

May 12
7/🧵 RelAgent points to an alternative direction for relational learning:
Use LLMs not to replace relational models, but to help construct them.
Paper Link: arxiv.org/abs/2605.07840v1
Github: github.com/HxyScotthuang/Rel…
Built with @CamelAIOrg @duckdb @RelBench
3
8
606

If you're at ICLR, come check out our poster for RelBench v2 (arxiv.org/abs/2602.12606) at the DATA-FM (Data for Foundation Models) Workshop! Apr 26, Hall 203 A/B 🇧🇷

Although relational databases are everywhere, there is no equivalent of the public internet for pretraining Relational Foundation Models (RFMs). Excited to see RelBench bridging that gap, growing from 7 datasets in v1 to 88 datasets in v2.
Deeply grateful to the numerous community contributions for helping RelBench serve as the central data repository for RFM research. ❤️
2
244

Feb 3
Integrando Meta-Learning y Automatización para potenciar el rendimiento académico en el S XXI (RelBench en Educación disruptiva & IA) juandomingofarnos.wordpress.… vía @juandoming
2
62
Although relational databases are everywhere, there is no equivalent of the public internet for pretraining Relational Foundation Models (RFMs). Excited to see RelBench bridging that gap, growing from 7 datasets in v1 to 88 datasets in v2.
Deeply grateful to the numerous community contributions for helping RelBench serve as the central data repository for RFM research. ❤️
Jan 12

🚀 Announcing RelBench V2, a major update to our benchmark for foundation models on relational data!
With V2, we are significantly expanding the benchmark’s scope to catalyze further research in Relational Deep Learning (RDL) and Relational Foundation Models (RFMs).
Key features:
🍺 4 new databases, spanning domains like e-commerce and beer reviews to scientific research and clinical healthcare.
🧩 40 new predictive tasks, including 28 autocomplete tasks, across new and existing databases.
🔌 External data integrations: 70 datasets from CTU, 7 datasets from 4DBInfer, and your own data via SQL connector, all in RelBench format.
🛠️ Bug fixes and performance improvements.
🔥 Introducing autocomplete tasks: As opposed to forecasting tasks, autocomplete tasks predict existing columns in the database. We found that models need to deeply understand the relational context to autocomplete database fields, a critical capability that expands the scope of real-world RDL applications.
Learn more:
🌐 Website: relbench.stanford.edu
💻 GitHub: github.com/snap-stanford/rel…
Huge thanks to @justingu32 @_rishabhranjan_ @jakub_peleska @VHudovernik @CKanatsoulis @fengyuli607, Tang Haiming, Alistiq and everyone else who contributed to our GitHub for making this possible!

3
9
730

Jan 12
🚀 Announcing RelBench V2, a major update to our benchmark for foundation models on relational data!
With V2, we are significantly expanding the benchmark’s scope to catalyze further research in Relational Deep Learning (RDL) and Relational Foundation Models (RFMs).
Key features:
🍺 4 new databases, spanning domains like e-commerce and beer reviews to scientific research and clinical healthcare.
🧩 40 new predictive tasks, including 28 autocomplete tasks, across new and existing databases.
🔌 External data integrations: 70 datasets from CTU, 7 datasets from 4DBInfer, and your own data via SQL connector, all in RelBench format.
🛠️ Bug fixes and performance improvements.
🔥 Introducing autocomplete tasks: As opposed to forecasting tasks, autocomplete tasks predict existing columns in the database. We found that models need to deeply understand the relational context to autocomplete database fields, a critical capability that expands the scope of real-world RDL applications.
Learn more:
🌐 Website: relbench.stanford.edu
💻 GitHub: github.com/snap-stanford/rel…
Huge thanks to @justingu32 @_rishabhranjan_ @jakub_peleska @VHudovernik @CKanatsoulis @fengyuli607, Tang Haiming, Alistiq and everyone else who contributed to our GitHub for making this possible!
24
41
4,929

