Hyperparameter tuning (model optimizasyonu - GridSearch/RandomSearch) Cross-validation ve backtesting (model güvenilirliği) Model interpretability (SHAP values, feature interactions)
1) Hyperparameter tuning (GridSearch / RandomSearch) – “Model optimizasyonu”
Ne yapar?
Modelin öğrenme süreciyle ilgili ayarlarını (hyperparameter) en iyi hale getirir. Bunlar modelin veriden “ne kadar esnek / ne kadar katı” öğrenmesini belirler. Örn: ağaç derinliği, regularization gücü, learning rate, n_estimators, C, gamma vs.
GridSearch
Senin belirlediğin değerlerin tüm kombinasyonlarını dener.
Artısı: Sistematik; “şu aralıkta en iyisi hangisi” net görürsün.
Eksisi: Kombinasyon sayısı büyüdükçe maliyet patlar.
RandomSearch
Arama uzayından rastgele kombinasyonlar dener.
Artısı: Aynı bütçede çoğu zaman Grid’e göre daha hızlı iyi sonuca yaklaşır (özellikle çok parametre varsa).
Eksisi: Tam kapsamlı taramaz; ama pratikte çoğu projede daha verimli olur.
“Modelin performansını sadece ‘algoritma seçerek’ değil, algoritmanın davranışını belirleyen ayarları optimize ederek yükseltiyorum; Grid/RandomSearch ile en iyi hiperparametre setini, uygun validasyon düzeninde seçiyorum.”
4
1
14
1,302

