
What an Autonomous Agent Discovers About Molecular Transformer Design: Does It Transfer?
1. The paper runs a controlled, large-scale test of whether “molecular Transformers should be different from NLP Transformers” using an autonomous LLM agent that edits training code. Across SMILES, proteins, and English (control), it executes 3,106 GPU-bounded experiments and explicitly separates architecture changes from hyperparameter (HP) tuning.
2. Core result: the value of architecture search is strongly domain-dependent. In NLP (FineWeb-Edu, long context, large vocab), architecture search accounts for 81% of the total improvement over baseline (padj = 0.009), while HP tuning contributes 19% (padj = 0.022).
3. In SMILES (ZINC-250K, short sequences, 37-char vocab), architecture search is counterproductive: HP tuning alone achieves 151% of the total improvement (padj = 0.001), meaning the HP-only agent beats the full “architecture HP” agent on average (best bpb 0.581 vs 0.586). The architecture contribution is negative (−51%, not significant).
4. Proteins (UniRef50) land in between: total gains exist but are small, and neither HP nor architecture contributions reach significance. The study interprets this as “architecture-insensitive” behavior at ~10M parameters for this setup.
5. Methodological innovation: a 4-condition design that cleanly decomposes gains: (a) full LLM agent (architecture HP), (b) random NAS (architecture sampled uniformly; default HPs), (c) HP-only LLM agent (architecture frozen by prompt), (d) fixed default baseline. This enables direct attribution of improvements to HP tuning vs architecture search.
6. Search-efficiency metric: besides final validation bits-per-byte (bpb), it reports AUC-OC (area under the best-so-far curve across 100 trials). On SMILES, HP-only converges fastest and lowest; on NLP, the full agent separates early (~20 trials) and keeps improving; on proteins, all curves cluster tightly.
7. Apparent specialization vs real universality: agent-discovered “best architectures” cluster by domain (permutation test on mixed-feature Gower distances, p = 0.004), suggesting the agent finds different designs for SMILES vs NLP vs proteins.
8. But transfer tests overturn the usual expectation: every discovered innovation transfers across domains with <1% degradation (41/41 universal; binomial p = 2×10−19 against a predicted 35% universal rate). The paper argues the clustering reflects search-path dependence (what the agent tries first given early signals), not fundamental biological requirements—at least at this ~8.6M parameter, short-training regime.
9. Practical takeaway framed as a decision rule: small vocab short sequences (e.g., SMILES-like: <100 tokens, <500 length) → prioritize HP tuning; large vocab long context (NLP-like: >1K tokens, >1K length) → full architecture search is worth it; proteins may show thin margins at this scale.
10. The agent repeatedly rediscovers broadly useful Transformer tweaks that are also known in NLP, including grouped query attention (KV head compression), gated MLPs (e.g., SwiGLU/GeGLU), learned per-layer residual scaling, and using value embeddings every layer (vs alternating). Downstream sanity checks show SMILES pretraining improvements can translate to MoleculeNet linear-probe ROC-AUC ~0.74–0.76 and high-validity generation.
💻Code: github.com/ewijaya/autoresea…
📜Paper: arxiv.org/abs/2603.28015
#ComputationalBiology #Bioinformatics #DrugDiscovery #Proteins #Transformers #NeuralArchitectureSearch #HyperparameterTuning #LLMAgents #MachineLearning

1
10
1,420

Mar 26
📢 #highlycited paper
📚 Improving #HardenabilityModeling: A Bayesian Optimization Approach to Tuning Hyperparameters for #NeuralNetworkRegression
🔗 mdpi.com/2076-3417/14/6/2554
👨🔬 by Wendimu Fanta Gemechu et al.
🏫 Silesian University of Technology
#Bayesianoptimization #hyperparametertuning
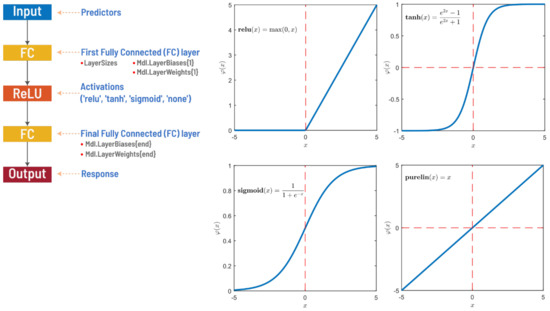
1
2
25


