
Jun 12
On the hidden cost of thinking
"Every private deliberation is counted and priced. You are charged for the pacing in the hallway."
paragraph.com/@internet-of-t…
#LLMs #ArtificialIntelligence #AISafety #ReasoningModels
16

Jun 10
Today I implemented and debugged a Self-Refinement Loop for LLMs inspired by Sebastian Raschka's work.
The pipeline was simple:
→ Generate a draft answer
→ Critique the draft
→ Produce a revised answer
→ Use average token log-probability to decide whether to accept the revision
What surprised me was the outcome.
The model successfully identified that the original answer was wrong and revised it to the correct answer. However, the verifier still preferred the incorrect answer because it assigned higher likelihood to it.
A useful reminder:
Most likely answer ≠ Correct answer
This small experiment helped me better understand one of the motivations behind reward models, verifiers, and RL-based post-training methods.
Notebook link in thread👇
#LLM #AIResearch #MachineLearning #ReasoningModels #PostTraining #RLHF #OpenSourceAI
1
2
58

Jun 10
Why do advanced AI models sometimes pause before answering? That extra thinking time is called Test Time Compute, a breakthrough that's helping AI deliver smarter, more accurate results on complex tasks. Discover how it works. tinyurl.com/3h2rfnxk
#AI #ReasoningModels
6

Jun 9
Pipeline 4: Engineered Reasoning Traces
Reasoning models are only as good as the reasoning they're trained on. And most "reasoning data" in the wild is either thin, post-hoc, or unverifiable.
Pipeline 4 — Engineered Reasoning Traces — produces premium, step-by-step deliberation: explicit decision trees, chain-of-thought scaffolds, self-correction, and multi-step tool-use sequences. Every trace is validated for logical coherence and graded against expert benchmarks.
This is post-training fuel — built for SFT, RLHF, and distillation into smaller models.
We've built domain-specific traces for quant trading decisions, patent claim review, legal reasoning, and risk analysis under the Engineered Reasoning Trace brand.
For post-training and reasoning-model teams: if you're distilling a large reasoner into an SLM, the quality of your trace data is the ceiling on the result.
Want to evaluate a trace set? Reply and I'll share specs.
xpertsystems.ai/
#ReasoningModels #RLHF #Distillation #ChainOfThought
1
27

