
28 Jun 2025
In the last ~6 months more closely analyzing the open models and datasets of note across the community on @huggingface, we've highlighted artifacts from 141 different organizations.
It takes many people to build the open ecosystem for AI.
ACE-Step
AI-MO
AIDC-AI
ASLP-lab
Alpha-VLLM
AtlaAI
BAAI (4)
BLIP3o
ByteDance (3)
ByteDance-Seed (4)
CYFRAGOVPL
CohereLabs (5)
DataoceanAI
DatologyAI (2)
Datou1111
Etched
EuroBERT
Freepik (2)
GSAI-ML
Goedel-LM
Hcompany
HelloKKMe
HiDream-ai
HuggingFaceTB (3)
ICTNLP
JetBrains
LGAI-EXAONE
LLM360 (2)
MiniMaxAI (2)
NX-AI
NexaAIDev
Nexusflow
NousResearch
NovaSky-AI (2)
Open-Reasoner-Zero
OpenGVLab
OpenPipe
OuteAI
POLARIS-Project
PRIME-RL
PeterJinGo
PlayHT
PleIAs (2)
PrimeIntellect (2)
Qwen (15)
RekaAI
Salesforce (2)
Skywork (6)
Snowflake
SparkAudio
StarJiaxing
SultanR
THUDM (3)
TIGER-Lab
UCSC-VLAA
UW-Madison-Lee-Lab
Wan-AI (3)
WisdomShell
XiaomiMiMo (2)
Xkev
Zyphra (2)
agentica-org (2)
ai21labs
all-hands
allenai (5)
allura-org
amd (3)
answerdotai
apple
arcee-ai (6)
arcinstitute
bespokelabs
canopylabs
cl-nagoya
convergence-ai
deepcogito
deepseek-ai (9)
ds4sd
echo840
facebook (3)
fdtn-ai
featherless-ai
fishaudio
genmo
google (9)
haizelabs
hexgrad
hkust-nlp
hpcai-tech
ibm-granite (9)
inclusionAI (4)
infgrad
internlm (5)
kuleshov-group
kyutai (4)
laion (2)
lerobot
lightonai
m-a-p
marin-community
maya-multimodal
meta-llama (2)
metagene-ai
microsoft (7)
mistralai (6)
mixedbread-ai
mobiuslabsgmbh
moonshotai (4)
nanonets
nllg
nomic-ai (3)
nvidia (18)
open-r1
open-thoughts
openbmb (3)
opencompass
osmosis-ai
ostris
perplexity-ai
qihoo360
rednote-hilab
reducto
rhymes-ai (3)
ruliad
sand-ai
sarvamai
sesame
si-community
simplescaling
stabilityai (2)
stepfun-ai (4)
tencent (3)
thomas-sounack
tiiuae (2)
tngtech
tomg-group-umd
vidore (2)
vikhyatk
xlr8harder
yentinglin
zed-industries
1
10
22
5,881

5 Mar 2025
今は、下記のhugging faceに公開されているデータセット
kanhatakeyama/AutoMultiTurnByCalm3-22B
Elriggs/openwebtext-100k
fujiki/wiki40b_ja
と、Qwen32Bで日々増産中の合成データセットで学習トライしてます。
あとは、使えそうなデータセットとして、
open-r1/OpenR1-Math-220k
open-thoughts/OpenThoughts-114k
simplescaling/data_ablation_full59K
open-thoughts/OpenThoughts-114k
simplescaling/s1K-1.1
GeneralReasoning/GeneralThought-195K
あたり。
1
3
85