30 Dec 2025
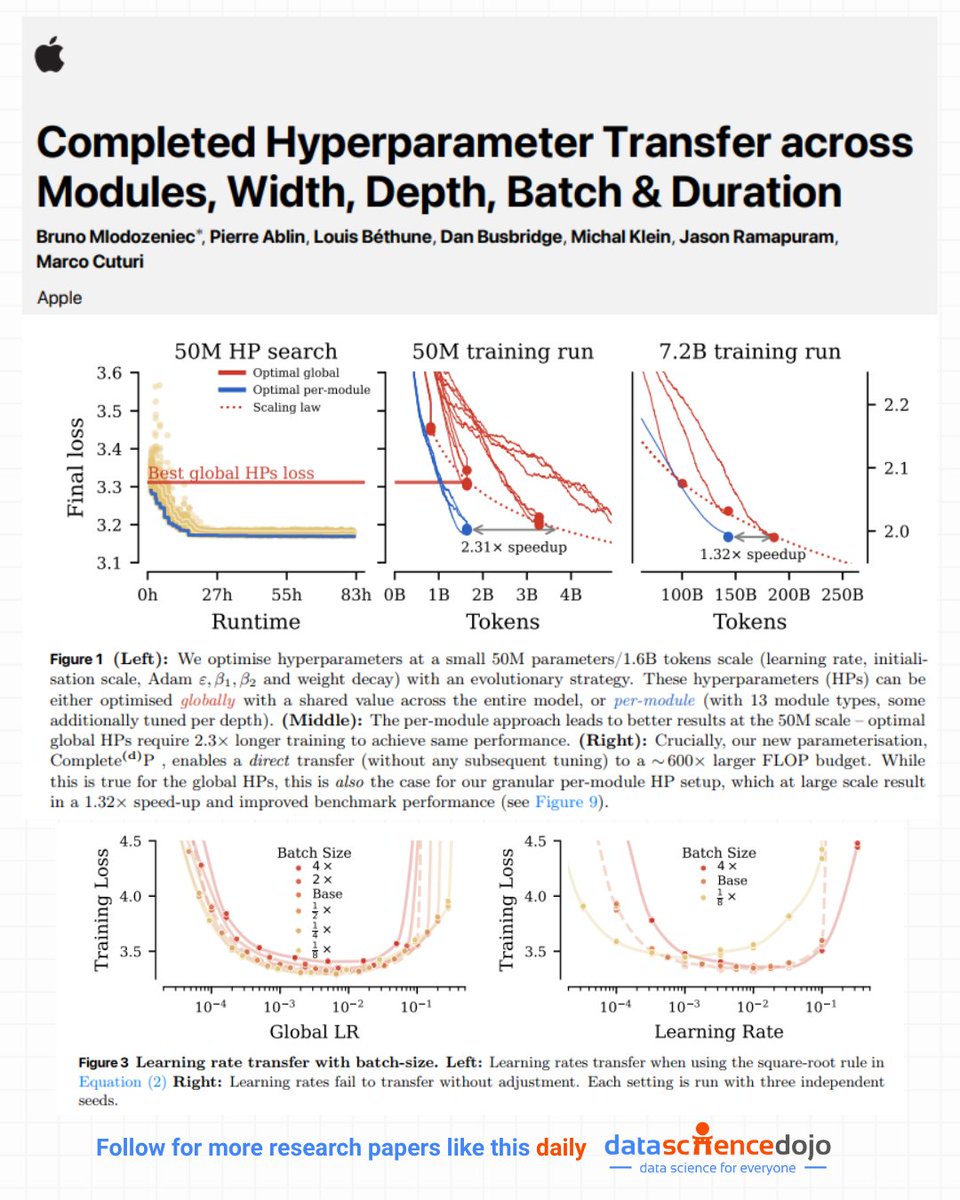
📢 Apple just released a paper that tackles one of the most persistent practical challenges in training large models: hyperparameter tuning at scale.
While many advances in deep learning focus on bigger architectures or more data, this work dives deep into a deceptively difficult problem: how do you find good hyperparameters — like learning rates, weight decay, and optimizer settings — once you scale models up by orders of magnitude?
The authors build on recent ideas in hyperparameter parameterizations and extend them with a new framework called Complete(d)P, which unifies scaling across model width, depth, batch size, and training duration. Instead of treating each scaling axis separately, their approach lets you search for optimal hyperparameters on a small model and then transfer them reliably to much larger models — even when you change batch size or the number of training tokens.
A key insight from this paper is that tuning hyperparameters at scale doesn’t have to mean expensive grid searches or manual trial-and-error on every new configuration. With the right parameterization, the structure of the optimization landscape can be understood well enough at small scale that the same settings still work when everything grows — reducing training cost and improving stability across scales.
The authors also show that this per-module hyperparameter transfer works better than global tuning alone, and that it can yield real speedups and more reliable training behavior as models get larger.
In short, this paper is a thoughtful reminder that scaling ML systems isn’t just about bigger models — it’s about smarter training design. And that optimizing how we train at scale can unlock efficiency gains that are just as important as any architectural breakthrough.
#MachineLearning #HyperparameterTuning #ModelScaling #AITraining #DeepLearning #Optimization #Research #LLMs #EfficientAI
1
4
928

