
Jun 11
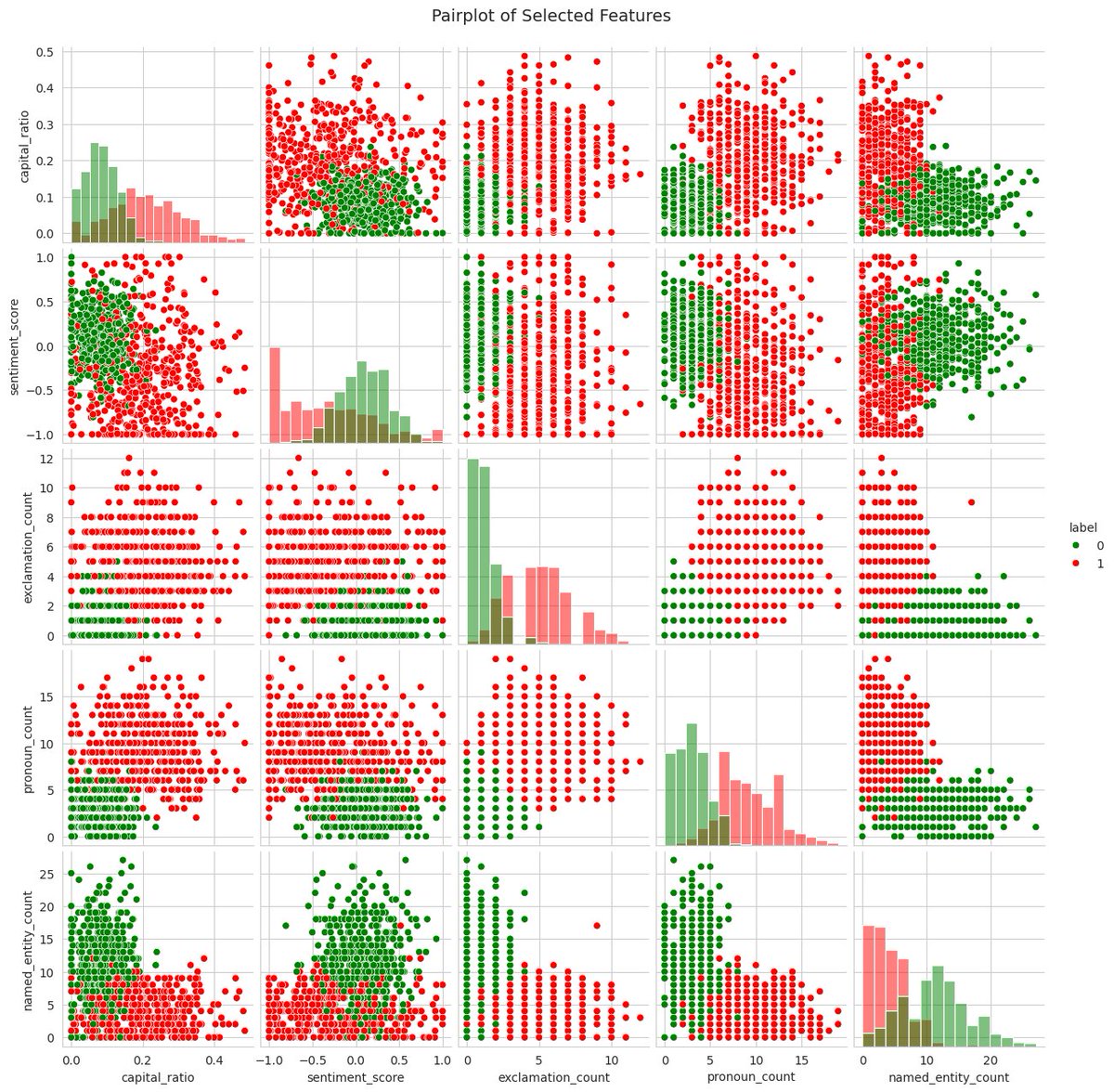
🚀 today's we can Built a Python-based exploratory analysis using a sample Real vs Fake News dataset and feature engineering techniques.
🐍 Python | 📈 EDA | 🤖 ML Prep | 📰 Text Analytics
#DataScience #Python #MachineLearning #NLP #EDA #FeatureEngineering #AI #Kaggle
1
27

