
Introducing Spanner Graph algorithms
At Google Cloud Next, Google announced the preview of graph algorithms with Spanner Graph, bringing Google Research's state-of-the-art graph mining capabilities natively into an operational database.
Enterprises are increasingly leveraging graph technologies to uncover complex relationships in data for fraud detection, social network analysis, entity resolution, and healthcare research.
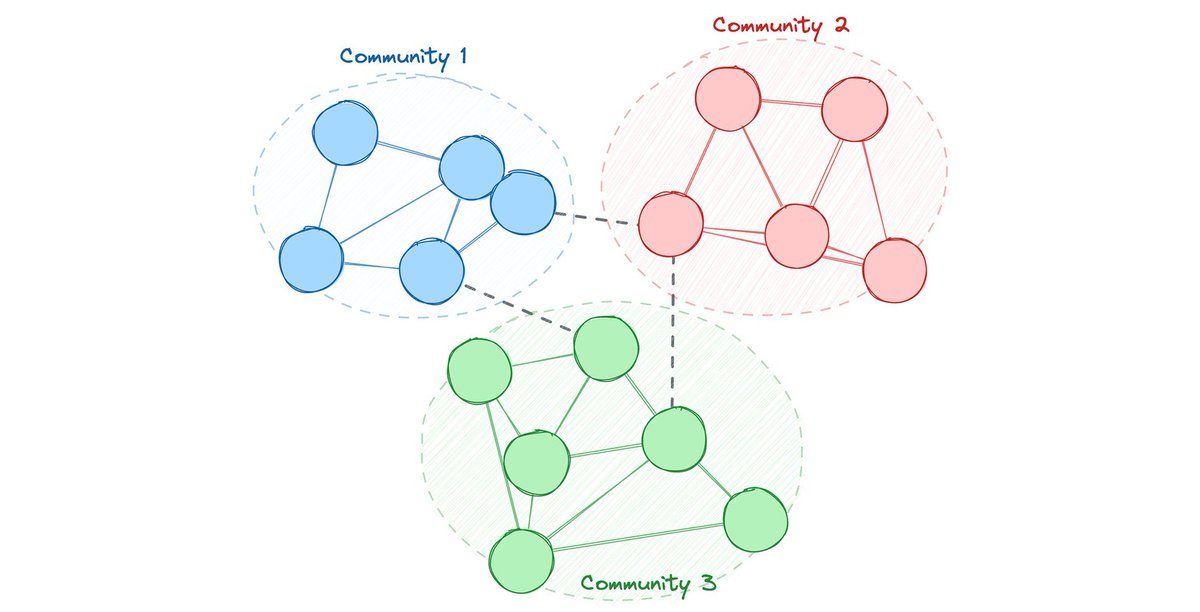
Graph algorithms -- such as node centrality and community detection -- are the computational methods used to analyze these structures, quantifying patterns and the strength of connections between entities.
Running graph algorithms at scale has historically been challenging and resource-intensive, often requiring complex ETL pipelines to dedicated analytic solutions or risking the transactional performance of the graph database.
Spanner Graph algorithms are designed to tackle demanding enterprise workloads without compromising operational database performance:
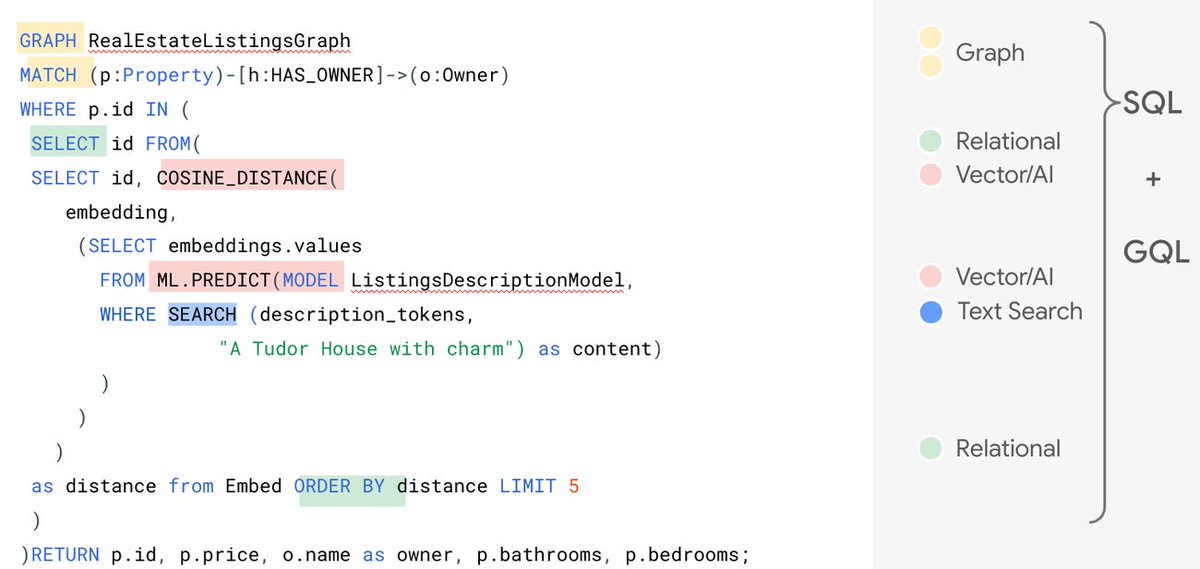
Tight integration with GQL: Directly invoke algorithms using ISO Graph Query Language (GQL) to run structural analytics across your data, minimizing complex data movement to external engines.
Near-zero transactional impact: Algorithm execution happens on dedicated compute resources via Data Boost, without custom ETL pipelines. Pay only for what you use.
Global insights on billion-edge graphs in minutes: The engine can run algorithms on graphs with tens of billions of edges within minutes, using dense topology encoding optimized for random access.
Algorithms available include centrality (betweenness, closeness, PageRank), community detection (label propagation, correlation clustering, modularity clustering, weakly connected components), and similarity/path finding (Jaccard, cosine, set-to-set shortest paths).
Customers including DaVita, Yahoo!, SoundCloud, and WPP are already using Spanner Graph algorithms for patient 360, personalization at scale, music graph analytics, and enterprise intelligence.
By Bei Li and Vahab Mirrokni
cloud.google.com/blog/produc…
#SpannerGraph #GraphAlgorithms #GraphDatabase #FraudDetection #EntityResolution
--
Connected Data London 2026 | 11–12 November | Leonardo Royal Hotel London Tower Bridge
🎤 Share your work with the world's most passionate data community. The Call for Submissions is open. connected-data.london/2026-c…
🎟 Tickets on sale now. Early bird discounts up to 30%. 2026.connected-data.london?u…
📺 Sponsorship opportunities available. Contact info@connected-data.london for details.
#KnowledgeGraph #GraphRAG #Ontology #Graph #AI #DataScience #GraphDB #SemTech
2
14
465