2 May 2025
P1 Remedies: The community is overlooking many significant and transformative applications, including chip design and broader ML for systems, combinatorial optimization, and relational data (as highlighted by RelBench). Each of them offers $billions in potential outcomes.
3/10
1
19
2,409

19 Oct 2024
I understand the point of that to be that no data pre-processing can be done to be called RDL. More automated learning, less data engineering. I like that.
But the RelBench tasks are still transductive though.
I am partial to inductive tasks: Can machines learn general rules?
1
2
128
28 Sep 2024
((NUEVA INVESTIGACIÓN)) @juandoming Integrando Meta-Learning y Automatización para potenciar el rendimiento académico en el S XXI (RelBench en Educación disruptiva & IA) – sco.lt/70s9Hk #RelBench #IA #AGI #Educaciondisruptiva #universidad #edtech #algoritmos
2
108
27 Sep 2024
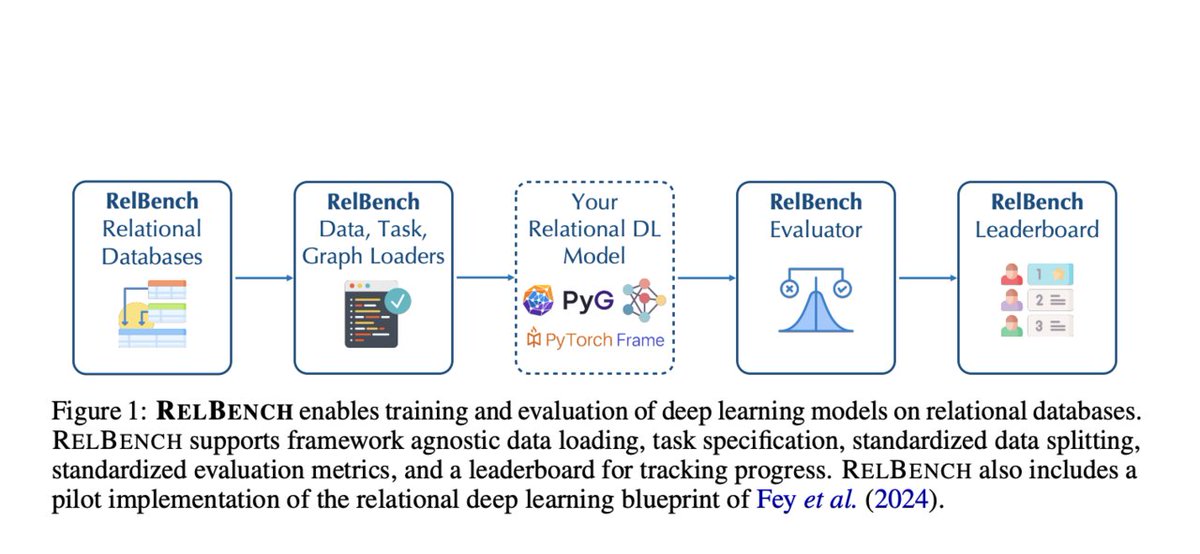
Excited to share that RelBench: Relational Deep Learning Benchmark paper was accepted to NeurIPS. Summarizing the study in one picture 📷
relbench.stanford.edu

2
20
117
9,922



1 Aug 2024
Researchers at Stanford Present RelBench: An Open Benchmark for Deep Learning on Relational Databases #DL #AI #ML #DeepLearning #ArtificialIntelligence #MachineLearning #ComputerVision #AutonomousVehicles #NeuroMorphic #Robotics buff.ly/46qIGLr
1
182