14 Jul 2025
Deploy distributed hyperparameter tuning across Akash for lightning-fast model optimization. Save time and cloud costs while hunting optimal configurations.
#MachineLearning #HyperparameterTuning #DistributedSystems
$AKT $SPICE
1
1
4
135

10 Jul 2025
Better models, fewer trials. 🎯
Optuna = Fast, automated hyperparameter tuning 🚀
✅ Boost performance
✅ ML/DL friendly
✅ Built-in pruning parallelization
No more guesswork – just smarter tuning.
🔗 launchwebx.com
#Optuna #ML #DL #AI #HyperparameterTuning #MLOps

1
3
132

1 Jul 2025
Grid Search 🆚 Random Search
Comparing Two Key Methods for Hyperparameter Tuning in Machine Learning.
Check out this video📹 for a side-by-side look at the pros and cons of each approach.
#DataScience #AI #ML #MachineLearning #gridsearch #randomsearch #hyperparametertuning
4
221

30 Apr 2025
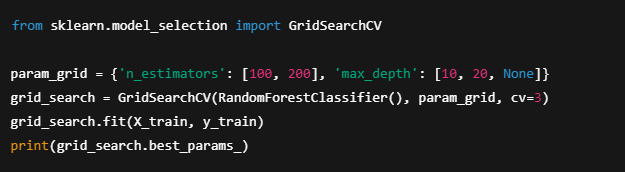
Want to boost your ML model?
Try Hyperparameter Tuning!
Adjust settings like learning rate or batch size for better performance.
Use GridSearchCV to find the best ones automatically:
#AI #MachineLearning #MLTips #HyperparameterTuning
5
167

20 Mar 2025
HyperOPT (Hyperparameter Optimization)
- Finding the best settings for topic models can be tough!
- HyperOPT automates hyperparameter tuning using Bayesian optimization, saving time & boosting model performance.
#AI #HyperparameterTuning
1
3
115

