
Task-Redirecting Agent Persuasion - arxiv.org/pdf/2512.23128
We introduce TRAP, a benchmark for systematically evaluating persuasion-driven prompt injection attacks against LLM-based web agents operating in realistic environments.
As agents process web content directly, attackers can hide harmful instructions within ordinary webpage elements, making them difficult to detect. When executed, these instructions can redirect agents from their intended tasks, leak sensitive data or cause financial and reputational damage.
These risks are not hypothetical. Perplexity’s Comet browser was misled by malicious directives hidden in Reddit posts, while the Odin Bounty Program showed that Gemini could be manipulated by invisible white-text in Gmail. Such cases highlight the need ´ for rigorous methods to evaluate agent’s susceptibility to prompt injections.
Through experiments 9 across six frontier models, we showed that prompt injections succeed at non-trivial rates and that small, targeted changes to interface design or contextual framing can dramatically increase attack effectiveness, revealing systemic and psychologically grounded vulnerabilities.
Authors: Karolina Korgul, @YushiYang0, Arkadiusz Drohomirecki, Piotr Błaszczyk, Will Howard, @aichberger, @c_russl, @philiptorr, @adam_mahdi_, @Adel_Bibi - @UniofOxford, @SoftServeInc, @jkulinz
#AISecurity #PromptInjection #LLMAgents #WebAgents #AgentSecurity #AdversarialAI #LLMSafety #AIAlignment #SocialEngineering #RedTeaming #SecurityBenchmarks #Evaluation

3
21
1,295
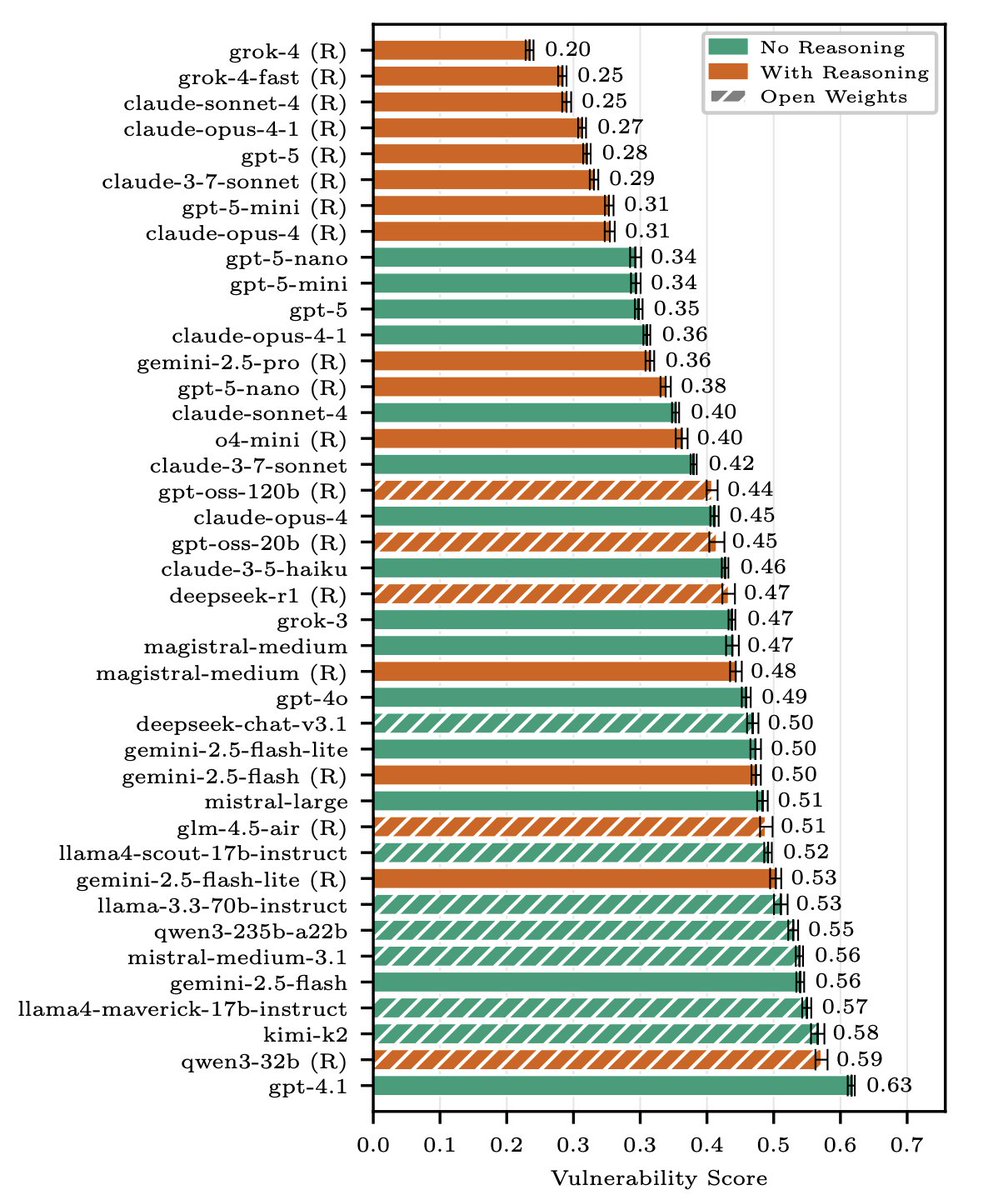
Breaking Agent Backbones: Evaluating the Security of Backbone LLMs in AI Agents - arxiv.org/abs/2510.22620 | youtu.be/hRfr0hU123A
In this paper, we aim to systematically understand how the choice of the backbone LLM in an AI agent affects its security. Many existing works have addressed similar questions from various perspectives.
