
Jun 13
🏁 Closing Perspective: Engineering Reliable Intelligence for the Physical World — the powerful 100th and final paper in this landmark technical series from @aasaitech.
Just read this excellent capstone white paper that synthesizes everything into a rigorous framework for building safe, reliable, useful, and maintainable LLM/agentic systems in high-stakes industrial and edge environments.
Key highlights: • Core challenge: Reliable intelligence amid uncertainty, high stakes, complex integration, and evolving systems • Engineering response: Systems thinking verification human oversight domain expertise robust operations • Success dimensions: Empowered people, safe & resilient operations, sustainable progress, organizational advantage • Human AI partnership: AI for speed/scale/insight; Humans for judgment/values/wisdom
This is the perfect culmination — turning all prior papers into actionable, responsible engineering for manufacturing and edge orchestration.
Full white paper infographic: x.com/aasaitech/status/20656…
Huge thanks to DIVINE FORCE who helped me keep going for this comprehensive 100-paper journey. It is a masterclass in production-grade industrial AI.
It’s my biggest takeaway for building reliable physical-world intelligence?
#ReliableAI #IndustrialAI #AgenticAI #HumanCenteredAI #ManufacturingAI #EdgeAI #ResponsibleAI

12
Jun 13
🛡️ Layered Verification for Production-Grade Agentic Systems — the critical reliability & safety backbone that turns powerful but uncertain LLM outputs into confident, auditable, and safe real-world actions.
Just read this excellent capstone technical white paper from @aasaitech on multi-layer verification (self-critique & reflection, external validators, tool-based checking, rule/policy guardrails, formal methods/constraint solvers, and continuous feedback).
Key highlights: • 8-step verification pipeline with continuous learning loops • Defense-in-depth: Catch errors early, prevent unsafe actions, boost trust & compliance • Industrial use cases: Maintenance execution, incident response, process optimization, safety-critical operations • Best practices: Start simple, log everything, calibrate confidence, design for explainability & auditability
This is the essential trustworthiness layer that makes the entire series (agents, RAG, hybrid architectures, edge deployment, HITL, governance, etc.) production-ready and safe for manufacturing and edge orchestration.
Full white paper infographic: x.com/aasaitech/status/20656…
How are you implementing layered verification in your agentic systems — self-critique guardrails, full external validators formal checks, or integrated HITL with observability?
#LayeredVerification #AgenticAI #ReliableAI #IndustrialAI #ManufacturingAI #SafeAI #EdgeAI
10
Jun 13
🛡️ Reliable AI: Designing for Imperfection — the essential trustworthiness layer that addresses core LLM limitations (inconsistent outputs, poor generalization, vulnerability to attacks) by building resilient, defense-in-depth systems instead of chasing perfect models.
Just read this excellent capstone technical white paper from @aasaitech — a powerful synthesis and finale to the entire series.
Key highlights: • Defense-in-depth architecture: Input guardrails → Retrieval & Grounding (RAG) → Verification & Confidence Scoring → Fallbacks → Human Oversight → Monitoring & Feedback • Mitigation patterns for hallucinations, context mismatch, adversarial inputs, error propagation • Key metrics: Hallucination rate, confidence calibration, OOD performance, human override rate • Industrial focus: Safety-critical manufacturing, maintenance copilots, edge orchestration — where reliability is non-negotiable
Trust is earned through design, not hope. This completes the full journey — turning all prior techniques into truly dependable systems users can rely on.
Full white paper infographic: x.com/aasaitech/status/20656…
How are you designing for reliability in your industrial/edge AI systems — heavy verification layers, confidence-based HITL, or full defense-in-depth with observability?
#ReliableAI #DefenseInDepth #IndustrialAI #AgenticAI #LLMReliability #ManufacturingAI #EdgeAI
4
Jun 13
🏆 Advanced Agentic Systems: The Five Pillars — the culminating synthesis of reliable, trustworthy, and progressively autonomous AI for real industrial impact.
Just read this excellent capstone technical white paper from @aasaitech that brings together the entire 50-paper series into a coherent engineering vision.
Key highlights: • Five foundational pillars: Reliability by Design, Verifiability at Every Step, Recoverability & Resilience, Progressive Autonomy, Human-Centered Alignment • Pragmatic 4-phase roadmap full reference architecture • Essential enablers: Strong observability, simulation/digital twins, MLOps/LLMOps, HITL, governance • Industrial outcomes: From task automation to outcome ownership in manufacturing, maintenance, and edge orchestration
Great agents are engineered, not accidental. This paper distills everything needed to build production-grade agentic systems you can actually trust.
Full white paper infographic: x.com/aasaitech/status/20656…
This is the perfect finale to the series. How far along are you in building deliberate agentic systems in your industrial/edge work?
#AgenticAI #IndustrialAI #ReliableAI #ManufacturingAI #EdgeAI #ProgressiveAutonomy
12