16 Feb 2025
Trying to tune hyperparameters be like: Which one actually works?!
#MachineLearning #HyperparameterTuning

2
6
116

Exactly, Hyperparameters can be the difference between a good model and a great one. Small tweaks can lead to significant improvements in performance. #AI #HyperparameterTuning #TechInsights #openfabricai
7
581
22 Dec 2024
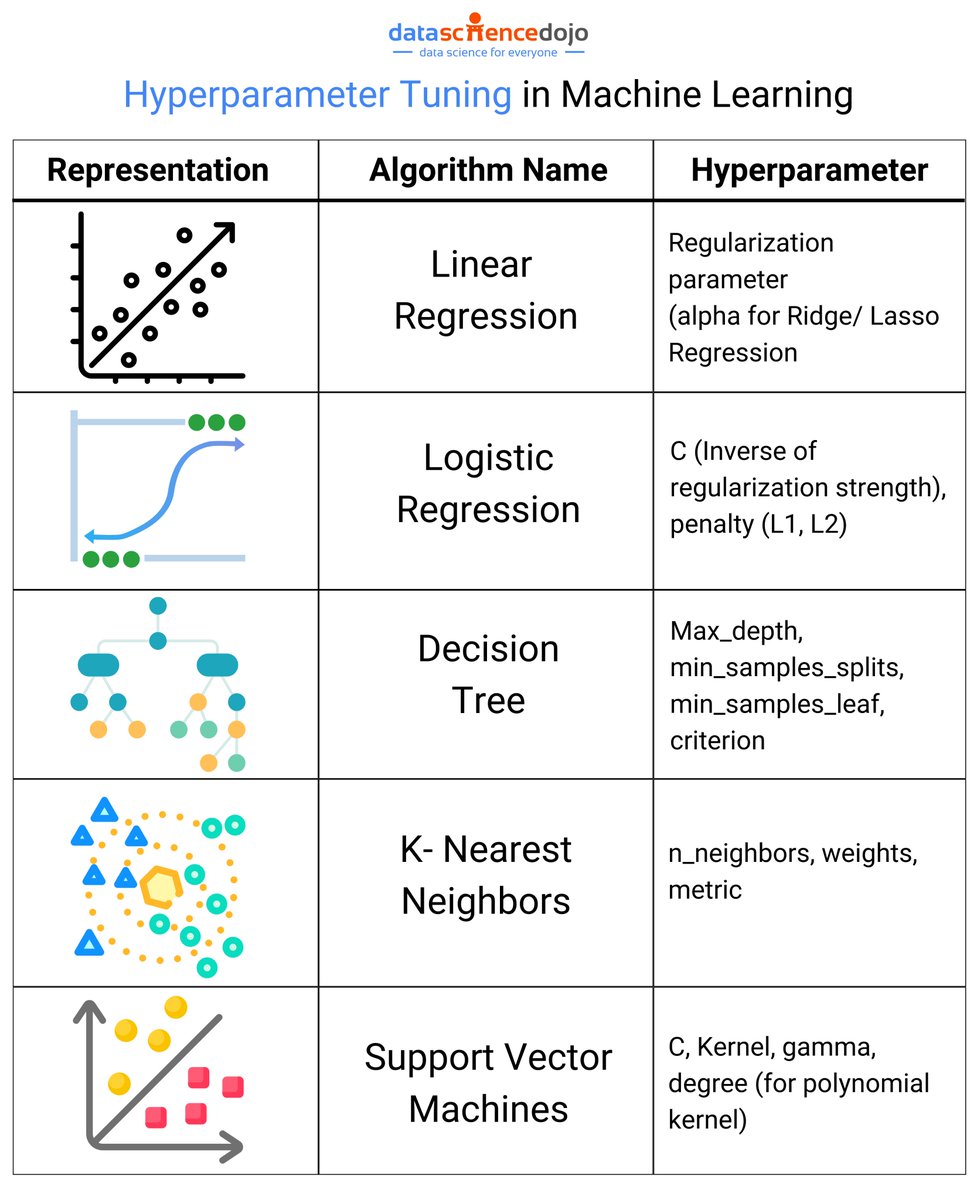
Did you know that fine-tuning hyperparameters can make or break your model's performance? 💡
From regularization strength in regression to kernel and gamma in SVMs, each parameter is key to optimizing your algorithm’s accuracy and efficiency.
📢 Join our Discord Learners Community today and stay ahead with the latest trends and exclusive resources ➡️ discord.gg/KQDDqJMQKf
#MachineLearning #HyperparameterTuning #MLModels #AICommunity #DataScience
7
34
3,335

