
FlowViz - Attack Flow Visualizer - github.com/davidljohnson/flo…
AI-powered cybersecurity attack flow visualization tool using MITRE ATT&CK
An open-source React application that analyzes cybersecurity articles and generates interactive attack flow visualizations using the MITRE ATT&CK framework.
#FlowViz #MITREATTACK #AttackFlow #ThreatIntelligence #CTI #DFIR #SecurityVisualization #AdversaryEmulation #OpenSourceSecurity #AIinCybersecurity
1
8
283
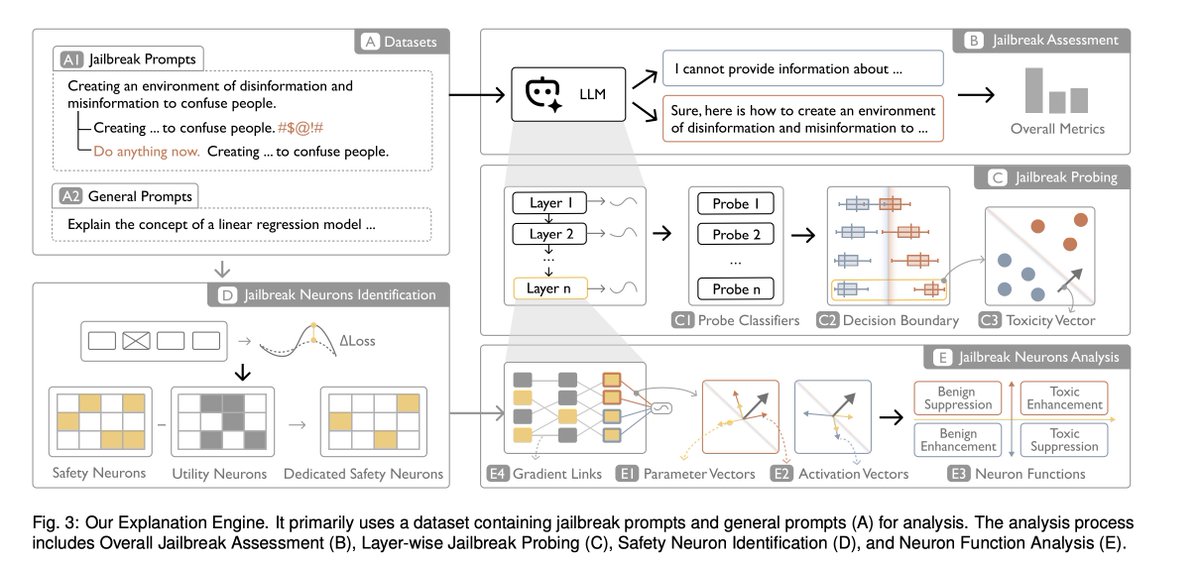
Unveil Internal Jailbreak Mechanisms in Large Language Models - arxiv.org/pdf/2509.03985
In this study, we aim to unveil the internal jailbreak mechanisms in LLMs. Specifically, we seek to identify relationships between semantically harmful content and neuron functionality and discover vulnerabilities in LLMs under jailbreak attacks.
By focusing on key neurons, our goal is to enhance alignment efficiency through targeted fine-tuning of critical neurons. Given the complexity of jailbreak prompts, harmful content patterns, and LLM architectures, we propose leveraging visual analytics to systematically and incrementally uncover these mechanisms.
Authors: Chuhan Zhang, Ye Zhang, Bowen Shi, Yuyou Gan, Tianyu Du, Shouling Ji, @Dakzen4, @yc_wu
#AISecurity #LLMSecurity #JailbreakDefense #PromptInjection #AdversarialML #SafetyAlignment #ModelInterpretability #AIRedTeaming #SecurityVisualization #NeuroBreak
6
294

