



















ALT 🔹 Optuna Uses Bayesian optimization via TPE (Tree-structured Parzen Estimator). Learns from previous trials to focus on promising areas. 🧠 Think of it as: GridSearch = checking every store RandomSearch = checking random stores Optuna = checking where people said the best deals were and focusing there 🧮 How TPE (Tree-structured Parzen Estimator) Works TPE models the probability distributions of good and bad trials. It keeps two densities: 𝑙(𝑥) distribution of good hyperparams (high scores) 𝑔(𝑥) distribution of bad hyperparams It chooses the next hyperparameter 𝑥 that maximizes: 𝑙(𝑥)/𝑔(𝑥)→ So Optuna focuses search around promising regions. That’s why it’s much faster than random or grid search. so, GridSearchCV “Try everything.” RandomSearchCV “Try random things.” Optuna “Learn where to look.” ✅
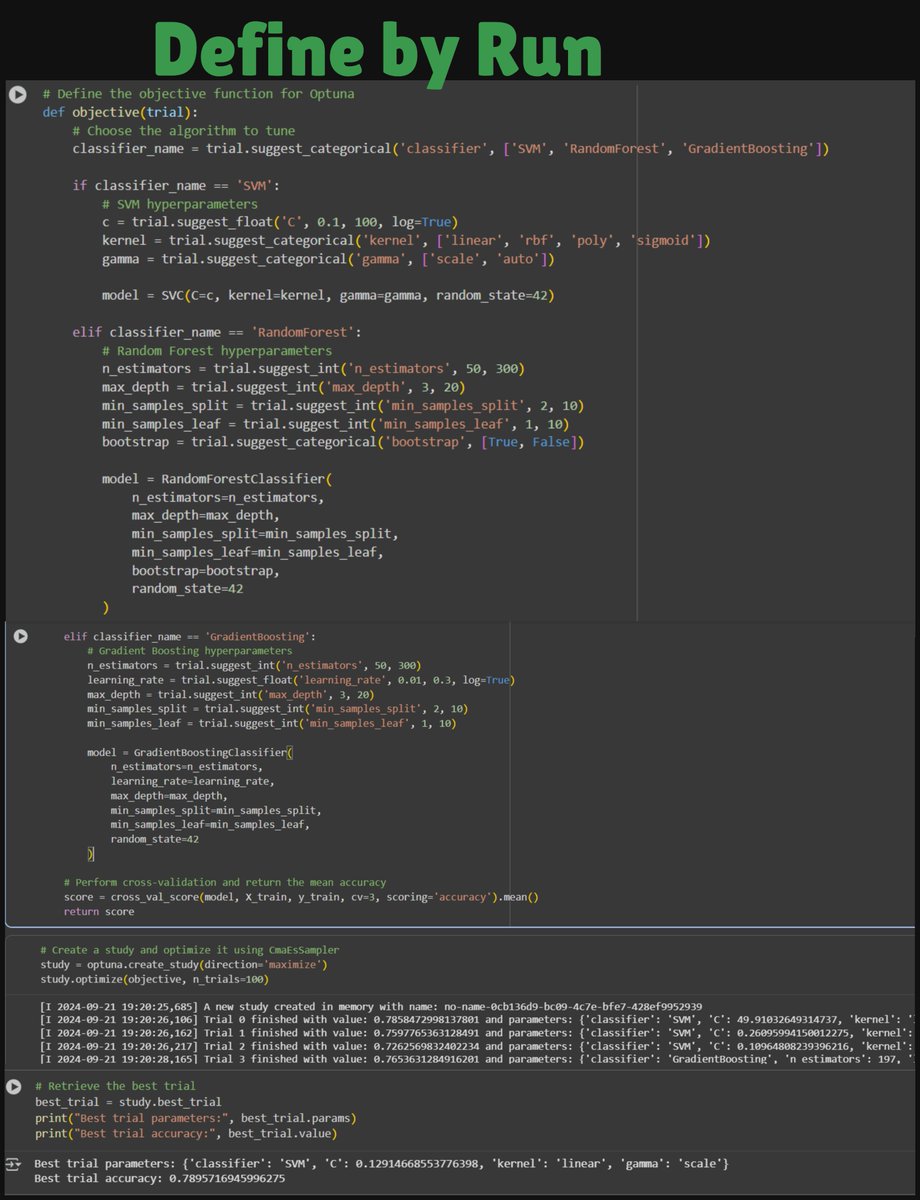
ALT 🧠 Core Idea of Bayesian Optimization Bayesian optimization builds a probabilistic model of your objective function. At each step, it uses that model to decide: “Where should I try next to most likely improve my result?” It’s like an intelligent treasure hunt: Try a few random points. Learn which regions give good results. Use that knowledge to sample more in promising areas. 🧩 TPE (Tree-structured Parzen Estimator) in Optuna Instead of modeling the objective directly, TPE models the probability of parameters given performance: p(x | y) where • x = hyperparameters • y = objective score (e.g., accuracy, loss) 🚀 How It Works: 1. Split trials into good and bad based on performance. 2. Model p(x y) separately for good and bad trials. 3. Suggest new parameters that are more likely to be in the good group. 4. Repeat to keep improving. ✅ Bayesian: it uses previous beliefs (distributions) to inform future sampling decisions.