12 Feb 2025
Open source can plausibly beat the labs to AGI/ASI (for some definition of those terms), in the open, over the Internet. While there are still details to work out:
The flywheel is simply RL on many hard problems with verifiable outcomes.
* Writing verifiers, searching for excellent rollouts, and refining them are all embarrassingly parallel.
* There is more compute and software engineering talent outside of the labs than within them.
* @PrimeIntellect has already built and validated the data generation half of the flywheel. Their community of compute volunteers has produced and gifted 2M verified reasoning traces (2.5x what DeepSeek used for R1-Distilled) already.
This unlocks bushels of low hanging fruit. Nearly anyone can accelerate the open source flywheel by working out any of the following:
1. Reasoning data selection
To date: LIMO and simplescaling 1.1 both find that ~1k carefully selected reasoning traces from R1 are sufficient to distill reasoning capability into Qwen2.5-Instruct models.
Careful selection to date has meant filtering for hard problems by filtering out problems the instruct model can already solve, and sampling for diversity. But there is more to do:
A. Ensure the reasoning traces are in-distribution wrt the student by filtering samples for low loss. Just about every post-training paper of note published in the last year finds that in-distribution data is a big deal, including arxiv.org/pdf/2502.04194 and arxiv.org/abs/2502.02797, this is almost certainly going to work. But it needs to be validated, thresholds need to be determined, and if there is a curriculum learning play (like easier samples first), of course that would be good to know.
B. Filtering may be done at token scale: with human data, if one masks high-loss tokens to spare the model OOD tokens (cf. arxiv.org/abs/2501.14315), ~3/4 of the performance hit from human data goes away. This simple hack might well work for synthetic data, too. But the threshold will be important to find.
C. Prompts may be filtered for quality by looking at the variance in output reward, cf arxiv.org/abs/2501.18578. It's unclear if this applies to traces with verified outcomes, but it probably at least applies to the rest of the post-training mix.
2. Distillation data refinement
A. Pruning
Reasoning traces are often long and sloppy, which is slow, expensive, and gratingly neurotic for the user at inference time. At least one paper (arxiv.org/pdf/2501.12570) shows efficiency and accuracy benefits to pruning reasoning traces.
The targets here ought to be length (shorter is faster/cheaper), loss on the target model to distill (lower loss samples limit harm to base model's distribution), and accuracy (the final answer must remain correct).
B. Establish pruning limits / pivot token data mixing laws.
One risk of pruning reasoning traces is the loss of pivot tokens. Student models presumably need to see some of these!
So, the optimal pruning vs. pivot token mix needs to be determined. Determining where it is most beneficial to leave them (perhaps more difficult prompts) will also be high value.
B. Re-writing reasoning traces for low loss
Distillation reasoning traces are by definition off-policy for the student. As such, they are liable to be out of distribution, which is Bad.
We can fix this by re-writing high loss portions of reasoning traces with a FIM model, then verifying semantic equivalence and lower loss on the target model.
It may even be possible to do this very cheaply with @jeremyphoward's ModernBert: use masked language modeling (like this: x.com/jeremyphoward/status/1…) to swap out tough tokens, and use distance of the embeddings for the original vs. modified sentences to estimate semantic equivalence.
C. Reasoning condensation
<thinking> tokens are neat, but sometimes they're overkill, and many (e.g., Dario) do not find them aesthetically pleasing.
If and when is it constructive to integrate them into the answer with a more normal CoT (like Claude)?
This seems particularly promising in cases where (say) an instruct version of a student model can answer the question correctly (so you would filter the question out if tuning from that instruct model), but you are starting fresh with the base model and want more verifiably correct instruct data in your SFT or midtraining mix.
D. Persona reasoning
Right now, R1 and its distillates think in slop. It will be much nicer for many purposes if reasoning models <think> in character. e.g., if my System Prompt says the model is Captain Ahab, "OK, the User wants me to pretend to be Captain Ahab, I should care about this whale," is lame, "I'll follow him around the Horn, and around the Norway maelstrom, and around perdition's flames before I give him up" is much more interesting -> likely to yield better results any time vibe is important (like creative writing) or the persona's particular reasoning patters are at issue.
3. Determine prerequisites for reasoning distillation:
Qwen2.5-Instruct models, which were mid-trained on lots of synthetic data, require less than 1,000 examples to learn long chain of thought (cf LIMO & simplescaling).
True base models require more than 1,000 examples, but no more than 800k examples (used in R1-Distilled). Dialing in filtered and SFT and midtraining datasets is going to be a big deal.
Now that the gains for post-training small to medium sized models are huge again, it's an ideal time to dial this in. Tulu 3 is the data mix to beat with clearer prompts (arxiv.org/abs/2501.18578), unencumbered data, and in-distribution rollouts of exemplary quality (cf arxiv.org/abs/2502.01697, arxiv.org/abs/2412.04305, and arxiv.org/pdf/2411.08733 for ideas)
4. Demystify the unreasonable effectiveness of DoRA.
.@winglian found that DoRA speeds up finetuning for reasoning by *a lot*. LoRA too --but not as much. Nobody knows why, but there's a quick and easy hypothesis to test: maybe FT is slower than LoRA is slower than DoRA because fewer weights are modified.
If so, we would expect @DiLuo28's QuanTA (high-rank extremely sparse PeFT method) to be even better. This is extremely quick to test.
5. Build simple test-time compute levers.
The simplescaling folks (@Muennighoff et al) validated and wrote up something @_xjdr, @voooooogel, and others tweeted:
One can simply insert pivot tokens and forbid end-of-thinking tokens to force the model to reason longer.
The obvious next step for scaling TTC economically is branching on pivot tokens. i.e., if the model wants to 'wait', spawn a branch where that is replaced by an end-of-thinking token (or vice versa).
The other obvious thing is running multiple streams in parallel (which is reportedly what O1-Pro is doing).
From there, you need some means of selecting or aggregating one's responses. Majority voting, fuzzy majority voting via clustering embeddings, shortest-of-n, and selection via reward model have all been shown to work in some settings. They ought to be refined and compared.
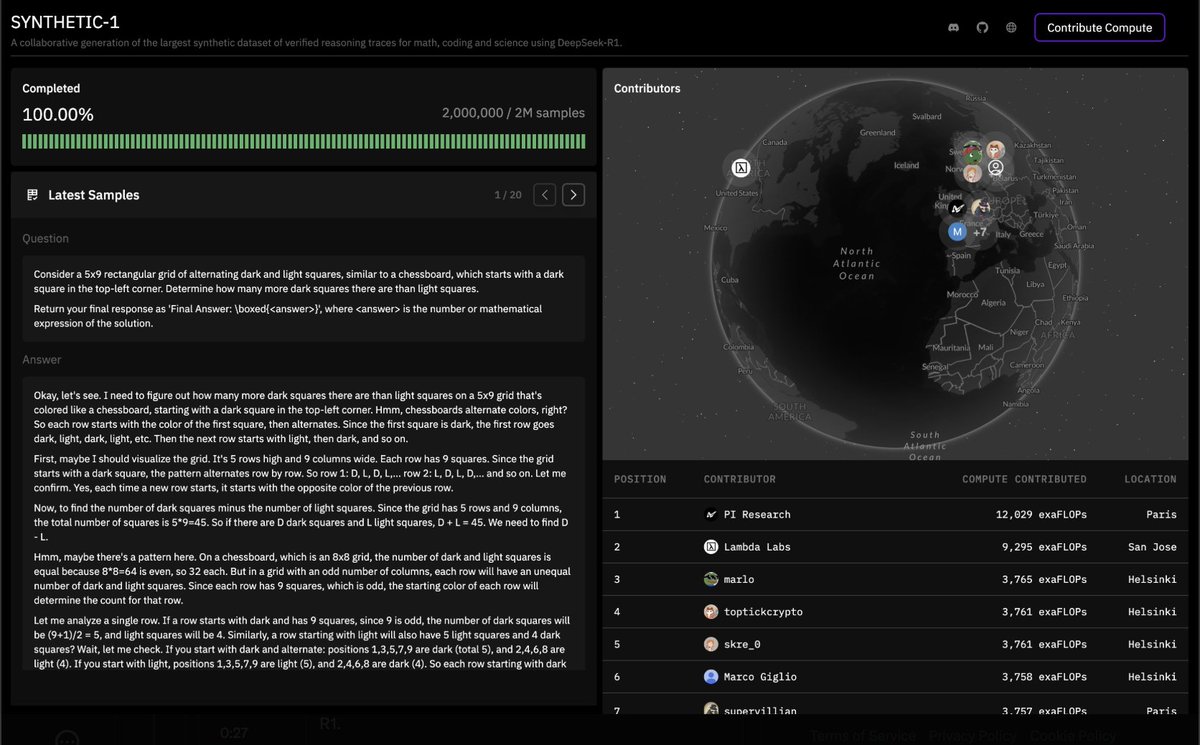
10 Feb 2025

