
9 Dec 2025
PlantBiMoE: A Bidirectional Foundation Model with SparseMoE for Plant Genomes
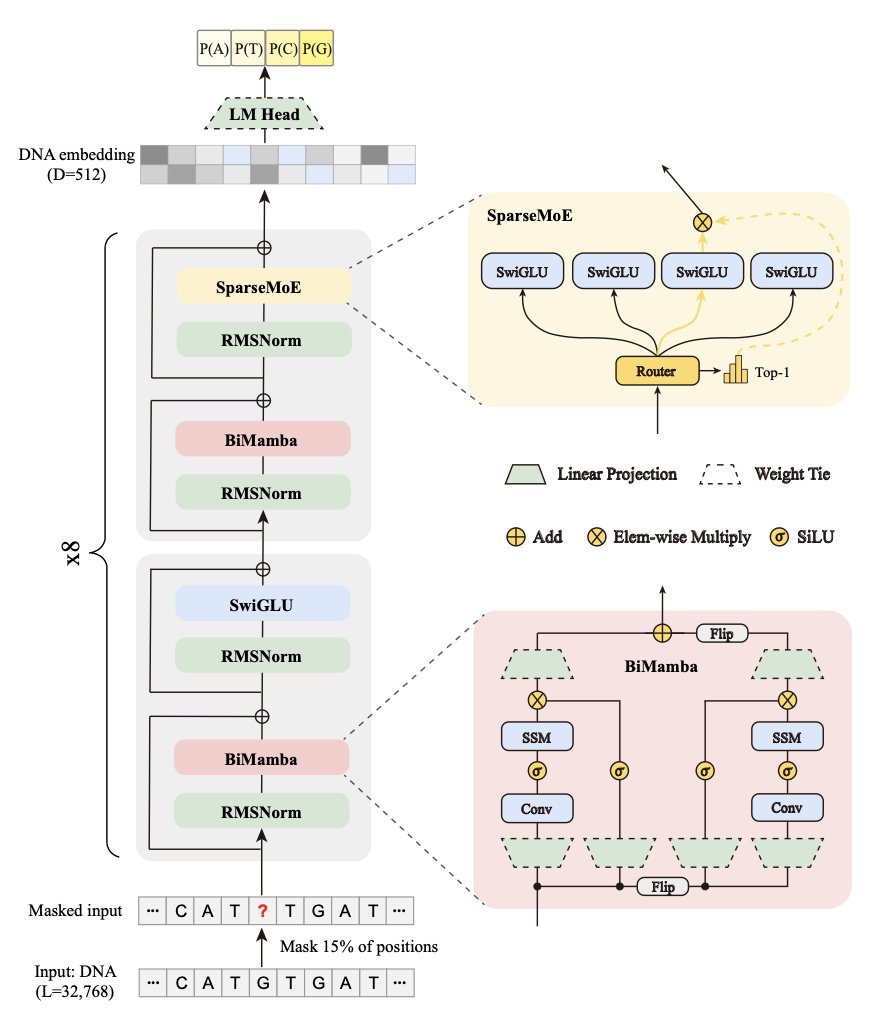
1. PlantBiMoE introduces a novel approach to plant genome language modeling by integrating bidirectional Mamba and SparseMoE frameworks. This combination not only enhances the model's ability to capture bidirectional dependencies in DNA sequences but also significantly reduces computational costs through sparse parameter activation.
2. The model achieves state-of-the-art performance on the Modified Plants Genome Benchmark (MPGB), outperforming previous models like AgroNT and PDLLMs in tasks such as chromatin accessibility prediction and histone modification analysis. This demonstrates its superior generalization across diverse plant species and genomic tasks.
3. PlantBiMoE is pre-trained on a comprehensive dataset of 42 plant species, covering a wide range of categories from model plants to algae. This extensive pre-training ensures the model's robustness and adaptability to various genomic contexts.
4. The bidirectional Mamba module in PlantBiMoE allows for efficient encoding of both forward and reverse DNA strands, addressing the limitations of unidirectional models. This is crucial for accurately modeling the complex regulatory mechanisms in plant genomes.
5. SparseMoE enables the model to dynamically activate only a subset of experts for each input token, enhancing specialization and reducing interference between unrelated inputs. This leads to improved generalization and efficiency.
6. PlantBiMoE's architecture includes a theoretical context window of 32,768 base pairs, allowing it to capture long-range dependencies in genomic sequences. This is a significant improvement over previous models and essential for tasks involving cis-regulatory elements.
7. The model's lightweight design, with only 116 million parameters, makes it highly practical for deployment in typical research settings, unlike larger models that require extensive computational resources.
8. The introduction of the Modified Plants Genome Benchmark (MPGB) provides a unified and enhanced evaluation framework for plant genome language models, consolidating 31 datasets across 11 tasks. This benchmark will facilitate future model comparisons and advancements.
📜Paper: arxiv.org/abs/2512.07113v1
#PlantGenomics #LanguageModeling #SparseMoE #BidirectionalMamba #ComputationalBiology
1
2
8
1,059