Why XGBoost and LightGBM are secretly leaking your data 🤫 (and how CatBoost fixes it)
If you’ve ever worked with high-cardinality features (User IDs, Zip Codes, Agents) in gradient boosting, you’ve faced the classic dilemma:
1️⃣ One-Hot Encoding: Explodes your memory. 2️⃣ Target Encoding: Leaks the future.
We rarely talk about how dangerous option 2 is.
When you replace a category with its mean target value using standard GBDTs, you are often using the label of the row you are currently predicting to calculate that mean.
Even with cross-validation, this leads to massive overfitting on rare categories. If a Zip Code appears once, its "mean" is the answer itself. The model memorizes it.
It’s like letting a student grade their own exam. They get an A , but they didn't learn a thing.
🚀 Enter CatBoost: The "Time Travel" Fix
CatBoost solves this with a brilliant mechanism called Ordered Target Statistics.
It treats your static dataset like a timeline. It artificially permutes (shuffles) the data and, to encode Row X, it only calculates the mean target using rows that appear before X in the permutation.
🔹 The Result:
• Zero Leakage: The model never sees the "future." • Built-in Smoothing: A mathematical prior prevents overfitting on rare categories. • No Prep: You can throw raw strings at it, and it outperforms manual engineering.
💡 But wait, there’s more: The "Auto-Pilot" Feature Engineer
In XGBoost, trees are greedy. They split on Feature A, then Feature B. But what if the signal is A B? (e.g., "Blue" is noise, "Small" is noise, but "Small Blue Widget" is a bestseller).
Usually, you have to manually engineer these interactions.
CatBoost does this automatically. Because it handles categories so efficiently, it aggressively combines them during tree construction. It merges features on the fly (e.g., Color_Region) and calculates stats for these new combos immediately.
TL;DR
❌ XGBoost / LightGBM: "Manually encode categories and pray you don't leak data." ✅ CatBoost: "Ordered stats Auto-combinations."
Sometimes the best feature engineering is the code you don't have to write.
#MachineLearning #DataScience #CatBoost #XGBoost #FeatureEngineering #AI
Check out my book:
👉 valeman.gumroad.com/l/Master…

1
6
792

Revised Feature Engineering today ⚙️📊
Covered handling missing values, dealing with imbalanced datasets, and encoding categorical features for ML models🤖
Strengthening the data preprocessing skills that power better predictions🚀
@krishnaik06
#ML #DS #FeatureEngineering #Python