so many synthetic data projects need inference. I"m sure @georgejrjrjr could name a half dozen. :)
1
9
81
8,134

9 Feb 2025
𝑨𝒘𝒆𝒔𝒐𝒎𝒆 𝒑𝒓𝒐𝒋𝒆𝒄𝒕🔥.𝑰'𝒎 𝒅𝒆𝒇𝒊𝒏𝒊𝒕𝒆𝒍𝒚 𝒊𝒏𝒕𝒆𝒓𝒆𝒔𝒕𝒆𝒅 𝒊𝒏 𝒕𝒉𝒊𝒔 𝒑𝒓𝒐𝒋𝒆𝒄𝒕📷.𝑺𝒆𝒏𝒅 𝒎𝒆 𝒎𝒆𝒔𝒔𝒂𝒈𝒆 𝒑𝒍𝒆𝒂𝒔𝒆📷 📥.
5
9 Feb 2025
𝑨𝒘𝒆𝒔𝒐𝒎𝒆 𝒑𝒓𝒐𝒋𝒆𝒄𝒕🔥.𝑰'𝒎 𝒅𝒆𝒇𝒊𝒏𝒊𝒕𝒆𝒍𝒚 𝒊𝒏𝒕𝒆𝒓𝒆𝒔𝒕𝒆𝒅 𝒊𝒏 𝒕𝒉𝒊𝒔 𝒑𝒓𝒐𝒋𝒆𝒄𝒕📷.𝑺𝒆𝒏𝒅 𝒎𝒆 𝒎𝒆𝒔𝒔𝒂𝒈𝒆 𝒑𝒍𝒆𝒂𝒔𝒆📷 📥.
2
9 Feb 2025
𝑨𝒘𝒆𝒔𝒐𝒎𝒆 𝒑𝒓𝒐𝒋𝒆𝒄𝒕🔥.𝑰'𝒎 𝒅𝒆𝒇𝒊𝒏𝒊𝒕𝒆𝒍𝒚 𝒊𝒏𝒕𝒆𝒓𝒆𝒔𝒕𝒆𝒅 𝒊𝒏 𝒕𝒉𝒊𝒔 𝒑𝒓𝒐𝒋𝒆𝒄𝒕📷.𝑺𝒆𝒏𝒅 𝒎𝒆 𝒎𝒆𝒔𝒔𝒂𝒈𝒆 𝒑𝒍𝒆𝒂𝒔𝒆📷 📥.
2