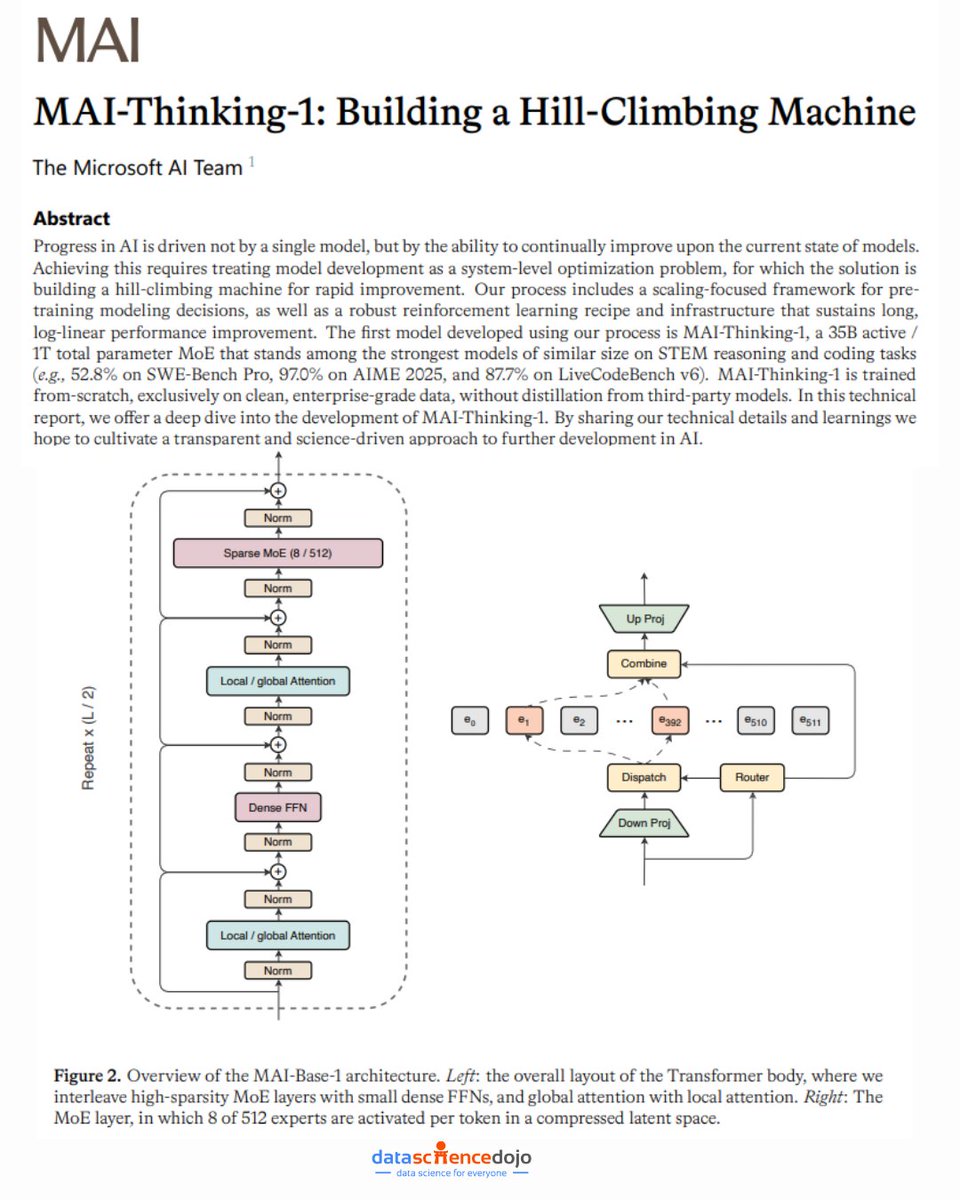
📢 Microsoft just released MAI-Thinking-1 — and the way they built it might matter more than the model itself.
Here's what they found:
- "Capabilities should be learned, not inherited" — they trained entirely from scratch with zero distillation from other models, betting that imitation limits long-term steerability
- A 35B active / 1T total parameter MoE that hits 97.0% on AIME 2025, 94.5% on AIME 2026, and 52.8% on SWE-Bench Pro — elite STEM and coding performance at a mid-size footprint
- RL that runs for thousands of steps — most labs hit a ceiling early; Microsoft built infrastructure specifically to sustain log-linear improvement over the long haul
- Three specialist models, one final model — separate RL climbs for STEM reasoning, agentic coding, and safety/helpfulness, then consolidated into a single deployment model
The core insight is treating model development as a continuous optimization loop — not a one-time training run. They call it a "hill-climbing machine": integrated data pipelines, RL environments, eval suites, and safety tests that turn every decision into a testable, empirical experiment.
What's counterintuitive? They deliberately avoided synthetic data during pre-training and excluded all open-source training datasets. In an era where everyone is recycling model outputs, Microsoft went the other way — 30T tokens of clean, human-generated, enterprise-grade data only.
If this approach scales, it means the next frontier isn't just a bigger model — it's a better process.
#AI #MachineLearning #LLM #ReinforcementLearning #MicrosoftAI #ReasoningModels #AIResearch #MixtureOfExperts #AIBenchmarks #STEM #AgenticAI #TechInnovation
1
4
13
1,195

