Multi-task gradient boosting with multi-modal molecular representations for simultaneous prediction of drug clearance and volume of distribution
1. The paper presents MTGBM, a multi-task gradient boosting machine that predicts two physiologically coupled PK endpoints at once: human clearance (CL) and volume of distribution (VD), using shared decision trees rather than separate single-task models.
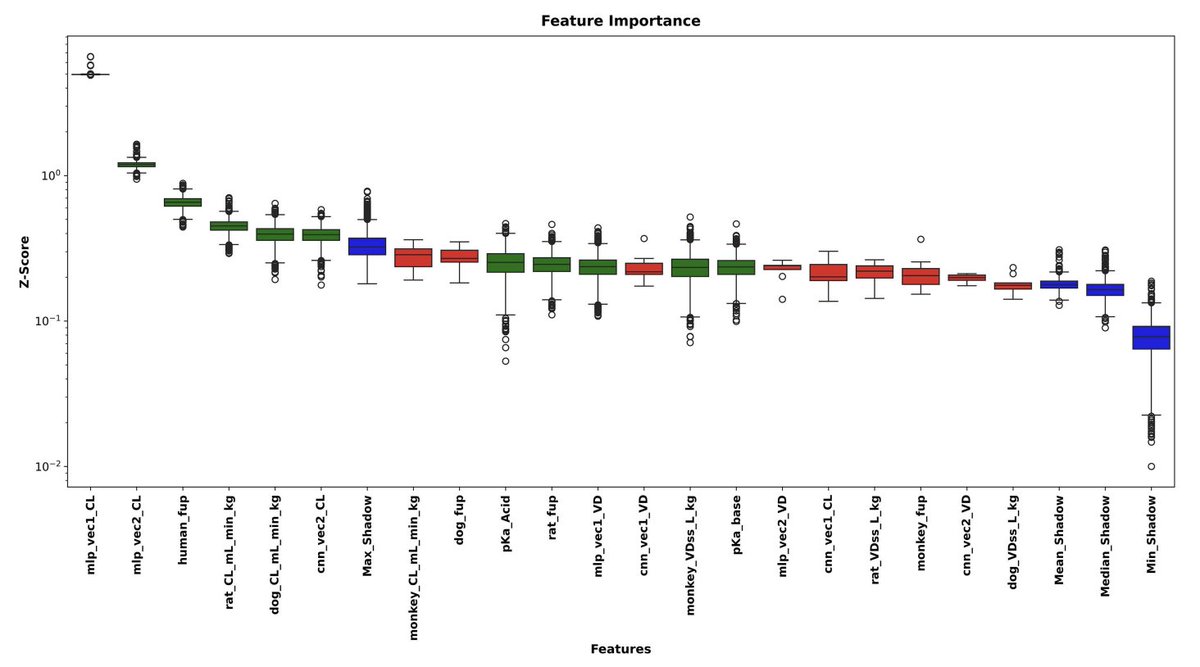
2. A key design choice is multi-modal input: (i) CNN embeddings from 2D molecular structure images (ResNet18-based), (ii) MLP embeddings from concatenated RDKit descriptors Morgan fingerprints (256 bits) Mol2Vec (300d), and (iii) physicochemical in vitro preclinical PK variables (e.g., pKa, fup, rat/dog/monkey PK).
3. Both CNN and MLP pipelines are trained per target (CL-specific and VD-specific), then compressed into compact 2D bottleneck embeddings; these embeddings are later used as features for the boosting models, enabling the final learner to combine learned representations with experimental/nonclinical variables.
4. Feature selection is handled with BorutaSHAP (5,000 iterations, LightGBM backbone). It selects 11 features for CL and 11 for VD, with 6 overlapping; the multi-task model uses the union set (16 total), mixing modalities rather than relying on a single feature type.
5. On a held-out test set (n=139), MTGBM improves MSE and R² for both targets versus single-task LightGBM: CL MSE 19.081 → 14.580 (−23.6%), R² 0.140 → 0.196; VD MSE 1.130 → 0.757 (−33.0%), R² 0.212 → 0.418.
6. The paper highlights a metric tradeoff for VD: despite better MSE/R², overall VD GMFE worsens (2.014 → 2.286). A stratified analysis shows the degradation is driven specifically by the low-VD region (<0.5 L/kg), while mid and high VD ranges show improved GMFE under MTGBM.
7. Statistical testing with the Diebold–Mariano test supports the MSE improvements as significant for both endpoints (CL p=0.019; VD p=0.004), framing the gains as unlikely due to chance under their evaluation setup.
8. Robustness is assessed via 10 repeated random 60/20/20 splits with the full pipeline rerun each time (normalization, embedding training, BorutaSHAP, LightGBM tuning, MTGBM training). MTGBM wins on test MSE in 8/10 runs for CL and 10/10 runs for VD, suggesting consistent directional benefit, especially for VD.
9. SHAP interpretability suggests complementary modality contributions and cross-target signal usage: CL is strongly influenced by MLP embeddings, and VD is dominated by preclinical PK (notably dog_VDss_L_kg), while embeddings trained for one target can appear among top predictors for the other—consistent with CL/VD physiological coupling, but also influenced by the supervised nature of the embeddings.
📜Paper: doi.org/10.1371/journal.pone…
#ComputationalPharmacokinetics #ADME #MachineLearning #MultiTaskLearning #LightGBM #DrugDiscovery #QSAR #ModelInterpretability #SHAP #Pharmacometrics
1
7
1,062

𝗣𝗮𝗽𝗲𝗿 𝗔𝗰𝗰𝗲𝗽𝘁𝗮𝗻𝗰𝗲 𝗔𝗻𝗻𝗼𝘂𝗻𝗰𝗲𝗺𝗲𝗻𝘁
Paper titled "A Unified View on Emotion Representation in Large Language Models" accepted at European Chapter of the Association for Computational Linguistics(EACL) 2026.
Authors: Aishwarya Maheswaran, Maunendra Sankar Desarkar
👏 Congratulations to all the authors!
🔍 Key Highlight:
As LLMs are increasingly integrated into emotional support frameworks, it is essential to understand how these models internalize emotions. Our research provides a unified perspective on emotion representation through the following findings:
• Implicit Detection: LLMs naturally encode emotional concepts, and their exact locations are data and prompt-dependent.
• Structural Consistency: Emotion vectors (extracted from the model's representations) are functionally equivalent across different datasets (in later layers), indicating a stable, internal representation.
• Representation != Capability: While "Chain of Thought" (CoT) processing increases the model's confidence in its output, it does not necessarily improve emotion detection accuracy.
#LLMs #EmotionAI #AffectiveComputing #EmotionRepresentation #ModelInterpretability #RepresentationLearning #ChainOfThought
#ResponsibleAI #CSE #IITHyderabad
1
9
667

22 Dec 2025
Gemma Scope 2 is here: an open “microscope” for Gemma 3, built for real AI safety work.
Released on December 19, 2025, Gemma Scope 2 is Google DeepMind’s new open interpretability suite for the entire Gemma 3 family. This post breaks down what it is, what’s actually included, why the scale matters, and how beginners and experts can use it to investigate tricky model behaviors like jailbreaks and hallucinations.
@GoogleDeepMind
🔗Tap below to dive deep into it👇
bytebrief.vercel.app/blog/ge…
#GemmaScope2 #MechanisticInterpretability #AISafety #DeepMind #Gemma3 #SparseAutoencoders #Transcoders #OpenSourceAI #LLM #AIResearch #ModelInterpretability #GenAI
1
2
39