9 Feb 2025
Hello! Your project is amazing.
Let's collaborate🚀, Follow me or send me DM 📥 please
8

Business Bites sponsored by @InvestNI, @davidctighe talks to Brendan McGurgan, co-founder of Simple Scaling. They discuss the forthcoming ScaleX Summit.
To find out more click here: youtu.be/XjnyoDV1cFA
#BussinessBites #InvestNI #ScaleXSummit #SimpleScaling
150

16 Jan 2023
Listen to my SimpleScaling Ltd. podcast interview with the great Brendan McGurgan about how to create a high-performance business.
youtube.com/watch?v=VZHhhGO-…
2
104

23 Feb 2022
Join us at the BRA Alumni Association - Business Breakfast Club on Tue 29th Mar at 7.30am in Ten Square, Belfast. Speaking will be Steven Johnston, MD of @adhausmedia and Claire Colvin, Director of SimpleScaling eventbrite.co.uk/e/bra-alumn… @Eventbrite

1
3

12 Jan 2022
I'm on the latest SimpleScaling podcast episode! 🎙
I discuss my purpose journey in @Unilever, the @Brandsonmission Purpose Tree and how brands are pursuing business growth and social impact through purpose.
It's out on all major platforms. I'd love to hear your thoughts! 💬

2
14

24 Sep 2020
Simple Scaling 17
Check out more Simple Scaling at dankham.com/simple-scaling
Request any animals you want to see in the future
#comic #comics #animal #animals #science #banana #dankham #simplescaling #rhino #rhinos #cassowary #bird #white_rhinoceros