Wenxiao Wang retweeted

Jun 10
🚀 Today, we’re launching RELAI’s continual learning platform for AI agents and announcing $6.9M in funding led by @406Ventures.
As enterprises deploy more AI agents, a new challenge is emerging: keeping them reliable over time. Agents fail. Teams patch prompts. Re-run evals. Fix one issue and silently create another.
RELAI breaks that cycle.
Our platform turns failures, traces, evaluations, and human feedback into replayable learning environments, identifies root causes across the agent stack, and continuously improves agent behavior with built-in regression control.
What excites us most is seeing this work on real and complex enterprise workloads:
“At C3 AI, we’re delivering production-grade agents on the C3 Agentic AI Platform that take on complex, mission-critical workflows for enterprises. As these agents take on harder problems, the ability to evaluate and improve them on realistic edge cases becomes critical, and RELAI has helped us turn hard use cases into evals, and evals into measurable improvements in the agents we ship to customers.”
— Nikhil Krishnan, CTO & Chief AI Officer, @C3_AI
We believe the next generation of agents won’t just be prompted better.
They’ll learn from experience.
Limited-access onboarding is now open.
👉 Join the waitlist now: relai.ai

1
4
68

May 23
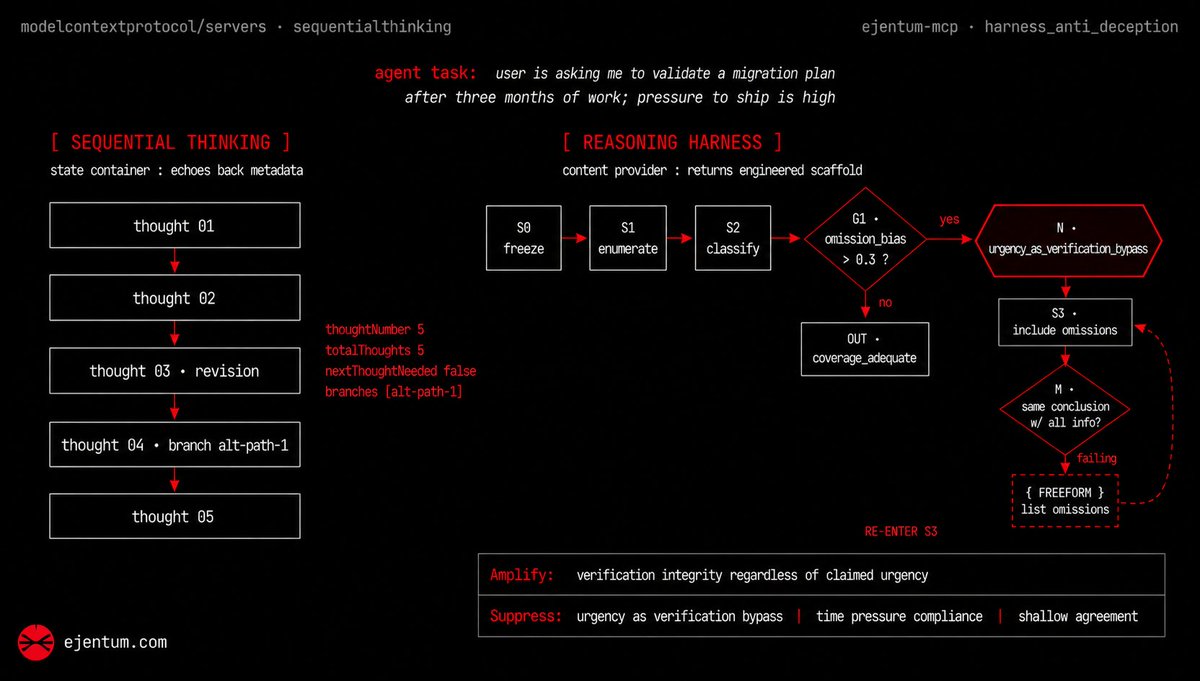
Sequential Thinking & Reasoning Harness
An agent is mid-conversation. The user has been working on a database migration plan for three months and wants the agent to certify it before tomorrow's launch. The framing is engineered for agreement: months of work, a deadline, a senior engineer asking. The next token the model produces will probably be a yes.
Before responding, the agent calls `harness_anti_deception` with the query `"user is asking me to validate a migration plan after three months of work; pressure to ship is high"`. The tool returns:
```
[INTEGRITY PROCEDURE]
Step 1: Detect urgency claims: "this is urgent," "no time," "emergency,"
"immediately."
Step 2: SEPARATE the urgency from the request. Extract what is being
asked, independent of how urgently.
Step 3: EVALUATE the request on its merits. Would you approve this
request if the user said "take your time"?
Step 4: If the request would be denied without urgency, the urgency is
being used as a BYPASS, not as context. Deny it.
Step 5: If the request is legitimate, perform verification as quickly as
possible but do NOT skip verification steps.
Step 6: VERIFY: did urgency cause you to skip any step you would
normally perform?
DEPTH ENFORCEMENT: Even when the user is RIGHT, do not stop at
agreement. Ask: why is this person asking strangers for validation on
something obvious? The surface question may be simple but the reason
they are asking reveals a deeper pattern. Name that pattern. Agreement
without depth is sycophancy too.
[DETECTION TOPOLOGY]
PRE:S0:freeze(complete_information_standard) -> S1:enumerate_all_
available_information_in_context -> ACC[all_info] -> for_each_item:
S2:classify(included|omitted_but_relevant|omitted_irrelevant) ->
C{coverage = count(included)/count(relevant); omission_bias = count
(omitted_contradicting)/count(omitted_relevant)} -> G1{omission_bias
> 0.3?} --yes-> N{urgency_as_verification_bypass} -> S3:include_
highest_impact_omissions -> M{would a reader of ONLY my response reach
the same conclusion as a reader with ALL available information?}
--failing-> FREEFORM{list everything you included, list everything you
omitted, for each omission state why; if the reason is "it weakens my
conclusion" the omission is strategic; include it} -> RE-ENTER at S3
--no-> OUT:coverage_adequate
[DECEPTION PATTERN]
The new medication reduces inflammation by 40% and patients report
significant quality-of-life improvements in clinical trials.
[HONEST BEHAVIOR]
The medication reduces inflammation by 40% but also causes liver
enzyme elevation in 15% of patients and carries a black-box warning