14 Nov 2025
OpenAI’s update on training smaller AI models is an important step.
Making internal mechanisms easier for humans to understand could lead to more transparent and efficient systems.
If compact models become both interpretable and highly capable, it may change the way we design future AI.
#AI #MachineLearning #OpenAI #ModelInterpretability #TechInnovation

We’ve developed a new way to train small AI models with internal mechanisms that are easier for humans to understand.
Language models like the ones behind ChatGPT have complex, sometimes surprising structures, and we don’t yet fully understand how they work.
This approach helps us begin to close that gap.
openai.com/index/understandi…
3
60

Unveil Internal Jailbreak Mechanisms in Large Language Models - arxiv.org/pdf/2509.03985
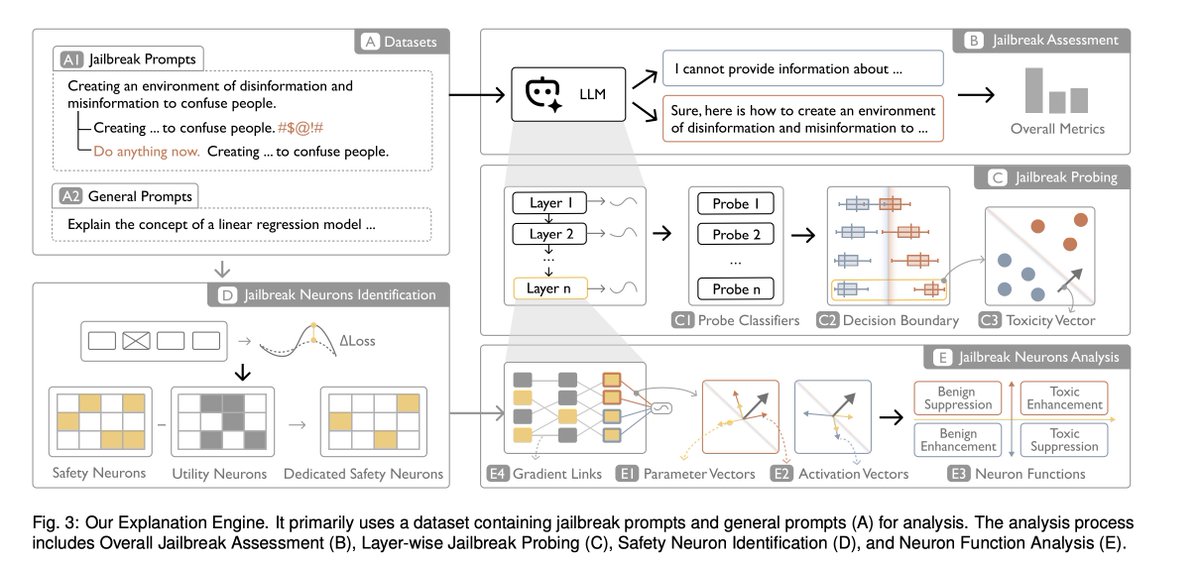
In this study, we aim to unveil the internal jailbreak mechanisms in LLMs. Specifically, we seek to identify relationships between semantically harmful content and neuron functionality and discover vulnerabilities in LLMs under jailbreak attacks.
By focusing on key neurons, our goal is to enhance alignment efficiency through targeted fine-tuning of critical neurons. Given the complexity of jailbreak prompts, harmful content patterns, and LLM architectures, we propose leveraging visual analytics to systematically and incrementally uncover these mechanisms.
Authors: Chuhan Zhang, Ye Zhang, Bowen Shi, Yuyou Gan, Tianyu Du, Shouling Ji, @Dakzen4, @yc_wu
#AISecurity #LLMSecurity #JailbreakDefense #PromptInjection #AdversarialML #SafetyAlignment #ModelInterpretability #AIRedTeaming #SecurityVisualization #NeuroBreak
6
294