2
2
17 Sep 2020
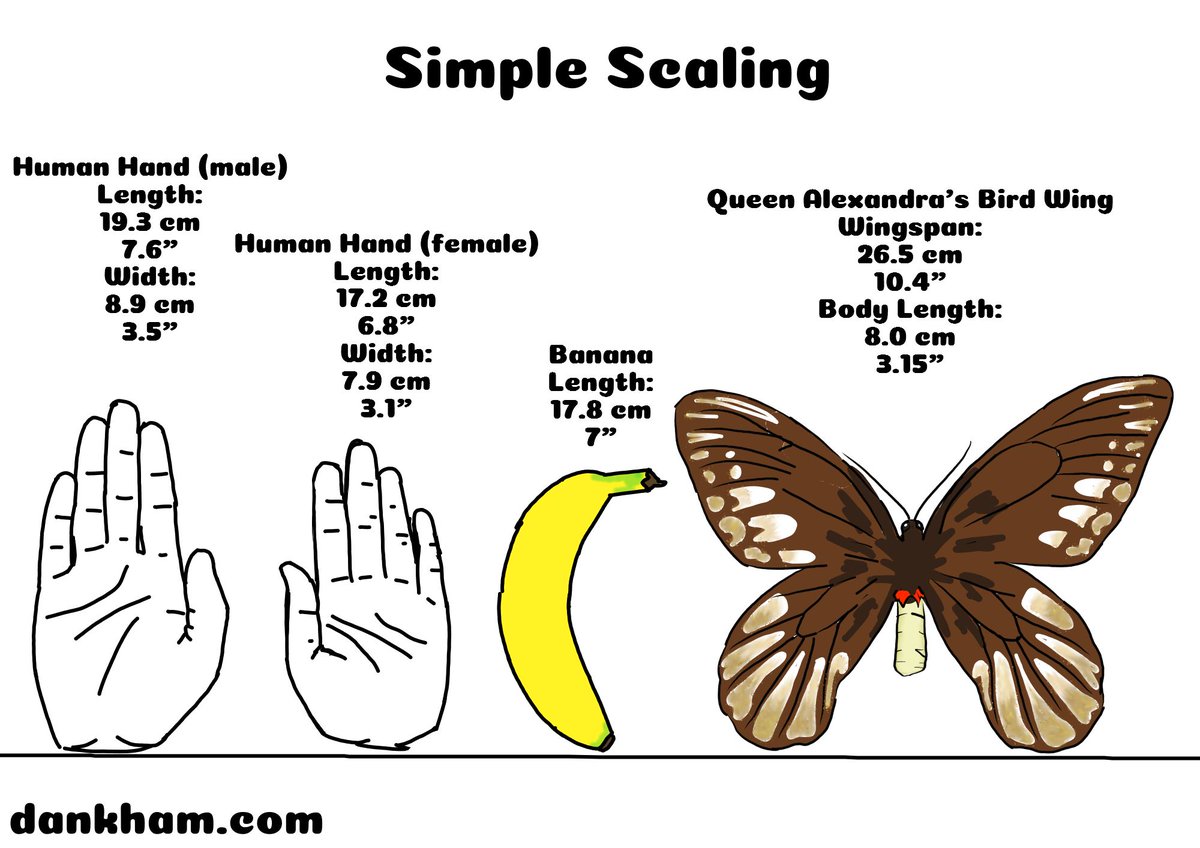
Simple Scaling 16
Check out more Simple Scaling at dankham.com/simple-scaling
Request any animals you want to see in the future
#comic #comics #animal #animals #science #banana #dankham #simplescaling #insect #insects #butterfly #biggest #QueenAlexandrasBirdwing #bug #bug
1
3
11 Sep 2020
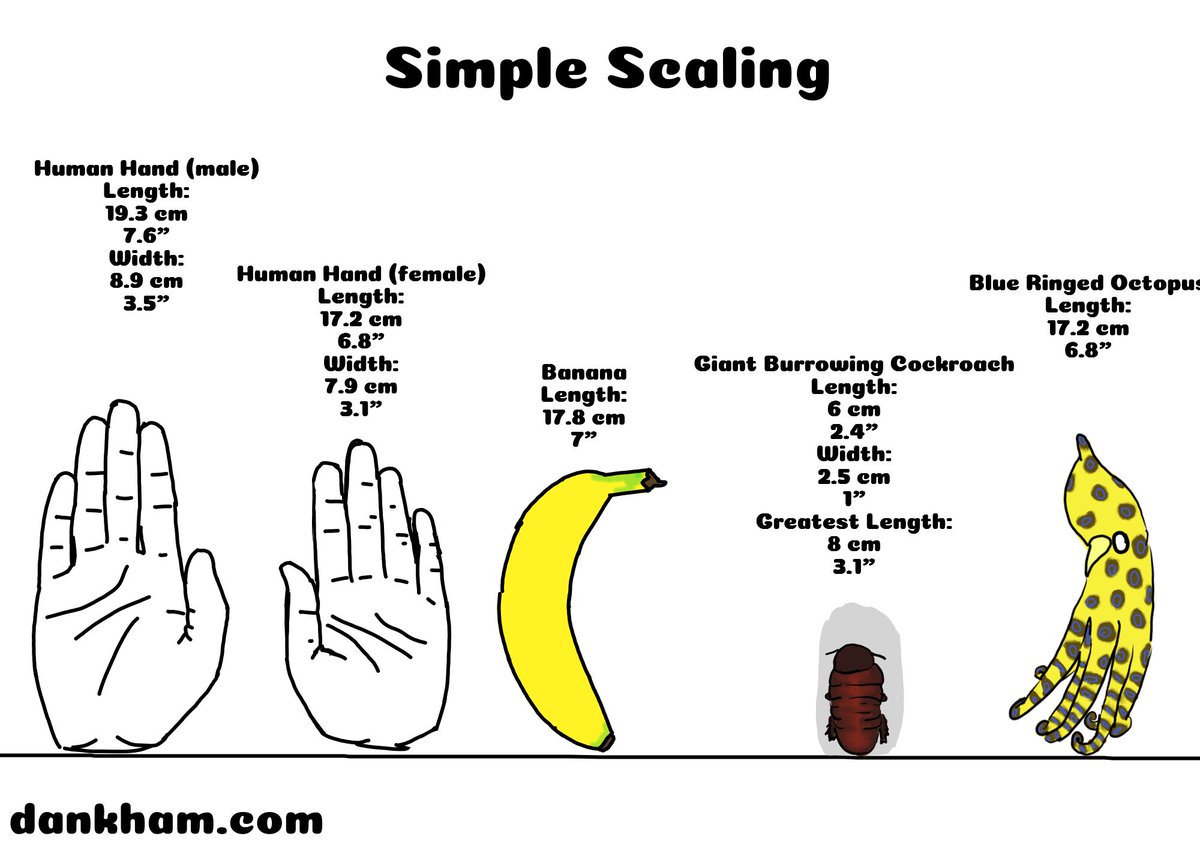
Simple Scaling 15
Check out more Simple Scaling at dankham.com/simple-scaling
Poll link: dankham.com/weekly-poll