2
61

Jun 5
🚀 Feature Engineering can make or break an ML model.
Good features improve accuracy and help models learn better patterns.
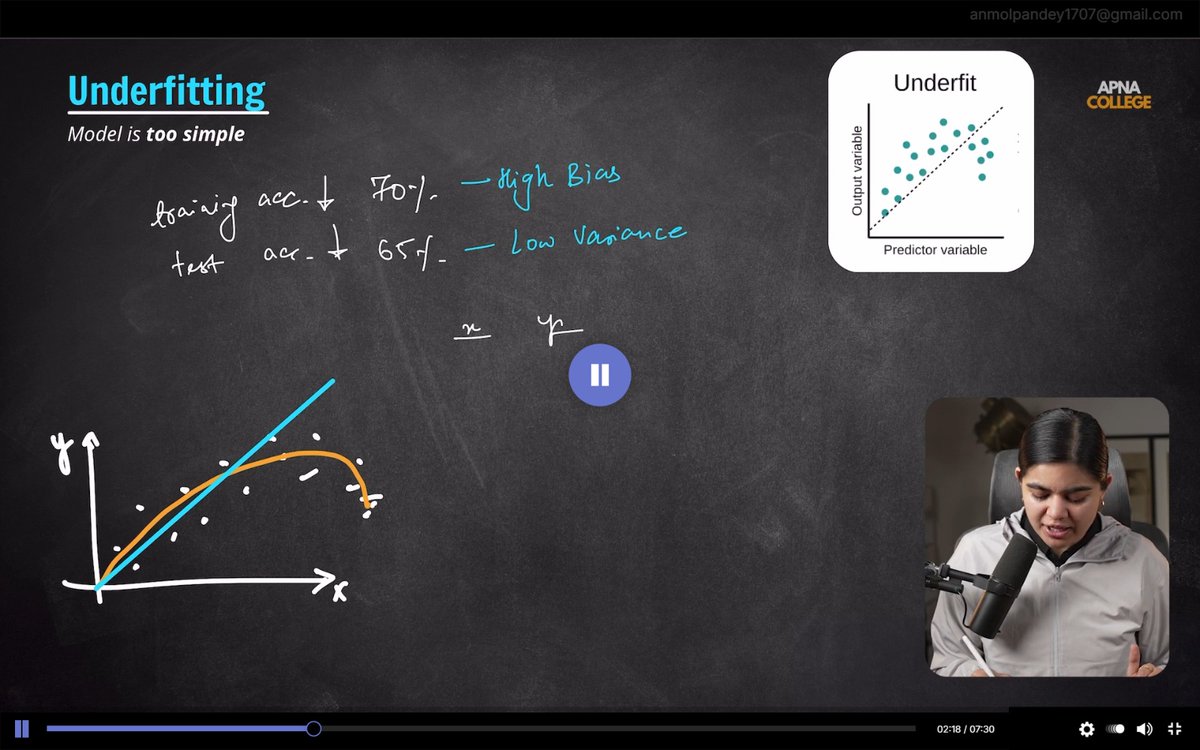
⚠️ Underfitting: Model is too simple.
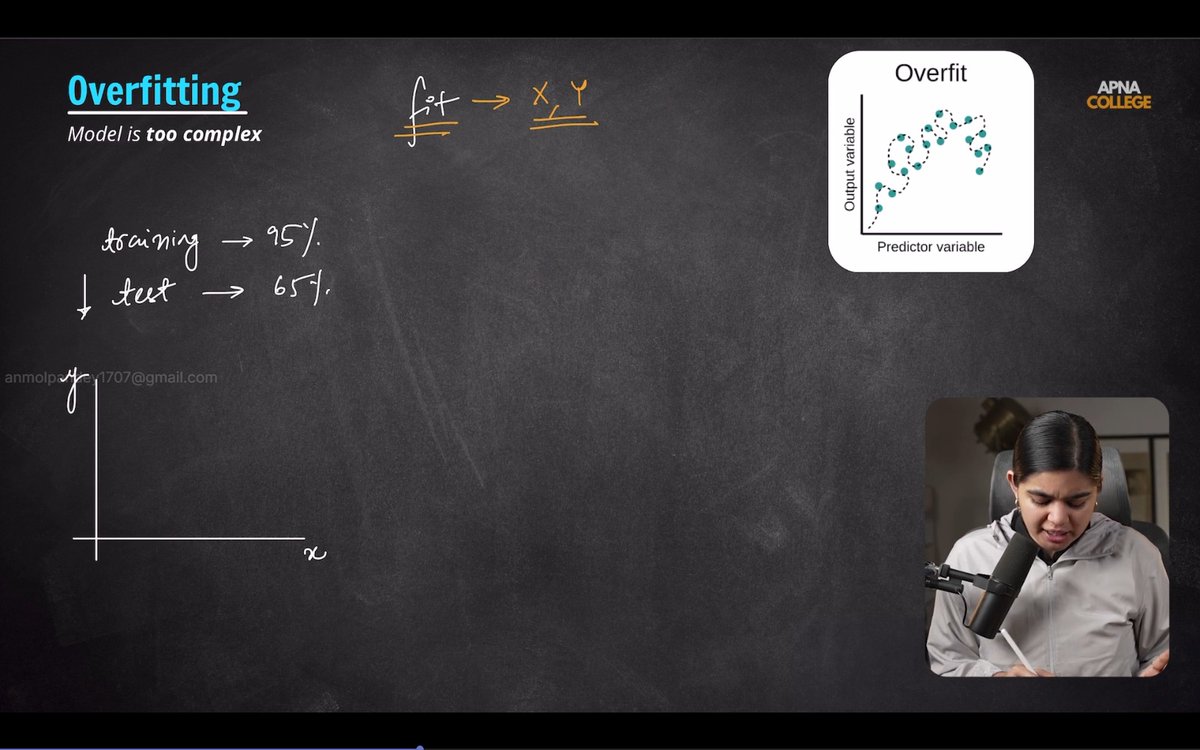
⚠️ Overfitting: Model memorizes training data.
#MachineLearning #AI #DataScience #FeatureEngineering #ML
Day 43
1
3
31

100 Days of ML | Day 23 🚀
Explored Feature Engineering today. ⚙️
Transforming raw data into meaningful features that help models learn better.
• Creating new features
• Encoding categories
• Scaling values
• Extracting useful patterns
#FeatureEngineering
2
21