31 Dec 2025
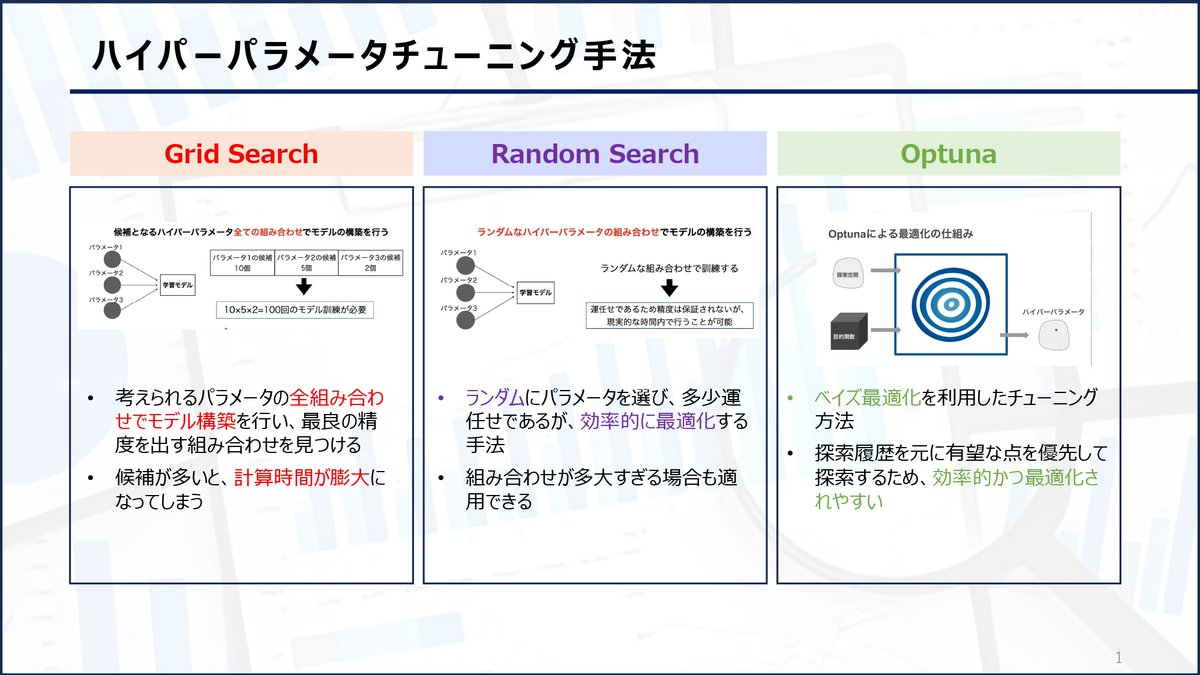
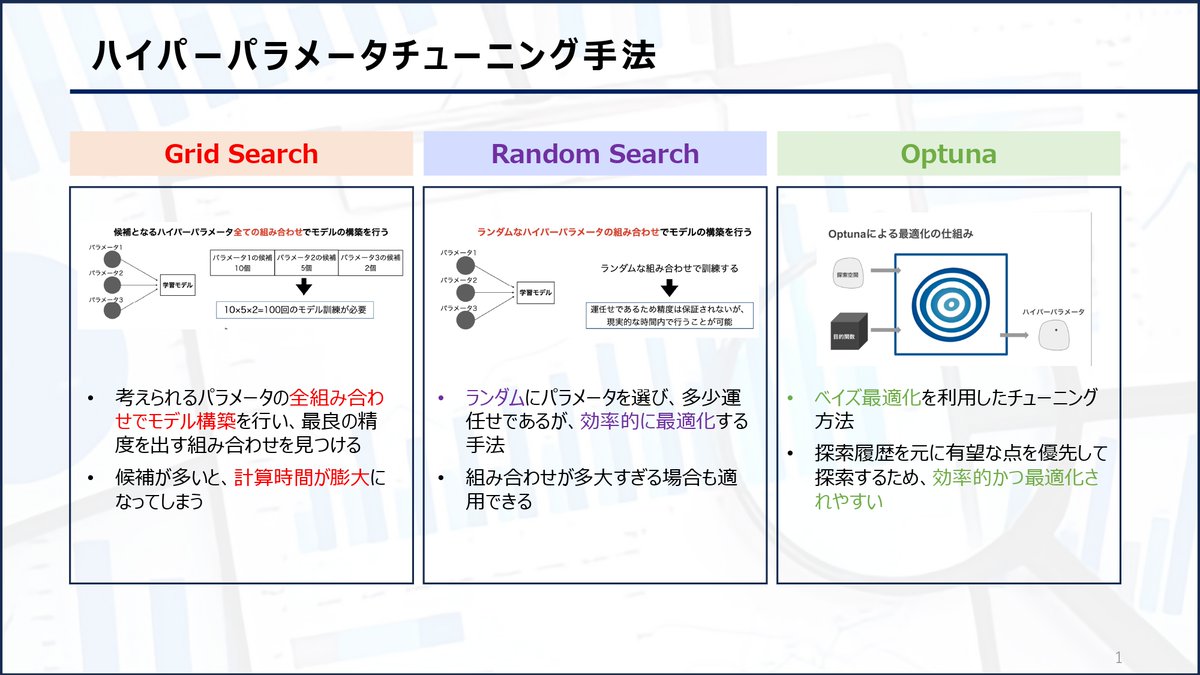
【ハイパーパラメータチューニング方法】
機械学習のハイパーパラメータを最適化する3つの方法を紹介します。
・GridSearch
・RandomSearch
・Optuna
それぞれの方法をよく把握して利用しましょう!
1
8
92
9,111
17 Sep 2025
【ハイパーパラメータチューニング方法】
機械学習のハイパーパラメータを最適化する3つの方法を紹介します。
・GridSearch
・RandomSearch
・Optuna
それぞれの方法をよく把握して利用しましょう!