Request any animals to see in the future
#comic #comics #animal #animals #science #banana #dankham #simplescaling #roach #octopus #blue_ringed_octopus #cockroach
1
2
3 Sep 2020
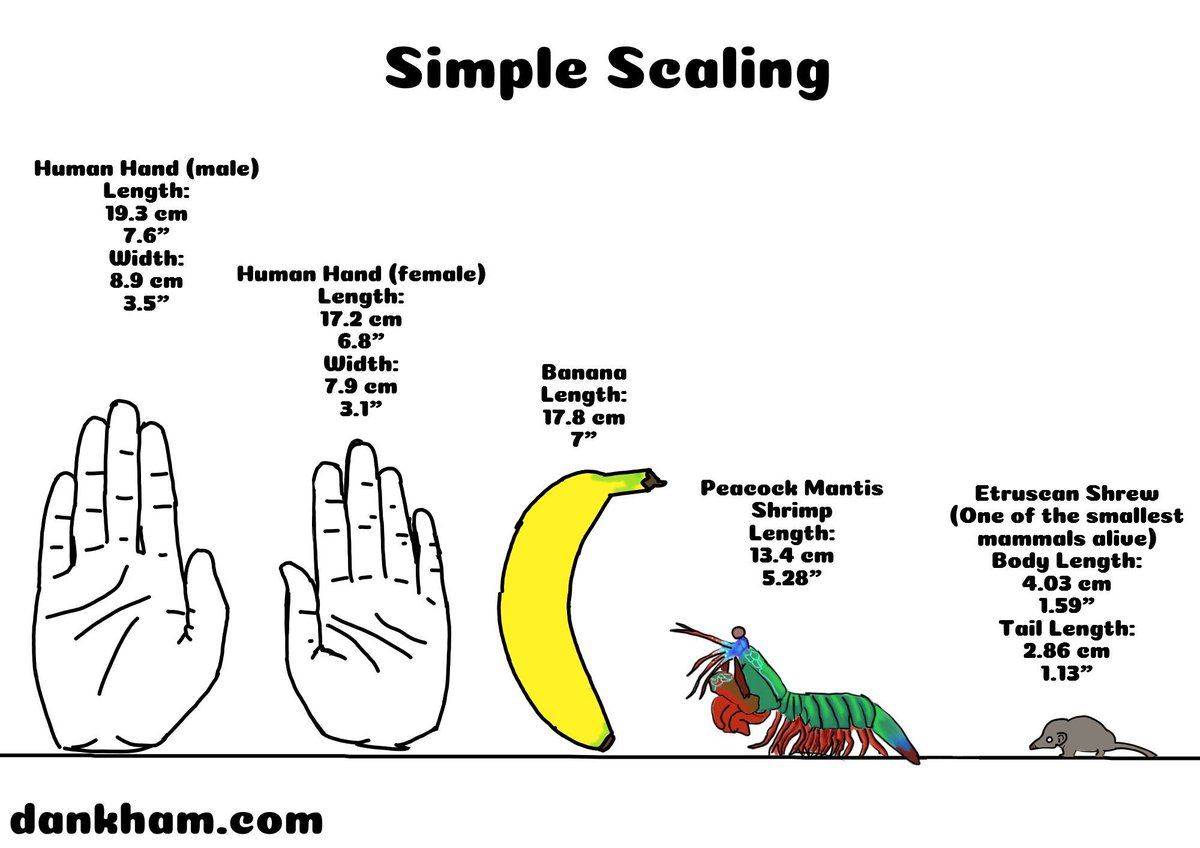
Simple Scaling 14
Check out more Simple Scaling at dankham.com/simple-scaling
Poll link: dankham.com/weekly-poll
Request any animals to see in the future
#comic #comics #animal #animals #science #banana #dankham #simplescaling #mantis #shrimp #mammal #etruscanshrew #scale