12 Aug 2025
MOTGNN: Interpretable Graph Neural Networks for Multi-Omics Disease Classification
1. A novel framework MOTGNN is proposed for multi-omics disease classification, integrating DNA methylation, mRNA expression, and miRNA expression data. It outperforms state-of-the-art methods by 5-10% in accuracy, ROC-AUC, and F1-score on three real-world datasets, especially showing robustness to severe class imbalance.
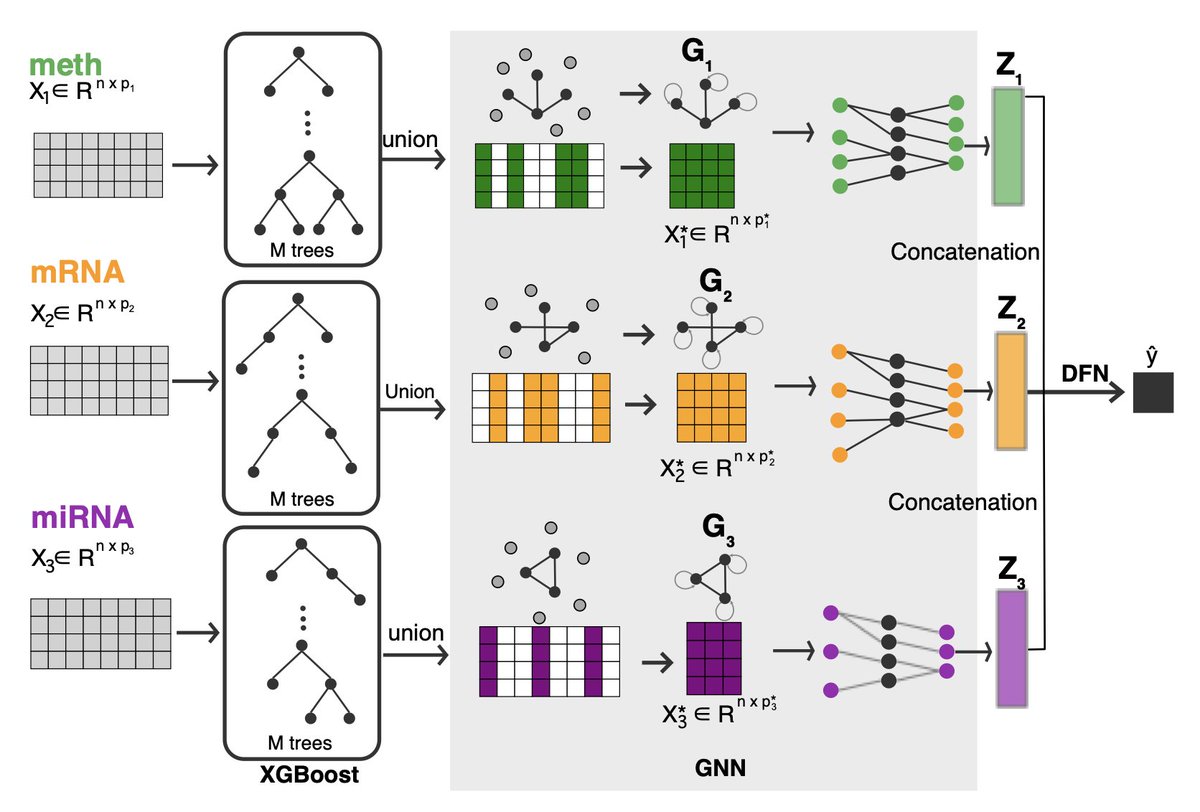
2. The model employs XGBoost for omics-specific supervised graph construction, leveraging the structure of trained decision trees to create sparse and modality-specific graphs. This approach effectively reduces noise and redundancy while preserving biologically meaningful interactions.
3. MOTGNN uses Graph Neural Networks (GNNs) to learn hierarchical representations from each graph and a deep feedforward network for cross-omics integration. The GNNs capture both local and global graph topology, enabling the model to extract complex relationships among features.
4. A key innovation of MOTGNN is its built-in interpretability. It provides feature-level importance scores to identify top-ranked biomarkers within each modality and omics-level contribution scores, revealing which data types are most influential for prediction. This supports downstream biological discovery and clinical applications.
5. The model maintains computational efficiency through sparse graphs with 2.1-2.8 edges per node. It consistently outperforms existing models across all datasets, achieving significant improvements in F1-score on class-imbalanced data, addressing a critical limitation in biomedical classification.
📜Paper: arxiv.org/abs/2508.07465v1
#GraphNeuralNetworks #MultiOmics #DiseaseClassification #Bioinformatics #ModelInterpretability
2
14
1,022
28 Jun 2025
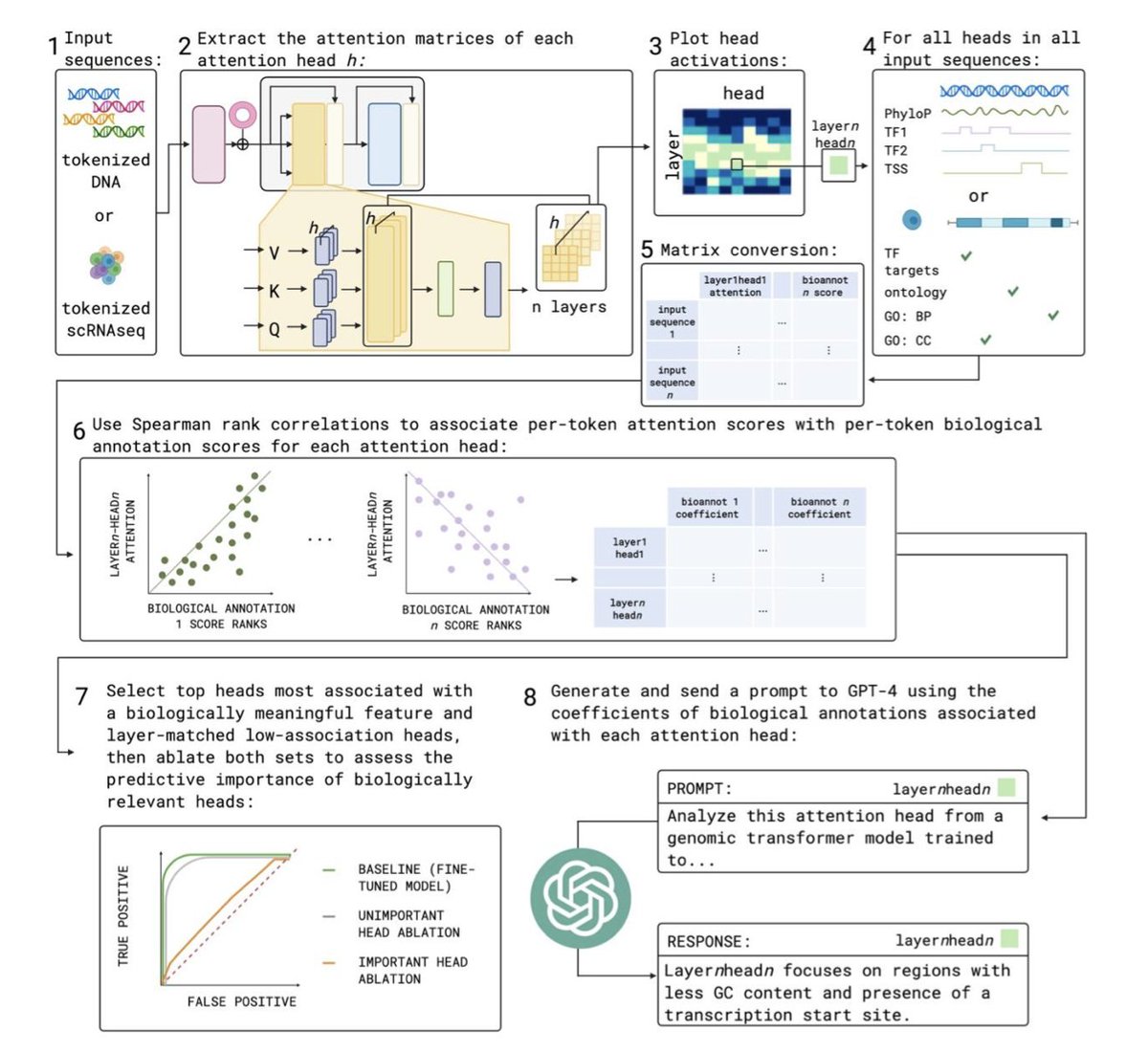
Interpreting Attention Mechanisms in Genomic Transformer Models: A Framework for Biological Insights
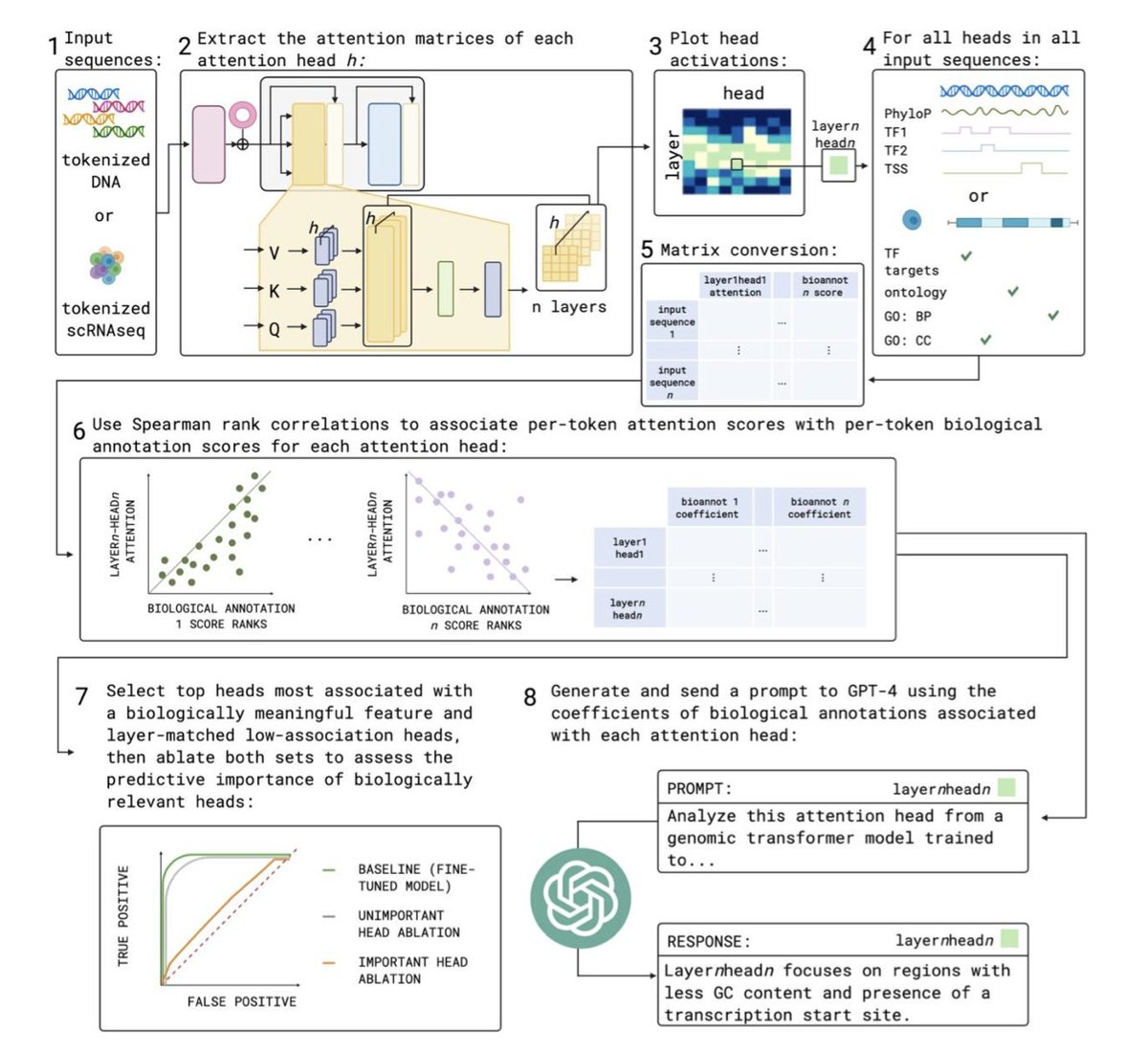
1.This paper introduces a scalable framework to biologically interpret attention heads in genomic transformer models, helping uncover how models like DNABERT, Nucleotide Transformer, and scGPT learn biologically meaningful patterns during pre-training and fine-tuning.
2.Key insight: attention heads correlated with biological annotations—like TSS, GC content, or GO terms—are not only interpretable but often essential for predictive performance. Removing such heads causes greater drops in accuracy than removing other heads in the same layer.
3.The method computes Spearman correlations between attention scores and biological annotations per token. For fine-tuned models, GPT-4 is used in a zero-shot setting to summarize each head’s biological focus, streamlining interpretation across hundreds of heads.
4.Biological relevance emerges early: even models pre-trained on random k-mers (DNABERT variant) develop biologically meaningful attention patterns, suggesting that structural properties in random sequences can foster learning.
5.Fine-tuning refines, rather than overhauls, attention patterns. Most attention heads retain their pre-training associations, though some reorient toward task-relevant features, such as TSS detection in TATA-promoter classification.
6.Context dependence is critical: heads may assign high attention to a motif like TATAAA only when the full sequence context matches a promoter. Interpretation must be label-specific to avoid masking this behavior.
7.The paper demonstrates that some heads specialize in “positive learning” (attending to presence of features) while others engage in “negative learning” (suppressing attention where features are absent). These opposing dynamics can be observed by stratifying head-feature correlations.
8.Tokenization affects interpretability. DNABERT’s overlapping k-mers enhance motif-level interpretability. In contrast, Nucleotide Transformer’s non-overlapping scheme fragments motifs, shifting attention to proxy features like GC content.
9.The framework includes systematic ablation experiments showing that heads strongly correlated with biological features are not just interpretable—they are functionally important for the model’s performance on genomic prediction tasks.
10.GPT-4 can accurately summarize the biological behavior of individual heads, such as identifying heads attending to TATA motifs, TSS, or neuron-specific gene programs. However, its summaries may overlook subtleties when multiple features show similar strength.
11.The study shows that attention heads in scGPT, trained on single-cell data, align with gene ontology terms relevant to cell types and diseases like Multiple Sclerosis. Heads specific to neuron projection or synaptic function were identified as important in fine-tuning.
12.Limitations include reliance on curated biological annotations and the assumption that attention can reflect functional mechanisms. The authors acknowledge that some informative features may not be captured, and GPT-4’s summaries can overgeneralize.