May 13
Feature Engineering
This is the SECRET skill that separates
good Data Scientists from great ones.
Link: drive.google.com/file/d/1VVy…
#FeatureEngineering #DataScience #Python

1
2
81

The algorithm will follow.
Our Data Science & Business Analytics Cohort 2 is enrolling now.
DM us to get full details. 🚀📩
#StackronAcademy #MachineLearning #MLOps #DataScience #AI #ModelEvaluation #FeatureEngineering #DataQuality #MLPractitioner #BuildBetterModels
1
2
20
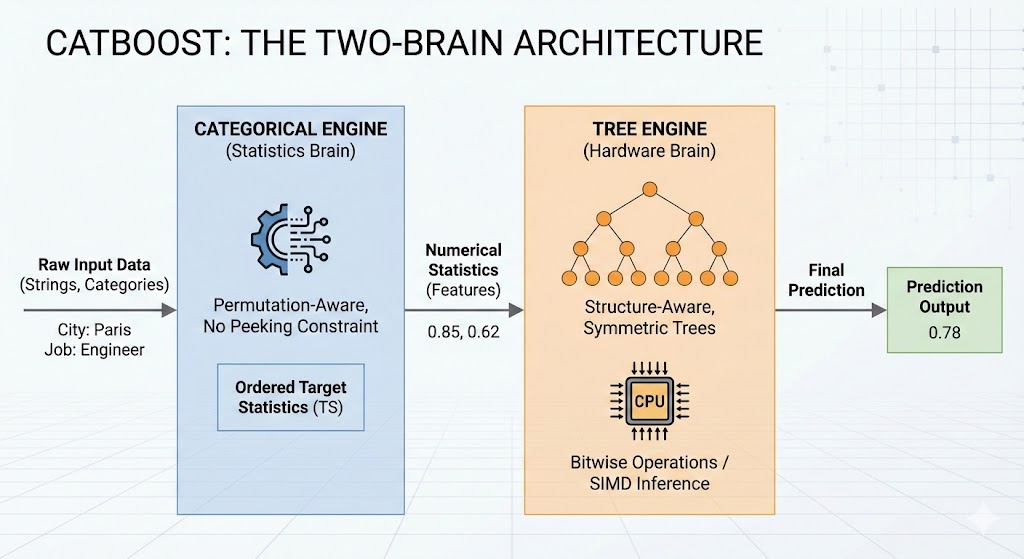
Stop treating your model like a black box.
The biggest mistake Data Scientists make with CatBoost is treating it like "just another GBDT."
To master it, you need the Two-Brain Mental Model:
🧠 Brain 1 (The Statistician): The Categorical Engine. It uses permutations and "No Peeking" rules to turn categories into numbers without leakage.
🧠 Brain 2 (The Engineer): The Tree Engine. It takes those numbers and builds hardware-optimized symmetric trees for insane inference speed.
If you are manually One-Hot Encoding your data before feeding it to CatBoost, you are literally lobotomizing Brain #1. Stop it.
I break down the full architecture—from quantization to bitwise scoring—in Chapter 3 of Mastering CatBoost.
Join the readers mastering the state of the art: 👉 valeman.gumroad.com/l/Master… 👉 valeman.gumroad.com/l/Master…
#DataEngineering #AI #FeatureEngineering #Python #CatBoost
4
7
869

Apr 22
It's very possible that the more features you engineered into your model, the worse it becomes.
Go back to the baseline features again and approach your modeling from another angle.
#DataScience #DataAnalytics #MachineLearning #FeatureEngineering

