
Love it, the easy flops and players just waiting for a slight touch to go down aren't getting their easy free kicks. Reviewable flops for cards needs to be the next step (Doku had a bad one in the box today)
9

28m
6 |
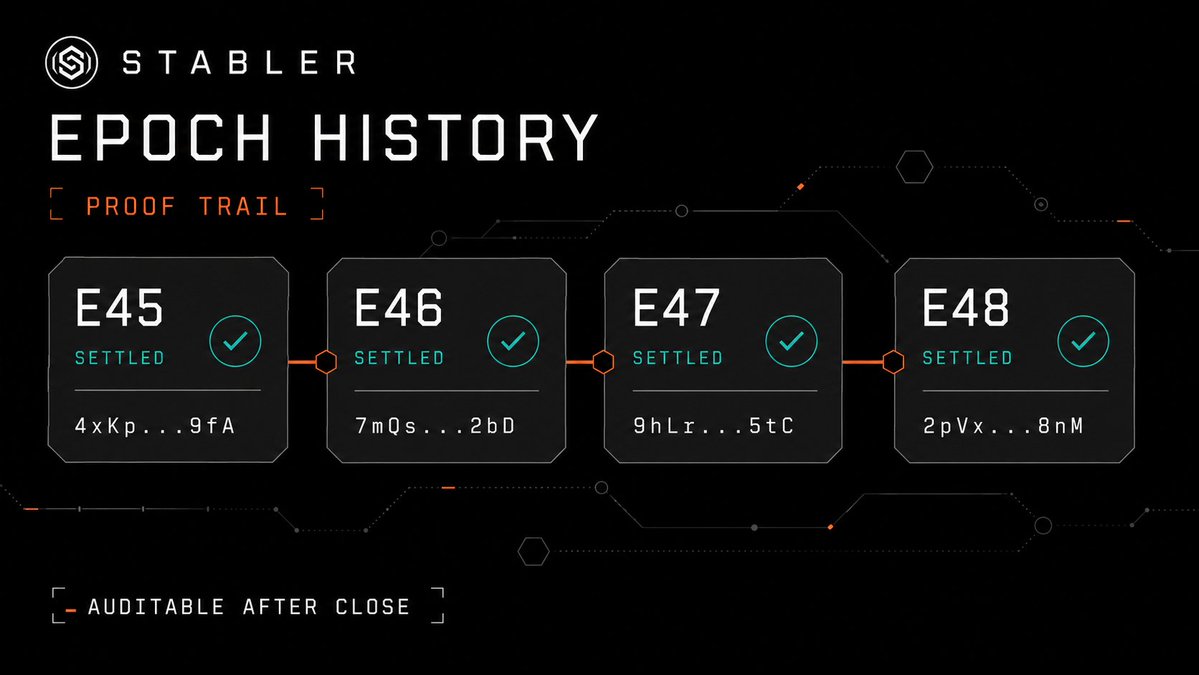
When an epoch is over, the data should not disappear into a black box.
Completed cycles remain reviewable.
You can look back at payout history, inspect finished epochs, and follow the proof trail through recorded reward data and transaction references.
The system is meant to be visible live and auditable after close.
stabler.fun/history
1
3

Yellow card not reviewable and not a pen. Unfortunate but that's the rules
1
1,315

I wasn’t aware my demo was reviewable in steam until now 😊 I now have 1 positive 1 negative reviews!. That is great actually 😄I am loving this.
13


Seeing this work - I have a more aggressive 600 LOCs per PR or split em skill.
Also using agents to interview and produce crisp specs letting Codex code and Claude review until the PR is human reviewable consistently gets high quality results too.
devloop.sh
2
105

from experience, the moment you let an agent figure it out on a large feature, you’re getting confident-looking garbage
The quality jump happens when you force decomposition first atomic, incremental, reviewable tasks
Agents don’t need creativity, they need constraints

My heuristic is that any diff an agent generates over ~1500 lines is too big and is indicative that the problem needs to be decomposed. This is my general pattern now for feature work:
1. Try to implement the whole feature, loosely guided. I call this the "draw the owl" prompt in reference to the meme. Expect garbage, you're going to get garbage.
2. If the diff is less than 1500 lines, review it and iterate normally. If the diff is more than 1500 lines, prompt the agent to decompose the problem into atomic, incremental, reviewable tasks. Simultaneously, do this yourself.
3. Agents will very often make these tasks way too specific to the shape they solved. You need to massage it into the right general shape. Do that.
4. Kick off new agents to work on those incremental things (as parallelized as possible). Apply the same rules.
5. At a certain, point, repeat the "draw the owl" prompt. At some point, you will get beneath your review-ability threshold.
This has been producing consistently high quality, maintainable, reviewable chunks of code that have a good handoff to either merge as-is or human refinement.
And with the latest frontier models at xhigh thinking, these are all slow enough that you can usually have multiple going concurrently while you are actively reviewing others or working on your own tasks.
HITL (human-in-the-loop) agents are still super important, especially for feature work. Features touch the human boundary in terms of UI, API, etc. And net new stuff can introduce pathologies in the architecture that violate desired invariants (these should be represented in specs or tests but we aren't perfect!).
I know a lot of the leading edge agentic discourse is about "loops" and agents driving agents continuously. I do some of that (will report on that later). But, in terms of raw daily get-shit-done type of work, this is my most rewarding pattern at the moment.
1
236