13.Despite limitations, the work offers a robust framework for head-level interpretability in genomic foundation models, spanning DNA and single-cell domains. It facilitates large-scale, context-aware dissection of what these models learn across training stages.
💻Code: github.com/yaozhong/bert_inv…
📜Paper: biorxiv.org/content/10.1101/…
#Genomics #Transformers #AttentionMechanism #scGPT #DNABERT #ModelInterpretability #ComputationalBiology #Bioinformatics #MachineLearning #AI4Science
6
22
2,084
28 Jun 2025
Interpreting Attention Mechanisms in Genomic Transformer Models: A Framework for Biological Insights
1.This paper introduces a scalable framework to biologically interpret attention heads in genomic transformer models, helping uncover how models like DNABERT, Nucleotide Transformer, and scGPT learn biologically meaningful patterns during pre-training and fine-tuning.
2.Key insight: attention heads correlated with biological annotations—like TSS, GC content, or GO terms—are not only interpretable but often essential for predictive performance. Removing such heads causes greater drops in accuracy than removing other heads in the same layer.
3.The method computes Spearman correlations between attention scores and biological annotations per token. For fine-tuned models, GPT-4 is used in a zero-shot setting to summarize each head’s biological focus, streamlining interpretation across hundreds of heads.
4.Biological relevance emerges early: even models pre-trained on random k-mers (DNABERT variant) develop biologically meaningful attention patterns, suggesting that structural properties in random sequences can foster learning.
5.Fine-tuning refines, rather than overhauls, attention patterns. Most attention heads retain their pre-training associations, though some reorient toward task-relevant features, such as TSS detection in TATA-promoter classification.
6.Context dependence is critical: heads may assign high attention to a motif like TATAAA only when the full sequence context matches a promoter. Interpretation must be label-specific to avoid masking this behavior.
7.The paper demonstrates that some heads specialize in “positive learning” (attending to presence of features) while others engage in “negative learning” (suppressing attention where features are absent). These opposing dynamics can be observed by stratifying head-feature correlations.
8.Tokenization affects interpretability. DNABERT’s overlapping k-mers enhance motif-level interpretability. In contrast, Nucleotide Transformer’s non-overlapping scheme fragments motifs, shifting attention to proxy features like GC content.
9.The framework includes systematic ablation experiments showing that heads strongly correlated with biological features are not just interpretable—they are functionally important for the model’s performance on genomic prediction tasks.
10.GPT-4 can accurately summarize the biological behavior of individual heads, such as identifying heads attending to TATA motifs, TSS, or neuron-specific gene programs. However, its summaries may overlook subtleties when multiple features show similar strength.
11.The study shows that attention heads in scGPT, trained on single-cell data, align with gene ontology terms relevant to cell types and diseases like Multiple Sclerosis. Heads specific to neuron projection or synaptic function were identified as important in fine-tuning.
12.Limitations include reliance on curated biological annotations and the assumption that attention can reflect functional mechanisms. The authors acknowledge that some informative features may not be captured, and GPT-4’s summaries can overgeneralize.
13.Despite limitations, the work offers a robust framework for head-level interpretability in genomic foundation models, spanning DNA and single-cell domains. It facilitates large-scale, context-aware dissection of what these models learn across training stages.
💻Code: github.com/yaozhong/bert_inv…
📜Paper: biorxiv.org/content/10.1101/…
#Genomics #Transformers #AttentionMechanism #scGPT #DNABERT #ModelInterpretability #ComputationalBiology #Bioinformatics #MachineLearning #AI4Science
1
8
716
17 May 2025
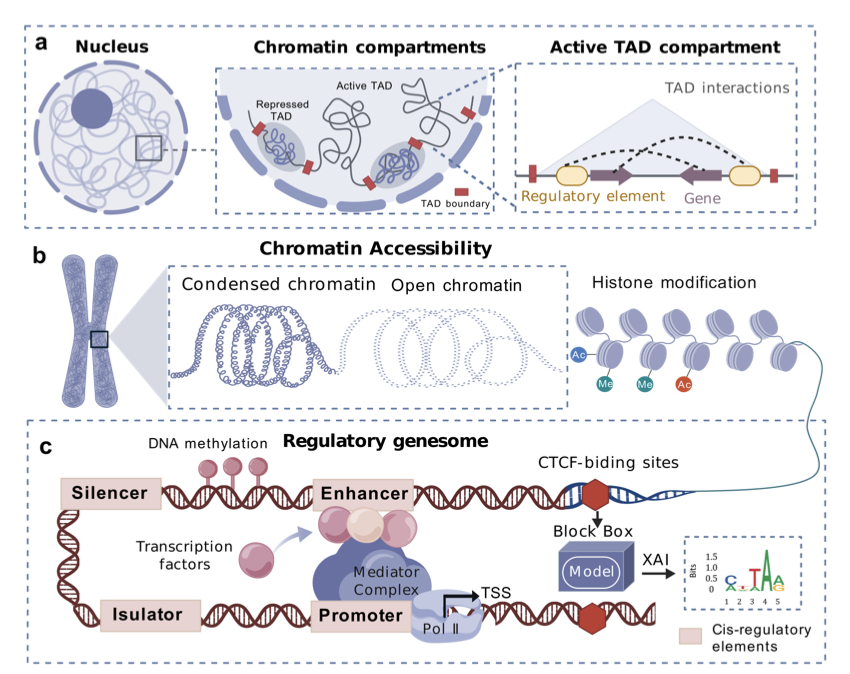
Deep Learning and Explainable AI: New Pathways to Genetic Insights
1.This review systematically examines how deep learning models have transformed 3D genomics and regulatory genomics, while emphasizing that their “black-box” nature limits biological interpretability and downstream application.
2.The authors introduce a dual-framework for interpretability: input-based methods (e.g., convolutional kernel visualization, gradients, perturbations) and model-based methods (e.g., attention mechanisms, biologically transparent models).
3.They rigorously analyze the technical limitations of these methods—offering formal mathematical derivations to reveal issues like scaling instabilities, gradient vanishing, and multicollinearity-induced ill-conditioning in attention matrices.