6 Sep 2025
【高性能なのに効率的!?Kwai-KlearのSparse-MoE LLMがすごいんです!】
AIの進化は止まらない!✨ Redditで見つけた、注目のLLMをご紹介します。
「Kwai-Klear/Klear-46B-A2.5B-Instruct」は、画期的な「Sparse-MoE」アーキテクチャを採用。
💡Sparse-MoEは、必要なエキスパートだけが働く賢い仕組み。例えるなら、困った時に最適な先生がサッと助けてくれるイメージ📚
総パラメータ数460億(46B)に対し、アクティブなパラメータ数はわずか25億(2.5B)という驚異的な効率性!😳
これにより、リソースを節約しながら高性能を発揮できる、まさに次世代のLLM。幅広い環境での活用に期待が高まります。Hugging Faceでも関連情報があるようです。
#KwaiKlear #SparseMoE #LLM
1
2
153

26 May 2025
🤔 Can diffusion models rival transformers for language modeling? This new research says yes — and introduces LLaDA to prove it.
The paper presents LLaDA (Large Language Diffusion with mAsking), a novel 8B-parameter language model that abandons the autoregressive paradigm. Instead of generating text token-by-token like GPT-style models, LLaDA uses a masked diffusion process, enabling it to learn and generate bidirectionally.
🔍 What makes it different?
🔹No causal masking — the model sees the entire context while predicting
🔹Uses random masking ratios from 0 to 1 (vs fixed masking in BERT-like models)
🔹Trained from scratch on 2.3T tokens with 0.13M H800 GPU hours
📊 How it performs:
🔹Matches or outperforms LLaMA2 7B on most zero-shot/few-shot tasks
🔹Competes closely with LLaMA3 8B, despite using fewer training tokens
🔹Excels in math, code, and Chinese benchmarks
🔹Handles reversal reasoning better than GPT-4o in poem completion tasks
🧠 Emerging capabilities:
🔹Strong in-context learning without autoregressive modeling
🔹Effective instruction-following with only supervised fine-tuning (no RLHF)
🔹Robust multi-turn dialogue, despite being diffusion-based, a first at this scale
📘 Why it matters:
This work challenges the long-held belief that large-scale LLM capabilities are inherently tied to autoregressive methods. By proving that diffusion-based models can scale, generalize, and reason competitively, it opens the door to new architectures that may reduce generation latency, improve robustness, and diversify LLM design.
🎯 Learn to build the future—enroll in our LLM Bootcamp today!
🔗 Register now: hubs.la/Q03nNcs-0
#ModularLLMs #SparseMoE #ParameterEfficientTuning #LLM #AIResearch #MixtureOfExperts #FineTuning #DeepLearning #TransformerModels #LLMBootcamp

3
1
11
2,614

4 Feb 2025
完全从零手写MOE大模型,复现 DeepSeek MOE 算法,彻底 MOE 算法进化之路,build a nano MOE LLM from scratch
本次课一共讲解三个不同版本的 MOE,分别是基础版MOE,大模型训练用的 SparseMoE,还有 DeepSeek 用的比较多的 shared_expert 的 SparseMoE。 #DeepSeekAI
youtu.be/0BodppoiloM?si=5isr…
1
261

27 Dec 2024
【保存版】年末年始に学びたい生成AI技術まとめ🎄
1️⃣ トランスフォーマー深掘り(SparseMoE他)
2️⃣ 最新RAG×プロンプトエンジニアリング
3️⃣ LLM評価手法(ハルシネーション定量化)
4️⃣ 効率的なファインチューニング(LoRA/QLoRA)
5️⃣ LLMOps実践(本番投入のノウハウ)
私も今これ勉強中です👨💻
1
103

16 Feb 2024
Nanotron v0.2 is here! ⚡️
With Gemini 1.5 Pro and Mixtral, seems like sparse MoEs are taking over! This release brings them to Nanotron, enabling efficient training with expert parallelism support.
🚀github.com/huggingface/nanot…
#NLP #AI #MachineLearning #Transformers #MoE #SparseMoE
1
23
101
11,687