1
2
27 Aug 2020
Simple Scaling 13
Check out more Simple Scaling at dankham.com/simple-scaling
Poll link: dankham.com/weekly-poll
Request animals to see in the future
#comic #comics #animal #animals #science #banana #dankham #simplescaling #stbernard #otter #bat #flying_fox #tapir #bairds_tapir


1
2
20 Aug 2020
Simple Scaling 12
Check out more Simple Scaling at dankham.com/simple-scaling
Poll link: dankham.com/weekly-poll
Request anything to see in the future
#comic #comics #animal #animals #science #banana #dankham #simplescaling #banana #hamster #parakeet #bird #budgie #golden_hamster
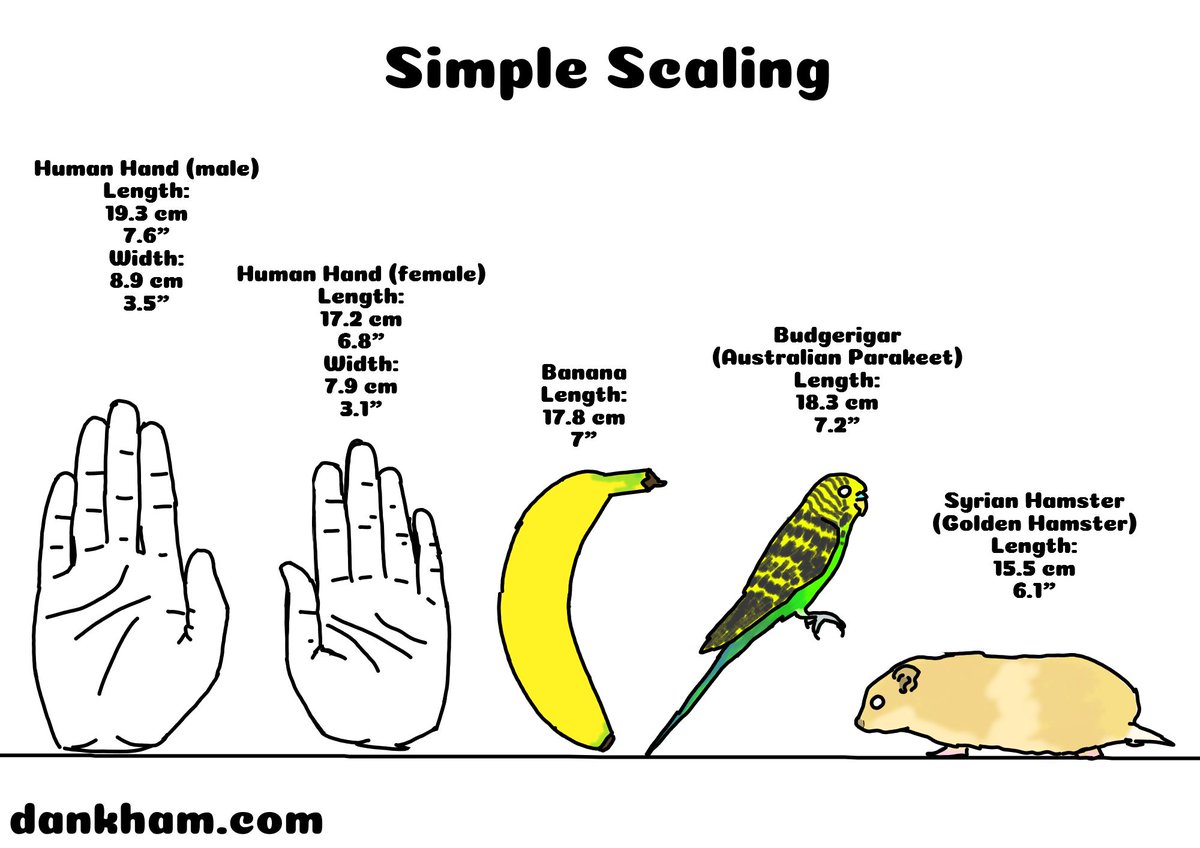

1
3
13 Aug 2020
Simple Scaling 11
Check out more Simple Scaling at dankham.com/simple-scaling
Poll link: dankham.com/weekly-poll
#comic #comics #animal #animals #science #banana #dankham #simplescaling #beetle #banana #banana_slug #hercules_beetle #goliath_beetle #hands
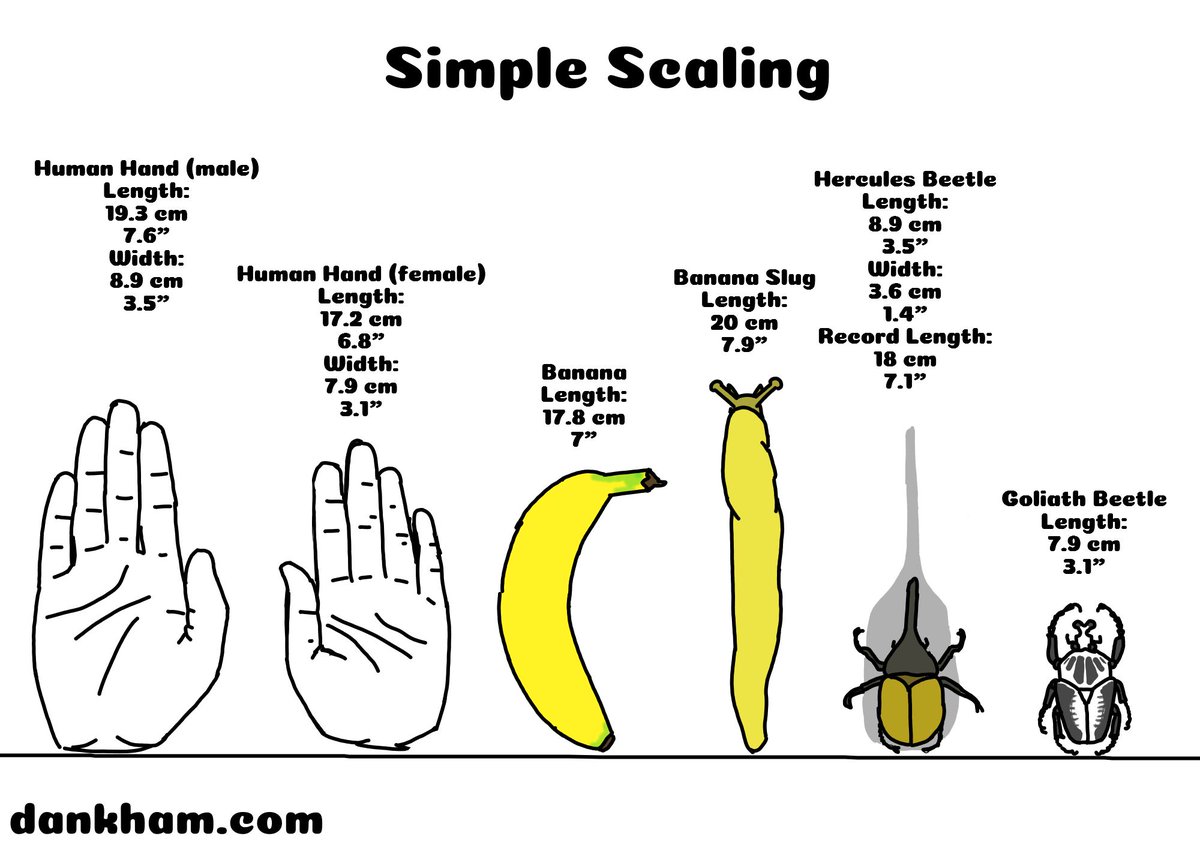