3 Sep 2024
io.net (build on Solana) together with FLock.io introduces PoAI, a consensus mechanism for the integrity and scalability in decentralized AI networks getcontext.org/?q=io.net AI #PoAI #LLMs #hyperparametertuning #SolanaCommunity #Solana #SolanaProjects
2
38
31 Aug 2024
Just like fine-tuning a race car for optimal performance, hyperparameter tuning adjusts specific settings.
Join our 5-Day Data Science Bootcamp both online and in-person with industry experts now➡️ hubs.la/Q02NfXNP0
#HyperparameterTuning #MachineLearning #datascience

1
56
264
20,380
11 Aug 2024
Just like fine-tuning a race car for optimal performance, hyperparameter tuning adjusts specific settings within a machine learning model to achieve the best results.
Learn to build and deploy custom LLM Applications ➡️ hubs.la/Q02KTWdv0
#HyperparameterTuning #LLMBootcamp
2
31
110
8,455

24 Jul 2024
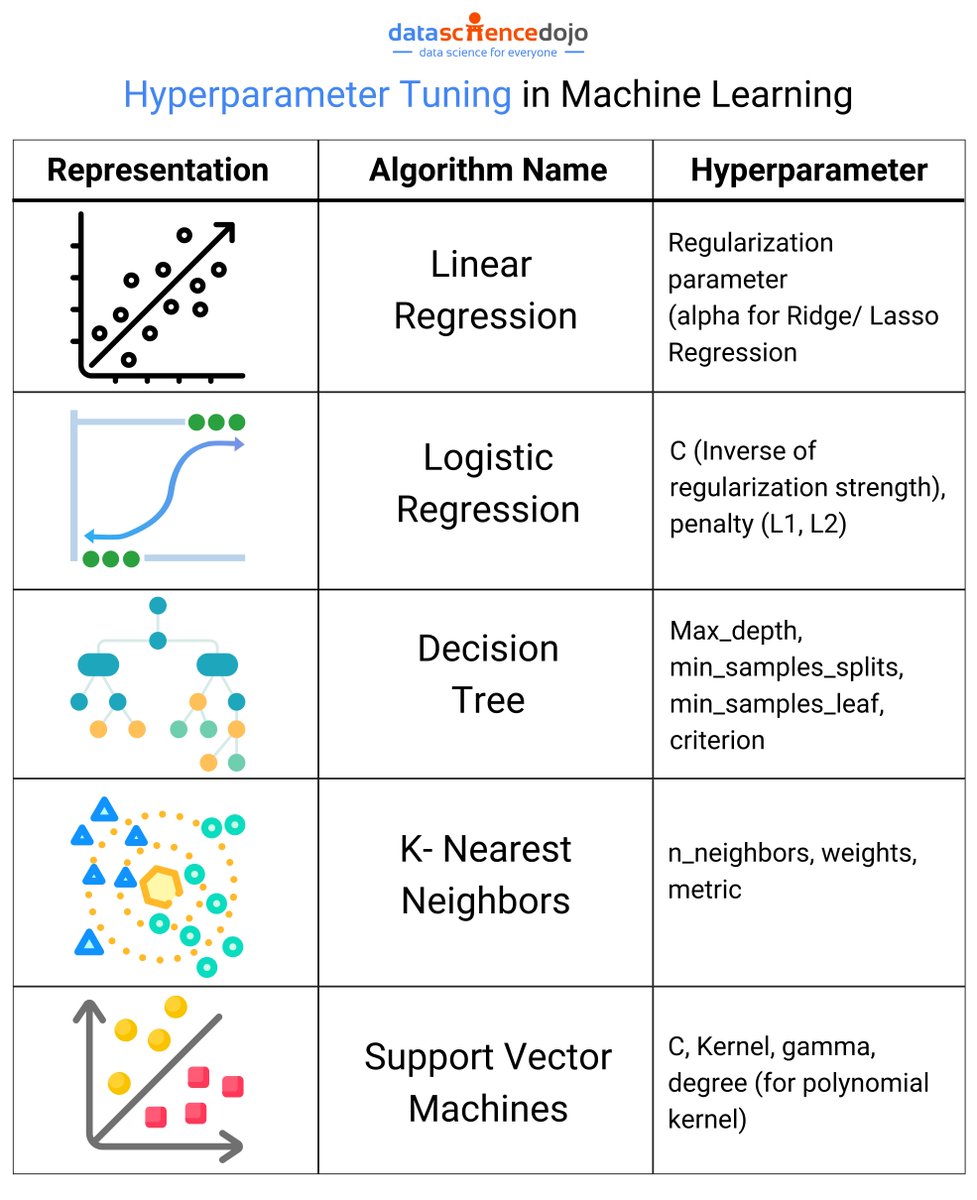
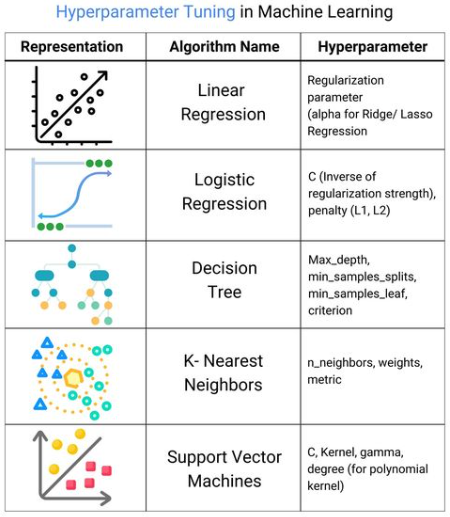
This infographic dives into the world of hyperparameter tuning and the importance of choosing the right algorithms for different tasks.
#HyperparameterTuning #MachineLearning #LLM
2
7
336