3 Aug 2023
I’ve never been convinced by SparseMoE models. They sound appealing, but are plagued with fundamental technical issues.
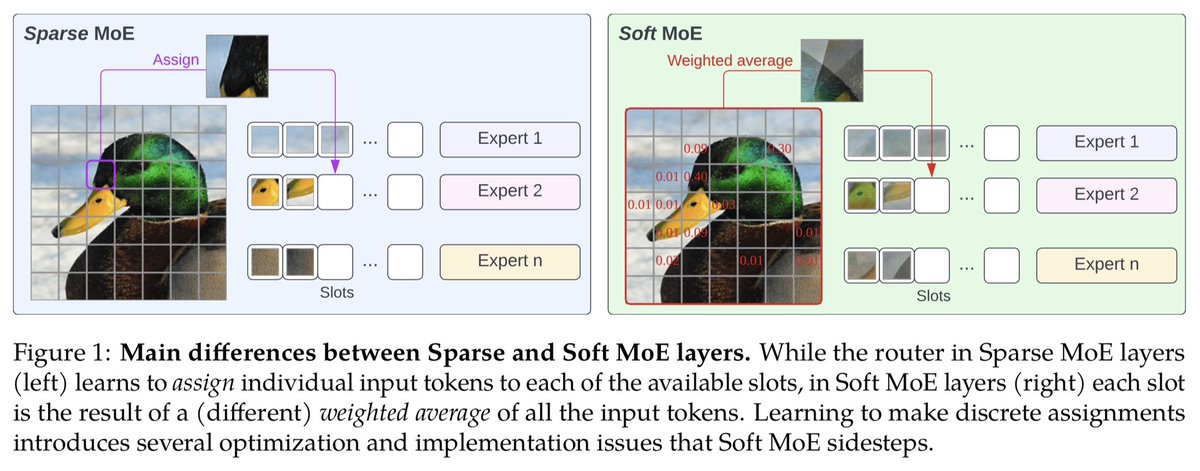
When Joan and Carlos shared their SoftMoE idea and results, for the first time, I thought “this may be it!”
Not a panacea, but still feels like a breakthrough
3 Aug 2023

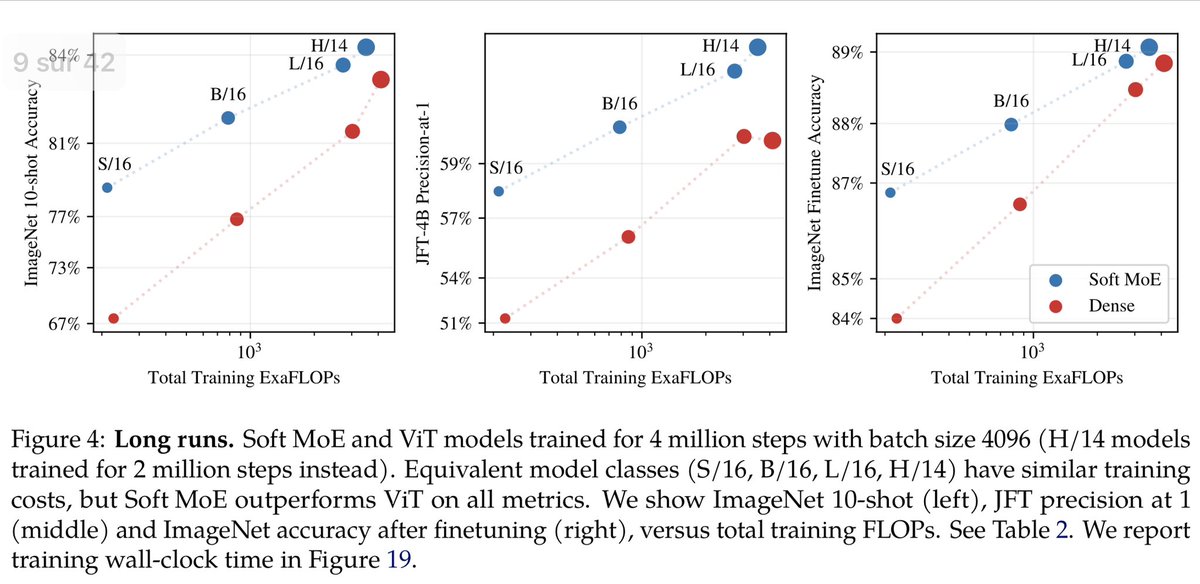
Introducing Soft MoE! Sparse MoEs are a popular method for increasing the model size without increasing its cost, but they come with several issues. Soft MoEs avoid them and significantly outperform ViT and different Sparse MoEs on image classification.
arxiv.org/abs/2308.00951
2
23
183
34,274

Good info, confirming what I heard from the SV grapevine, mostly changes that are forced upon OAI. GPT3 had exhausted all text data from the web. There is no way to feed the monster except by using other modalities. There is also no other way to scale so far except by sparseMOE..
4
2