31 Jul 2024
Researchers at Stanford Present RelBench: An Open Benchmark for Deep Learning on Relational Databases
Researchers from Stanford University, Kumo.AI, and the Max Planck Institute for Informatics introduced RelBench, a groundbreaking benchmark to facilitate deep learning on relational databases. This initiative aims to standardize the evaluation of deep learning models across diverse domains and scales. RelBench provides a comprehensive infrastructure for developing and testing relational deep learning (RDL) methods, enabling researchers to compare their models against consistent benchmarks.
RelBench leverages a novel approach by converting relational databases into graph representations, enabling the use of Graph Neural Networks (GNNs) for predictive tasks. This conversion involves creating a heterogeneous temporal graph where nodes represent entities and edges denote relationships. Initial node features are extracted using deep tabular models designed to handle diverse column types such as numerical, categorical, and text data. The GNN then iteratively updates these node embeddings based on their neighbors, facilitating the extraction of complex relational patterns.
Read our full take on RelBench: marktechpost.com/2024/07/30/…
Paper: arxiv.org/abs/2407.20060
GitHub: github.com/snap-stanford/rel…
Project: relbench.stanford.edu/
@RelBench @Josh_d_robinson
@_rishabhranjan_
@weihua916
@KexinHuang5
@jiaqihan99
@adobles96
@rusty1s
@janericlenssen
@yiwenyuan98
@zechengzh
@xhe1997
@jure

7
23
2,730

31 Jul 2024
Researchers at Stanford Present RelBench: An Open Benchmark for Deep Learning on Relational Databases
itinai.com/researchers-at-st…
#DeepLearning #RelationalDatabases #RelBench #AIImplementation #CustomerEngagement #ai #news #llm #ml #research #ainews #innovation #artificialintelli…
2
38
30 Jul 2024
🚀 Announcing RelBench: an open benchmark for deep learning on relational databases! RelBench is the foundational infrastructure for research in Relational Deep Learning (RDL), which brings modern AI to structured data.
RelBench has databases, tasks, loaders, evaluators, and leaderboards to catalyze research in the field!
Key features:
🌍 7 datasets spanning diverse domains: e-commerce, social, medical, and sports.
🧩 30 carefully curated predictive tasks: including entity classification/regression and recommendation.
📊 Wide data size range: ranging from 74K to 41M rows, 15 to 140 columns, 3 to 15 tables.
⏳ Wide time spans: from 2 weeks to 55 years of training data.
🏅 Comprehensive benchmarks: SOTA tabular learning and GNN baselines for every task.
🔥We hired a data scientist with 5 years of industry experience to solve RelBench tasks using traditional machine learning (feature engineering, model training). The RDL outperforms the data scientist in accuracy while reducing the time/code by 20x (12.3 hors -> 0.5 hours) !!! 🤯
Learn more:
🌐 Website: relbench.stanford.edu
📄 Paper: arxiv.org/abs/2407.20060
💻GitHub: github.com/snap-stanford/rel…
Follow @RelBench for the latest updates
Shoutout to the amazing team: @Josh_d_robinson @_rishabhranjan_ @weihua916 @KexinHuang5 @jiaqihan99 @adobles96 @rusty1s @janericlenssen @yiwenyuan98 @zechengzh @xhe1997 @Kumo_ai_team @PyG_Team @StanfordAILab

4
56
205
21,950
25 Jul 2024
We are presenting our position paper on end-to-end deep learning for relational databases! Collaboration between @StanfordAILab and @Kumo_ai_team.
RDL learns directly on structured data across multiple tables, eliminates the need for feature engineering, and extends AI use cases to personalization, fraud, forecasting and others:
🕸️ Deep representation learning on across multiple tables, eliminating the need for single-table feature engineering
⚖️Launching RelBench, a new benchmark and testing suite to facilitate research
I'm excited to see the broader applications and diverse AI use cases this paradigm will unlock.
icml.cc/virtual/2024/poster/…

28
128
14,464
30 Nov 2023
Meet Relational Deep Learning Benchmark (RelBench): A Collection of Realistic, Large-Scale, and Diverse Benchmark Datasets for Machine Learning on Relational Databases
Quick read: marktechpost.com/2023/11/30/…
Paper: relbench.stanford.edu/paper.…
Project: relbench.stanford.edu/
Github: github.com/snap-stanford/rel…
#relationaldatabase #database #ArtificialInteligence #deeplearning #100DaysOfCode #GitHub #machinelearning #vectordatabase @RelBench @Stanford
1
10
288