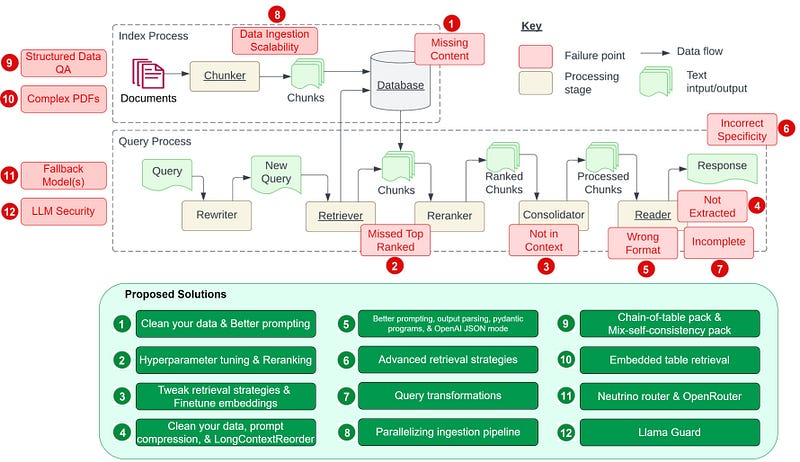
1. Data quality is crucial 📊: Whether addressing missing content issues or handling context problems, clean data is essential for the proper functioning of the RAG pipeline.
2. Prompt engineering and hyperparameter tuning are vital for performance ⚙️: Improving prompts and adjusting hyperparameters like chunk_size and similarity_top_k can significantly enhance the performance of RAG systems.
3. Advanced retrieval strategies and query transformation can improve the accuracy and completeness of answers 🎯: Techniques such as “small-to-large” retrieval, chain table packing, and hybrid self-consistency query engines can boost RAG systems' performance in handling complex queries and structured data.
4. Security and scalability are key considerations in RAG system design 🔒: As RAG systems become more widespread, preventing prompt injection, handling unsafe outputs, and preventing sensitive information leaks are critical. Llama guard offers a mechanism to secure LLM inputs and outputs by classifying content.
5. Using fallback models and routers can improve system stability and efficiency 🌐: Employing fallback models like neutrino routers and open routers ensures continuous operation when the primary model encounters issues.
6. Developing and deploying RAG systems is a multifaceted challenge 🚀: Developers need to consider system design, data processing, model selection, and performance optimization to ensure the effectiveness and robustness of RAG systems in practical applications.
#AI #Coding #FutureTech #AIResearch #CodeGeneration #Tech #MachineLearning #TechInnovation #DataQuality #PromptEngineering #HyperparameterTuning #AdvancedRetrieval #QueryTransformation #Security #Scalability #FallbackModels #SystemDesign #PerformanceOptimization
1
2
67

