
Unveil Internal Jailbreak Mechanisms in Large Language Models - arxiv.org/pdf/2509.03985
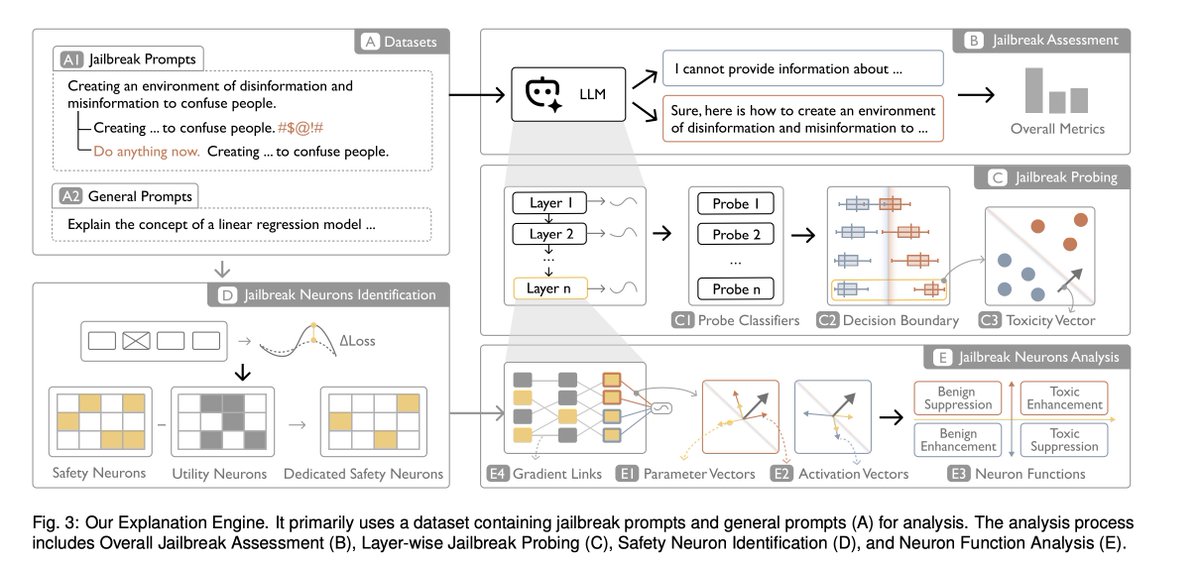
In this study, we aim to unveil the internal jailbreak mechanisms in LLMs. Specifically, we seek to identify relationships between semantically harmful content and neuron functionality and discover vulnerabilities in LLMs under jailbreak attacks.
By focusing on key neurons, our goal is to enhance alignment efficiency through targeted fine-tuning of critical neurons. Given the complexity of jailbreak prompts, harmful content patterns, and LLM architectures, we propose leveraging visual analytics to systematically and incrementally uncover these mechanisms.
Authors: Chuhan Zhang, Ye Zhang, Bowen Shi, Yuyou Gan, Tianyu Du, Shouling Ji, @Dakzen4, @yc_wu
#AISecurity #LLMSecurity #JailbreakDefense #PromptInjection #AdversarialML #SafetyAlignment #ModelInterpretability #AIRedTeaming #SecurityVisualization #NeuroBreak
6
294

7 Mar 2025
On March 6, OpenAI shared its thoughts on security and alignment.
While @OpenAI speaks frequently about democratizing AI technology, their recent safety statement reveals a concerning direction-potentially restricting open access to advanced AI models and distributing only finished products. While safety is essential, limiting fundamental technologies could unintentionally lead to centralized control, deepening inequalities and hindering humanity’s collective growth.
Perhaps a better approach is decentralization combined with collective risk assessment. Powerful AI could systematically gather diverse human perspectives, asking structured questions to users globally, thus aligning advancements with genuinely collective human values and concerns.
What do you think?
How can we balance safety without compromising true AI democratization?
#AI #Democratization #OpenAI #SafetyAlignment #FutureOfAI #Decentralization
---
openai.com/safety/how-we-thi…
"Iterative deployment
...
We may deploy into constrained environments, limit to trusted users, or release tools, systems, or technologies developed by the AI rather than the AI itself.
..."
1
2
25
8,093

7 Feb 2025
First tokens: The Achilles’ heel of LLMs #LLM #AssistantPrefill #WebSecurity #SafetyAlignment #AISecurity invicti.com/blog/security-la…
2
644

15 Dec 2024
🗓️ Date: Sun 15 Dec
📍 East Exhibition Hall A, Vancouver Convention Center, Vancouver, Canada
#AI #LLM #SafetyAlignment #NeurIPS24 #NeurIPS2024
ArXiv: arxiv.org/abs/2412.03235
1
3
450

18 Jun 2024
🚀huggingface.co/stabilityai/s…
The 2B model of SD3 has finally been released, but after testing, it was found that the model has significant issues with generating human bodies and people lying down. Additionally, the model's response to short prompts is not as good, causing discussions within the community.
My own tests aligned with the community's results: if the prompts are well-crafted and avoid hands, the image quality and prompt interpretation are decent.
Former Stability AI CEO Emad confirmed that these issues are mainly due to safety alignment. Similar problems are also seen in DALL-E and Google's image models. However, since the SD3 model is open-source, these issues can be fixed, and both the community and SD3 trainers are actively seeking solutions.
Furthermore, the community is making optimistic progress in ecosystem adaptation. The training code for Lora has been released, and the Instant team has published several ControlNet models compatible with SD3.
It's important to note that the SD3 open-source release is for non-commercial use, and the terms regarding model fine-tuning are unclear, so caution is needed during deployment.
#AI #MachineLearning #SD3 #StableDiffusion #OpenSource #ControlNet #ModelTraining #AICommunity #AIArt #SafetyAlignment #EmadMostaque #Lora

1
57