30 Nov 2023
A new research area that generalizes graph machine learning and broadens its applicability to a wide set of #AI use cases.
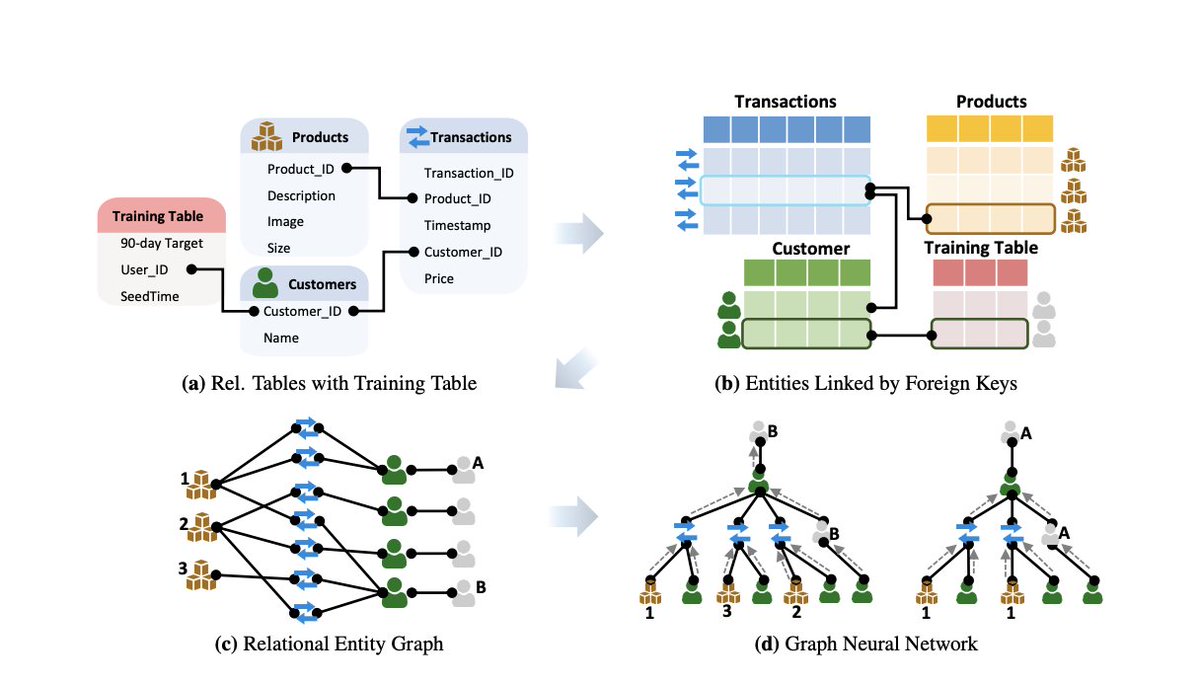
Much of the world’s most valued data is stored in data warehouses, where the data is spread across many tables connected by primary-foreign key relations.
However, building #machinelearning models using this data is both challenging and time consuming. The core problem is that no machine learning method is capable of learning directly on the data spread across multiple relational tables. Current methods can only learn from a single table, so the data must first be joined and aggregated into a single training table, a process known as feature engineering.
Jure Leskovac et.al. introduce an end-to-end #deeplearning approach to directly learn on data spread across multiple tables called Relational Deep Learning
The core idea is to view relational tables as a heterogeneous graph, with a node for each row in each table, and edges specified by primary-foreign key relations.
Message Passing Neural Networks can then automatically learn across multiple tables to extract representations that leverage all input data, without any manual feature engineering. To facilitate research, they have also developed RELBENCH, a set of benchmark datasets and an implementation of Relational Deep Learning.
lnkd.in/dWwWEYq9

1
6
399