2
25

Apr 19
🚀 Feature engineering isn’t just data prep—it’s the art of turning raw data into signals that make models smarter.
🔑 Great features = better accuracy, faster training, and deeper insights.
Think:
• Encoding categorical variables
• Creating interaction terms
• Extracting time-based patterns
• Scaling & normalizing for stability
In ML, features are the bridge between messy reality and predictive power. Build them wisely, and your model will thank you.
#MachineLearning #DataScience #FeatureEngineering
1
3
58
Why XGBoost and LightGBM are secretly leaking your data 🤫 (and how CatBoost fixes it)
If you’ve ever worked with high-cardinality features (User IDs, Zip Codes, Agents) in gradient boosting, you’ve faced the classic dilemma:
1️⃣ One-Hot Encoding: Explodes your memory. 2️⃣ Target Encoding: Leaks the future.
We rarely talk about how dangerous option 2 is.
When you replace a category with its mean target value using standard GBDTs, you are often using the label of the row you are currently predicting to calculate that mean.
Even with cross-validation, this leads to massive overfitting on rare categories. If a Zip Code appears once, its "mean" is the answer itself. The model memorizes it.
It’s like letting a student grade their own exam. They get an A , but they didn't learn a thing.
🚀 Enter CatBoost: The "Time Travel" Fix
CatBoost solves this with a brilliant mechanism called Ordered Target Statistics.
It treats your static dataset like a timeline. It artificially permutes (shuffles) the data and, to encode Row X, it only calculates the mean target using rows that appear before X in the permutation.
🔹 The Result:
• Zero Leakage: The model never sees the "future." • Built-in Smoothing: A mathematical prior prevents overfitting on rare categories. • No Prep: You can throw raw strings at it, and it outperforms manual engineering.
💡 But wait, there’s more: The "Auto-Pilot" Feature Engineer
In XGBoost, trees are greedy. They split on Feature A, then Feature B. But what if the signal is A B? (e.g., "Blue" is noise, "Small" is noise, but "Small Blue Widget" is a bestseller).
Usually, you have to manually engineer these interactions.
CatBoost does this automatically. Because it handles categories so efficiently, it aggressively combines them during tree construction. It merges features on the fly (e.g., Color_Region) and calculates stats for these new combos immediately.
TL;DR
❌ XGBoost / LightGBM: "Manually encode categories and pray you don't leak data." ✅ CatBoost: "Ordered stats Auto-combinations."
Sometimes the best feature engineering is the code you don't have to write.
#MachineLearning #DataScience #CatBoost #XGBoost #FeatureEngineering #AI
Check out my book:
👉 valeman.gumroad.com/l/Master…

2
15
1,387
Stop using TF-IDF for your gradient boosting models 🛑
We’ve all been there. You have a beautiful tabular dataset with 50 numerical columns and... one text column (e.g., "Customer Review" or "Ticket Description").
To use XGBoost or LightGBM, you have to leave the gradient boosting world and enter the NLP "preprocessing hell":
1. Import NLTK or SpaCy.
2. Clean, stem, and lemmatize.
3. Run TF-IDF or CountVectorization.
4. Generate a 10,000-column sparse matrix that eats all your RAM.
5. Run PCA to survive the memory crash.
It’s a massive engineering headache just to use one column of data.
🚀 Enter CatBoost’s Native Text Support
CatBoost allows you to bypass this entire pipeline. You don't need to convert text to numbers yourself. You just tell the model:
text_features=['Customer_Review']
That’s it. You feed it raw strings.
How does a decision tree read text? 📖
Under the hood, CatBoost performs a sophisticated automated pipeline during training:
1. Tokenization: It splits your text into words and n-grams (sequences of words).
2. Dictionary Creation: It builds an internal vocabulary on the fly.
3. Target Statistics (The Secret Weapon): Instead of just counting words (like Bag-of-Words), CatBoost calculates how predictive each word is. (e.g., It learns that the word "Refund" is associated with a 90% probability of Churn.)
4. Feature Generation: It creates new numerical features (Naive Bayes, BM25) based on these statistics and feeds them into the trees.
The Result:
• No Sparse Matrices: You don't explode your feature space to 10k columns.
• End-to-End Learning: The text processing is part of the model graph. You can save the model and deploy it without needing a separate Python preprocessing script.
• Better Accuracy: Because it uses Target Encoding on text (not just counts), it often extracts signal that standard TF-IDF misses.
TL;DR
❌ XGBoost / LightGBM: "Please convert text to numbers before entering." (Requires complex external pipelines).
✅ CatBoost: "I speak human. Give me the raw text." (Handles tokenization and encoding internally).
Stop engineering features. Start engineering architectures.
#MachineLearning #NLP #CatBoost #DataScience #FeatureEngineering #AI
check my book at the end valeman.gumroad.com/l/Master…