May 27
THE THESIS
Three of the biggest AI labs just independently cracked Paul Erdős's 80-year-old unit distance conjecture within the same week — and the story isn't that AI can do math now. The story is what the three completely different approaches reveal about where AI reasoning actually is and why your business should stop waiting for "AGI" and start preparing for what's already here.
THE EVIDENCE
OpenAI went first. An unreleased general-purpose reasoning model disproved Erdős's 1946 planar unit distance conjecture — square grids don't maximize unit-distance pairs. The model didn't search known patterns. It pulled algebraic number theory and applied it to elementary geometry. Fields medalist Tim Gowers called it "a milestone in AI mathematics."
Then Anthropic's Claude Mythos solved the same problem with a "cute, simple proof" — a different proof. Shorter. More elegant. Mythos used isolated Claude Code instances working in parallel: one develops solution paths, another summarizes and distributes to independent workers. Mythos also found OpenAI's proof independently.
Then DeepMind's AlphaProof Nexus solved nine Erdős problems in a single sweep, plus 44 unproven OEIS conjectures, for a few hundred dollars in inference. The architecture: four specialized Lean 4 agents (Architect, Coder, Critic, Explorer) managed by an Elo-rated selection loop. Every proof step is mechanically verified by the Lean compiler. No "it looks correct." It compiles or it doesn't.
Here's the detail that matters: AlphaProof's simplest agent design also solved open problems. Just like Google's Antigravity result where Flash beat Pro, the constraint isn't model power. It's architecture.
THE SO WHAT
1) Three labs. Three approaches. Same week. Same problem domain. AI reasoning has crossed a capability threshold. This isn't one lab getting lucky.
2) Formal verification is the trust layer AI has been missing. Lean 4 doesn't care how a proof looks. It compiles or it doesn't. For enterprises in regulated domains, this is the difference between "the AI said so" and "the AI proved it, and a compiler verified it."
3) The $300 proof changes cost expectations. A 56-year-old open problem solved for the cost of a nice dinner. If your organization is budgeting months of senior researcher time for problems AI can formally prove in hours, your cost structure is about to get disrupted.
4) "Simple agent wins too" is the enterprise takeaway. You don't need the biggest model. You need the right verification structure. The gap between "dumb agent with good architecture" and "smart agent with bad architecture" is enormous. Invest in the architecture.
The age of AI-as-calculator is ending. The age of AI-as-researcher is here.
#AIMath #Erdős #ReasoningModels #FormalVerification
1
4
110
May 22
Two days ago, an OpenAI model killed a conjecture Paul Erdős posed in 1946. Not incrementally improved — disproved. The planar unit distance problem, which asks how many pairs of n points can sit exactly one unit apart, was widely assumed to max out near n^(1 o(1)). OpenAI's model produced a 125-page proof showing constructions yielding n^(1 δ) unit-distance pairs for a fixed δ > 0. Will Sawin at Princeton has already tightened that to δ = 0.014. Small number, enormous consequences.
Here's why this is not just another "AI does math" headline — and why the details matter more than the press release.
First, the proof method. Every human attempt on this problem worked inside the geometry toolkit: incidence bounds, crossing numbers, graph theory. The model reached across disciplines into algebraic number theory — infinite class field towers, Golod-Shafarevich theory — and built number fields with rich enough symmetries that, when projected down to the plane, produce far more unit-distance pairs than any grid arrangement. As Thomas Bloom wrote in the companion paper, number theorists will now be taking a hard look at other open problems in discrete geometry. The result doesn't just settle a conjecture; it builds a bridge between two fields that didn't know they needed each other.
That cross-domain leap is the signal, not the headline number. Every organization building with AI should pay attention to the pattern: the model connected ideas across distant domains that human specialists, trained into ever-narrower silos, had no incentive to bridge. Geometry people don't study class field towers. Number theorists don't think about unit distances in the plane. The model doesn't carry that disciplinary baggage. It just searches for what works.
Second, the credibility arc matters. In October 2025, OpenAI's Kevin Weil posted that GPT-5 had solved ten Erdős problems. Thomas Bloom, who maintains the Erdős Problems database, publicly demolished the claim within days — the model had regurgitated known solutions, not produced original proofs. Demis Hassabis called it "embarrassing." Weil left OpenAI in April 2026. So when Bloom appears this time as a co-author on the verification paper, that's not a casual endorsement. That's the person with the most credibility incentive to be skeptical explicitly signing on. Fields Medalist Tim Gowers said he'd recommend the result for the Annals of Mathematics without hesitation. The framework for distinguishing real AI math from promotional noise now has a concrete standard: a named Fields Medalist willing to stake their reputation, co-signed by the researcher who caught the last false claim.
Third, what this doesn't establish. The model hasn't been released. Nobody outside OpenAI can reproduce its approach on related problems. The published paper is the human-cleaned version; how much the polished argument diverges from the raw AI output is an open question that mathematicians will debate for months. Melanie Matchett Wood at Harvard made the most honest observation: had the same nine mathematicians combined their efforts for the time it took them to parse the AI's answer, they likely would have found a counterexample themselves. The tools existed. The approach was accessible in hindsight. The AI found it first — but "first" and "only possible" are different claims.
The real implication for people building with AI right now: the value isn't that AI replaces expertise. It's that AI operates without the path dependencies that make expertise narrow. Every senior engineer has discarded approaches that didn't fit their mental model of the problem. The model hasn't. That's not magic — it's a search advantage that scales with compute and domain breadth. The integration work between that search capacity and human judgment — deciding which results matter, verifying them, understanding their consequences — is where the compounding returns live.
The organizations that figure out how to pair AI's cross-domain search with deep human expertise, rather than treating AI as either a novelty act or a replacement, will build the things that matter next. The Erdős result proves the pattern exists. The execution is still on us.
#AIMathematics #Erdős #ReasoningModels
5
157