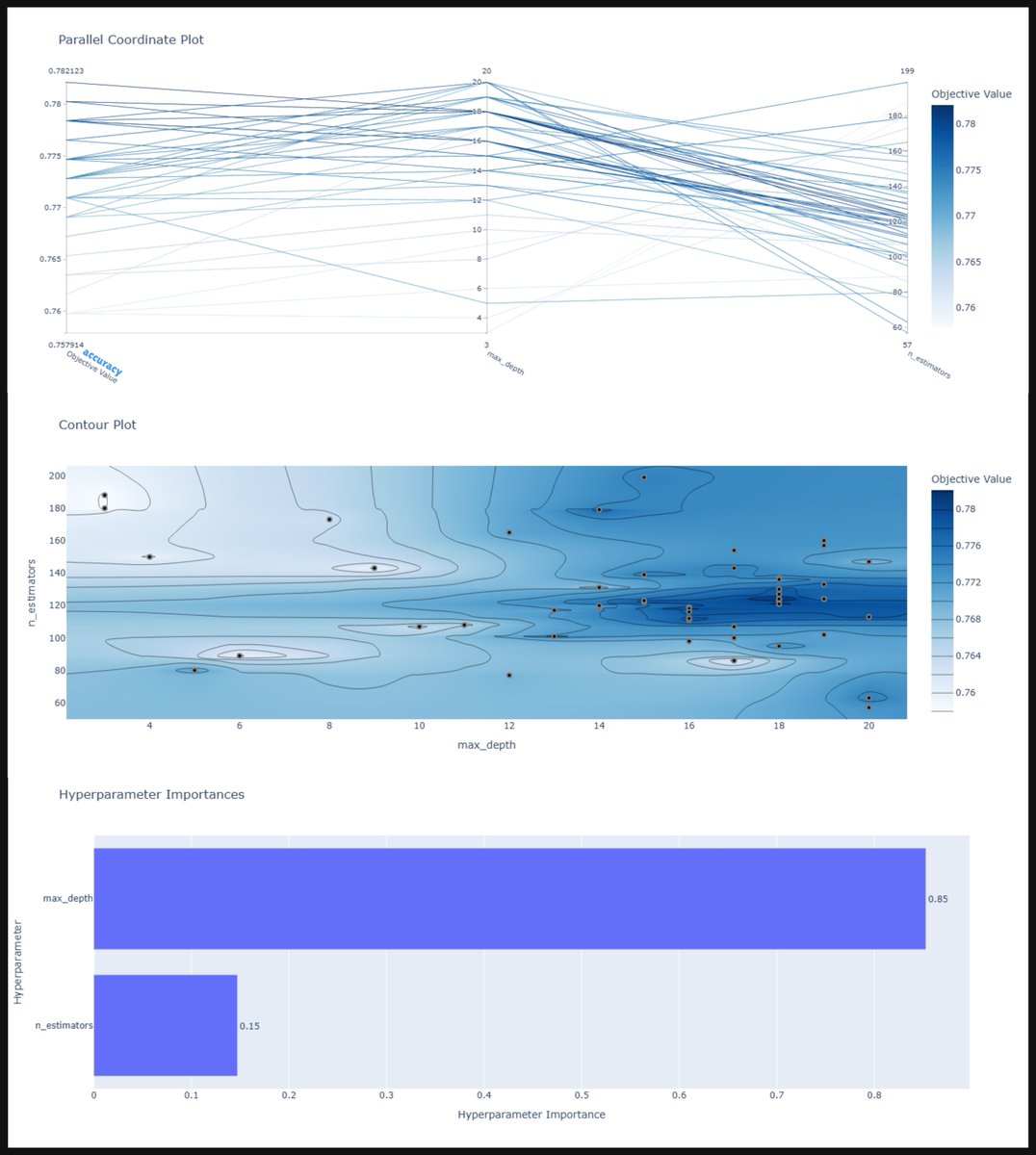
ALT key features of Optuna 🧭 1. Automated Hyperparameter Optimization 🧠 2. Bayesian Optimization (TPE Sampler) ⚙️ 3. Dynamic & Conditional Parameter Spaces ⚡ 4. Pruning — Early Stopping for Bad Trials 📈 5. Visualization Tools (Built-in Analytics) 🧮 6. Samplers (Search Algorithms) 🔄 7. Parallel & Distributed Optimization 🧩 8. Integration with Popular Libraries 🧩 9. Custom Metrics & Objective Functions 🧩 10. Lightweight Yet Powerful API