27 Sep 2025
今graph RAGをチーム開発しようとしたら
・任意のDWH上でノードとエッジをdbtで開発
・作成したノードとエッジのレコードを任意のgraph DBにロードして動作確認
って流れになんのかな?
neptuneとかSpannerGraphをいい感じに開発できるdbt的なツールを創造したい
7
1,259

10 Jul 2025
もうまじで「AIエージェント開発はGoogleADKを使うのが最強だと思う。」という、ほとんどの人には意味不明な投稿だけど、AIエージェント開発者にとっては、朗報的な投稿。
GoogleADKを使うと、マルチAIエージェントの開発が異常に早い。
AIエージェントがあらゆるアプリを操作できる技術「MCP」も簡単に統合できる。
そして、GCPを使ってれば諸々一気通貫で開発できる。
そして、最先端のグラフRAGという情報をグラフ化するRAGが「SpannerGraph」という先端技術もGCPでは使える。
AIエージェント開発するならば、GoogleADK一択でよいと思われます。いやぁ、インフラからAIモデル、AIエージェントFrameworkまでフルフルでそろってるGoogleさんはマジで最強すぎる。
たぶん、2026年からGoogle無双が始まると思います。
そして、今までは序章です。
cloud.google.com/blog/ja/top…
5
170

Spanner Graph で、グラフクエリ結果とスキーマの可視化機能が提供。返された要素のパターン、依存関係、異常の発見や、ノードとエッジの関係性の理解を支援 #SpannerGraph #GoogleCloud
cloud.google.com/spanner/doc…
2
260

17 Jan 2025
常時稼働の #データベース
Spanner のイノベーション🔧
→ goo.gle/4heMeoo
#SpannerGraph、全文検索、ベクトル検索のリリースなど、昨年にお伝えした特に重要な Spanner のイノベーションやそのメリットを振り返りましょう。今年はさらに多くの魅力的な機能の提供を予定しています!
6
2,180

3 Aug 2024
🚀 Google Cloud revoluciona la IA y la nube con nuevas herramientas. Descubre cómo optimizar tus aplicaciones. 🌐✨ wwwhatsnew.com/2024/08/03/in… #GoogleCloud #InteligenciaArtificial #Innovación #Tecnología #SpannerGraph
4
521