2
8
1,347
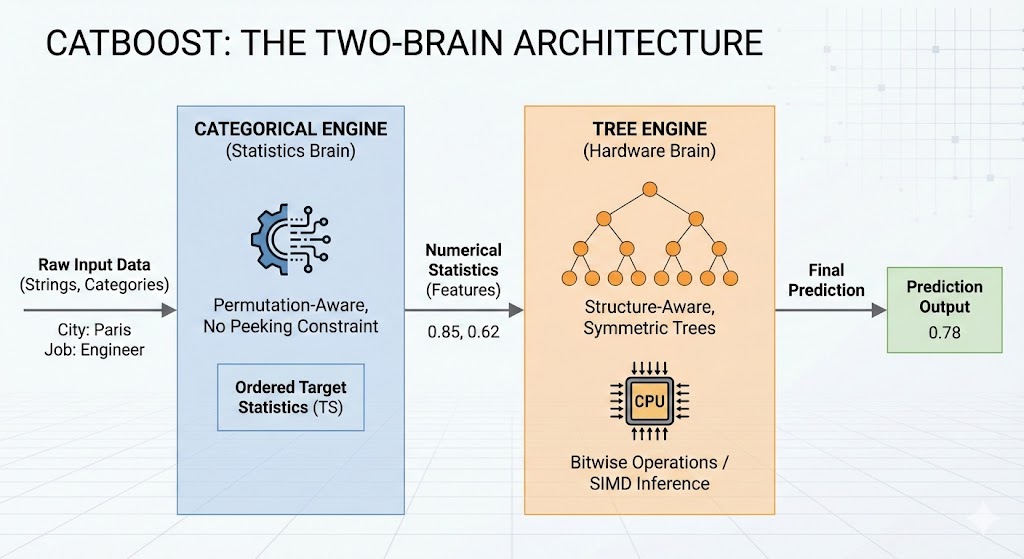
Stop treating your model like a black box.
The biggest mistake Data Scientists make with CatBoost is treating it like "just another GBDT."
To master it, you need the Two-Brain Mental Model:
🧠 Brain 1 (The Statistician): The Categorical Engine. It uses permutations and "No Peeking" rules to turn categories into numbers without leakage.
🧠 Brain 2 (The Engineer): The Tree Engine. It takes those numbers and builds hardware-optimized symmetric trees for insane inference speed.
If you are manually One-Hot Encoding your data before feeding it to CatBoost, you are literally lobotomizing Brain #1. Stop it.
I break down the full architecture—from quantization to bitwise scoring—in Chapter 3 of Mastering CatBoost.
Join the readers mastering the state of the art: 👉 valeman.gumroad.com/l/Master… 👉 valeman.gumroad.com/l/Master…
#DataEngineering #AI #FeatureEngineering #Python #CatBoost
1
9
1,505

Day 1: Started my Spotify recommendation system 🎧
Did EDA feature engineering on track data — cleaned it, explored audio features, and prepped it for modeling.
Laying the foundation before the ML 🚀
#DataScience #MachineLearning #EDA #FeatureEngineering #Python #Spotify

2
11

Mar 24
Are you building features, or just accumulating debt? 🏗️🏾
Most AI coding tools treat your codebase like a flat text file. They miss the context, they hallucinate, and they ship "slop" that breaks your architecture under pressure.
In the latest edition of the FastBuilder.AI Newsletter, we’re unboxing the future of Fast Feature Engineering.
What’s inside: 🚀 Velocity without Drift: How to ship 100X faster without sacrificing architectural integrity. 🧠 3D Architecture Memory: Why "context windows" aren't enough—you need a digital twin of your software's topology. 📺 GMC in Action: A full demo build showing spec-to-ship feature engineering with 100% compliance. 💎 Stop the Slop: Formal mathematical verification for every line of code generated.
Don't settle for "Yes-Man" AI that flatters you while it breaks your system. Get the blueprint for the next era of engineering.
Read the full newsletter here: [Newsletter Link] (Link to newsletter-engineering.md / local server)
Stop the slop. Build with control. 🚀
#SoftwareEngineering #AI #DeveloperEfficiency #CleanCode #FastBuilderAI #FeatureEngineering #Newsletter