1
2
6 Aug 2020
Simple Scaling 10
Check out more Simple Scaling at dankham.com/simple-scaling
Poll link: dankham.com/weekly-poll
Those are some big @Crocs!
#comic #comics #animal #animals #science #banana #dankham #simplescaling #crocodile #narwhal #Australia
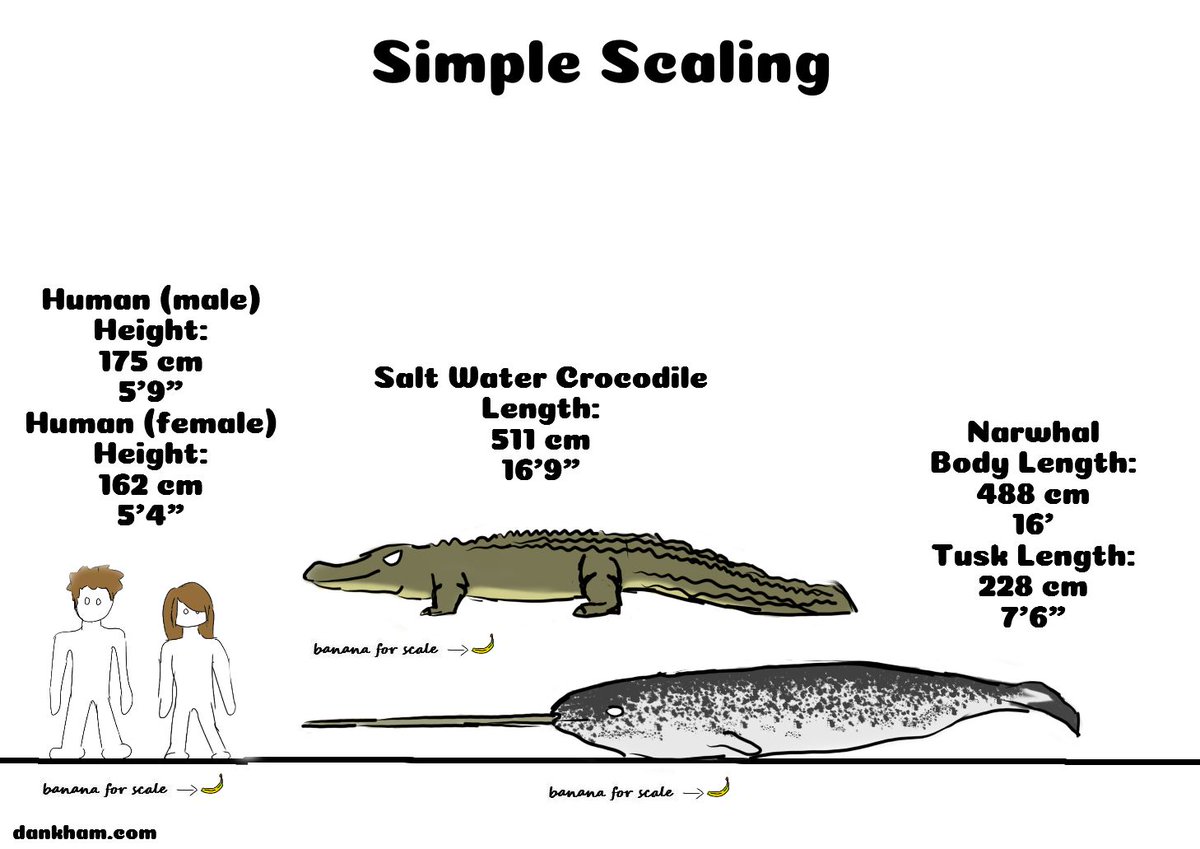

2
2