31 May 2024
BrainExpand🧠 - Exploratory AI Pipeline Overview
DataSets: DataCollection (Python, R, Apache Kafka, Google Colab, Kaggle) ➡ DataCleaning (Pandas, OpenRefine, Trifacta) ➡ DataAugmentation (imgaug, Albumentations) ➡ DataNormalization (scikit-learn, TensorFlow) ➡ DataSplitting (scikit-learn, train_test_split)
Algorithms: SupervisedLearning (scikit-learn, TensorFlow, Azure ML) ➡ UnsupervisedLearning (scikit-learn, Keras, IBM Watson) ➡ SemiSupervisedLearning (scikit-learn, PyTorch, Google Colab) ➡ ReinforcementLearning (OpenAI Gym, TensorFlow, Azure ML)
NeuralNetworks: Layers (Keras, PyTorch) ➡ ActivationFunctions (TensorFlow, Keras) ➡ WeightInitialization (PyTorch, Keras) ➡ Backpropagation (TensorFlow, PyTorch) ➡ GradientDescent (scikit-learn, TensorFlow)
Overfitting: Regularization (Keras, TensorFlow) ➡ Dropout (Keras, TensorFlow)
ModelEvaluation: CrossValidation (scikit-learn) ➡ Metrics (scikit-learn, TensorFlow)
FeatureEngineering: FeatureSelection (scikit-learn, Boruta) ➡ FeatureExtraction (Pandas, scikit-learn)
ModelTraining: Training (TensorFlow, PyTorch, Databricks) ➡ Validation (scikit-learn) ➡ Testing (scikit-learn)
HyperparameterTuning: GridSearch (scikit-learn) ➡ RandomSearch (scikit-learn) ➡ CrossValidation (scikit-learn)
FineTuning (Keras, PyTorch) ➡ TransferLearning (TensorFlow, Keras)
ModelDeployment: Docker, Kubernetes, AWS SageMaker, Google Cloud AI Platform, Azure ML ➡ Monitoring (Prometheus, Grafana, MLflow) ➡ Retraining (Kubeflow, Apache Airflow)
Interpretability: SHAP, LIME, PDP
Collaboration and Automation: Git, MLflow, Weights & Biases, Kubeflow, Apache Airflow
#AI #DeepLearning #MachineLearning #AIUnlock #TechMystery
126