May 12
Yapay zekada 'halüsinasyon' dönemi, yerini 'öz-denetim' (self-correction) mekanizmalarına bırakıyor. Artık modeller sadece bir sonraki kelimeyi tahmin etmiyor; cevabı size sunmadan önce kendi mantığını test eden otonom bir 'muhakeme katmanı' çalıştırıyor. Şaka gibi ama makine, hata yapma ihtimalini bizden daha hızlı fark etmeye başladı artık. Bu, yapay zekanın sadece bir bilgi kaynağı değil, gerçek bir 'iş ortağı' olduğu o kritik kilometre taşı...
Hazır mıyız? Emin değilim ama süreç artık durdurulabilecek eşiği aştı. 🤖🧠
#AI2026 #ReasoningModels #FutureOfAI #TheLogos #TechTrends

1
4
201
83,696

Apr 7
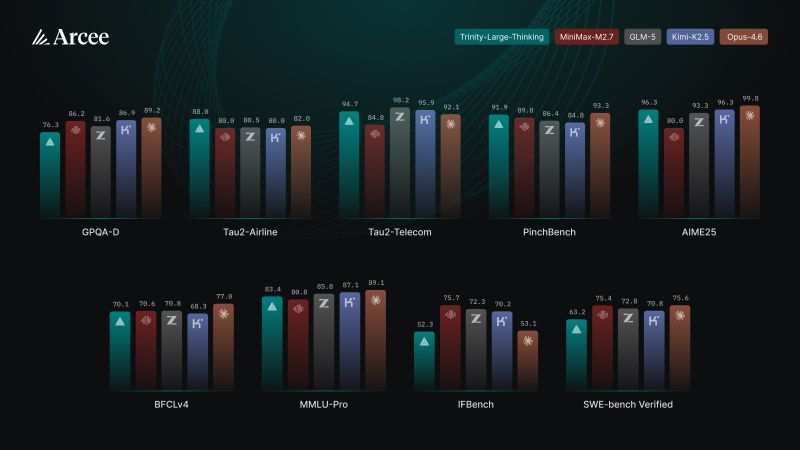
BREAKING🚨: Arcee AI has launched Trinity-Large-Thinking, a 398B parameter sparse MoE model with only about 13B active at a time. It delivers strong performance without heavy computing and is fully open-source under Apache 2.0.
On benchmarks, it is already near the top, ranking #2 on PinchBench at 91.9%, which is a strong signal of how capable open models are getting.
.
.
.
.
.
.
#AIAgents #ReasoningModels #OpenSourceAI #AgenticAI #TechificialAI #BuildingAIthatWorks
1
2
4
227


Mar 31
yeah i wasn’t sure if it worked but. hopefully it’s close enough haha
1
1
3,404

Reasoning-based AI models use stepwise logic, contextual embeddings and refinement-based inference to solve complex tasks, reduce ambiguity and deliver precise, transparent results across science, finance and logistics.
#AI #ReasoningModels #AdvancedAI #ContextualAI

2
4
58

Mar 13
GraphThePlanet is excited to announce another featured speaker for 2026: @aminkarbasi , Sr. Director of AI Research at @Cisco
Talk Topic: Foundation-sec-8B-Reasoning: The First Open-weight Security Reasoning Model
Amin will present new work on open-weight reasoning models designed specifically for security use cases, exploring how specialized models can support more capable analysis and investigation workflows.
Join executives, senior practitioners, researchers, and startup founders for discussions on AI, graph intelligence, and data-driven investigations.
We’re also hosting a small number of in-person Graphistry trainings during the week, including AI for Security: From Copilot to Commander and the Graph Masterclass: Digital Crime Edition.
Event Details:
• Date: RSAC Week 2026
• Location: San Francisco, CA
• Registration & More Info: graphtheplanet.com
• Trainings: louie.ai/trainings
Happy graphing,
— The Graphistry Team
#GraphThePlanet #GTP2026 #RSAC2026 #AIResearch #SecurityAI #ReasoningModels #OpenWeights #GraphIntelligence #CyberSecurity