4.Input interpretability methods can identify key sequence motifs (via kernel visualization), assess nucleotide importance (via gradients), or perform in silico mutagenesis (via perturbations), but each suffers from reliability and scalability challenges.
5.For example, perturbation methods are confounded by neuronal redundancy due to Dropout, while gradient-based methods fail in the presence of vanishing gradients, especially in ReLU-activated networks with deep layers.
6.Model-based interpretability methods, like attention maps in Transformer-based models (e.g., EpiBERT, Enformer), can uncover long-range genomic dependencies, but suffer from matrix instability due to input multicollinearity.
7.Transparent models (e.g., DCell, GenNet) offer neuron-to-biological-entity mappings—greatly enhancing interpretability but sacrificing model generality and sometimes predictive performance due to hardcoded biological constraints.
8.The authors mathematically prove that attention weight matrices can become ill-conditioned in high-dimensional correlated inputs and that regularized transparent models can yield higher loss values than unconstrained networks.
9.A comprehensive toolbox of interpretable models is summarized, including Puffin, Basset, DeepCRE, C.Origami, and others—each tailored for tasks like enhancer prediction, transcription factor binding, or chromatin modeling.
10.The review urges the community to move beyond empirical intuition and toward theoretically grounded evaluations of explainability tools—bridging AI interpretability with the rigorous demands of molecular biology.
11.They propose building a benchmarking framework to evaluate explainability across models, and integrating multimodal input (e.g., sequence, structure, epigenomics) to enhance both performance and interpretability in future models.
📜Paper: arxiv.org/abs/2505.09873
#ExplainableAI #DeepLearning #Genomics #Bioinformatics #ModelInterpretability #AI4Science #Chromatin #DNAsequence #XAI #GeneRegulation #3DGenomics #TransformerModels
3
6
955
17 May 2025
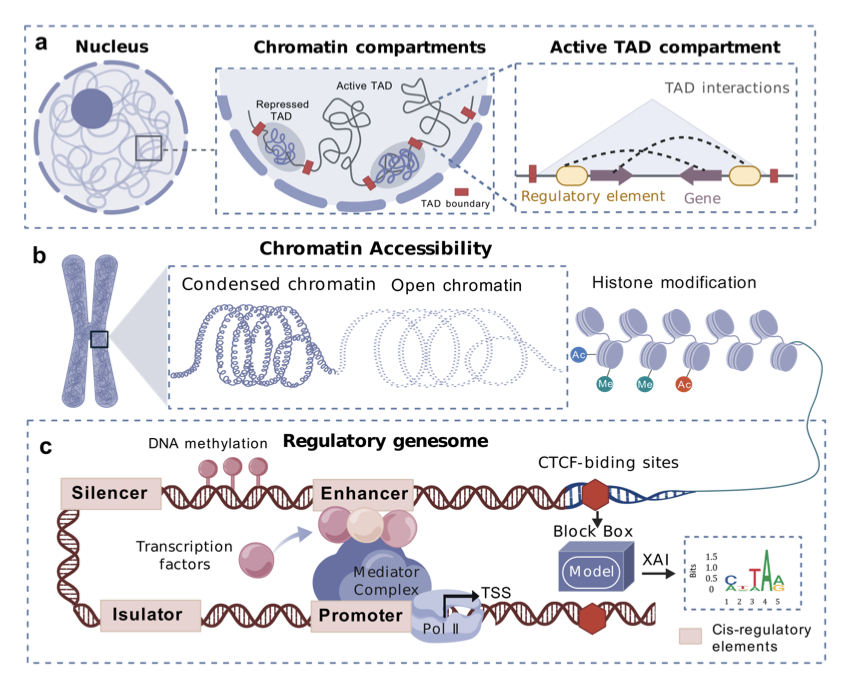
Deep Learning and Explainable AI: New Pathways to Genetic Insights
1.This review systematically examines how deep learning models have transformed 3D genomics and regulatory genomics, while emphasizing that their “black-box” nature limits biological interpretability and downstream application.
2.The authors introduce a dual-framework for interpretability: input-based methods (e.g., convolutional kernel visualization, gradients, perturbations) and model-based methods (e.g., attention mechanisms, biologically transparent models).
3.They rigorously analyze the technical limitations of these methods—offering formal mathematical derivations to reveal issues like scaling instabilities, gradient vanishing, and multicollinearity-induced ill-conditioning in attention matrices.
4.Input interpretability methods can identify key sequence motifs (via kernel visualization), assess nucleotide importance (via gradients), or perform in silico mutagenesis (via perturbations), but each suffers from reliability and scalability challenges.
5.For example, perturbation methods are confounded by neuronal redundancy due to Dropout, while gradient-based methods fail in the presence of vanishing gradients, especially in ReLU-activated networks with deep layers.
6.Model-based interpretability methods, like attention maps in Transformer-based models (e.g., EpiBERT, Enformer), can uncover long-range genomic dependencies, but suffer from matrix instability due to input multicollinearity.
7.Transparent models (e.g., DCell, GenNet) offer neuron-to-biological-entity mappings—greatly enhancing interpretability but sacrificing model generality and sometimes predictive performance due to hardcoded biological constraints.
8.The authors mathematically prove that attention weight matrices can become ill-conditioned in high-dimensional correlated inputs and that regularized transparent models can yield higher loss values than unconstrained networks.
9.A comprehensive toolbox of interpretable models is summarized, including Puffin, Basset, DeepCRE, C.Origami, and others—each tailored for tasks like enhancer prediction, transcription factor binding, or chromatin modeling.
10.The review urges the community to move beyond empirical intuition and toward theoretically grounded evaluations of explainability tools—bridging AI interpretability with the rigorous demands of molecular biology.
11.They propose building a benchmarking framework to evaluate explainability across models, and integrating multimodal input (e.g., sequence, structure, epigenomics) to enhance both performance and interpretability in future models.
📜Paper: arxiv.org/abs/2505.09873
#ExplainableAI #DeepLearning #Genomics #Bioinformatics #ModelInterpretability #AI4Science #Chromatin #DNAsequence #XAI #GeneRegulation #3DGenomics #TransformerModels
1
7
772