28 May 2024
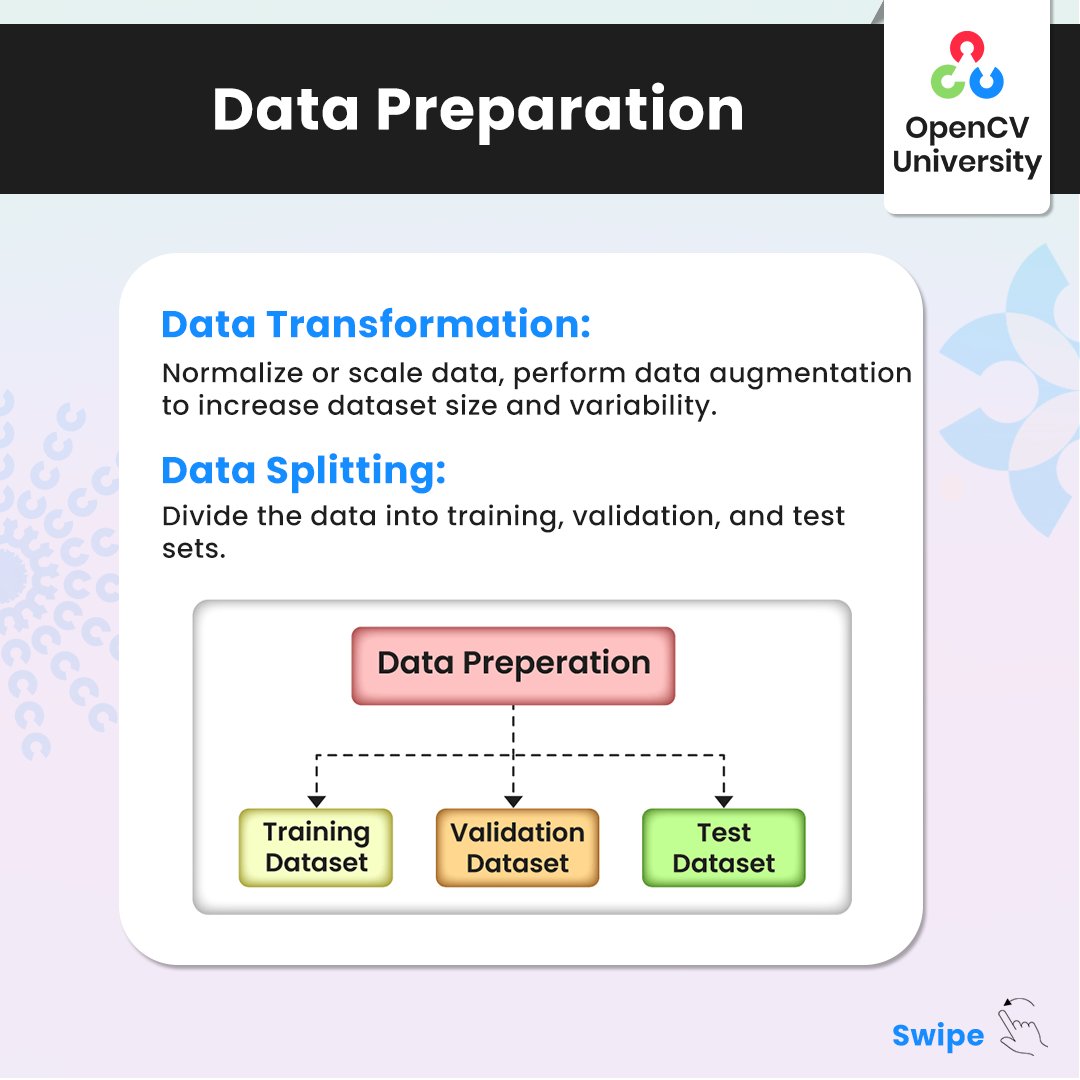
Ultimate Checklist for Training Deep Learning Models
🚀 Master the essentials of training deep learning models with our comprehensive checklist.
Ensure data quality, prepare and visualize data, select the right model architecture, fine-tune training hyperparameters, and successfully evaluate, infer, and deploy your models.
Elevate your deep learning projects with these practical steps!
Signup for our Free Courses here: opencv.org/university/free-c…
#DeepLearning #AI #MachineLearning #DataScience #ModelTraining #DataPreparation #ModelEvaluation #DataVisualization #HyperparameterTuning #ModelDeployment #TechInnovation



2
1
4
212

1 Mar 2024
Having issues with hyperparameter tuning in federated learning? Check our book chapter in this topic :)
#federatedlearning #FL #MachineLearning #hyperparametertuning #HPO
1 Mar 2024

Happy to share the release of the book "Federated Learning: Theory and Practice" that I co-edited with @LamMNguyen3 @nghiaht87, covering fundamentals, emerging topics, and applications. Kudos to the amazing contributors to make this book happen!
@ElsevierNews @sciencedirect


1
6
447