
General Synthetic-Powered Inference
👥 Meshi Bashari, Yonghoon Lee, Roy Maor Lotan et al.
#AIResearch #SyntheticData #StatisticalInference #ConformalPrediction
🔗 trendtoknow.ai/paper-reviews…

9

26 Aug 2025
Amortized Sampling with Transferable Normalizing Flows
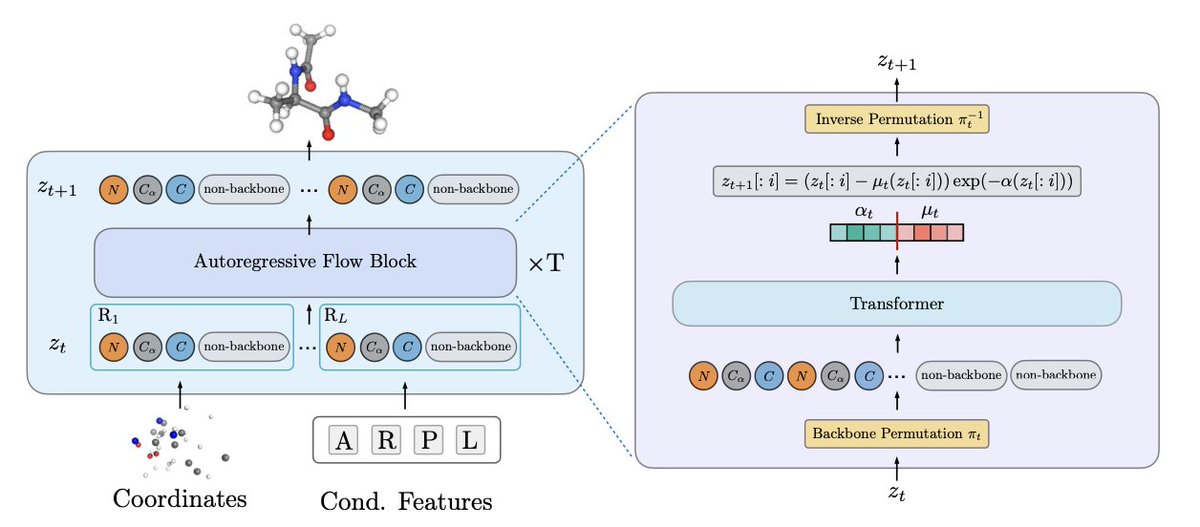
1. Introducing PROSE, a 280 million parameter all-atom transferable normalizing flow model. This model is trained on a large corpus of peptide molecular dynamics trajectories and demonstrates unprecedented abilities to transfer to previously unseen systems of different amino acids, sizes, and temperatures, outperforming traditional molecular dynamics (MD) methods in terms of computational efficiency and sampling performance.
2. The core innovation of PROSE lies in its ability to draw zero-shot uncorrelated proposal samples for arbitrary peptide systems, achieving transferability across sequence length while retaining the efficient likelihood evaluation of normalizing flows. This is a significant advancement as it allows for the generation of high-quality samples without the need for retraining or fine-tuning for each new system, thus addressing a major limitation of conventional sampling methods.
3. The study introduces a novel dataset of molecular dynamics trajectories for peptide systems between 2 and 8 residues, consisting of 21,700 peptide sequences simulated for 200 ns each. This extensive dataset provides a rich resource for training and evaluating the model, enabling it to learn the complex distributions of molecular conformations and generalize to unseen systems.
4. PROSE builds on the TarFlow architecture, incorporating several architectural modifications to enhance its performance. These include adaptive system conditioning through adaptive layer normalization and SwiGLU-based transition blocks, as well as chemistry-aware sequence permutations that promote effective molecular modeling by updating the backbone atoms before the sidechains.
5. The efficacy of PROSE as a proposal distribution for different Monte Carlo algorithms is demonstrated through extensive empirical evaluation. The study finds that a simple importance sampling-based fine-tuning procedure can achieve superior performance to established methods such as sequential Monte Carlo on unseen tetrapeptides, highlighting the potential of PROSE for accurate and efficient sampling in various applications.
6. The scalability and transferability of PROSE are further confirmed by its ability to sample from the equilibrium distribution on previously unseen peptide systems of length up to 8 residues, surpassing the continuous normalizing flow-based transferable Boltzmann generator while generating proposals significantly faster. This opens up new possibilities for accelerated sampling in computational chemistry and statistical inference.
7. The authors open-source the PROSE codebase, model weights, and training dataset, facilitating further research and development in the field of amortized sampling methods. This open-source approach encourages collaboration and innovation, allowing other researchers to build upon the work and explore new applications and improvements.
💻Code: github.com/transferable-samp…
📜Paper: arxiv.org/abs/2508.18175v1
#AmortizedSampling #TransferableNormalizingFlows #PROSE #MolecularDynamics #ComputationalChemistry #StatisticalInference
3
795