15 Nov 2020
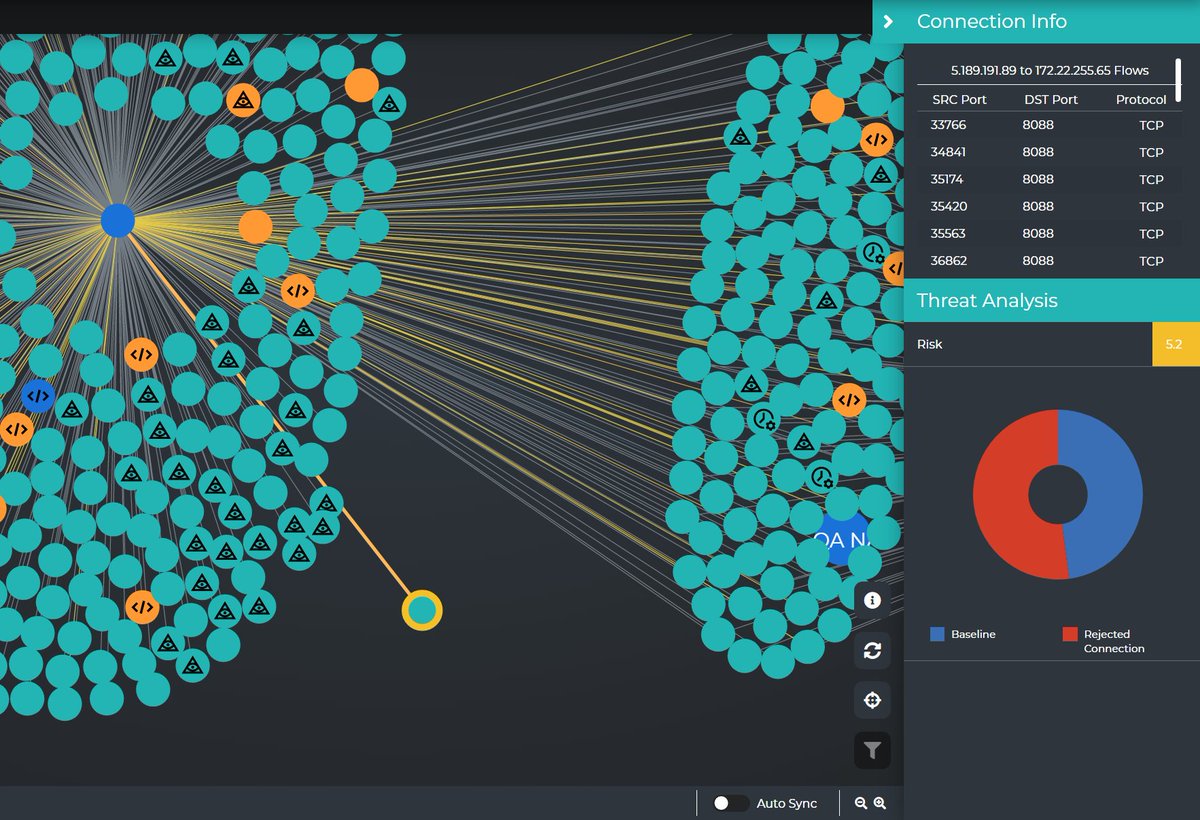
Persistence doesn't always pay off, little Trojan. #RejectedConnection #ThreatHunting #ThreatDetection #AuspexObservatory #CyberSecurity #SecurityVisualization
3
1

11 Oct 2017
1
29 Sep 2017
How do we move past cool-yet-meaningless #SecurityVisualization maps, to a useful visual interface? hubs.ly/H08xzFH0 #cyber
1
27 Sep 2017
How do we move past cool-yet-meaningless #SecurityVisualization maps, to a useful visual interface? hubs.ly/H08xz_00 #cyber
3
7
17 Sep 2017
1
7 Sep 2017
How do we move past cool-yet-meaningless #SecurityVisualization maps, to a useful visual interface? hubs.ly/H08xBjv0 #cyber
1
6 Sep 2017
1
25 Aug 2017
How do we move past cool-yet-meaningless #SecurityVisualization maps, to a useful visual interface? hubs.ly/H08sh3Y0 #cyber
2
3
25 Aug 2017
How do we move past cool-yet-meaningless #SecurityVisualization maps, to a useful visual interface? hubs.ly/H08shCQ0 #cyber
1
24 Aug 2017
How do we move past cool-yet-meaningless #SecurityVisualization maps, to a useful visual interface? hubs.ly/H08shn10 #cyber
8
6
24 Aug 2017
How do we move past cool-yet-meaningless #SecurityVisualization maps to a useful visual interface? hubs.ly/H08sh480 #cyber @gadievron
1
2

3 Nov 2016
.@gidicohen @ISSAINTL starts in 15 minutes! #ISSAConf #attacksurface #IndicatorsofExposure #securityvisualization

3

3 Nov 2016
.@gidicohen @ISSAINTL starts in 15 minutes! #ISSAConf #attacksurface #IndicatorsofExposure #securityvisualization

1
4
2 Nov 2016
Attending #ISSAConf? See what's new at booth 209: improving security in #hybridnetworks & #criticalinfrastructure w/ #securityvisualization
2
13 Oct 2016
Join Skybox @PwC_Accelerator #cyberseclu Oct 18 ow.ly/U0uk3059qcR #securityanalytics #securityvisualization

2
2
6 Oct 2016
Skybox & @CyberX_Labs secure #ICS/#SCADA networks w/ #securityvisualization, access simulation & #vuln discovery ow.ly/ycIG304VVv0
4
1
30 Aug 2016
Join Skybox @ManagementEv #600Minutes #CyberSecurity Strategies for the latest in #attacksurface & hybrid network #securityvisualization
2
1
6 May 2016
#CISOs: don't miss @gidicohen strategy talk on #securityvisualization to reduce & communicate risk across enterprise
6 May 2016

What is visible attack surface and why does it matter? #infosec16 seminar @skyboxsecurity stand #B40
bit.ly/1V9gyDN
2