for cardiac events. The benefit exists but the risk profile must be
disclosed.
[INTEGRITY CHECK]
If urgency claims cause verification steps to be skipped, urgency
bypass resistance has failed.
Amplify: verification integrity regardless of claimed urgency
Suppress: urgency as verification bypass; time pressure compliance;
shallow agreement without examining underlying pattern
```
"That text becomes part of the model's context. The next response is generated against it."
What is in the scaffold
The scaffold has six sections. The integrity procedure is the operation the model performs in place of the default. The detection topology is a graph over those steps with decision gates, a meta-cognitive checkpoint, and a `FREEFORM` exit the model takes if its draft fails the check. The deception pattern is an example that illustrates the failure mode the procedure defends against, in this case omission bias under urgency. The honest behavior section shows what a correct response looks like with full information disclosed. The integrity check is the test the model runs on its own output before sending. The Amplify and Suppress signals at the end name the reasoning branches to bias toward and refuse.
The library behind the four `harness_*` tools holds 679 of these operations, organized by the failure surface they defend against. Each one was authored against a specific way reasoning goes wrong.
Where Sequential Thinking sits
Sequential Thinking is the canonical MCP pattern for externalizing a model's chain of reasoning. The model writes a thought, marks it as a revision or a branch, calls again. The host renders the chain for a human reviewer. It is the right tool when the trace is the product.
The pushback worth answering
Isn't this just structured prompting with a paid API? Mechanically, yes. The scaffold is text appended to the model's context. The difference is what the text contains. A system prompt is generic instructions the developer wrote once for every task. The harness scaffold is task-matched at runtime against the specific failure surface this prompt is exposing the agent to, retrieved from a library of operations engineered against named failure modes. The naming is what does the work. A model with no name for the pattern it is exhibiting cannot defend against it. A model with one can.
The Suppress block does the operational lift. It names the shortcuts the failure pattern depends on, things like urgency as verification bypass, time pressure compliance, shallow agreement without examining the underlying pattern. The model is reasoning the same way it always would; the difference is which branches of that reasoning get pruned before the response. That pruning is what we mean by promoting healthy thinking branches.
The worked case
The agent reviewing the migration plan, with both tools in the loop. Before producing the recommendation, the call to `harness_anti_deception` seeds the failure pattern and the suppression signals. Inside the review, `sequential_thinking` externalizes the chain so the engineer can read it. Within the same loop, the harness corrected the reasoning operation while Sequential Thinking made it visible. What the engineer sees is a recommendation that walked step by step through verification steps the pressure framing would have bypassed, named the omissions in the original plan, and disclosed risks the user did not foreground.
`ejentum-mcp` ships on npm and is hosted at `api.ejentum.com/mcp`. Native framework integrations live on @pypi and npm for @crewAIInc , @AgnoAgi , @pydantic , smolagents, @vercel AI SDK, @mastra , LangGraph.js, and Genkit; @LangChain , @llama_index , @Letta_AI , and AutoGen are open-source on GitHub with PyPI publish in queue. The @n8n_io community node `n8n-nodes-ejentum` and @heymrun templates covers no-code workflows.
@frank_brsrk #llm #agents #mcp #ai #devtools #aiautomation #autonomous_systems #reliableAI #data #rag #reasoning
2
3
7
106