2
3
1,400

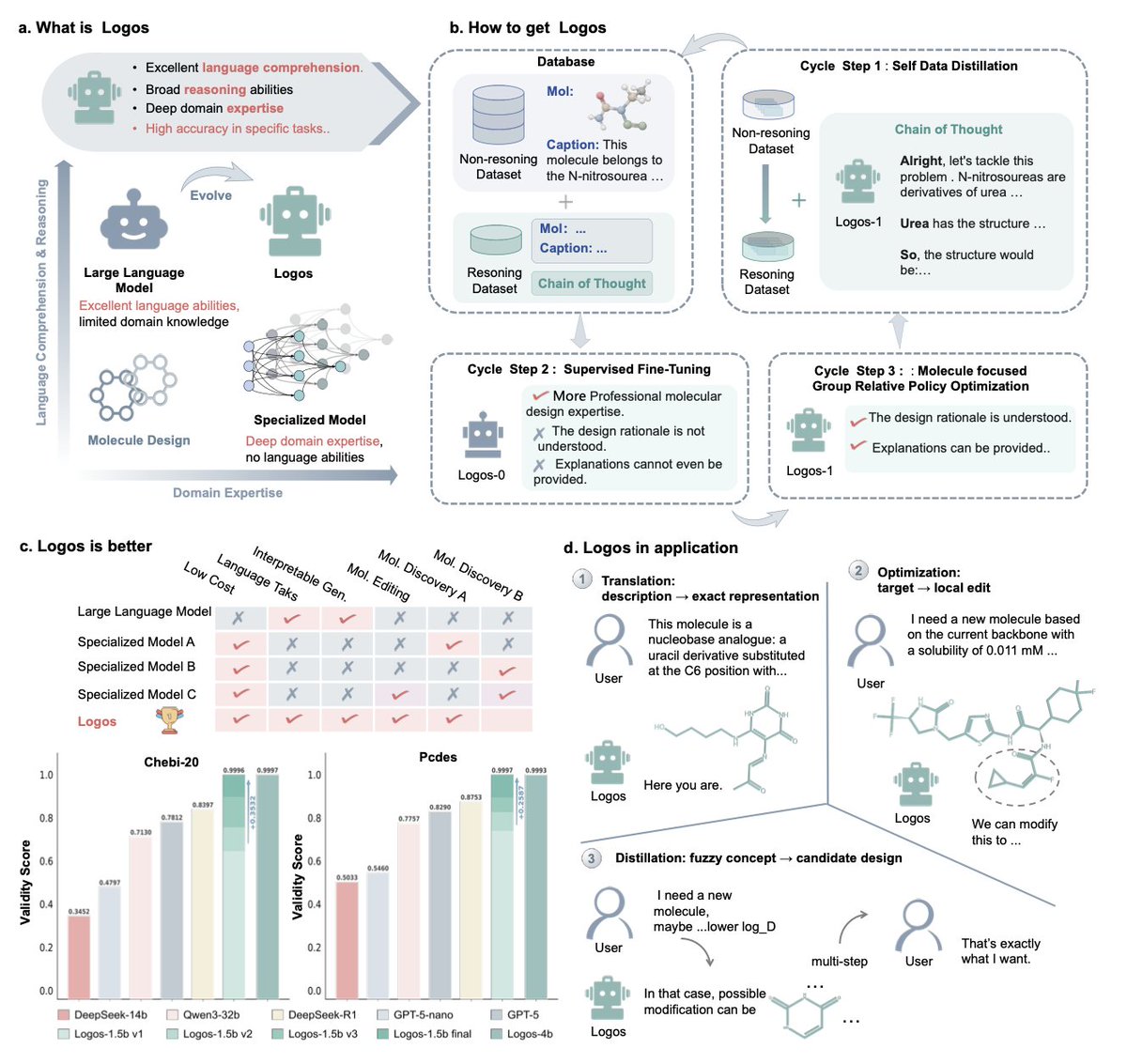
Logos: An Evolvable Reasoning Engine for Rational Molecular Design
1. The authors introduce Logos, a compact 1.5B/4B parameter molecular reasoning model that achieves near-perfect chemical validity (99.96-99.97%) while matching or outperforming much larger general-purpose LLMs like GPT-5 and DeepSeek-R1 on caption-to-molecule benchmarks.
2. The core innovation lies in a three-stage training framework that combines explicit chain-of-thought reasoning with strict chemical consistency: (1) self-data distillation to generate reasoning traces, (2) supervised fine-tuning for reasoning alignment, and (3) molecule-focused group relative policy optimization (M-GRPO) that internalizes chemical rules directly into the reward function.
3. Unlike existing approaches that trade off between physical fidelity and reasoning transparency, Logos integrates multi-step logical reasoning with rigorous chemical validation through RDKit-based rewards, eliminating the need for external post-hoc filters.
4. The model demonstrates strong performance on ChEBI-20 and PCdes datasets, with Logos-4B achieving exact match scores of 0.5588 and 0.5047 respectively, significantly surpassing GPT-5's 0.2467 and 0.3023.
5. Beyond benchmarks, Logos enables interactive multi-objective molecular optimization with human-in-the-loop feedback, successfully navigating conflicting constraints such as lipophilicity (log D7.4) and solubility while exposing its reasoning for inspection.
6. The evolutionary training mechanism includes an iterative bootstrapping procedure where the model generates and filters its own reasoning for previously failed samples, progressively expanding high-quality training data without manual annotation.
7. A key limitation acknowledged is the trade-off between inference latency and auditability: the explicit reasoning trace increases token generation time, making Logos better suited for precision-driven workflows than high-throughput virtual screening.
💻Code: github.com/LogoMol/Logos
📜Paper: arxiv.org/abs/2603.09268
#MolecularDesign #Chemoinformatics #AIforScience #DrugDiscovery #MachineLearning #ReasoningModels #ReinforcementLearning #ComputationalChemistry
1
5
21
1,875