1
16
1,673

14 Aug 2025
✅ Roadmap to Become a Machine Learning Engineer 🤖📈
*1. Programming Fundamentals*
- Master Python (NumPy, Pandas, Matplotlib)
- Learn object-oriented programming
- Version control with Git & GitHub
*2. Math for ML*
- Linear algebra, calculus
- Probability and statistics
- Optimization basics (gradient descent, cost functions)
*3. Core Machine Learning Concepts*
- Supervised vs Unsupervised learning
- Algorithms: Linear regression, decision trees, SVM, KNN
- Evaluation metrics: accuracy, precision, recall, F1-score
*4. Model Implementation*
- Use Scikit-learn for ML models
- Understand model training, testing, validation
- Hyperparameter tuning (GridSearch, RandomSearch)
*5. Deep Learning*
- Neural networks, CNNs, RNNs, LSTMs
- Frameworks: TensorFlow, Keras, PyTorch
- Activation functions, loss functions, backpropagation
*6. Data Engineering Skills*
- SQL for data queries
- Data cleaning and preprocessing
- Work with large datasets
*7. Model Deployment*
- Create REST APIs with Flask or FastAPI
- Use Docker for containerization
- Basics of CI/CD pipelines
*8. MLOps & Production*
- Model monitoring & retraining
- MLflow for experiment tracking
- Use cloud platforms: AWS Sagemaker, GCP Vertex AI
*9. Projects & Portfolio*
- End-to-end ML systems
- Kaggle competitions & real-life use cases
- Share projects on GitHub & blogs
*10. Interview Preparation*
- ML theory and use-case discussions
- Data structures & algorithms
- Mock interviews and system design
💬 *Tap ❤️ for more!*
7
769
4 Jul 2025
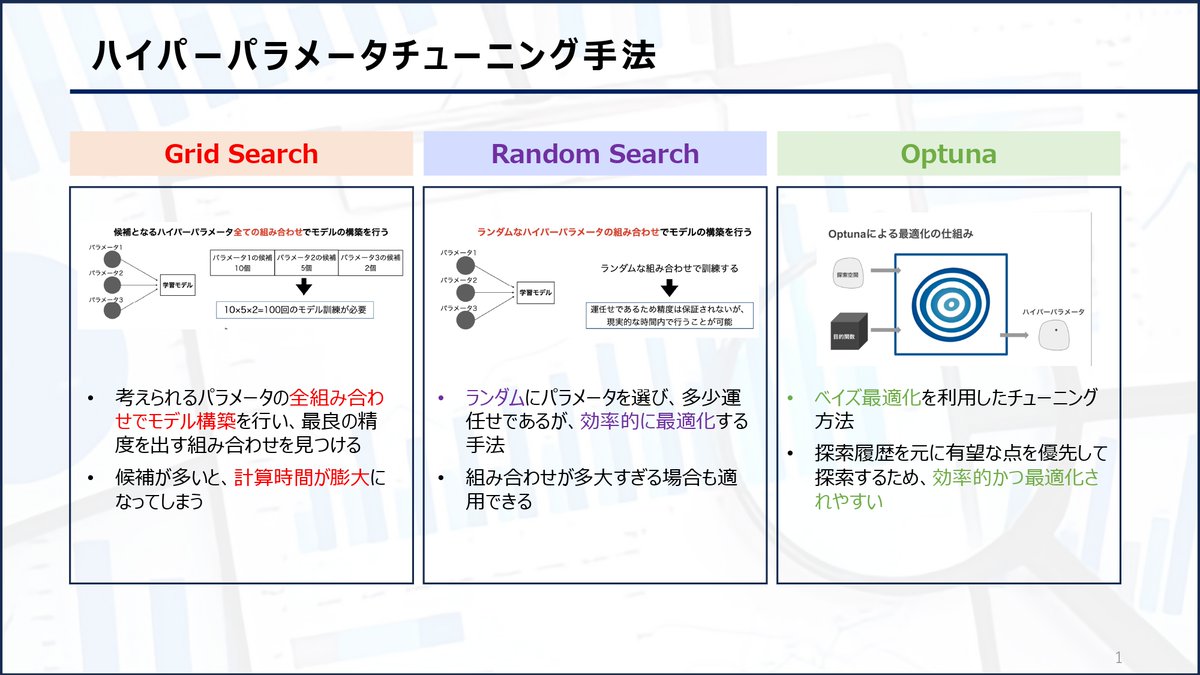
【ハイパーパラメータチューニング方法】
機械学習のハイパーパラメータを最適化する3つの方法を紹介します。
・GridSearch
・RandomSearch
・Optuna
それぞれの方法をよく把握して利用しましょう!
7
92
6,635

1 Jul 2025
Grid Search 🆚 Random Search
Comparing Two Key Methods for Hyperparameter Tuning in Machine Learning.
Check out this video📹 for a side-by-side look at the pros and cons of each approach.
#DataScience #AI #ML #MachineLearning #gridsearch #randomsearch #hyperparametertuning
4
221
25 Jun 2025
Grid Search 🆚 Random Search: Two powerful methods for hyperparameter tuning in Machine Learning.
Here's a chart for a side-by-side comparison of their pros and cons.
#DataScience #AI #ML #Machinelearning #hyperparameter #gridsearch #randomsearch

3
119

6 Jun 2025
Why don’t you Google/chatgpt/anyother randomsearch the origin of name “India”? Does it cost too much and you need a world bank loan to do that?
3
87
1 May 2025
【ハイパーパラメータチューニング方法】
機械学習のハイパーパラメータを最適化する3つの方法を紹介します。
・GridSearch
・RandomSearch
・Optuna
それぞれの方法をよく把握して利用しましょう!