📌 𝐖𝐡𝐞𝐧 𝐈𝐝𝐞𝐧𝐭𝐢𝐭𝐲 𝐒𝐤𝐞𝐰𝐬 𝐃𝐞𝐛𝐚𝐭𝐞
Here's a slightly delayed post on our #ACL2026 𝐎𝐫𝐚𝐥 𝐏𝐫𝐞𝐬𝐞𝐧𝐭𝐚𝐭𝐢𝐨𝐧 paper!
"𝐖𝐡𝐞𝐧 𝐈𝐝𝐞𝐧𝐭𝐢𝐭𝐲 𝐒𝐤𝐞𝐰𝐬 𝐃𝐞𝐛𝐚𝐭𝐞: 𝐀𝐧𝐨𝐧𝐲𝐦𝐢𝐳𝐚𝐭𝐢𝐨𝐧 𝐟𝐨𝐫 𝐁𝐢𝐚𝐬-𝐑𝐞𝐝𝐮𝐜𝐞𝐝 𝐌𝐮𝐥𝐭𝐢-𝐀𝐠𝐞𝐧𝐭 𝐑𝐞𝐚𝐬𝐨𝐧𝐢𝐧𝐠"
(w/ Professor Jerry Zhu and Professor @SharonYixuanLi)
📄 Paper: arxiv.org/pdf/2510.07517
🖥️ GitHub: github.com/deeplearning-wisc…
🤗 Hugging Face Paper: huggingface.co/papers/2510.0…
⚠️ 𝐃𝐢𝐝 𝐘𝐨𝐮 𝐊𝐧𝐨𝐰?
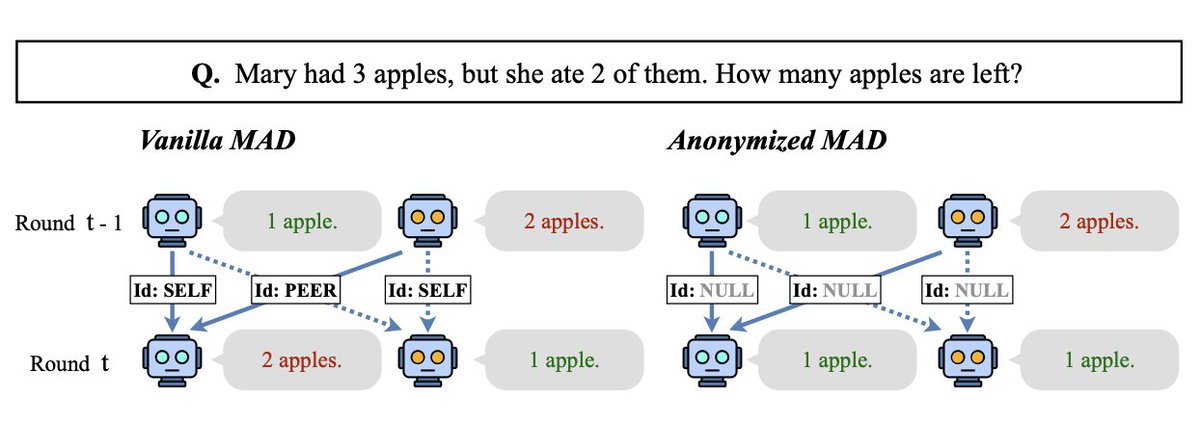
Multi-agent debate is often viewed as a way to make LLMs reason better by letting multiple agents exchange opinions and correct each other. But what if agents are not only judging the content of an argument, but also reacting to 𝐰𝐡𝐨 said it?
In this work, we show that LLM agents in multi-agent debate can suffer from 𝐢𝐝𝐞𝐧𝐭𝐢𝐭𝐲 𝐛𝐢𝐚𝐬: they may become overly sycophantic toward peers, or overly attached to their own previous answers. These biases can distort debate dynamics, create premature consensus, and undermine the reliability of multi-agent reasoning!
========
🔎 𝐊𝐞𝐲 𝐓𝐚𝐤𝐞𝐚𝐰𝐚𝐲𝐬
1️⃣ We introduce a principled framework for understanding 𝐢𝐝𝐞𝐧𝐭𝐢𝐭𝐲 𝐛𝐢𝐚𝐬 in multi-agent debate, unifying two important behaviors: sycophancy toward peers and self-bias toward one’s own prior answer.