Mar 10
LEARN AI. Start here with these 42 short videos covering the basic terms you need to know. They’ll help you understand AI and how the technology works at a level that will put you ahead of 99% of people.
@towards_AI
@Whats_AI
#BuildForTheFuture #TheFutureIsNow
#GenerativeAI #LLMs #Tokens #Embeddings
#LatentSpace #Parameters #PreTraining
#BaseModelsVsInstructModels #FineTuning
#Alignment #RLHF
#SystemPromptVsUserPrompt
#ContextWindow
#ZeroShotVsFewShotLearning
#ReasoningAndCoT #Inference #Latency
#TemperatureAndDeterministicVsStochasticOutputs
#GroundingAndRAG #WorkflowVsAgent
#AgeneticAI #ProprietaryVsOpenSourceModels
#API #SLM(Small Language Models)
#KnowledgeDistillation #ModalityAndMultimodality
#ReasoningModels #Benchmarks #Metrics
#LLMAsTheJudge #Hallucination
#PoorMathematicalAndLogicalReasoning
#InherentBias #KnowledgeCutoff
#GuardrailsAndSafetyFilters
#PromptInjectionPromptHacking
#PreferenceTuning #RLAIF #RLVR
#SelfConsistency #ModelEnsembling
#AddressingFailures
youtube.com/playlist?list=PL…
3
2
430
📢 OpenAI just published research arguing that AI models being bad at something is actually a safety feature.
The finding: reasoning models can barely control their own chain-of-thought — the internal reasoning trace visible before a final answer. Claude Sonnet 4.5 managed it only 2.7% of the time. When researchers told models to solve a problem without using a specific word in their thinking, they failed, panicked about failing in their own reasoning, and kept failing anyway.
That inability is exactly what makes CoT monitoring work as a safety tool. If a model can't control what it thinks out loud, it can't hide misaligned intentions from human oversight either.
The caveat the paper buries slightly: they don't actually know why models fail at this. It may be a training artifact rather than something fundamental — and larger models already show higher controllability than smaller ones, which points in a concerning direction as scaling continues.
So OpenAI's position is essentially: the dangerous capability doesn't exist yet, and we're cautiously relieved. The recommendation is that frontier labs start tracking this metric now, before that changes.
So what does this mean for you?
If you're building with reasoning models — or evaluating them for high-stakes use cases — CoT monitoring is one of the more credible safety levers available right now. It works partly because of a limitation that may not last. That's worth building around while it holds, and worth watching closely as next-generation models ship.
The gap between "we don't know why this works" and "we're confident it will hold" is where the real safety question lives.
Do you think AI safety should rely on model limitations — or do we need harder guarantees before deploying these systems in critical infrastructure?
#AgenticAI #LLMSafety #AIAlignment #ReasoningModels #AIEngineering