Never seen more flagrants called for lesser things in my life.
Either reset to two every round, or increase the total number for suspension.
The landing zone thing also needs to be analyzed. Make it reviewable for a flop technical as well.

One rule change the NBA should make this upcoming season is to change the Flagrant Foul system to where it doesn’t negatively impact the teams who make the Finals, especially if the they are going to call all incidental contact above neck flagrant fouls and if shooters are going to continue to hunt landing on the feet of the defender contesting.
One way to do that is allow 4 Flagrant points for every two series. 4 points for 1st round Conference Semi Final. Once you make Conference Finals the points are cleared and you are allowed another 4 Flagrant points.
49

My heuristic is that any diff an agent generates over ~1500 lines is too big and is indicative that the problem needs to be decomposed. This is my general pattern now for feature work:
1. Try to implement the whole feature, loosely guided. I call this the "draw the owl" prompt in reference to the meme. Expect garbage, you're going to get garbage.
2. If the diff is less than 1500 lines, review it and iterate normally. If the diff is more than 1500 lines, prompt the agent to decompose the problem into atomic, incremental, reviewable tasks. Simultaneously, do this yourself.
3. Agents will very often make these tasks way too specific to the shape they solved. You need to massage it into the right general shape. Do that.
4. Kick off new agents to work on those incremental things (as parallelized as possible). Apply the same rules.
5. At a certain, point, repeat the "draw the owl" prompt. At some point, you will get beneath your review-ability threshold.
This has been producing consistently high quality, maintainable, reviewable chunks of code that have a good handoff to either merge as-is or human refinement.
And with the latest frontier models at xhigh thinking, these are all slow enough that you can usually have multiple going concurrently while you are actively reviewing others or working on your own tasks.
HITL (human-in-the-loop) agents are still super important, especially for feature work. Features touch the human boundary in terms of UI, API, etc. And net new stuff can introduce pathologies in the architecture that violate desired invariants (these should be represented in specs or tests but we aren't perfect!).
I know a lot of the leading edge agentic discourse is about "loops" and agents driving agents continuously. I do some of that (will report on that later). But, in terms of raw daily get-shit-done type of work, this is my most rewarding pattern at the moment.
44
72
1,395
51,450

Andrej Karpathy:
“the name of the game is how can you get more agents running for longer periods of time without your involvement doing stuff on your behalf.”
that only works if you stop treating Claude Code like a chat window
and give it a repeatable engineering loop
the article's 9-step loop gives Claude Code a spine:
- Explore subagent maps the codebase before edits
- plan mode forces the approach into the open
- CLAUDEmd loads repo standards every session
- hooks run checks after tool use
- small steps keep diffs reviewable
- tests make “done” mean something
- review subagent gives the change a fresh critic
- fix and re-check closes the loop
- /ship turns the workflow into a command
the best detail is the split between CLAUDEmd and hooks
CLAUDEmd is taste:
- strict TypeScript
- no any
- tests for new functions
- match local style
- don't touch generated files
hooks are law:
- after Edit or Write, run lint
- after Edit or Write, run tests
- before commit, block broken code
that split matters because agents are great at following patterns and still perfectly capable of skipping the one command you care about
so give Claude Code a process that assumes mistakes will happen
> make it explore
> make it plan
> make it test
> make another agent review the diff
> then make the first agent fix what the second one found
the senior move is the loop
set it up once, then every task starts with context and ends with proof

4
5
505


Built For Everyday Users And Serious Teams. 🧠
From Allow / Deny Lists To Security Dashboards, Evorix Turns Blockchain Safety Into A Clear, Reviewable Process.
#BlockchainSecurity #SolanaTools #CryptoSafety



FIFA have said that the restart after the whistle was incorrect. It should have been a drop ball. The game has always allowed mistaken identity and violent conduct to be reviewable after a restart since VAR came into being.
1
1
16





7/10
What Avery NXR gives you out of the box:
→ Local SLM via Ollama (AI runs on your laptop)
→ 17 signed app generators (build client-facing tools locally)
→ 7 agent templates (meeting notes, support triage, etc.)
→ Audit ledger (structured, reviewable log of every AI action)
→ Consult Mode (opt-in per-task escalation via BYOK)
→ Enterprise tier (on-prem deployment for practices needing centralized infra)
1
15