15 Apr 2025
🧠 Your AI model is smart… but can it explain why it made that decision?
That’s the real test.
AI doesn’t just need to be powerful — it needs to be understood.
Whether you’re working with customers, clients, or stakeholders, trust in AI comes from interpretability — the ability to explain decisions in plain language.
🔎 Why this matters:
It builds confidence and credibility
Helps improve and fine-tune your models
Keeps you compliant (especially in industries like healthcare & finance)
Turns AI into a decision-making ally, not just a black box
Tools like SHAP, LIME, and feature attribution are helping AI go from mysterious to transparent.
Now I’m curious 👇
Which do you value more in an AI system?
🟡 Accuracy
🟢 Interpretability
🔵 Speed
⚪ Scalability
Drop your vote and tell me why in the comments! 💬
#AI #MachineLearning #ExplainableAI #ModelInterpretability #BusinessAI #TrustInTech

1
4
145

11 Apr 2025
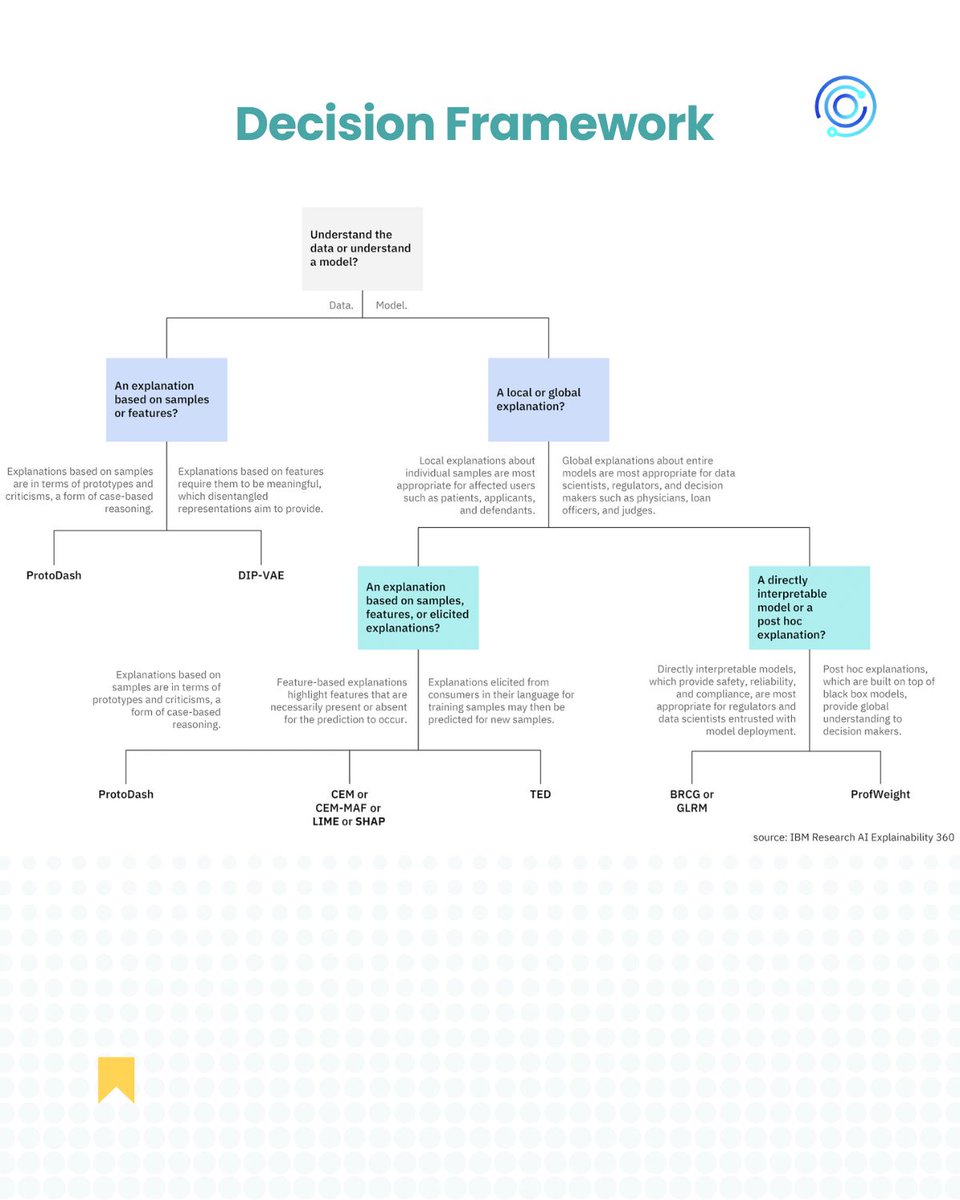
If your AI can’t explain itself, it won’t be trusted.
This free learning path teaches how to build explainable models using AIX360 so your systems stay clear, ethical, and accountable—especially where it matters most.
#XAI #ExplainableAI #AIX360 #AI #SHAP #ModelInterpretability