2
6
10
1,033

Mar 6
Speed matters in reasoning.
If your model takes too long to think, it can’t operate in real time.
@justkharbanda shares how diffusion reasoning models deliver 5x faster pipelines and higher engineering output.
→ Learn more: inceptionlabs.ai
→ Open roles: inceptionlabs.ai/careers
#Diffusion #AIInfrastructure #ReasoningModels
1
3
47
4,970

🧠 Los modelos de razonamiento no controlan su cadena de pensamientos, y eso es bueno
OpenAI presenta CoT-Control, un hallazgo clave para la seguridad de la IA.
openai.com/index/reasoning-m…
#ReasoningModels #AISafety #CoT #RoxsRoss
1
2
93

Mar 5
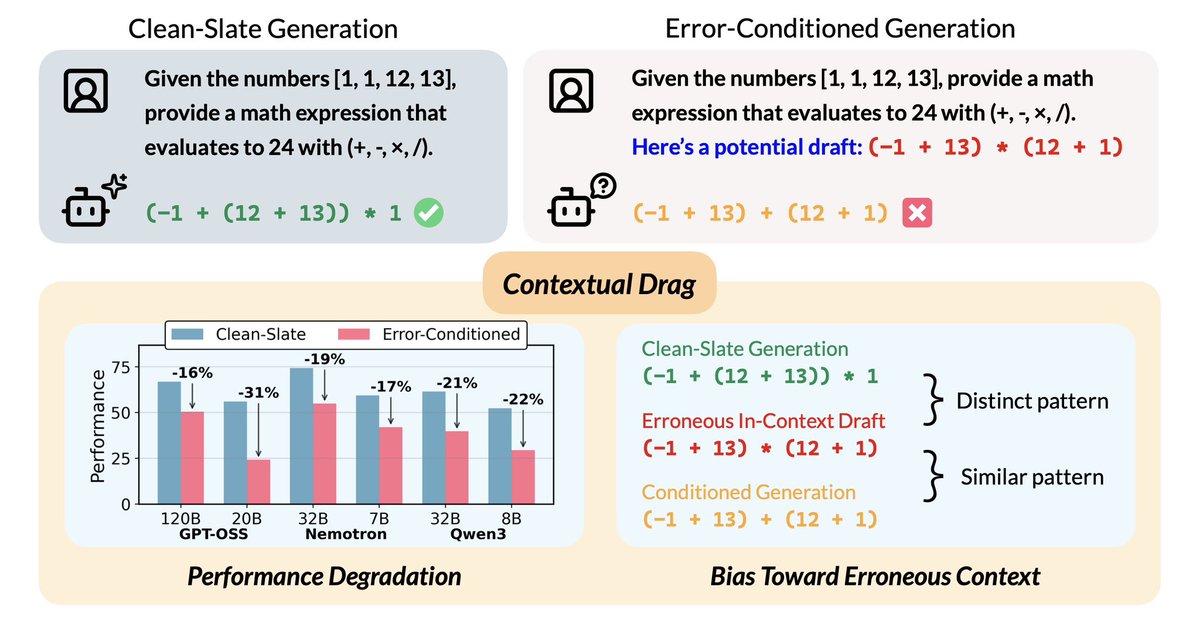
Presenting CONTEXTUAL DRAG 🚨
Humans could benefit from incorrect previous attempts and avoid making the same mistakes, but reasoning models are dragged toward similar errors (even when explicitly knowing the attempts are incorrect!)
Work @PrincetonPLI
#LLM #ReasoningModels
Mar 5

Humans anchor on the first piece of information they receive. Do reasoning models escape this bias?
We uncover Contextual Drag: errors in context bias subsequent reasoning toward similar mistakes.
It persists even if the error has been recognized via reasoning.
4
295

Mar 2
🧠 A big shift is underway in AI, from fast next-word prediction to reasoning models that map out logic step by step.
In this video, I explain:
✅ What reasoning models are, and why they matter
✅ How “pause and think” improves reliability on complex problems
✅ Why reasoning helps in research, law, analysis, and complex coding
✅ What self-checking means, spotting mistakes before output
✅ Why this opens the door to higher-stakes business decision-making
This is a move toward AI that handles complex logic with far more confidence.
#AI #ReasoningModels #MachineLearning #GenAI #DecisionMaking #AIinBusiness #TechnologyTrends #Innovation
1
2
6
672