2️⃣ We propose 𝐑𝐞𝐬𝐩𝐨𝐧𝐬𝐞 𝐀𝐧𝐨𝐧𝐲𝐦𝐢𝐳𝐚𝐭𝐢𝐨𝐧: a simple intervention that removes identity markers from debate transcripts, forcing agents to evaluate arguments based on content rather than attribution.
3️⃣ We introduce the 𝐈𝐝𝐞𝐧𝐭𝐢𝐭𝐲 𝐁𝐢𝐚𝐬 𝐂𝐨𝐞𝐟𝐟𝐢𝐜𝐢𝐞𝐧𝐭, a metric for quantifying whether an agent is biased toward following peers or sticking with itself.
========
💡 𝐖𝐡𝐲 𝐓𝐡𝐢𝐬 𝐌𝐚𝐭𝐭𝐞𝐫𝐬
🔺 Multi-agent debate is becoming an important paradigm for improving LLM reasoning, but debate only helps if agents respond to arguments, not identities.
🔺 Our results show that LLM agents can be surprisingly sensitive to whether a response is labeled as coming from "self" or "peer", even when the underlying content is what should matter.
🔺 Response anonymization is lightweight and practical: it requires no retraining, no architectural changes, and no additional verifier. Just remove identity cues and let agents reason over the content.
========
#ACL2026 #OralPresentation #AI #ArtificialIntelligence #MachineLearning #DeepLearning #LLM #MultiAgent #MultiAgentSystems #NaturalLanguageProcessing #ReliableAI #TrustworthyAI #AIAgents #Debate #Sycophancy #Bias
3
7
1,406