2
68
5,701

13 Mar 2025
Saber cómo hacer gridsearch o randomSearch, cómo funciona la regularización y los tipos de hay (l1, l2, drop-out para NN y más).
Saber por qué pasa el desvanecimiento o explosión del gradiente y cómo se suele evitar.
1
16
9,236
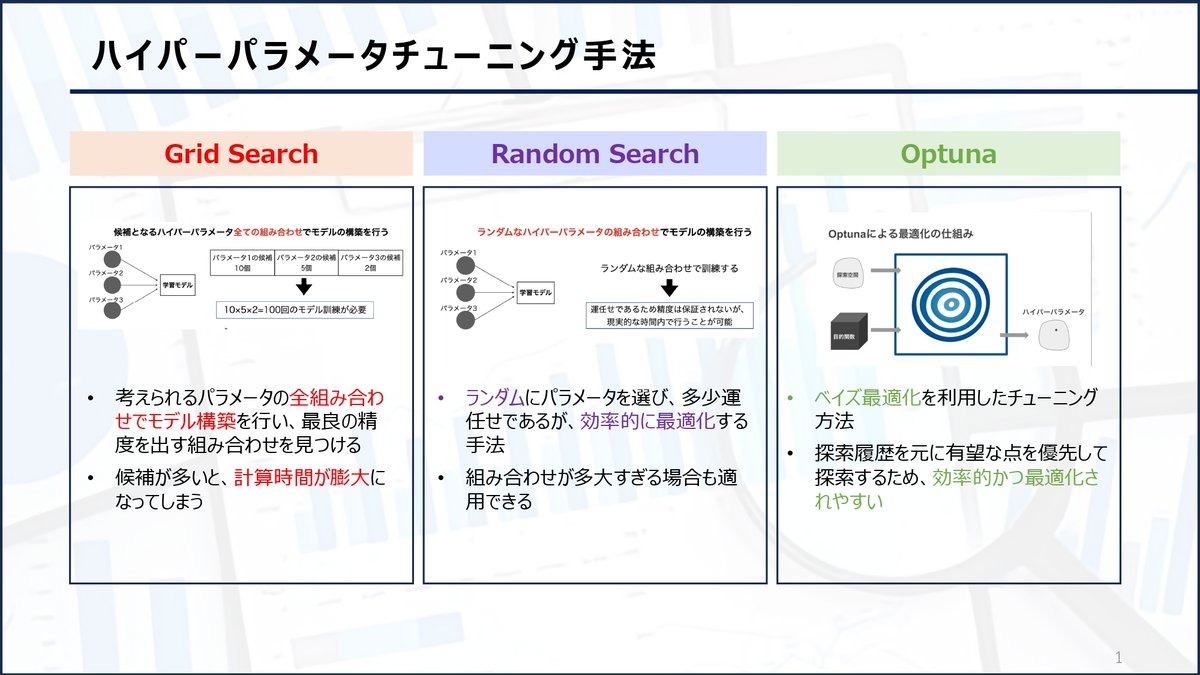
27 Feb 2025
【ハイパーパラメータチューニング方法】
機械学習のハイパーパラメータを最適化する3つの方法を紹介します。
・GridSearch
・RandomSearch
・Optuna
それぞれの方法をよく把握して利用しましょう!
3
23
2,545

2 Jan 2025
【ハイパーパラメータチューニング方法】
機械学習のハイパーパラメータを最適化する3つの方法を紹介します。
・GridSearch
・RandomSearch
・Optuna
それぞれの方法をよく把握して利用しましょう!
2
24
2,944
8 Dec 2024
【機械学習のパラメータチューニングを「これでもか!」というくらい丁寧に解説】
パラーメータチューニングに加え、評価指標にも言及された1800いいね越えの有料級の良記事です!
まず以下の3つの違いを把握しましょう。
・GridSearch
・RandomSearch
・Optuna
qiita.com/c60evaporator/item…
1
24
1,386

11 Nov 2024
More innocent passengers stopped and searched at their airport gates. InvestigateTV is following the story Monday at 4:30 on K8-ABC. #airport #DEA #RandomSearch.
1
795