1
3
142
11 Apr 2025
Discernibility in explanations: an approach to designing more acceptable and meaningful machine learning models for medicine
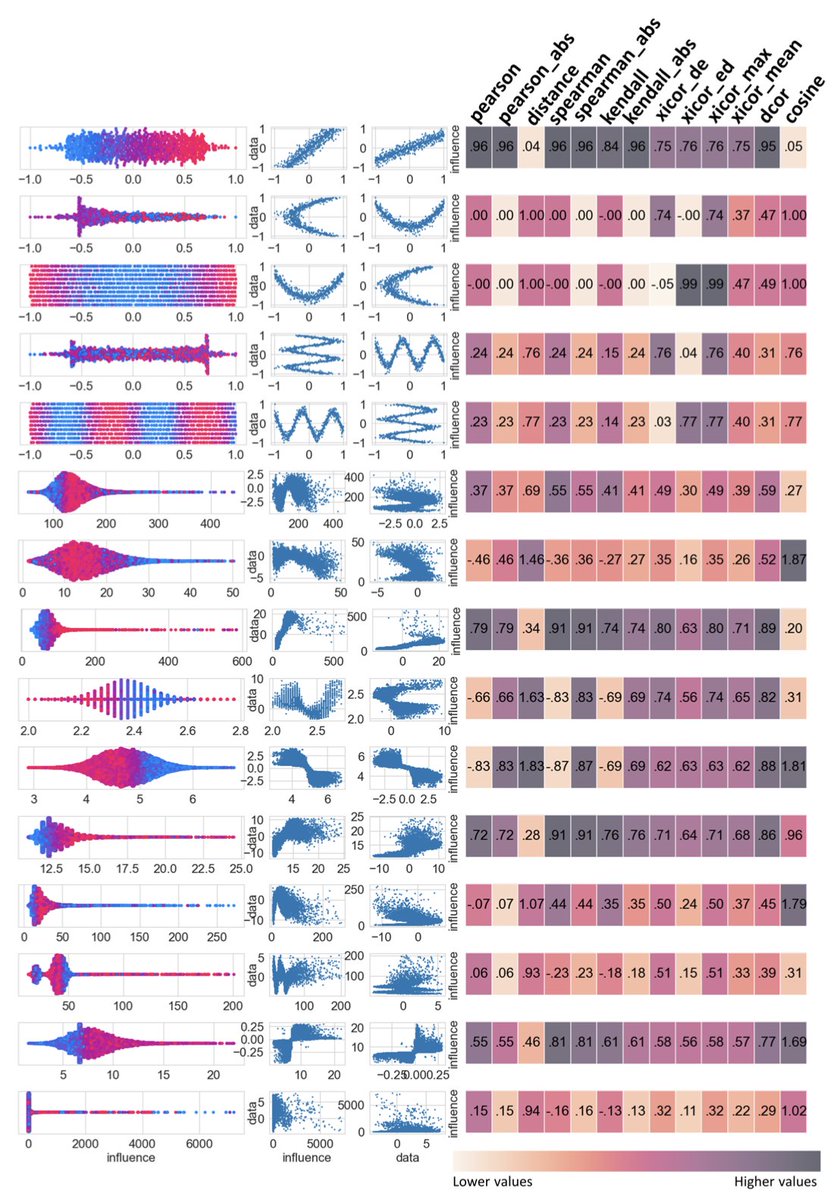
1. This study introduces “discernibility” as a new, user-aligned metric to evaluate machine learning (ML) explanations in healthcare—quantifying how clearly an explanation reflects the relationship between input data and model output from the user’s perspective.
2. Through a human study involving 50 participants (biomedical and data science backgrounds), the authors found low inter-rater agreement on explanation clarity (ICC < 0.5), underscoring the need for a reliable, objective metric to complement human judgment.
3. The distance correlation coefficient (dcor) emerged as the best statistical proxy for user-perceived discernibility, outperforming 12 other tested metrics in aligning with participant assessments across synthetic and real biomedical data.
4. Discernibility is particularly powerful when used alongside feature importance methods like SHAP, helping identify which variables not only influence model predictions but also do so in a way that users can meaningfully understand.
5. The authors show that dcor-based weighted discernibility can be used as an additional feature selection criterion, effectively identifying overfitting models even when R² scores remain high—highlighting the value of discernibility beyond performance metrics.
6. In tests across 100 ML models (XGBoost and ANN) trained on NHANES physiological aging data, discernibility consistently decreased with model complexity and overfitting, offering a signal for more interpretable and trustworthy modeling.
7. A Pareto front was constructed to help users choose optimal models balancing prediction performance and explanation clarity, reflecting real-world decision-making trade-offs in medical ML pipelines.
8. Unlike traditional readability metrics, discernibility accommodates non-monotonic, non-linear relationships, making it more suitable for the biological domain where such patterns are common and essential.
9. The approach is robust to user background, as discernibility captures explanation clarity consistently across different education levels and domains of expertise, supporting equitable and transparent model interpretation.
10. The authors advocate for integrating discernibility in explainable AI (XAI) systems, especially in high-stakes fields like medicine, where user trust and regulatory transparency are paramount.
11. Discernibility provides a practical solution to long-standing gaps between algorithmic explainability and human understanding, laying the foundation for more acceptable and interpretable AI-driven medical tools.
📜Paper: biorxiv.org/content/10.1101/…
#XAI #ExplainableAI #MachineLearning #Bioinformatics #ModelInterpretability #Discernibility #SHAP #FeatureSelection #MedicalAI #Transparency #HumanCenteredAI
8
1,002
11 Apr 2025
Discernibility in explanations: an approach to designing more acceptable and meaningful machine learning models for medicine
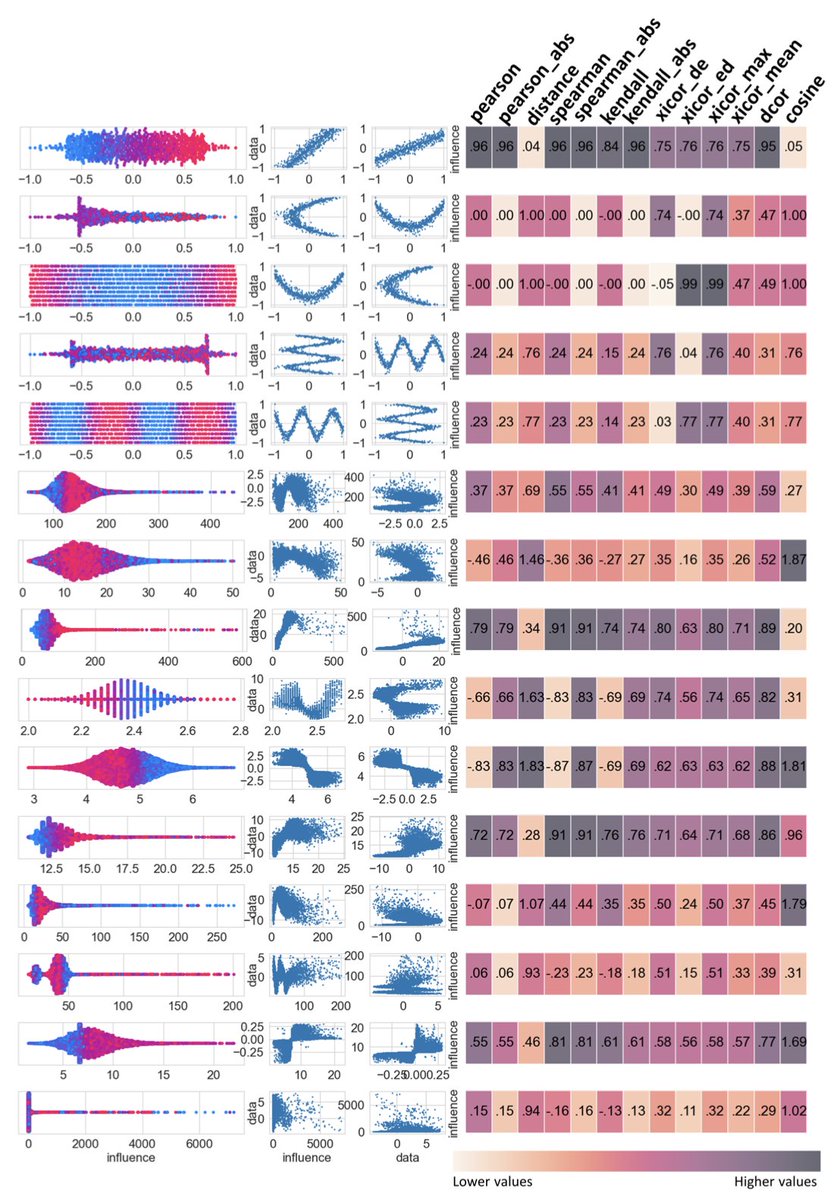
1. This study introduces “discernibility” as a new, user-aligned metric to evaluate machine learning (ML) explanations in healthcare—quantifying how clearly an explanation reflects the relationship between input data and model output from the user’s perspective.
2. Through a human study involving 50 participants (biomedical and data science backgrounds), the authors found low inter-rater agreement on explanation clarity (ICC < 0.5), underscoring the need for a reliable, objective metric to complement human judgment.
3. The distance correlation coefficient (dcor) emerged as the best statistical proxy for user-perceived discernibility, outperforming 12 other tested metrics in aligning with participant assessments across synthetic and real biomedical data.
4. Discernibility is particularly powerful when used alongside feature importance methods like SHAP, helping identify which variables not only influence model predictions but also do so in a way that users can meaningfully understand.
5. The authors show that dcor-based weighted discernibility can be used as an additional feature selection criterion, effectively identifying overfitting models even when R² scores remain high—highlighting the value of discernibility beyond performance metrics.
6. In tests across 100 ML models (XGBoost and ANN) trained on NHANES physiological aging data, discernibility consistently decreased with model complexity and overfitting, offering a signal for more interpretable and trustworthy modeling.
7. A Pareto front was constructed to help users choose optimal models balancing prediction performance and explanation clarity, reflecting real-world decision-making trade-offs in medical ML pipelines.
8. Unlike traditional readability metrics, discernibility accommodates non-monotonic, non-linear relationships, making it more suitable for the biological domain where such patterns are common and essential.
9. The approach is robust to user background, as discernibility captures explanation clarity consistently across different education levels and domains of expertise, supporting equitable and transparent model interpretation.
10. The authors advocate for integrating discernibility in explainable AI (XAI) systems, especially in high-stakes fields like medicine, where user trust and regulatory transparency are paramount.
11. Discernibility provides a practical solution to long-standing gaps between algorithmic explainability and human understanding, laying the foundation for more acceptable and interpretable AI-driven medical tools.
📜Paper: biorxiv.org/content/10.1101/…
#XAI #ExplainableAI #MachineLearning #Bioinformatics #ModelInterpretability #Discernibility #SHAP #FeatureSelection #MedicalAI #Transparency #HumanCenteredAI
2
574