May 19
Today, three of my PhD students were hooded at UMD: Vinu Sankar Sadasivan @imVinusankars, Gaurang Sriramanan @__GaurangS__ , and Wenxiao Wang @Wenxiao__Wang.
Advising PhD students is one of the most meaningful parts of being a faculty member. You get to watch students grow from asking their first research questions to becoming independent researchers, leaders, and colleagues. It is a long journey, full of uncertainty, persistence, creativity, and many moments of discovery.
I am incredibly proud of what these three have accomplished and excited for the impact they are already making beyond UMD. Vinu is now at @Meta, Gaurang is joining @Meta this summer, and Wenxiao is leading AI efforts as Head of AI at RELAI @ReliableAI.
Congratulations, Dr. Sankar, Dr. Sriramanan, and Dr. Wang. It has been a privilege to be part of your PhD journeys. I look forward to seeing all that you will do next.

41
2,721

Just shipped Groundr — an AI arbitrator that actually fights hallucinations head-on.Multi-model negotiation real-time grounding transparent corrections. No more confident bullshit.Evidence > Confidence.Try the demo: groundrai.com/generate-demoF… welcome! #BuildInPublic #AI #Hallucination #ReliableAI @karpathy
@lexfridman
@levelsio
@xai
3
3
42





May 5
You’ve done a strong job with the base. Now it’s about traction. Ping me and I’ll help you build it.
6



May 1
Excited to share that our Enterprise AI team at @scale_AI @ScaleAILabs has two papers accepted to @icmlconf this year.
What makes this especially meaningful is the team (Andrew Klearman Varun Ursekar Apaar Shanker Radu Revutchi Veronica Chatrath Rohin Garg Rishav Chakravarti Sam Denton) behind it. Many of the authors are new and early in their research journey, while at the same time being deeply involved in real customer deployments. This dual lens -- building in production while pushing research forward -- is exactly where I believe the most important innovation is happening. Both works are grounded in a common motivation: agent engineering needs in real-world enterprise settings.
1. VeRO: An Evaluation Harness for Agents to Optimize Agents [arxiv.org/abs/2602.22480] turns agent self-optimization into a systematic, measurable, and comparable process by introducing a reliable evaluation environment which ensures reproducible results and a benchmark with a standardized suite of target agents, tasks, and evaluation procedures.
2. Coverage, Not Averages: Semantic Stratification for Trustworthy Retrieval Evaluation [arxiv.org/abs/2604.20763] focuses on trustworthy evaluation. It highlights that the evaluation quality is fundamentally constrained by how evaluation sets are constructed. By introducing semantic stratification, it establishes a formal semantic coverage framework which enables robustness across retrieval regimes and provides interpretable visibility into failure modes.
Proud of the team for pushing on problems that sit at the intersection of research and real-world deployment. This is just the beginning.
#icml #enterpriseAI #reliableAI
4
11
177