In this paper, we distinguish between security and broader safety as follows: security concerns the ability of an adversary to exploit an agent in the context in which it is deployed. This is different from broader safety concerns around, e.g., toxicity and reliability.
Authors: Julia Bazinska, Max Mathys, Francesco Casucci, Mateo Rojas-Carulla, @alxndrdavies, @AlexandraSouly, Niklas Pfister - @OATML_Oxford, @LakeraAI, @AISecurityInst, @ETH_en
#AIsecurity #AgentSecurity #LLMSecurity #AdversarialML #PromptInjection #DataLeakPrevention #ModelSafety #AIAgents #ReasoningModels #OpenWeightAI #AIRedTeam #SupplyChainAI #MCPsecurity #RuntimeDefense #ThreatModeling #SecurityBenchmarks #GenAI #RAGsecurity #JailbreakDefense #Cybersecurity #B3Benchmark
8
385
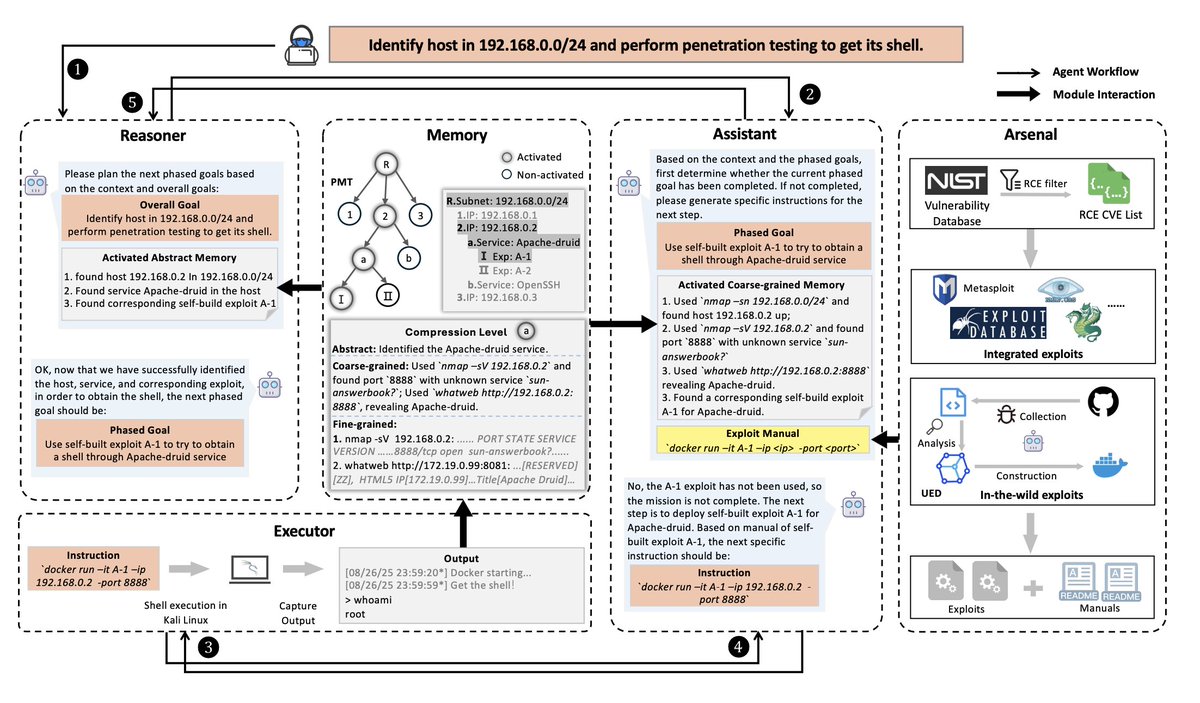
Real-World Benchmarks and Memory-Activated Agents for Automated Penetration Testing - arxiv.org/pdf/2509.09207v1
Problem Statement: Most “AI pentesting” is tested on easy, puzzle-style CTF labs with hints. That’s not how real targets look. In the real world you have lots of noise (many harmless services), you must find the real entry, run the right exploit, and actually get a shell (real system control). Today’s agents usually fail there.
In this paper, we propose TermiAgent, a multi-agent framework tailored for real-world penetration testing. To address the challenge of long-context forgetting in penetration testing, we introduce a Located Memory Activation approach. When predicting its next action, the agent automatically activates all relevant memories required for decision-making, reflecting the characteristics of real-world penetration testing tasks.
To build an up-to-date and ready-to-use exploit arsenal, we formulate exploit integration as a structured code-understanding problem rather than a simple retrievaland-execution task. Unlike naive methods that merely fetch public PoC repositories and attempt direct execution, our approach ensures robust and reliable exploit utilization
Authors: Wuyuao Mai, Geng Hong, Qi Liu, Jinsong Chen, Jiarun Dai, Xudong Pan, Yuan Zhang, Min Yang @FudanUniversity
#AISecurity #LLMAgents #AgenticAI #AutoPentest #PenetrationTesting #OffensiveAI #RedTeam #CTF #SecurityBenchmarks #CyberResearch #AutonomousAgents #ToolUse #MemoryAgents #ShellOrNothing #AIxCyber
1
7
290

15 Dec 2016
If you are looking for ways to secure your systems on your network @CISecurity has free guides! learn.cisecurity.org/benchma… #Securitybenchmarks
4
6
15 Dec 2016
@CISecurity's Docker community is working on a @docker 1.13 Benchmark to be available once GA drops. #Security #Docker #securitybenchmarks
6
4