2
2
30
Mar 23
Most AI coding tools guess where to put your code.
We built a system that knows.
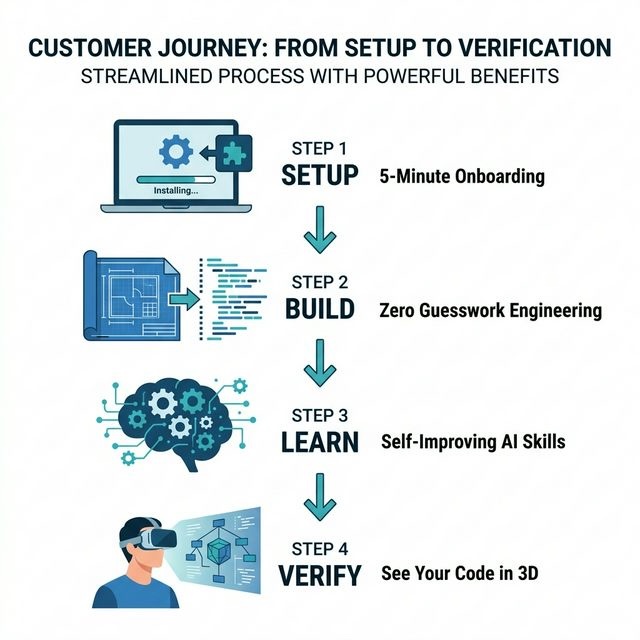
Today we're sharing our full Feature Engineering Tutorial for FastBuilder.AI — a step-by-step guide to shipping production features with 100% architectural accuracy using any IDE.
Here's the workflow:
1️⃣ Setup (5 minutes) Sign up → Create your project → Download the UpperSpace Desktop App and IDE plugin. That's it. You're connected to a deterministic architectural map of your codebase.
2️⃣ Build (Zero Guesswork) Write your feature spec in specs.md. Generate your Golden Mesh topology (CGMC FGMC). Click "Start Development." The agent doesn't guess which files to touch — it navigates a mathematical blueprint.
3️⃣ Learn (Self-Improving Skills) FastBuilder.AI auto-generates reusable engineering skills as it builds. You can also download your project's Skills Gap Report and generate custom skills with any AI agent — Claude, GPT, or your own.
4️⃣ Verify (See Your Code in 3D) Don't just trust terminal logs. Load your architecture into the UpperSpace 5D VR Explorer (Meta Quest / Apple Vision Pro) and walk through your system's structural integrity before merging.
This isn't "vibe coding." This is Spatial Engineering.
🔗 Get started: lnkd.in/ePbJpTtS
📖 Full tutorial: lnkd.in/eu5Rq3um
What's the most time you've wasted because an AI agent edited the wrong file? 👇
#SoftwareEngineering #AIEngineering #FastBuilderAI #DeveloperTools #FeatureEngineering #SpatialEngineering #VRDevelopment #DevTools
2
2
53

Stop obsessing over which algorithm to use. The "Model Bros" will spend 6 hours tuning hyperparameters just to gain a 0.01% increase in accuracy.
The Pro-tier move? Spend 20 minutes creating one high-impact feature that actually explains the data.
In Part 3 of our series, we’re talking Feature Alchemy. Your model is only as good as the variables you feed it. If you give the AI "Timestamp," it sees a number. If you give it "Hours until Deadline," you give it context. That is the difference between a mid-tier project and a billion-dollar insight.
Inside this slide deck:
- Why the model isn’t the magic—the data is.
- How to turn raw columns into "Predictive Gold."
- The mindset shift from "Coding" to "Engineering."
THE WAIT IS OVER: The Welm Beta is officially LIVE. Don’t just learn tech-master it in a way that’s personalized to your goals. We’ve built the GPS, you just need to start driving.
Click the link in our bio to join the Beta and start outperforming the room.
#StayWelmed #MachineLearning #FeatureEngineering #DataScience #DataEngineering #AI #TechCareer #WelmBeta #PersonalizedLearning #EngineerMindset