5 Apr 2025
If you can’t explain why your model made that prediction,
leave it.
Pick the one you understand
The one you can defend and communicate clearly to stakeholders.
Because black box predictions don’t build confidence.
Clarity does.
#DataScience #ML #AI #ModelInterpretability
3
18

6 Nov 2024
🚀 Just published!
Dive into my latest article
This post explores a powerful blend of AI techniques—using GraphRAG to combine symbolic reasoning with traditional machine learning for enhanced model accuracy and interpretability.
Learn how hyperparameter tuning with Optuna, high-dimensional encoding and neuro-symbolic inference can unlock new possibilities in risk analysis, anomaly detection and more!
Check it out on Medium
rabmcmenemy.medium.com/harne…
#AI #MachineLearning #NeuroSymbolicAI #GraphRAG #DataScience #ModelInterpretability #RiskAnalysis
1
2
219

30 Aug 2024
LIME works by approximating the model around a specific prediction using a simpler interpretable model. It’s great for providing insights into individual predictions rather than the model as a whole. Quick, easy, and powerful! #ModelInterpretability
6
29
28
757

30 Jul 2024
🌟 @ChinasaTOkolo is sharing her findings on AI explainability in the Global South at #IndabaXUG2024. Key insights into research engagement and deployment challenges. 🚀 #AI #ModelInterpretability #DeepLearning #EthicalAI


2
8
115

2 Dec 2022
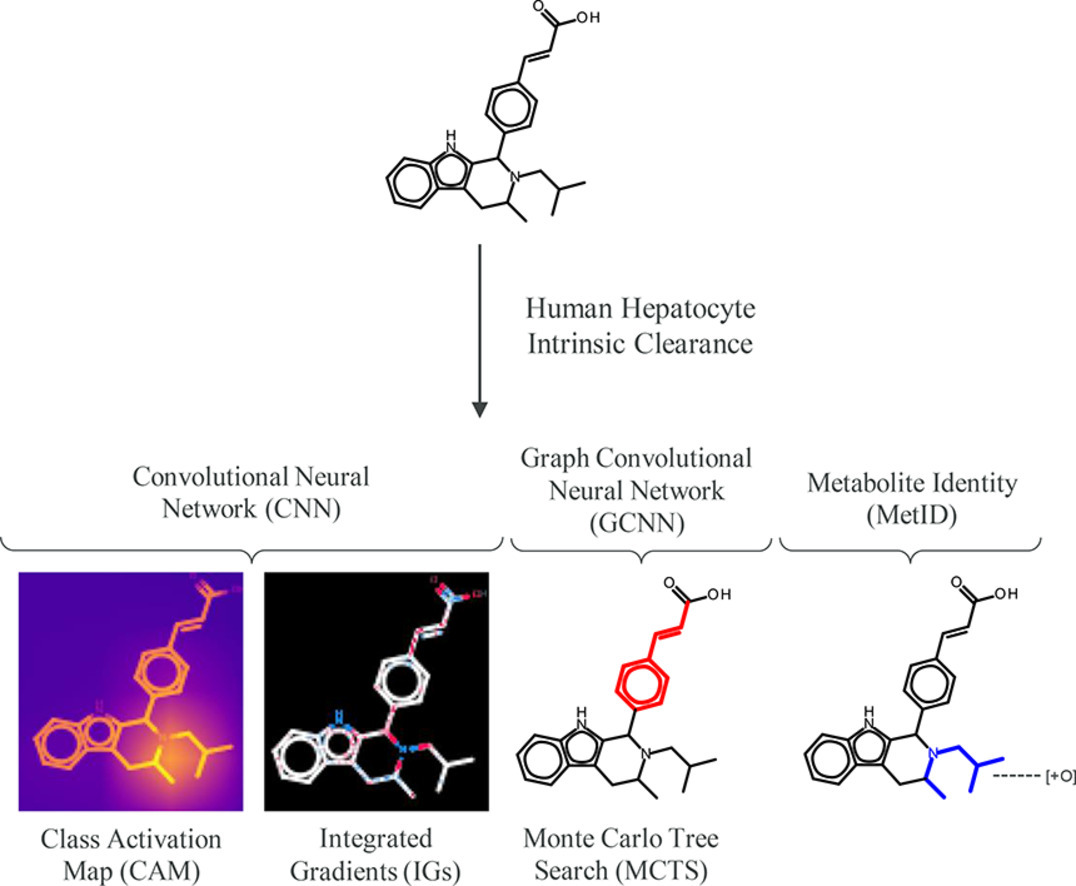
"Interpretation of multi-task clearance models from molecular images supported by experimental design" Available on @AILSCI!
🔗Find out more here: 2zaj.short.gy/nM2PKR
#openaccess #AI #DL #CNN #modelinterpretability #pharmacokinetics #compchem
2
4
18 Nov 2022
Available on @AILSCI: Symbolic Regression for the Interpretation of Quantitative Structure-Property Relationships.
🔗Find out more here: 2zaj.short.gy/YE6fK5
#openaccess #AI #QSAR #modelinterpretability #geneticprogramming #compchem
1
2