1
2
23

#Day26 of learning Machine Learning:
⭐ Intro To Natural Language Processing
⭐ Tokenization And Its Implementation
⭐ Stemming And Lemmatization And Its Implementation
#ML #FeatureEngineering #LearningInPublic #MachineLearning
2
35
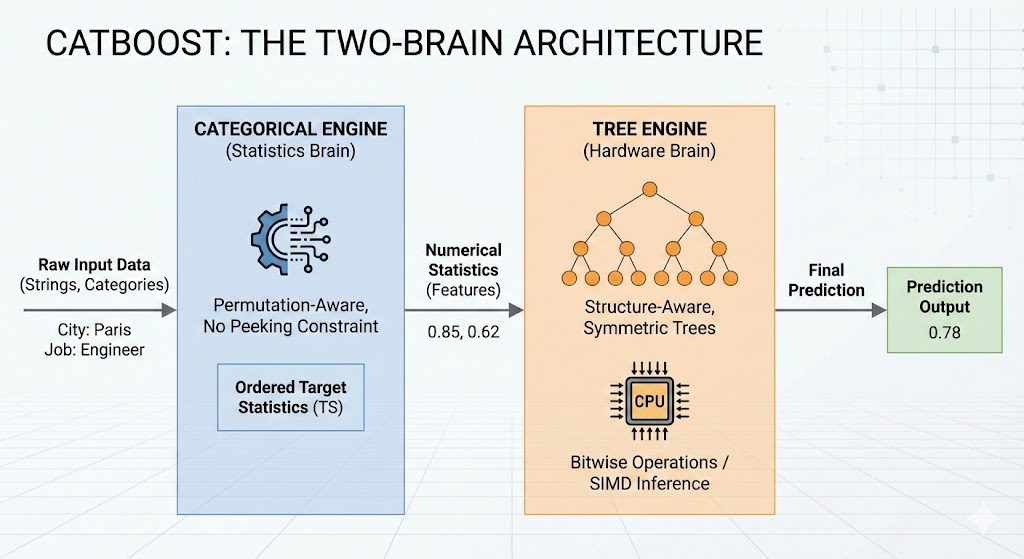
Stop treating your model like a black box.
The biggest mistake Data Scientists make with CatBoost is treating it like "just another GBDT."
To master it, you need the Two-Brain Mental Model:
🧠 Brain 1 (The Statistician): The Categorical Engine. It uses permutations and "No Peeking" rules to turn categories into numbers without leakage.
🧠 Brain 2 (The Engineer): The Tree Engine. It takes those numbers and builds hardware-optimized symmetric trees for insane inference speed.
If you are manually One-Hot Encoding your data before feeding it to CatBoost, you are literally lobotomizing Brain #1. Stop it.
I break down the full architecture—from quantization to bitwise scoring—in Chapter 3 of Mastering CatBoost.
Join the readers mastering the state of the art: 👉 valeman.gumroad.com/l/Master… 👉 valeman.gumroad.com/l/Master…
#DataEngineering #AI #FeatureEngineering #Python #CatBoost
1
6
40
2,792

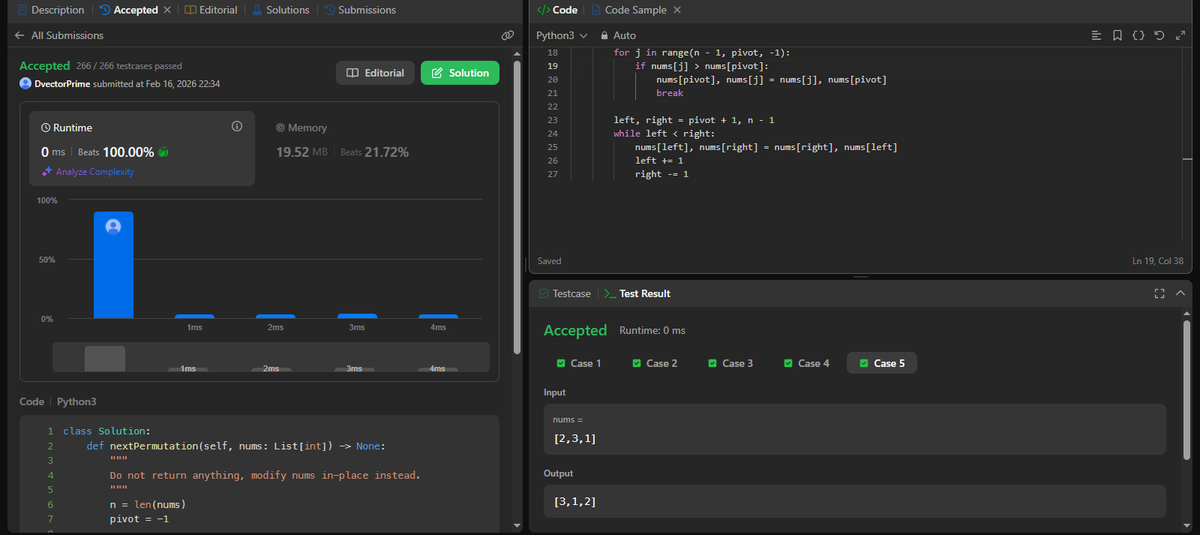
DSA:• LeetCode 31 (Next Permutation). Pattern recognition is improving. 🧩
Better Data > Better Math.
#90DaysOfCode #Python #MachineLearning #FeatureEngineering #DataScience
1
8
82