5 Apr 2025
Fisher Information captures how well your data constrains a parameter θ. It has two powerful interpretations:
1. It’s the curvature of the log-likelihood near its peak. A sharper peak means your data strongly favors the true value θ₀, and quickly rules out alternatives — i.e., your data is highly constraining.
2. It’s the inverse variance of the Gaussian approximation to the likelihood. A narrow, peaky likelihood means low uncertainty in your estimate — directly linked to the Cramér-Rao Bound, which sets the best possible precision for any unbiased estimator.
So:
🔹 High Fisher Info → steep likelihood → precise estimates
🔹 Low Fisher Info → flat likelihood → weak constraint
#StatisticalInference #MLE #FisherInformation #CramerRaoLowerBound
1
3
190

13 Mar 2025
Department of Mathematics at KSRCT organizing a guest lecture on "Statistical Inference : Exploring Hypothesis Testing and ANOVA for Data - Driven Decisions" on March 19, 2025, 01:30 PM through Microsoft teams
#ksrct1994 #Mathematics #GuestLecture #StatisticalInference #ANOVA

19
54
131

Normal dağılımın teoride geçerli olduğu yaşamda, kuyruk etkisi sonucu belirliyor. Buna kara kuğu için rol alma dönemi de diyebiliriz.
Akıllı paranın piyasa diplerinden alıp, zirvelerinden sattığına inanıyorsak, hesaplamaları da buna göre yenilemek gerekir.
Buna göre dibine göre getiri hesabıyla gerçek kazancı görebiliriz. Bu durumda karar alma mekanizmaları değişecektir.
Ons altın dibine göre getiri hızını normalize edelim:
20 yıl: 3 birim
10 yıl: 3 birim
5 yıl: 4 birim
3 yıl: 6 birim
2 yıl: 7 birim
1 yıl: 10 birim
2025: 7 birim
Efsaneler aksine gerçeğe bakınca akıllı paranın işthında 3 yıldır artış var ve giderek yükseliyor.
Bu artışın 20 yıllığa göre aşırı olduğunu düşünenler "fat tail" veya şişen anormal getirilerin nadiren görülmeye devam edeceğini bilmeleri gerekir.
#distribution #anomaly #statisticalinference #inferenceengine #xauusd #gold #altın #goldetfs


1
71

14 Feb 2025
🌟 Day 26 of #100DaysOfConsistencyChallenge!!🌟
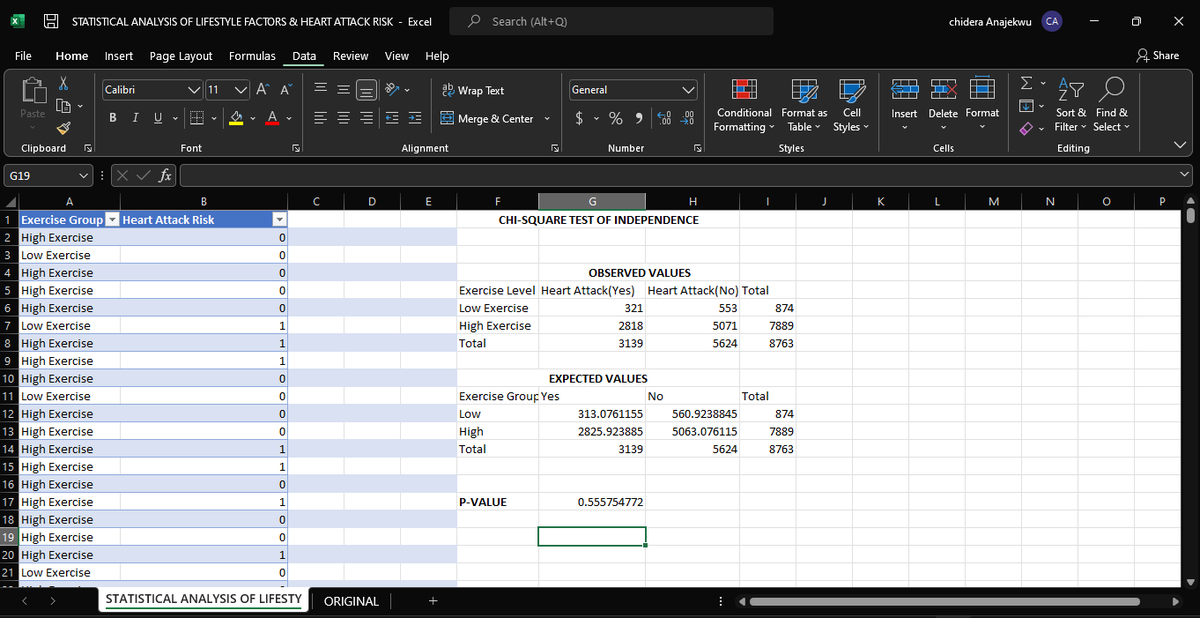
Practicing Statistical Inference with a demo dataset on " lifestyle factors of heart attack" .
Data Analytics x Statistics = 🤯
See you when I conclude the project...
#100DOCC
#100DaysOfDataAnalytics
#StatisticalInference
🚀✨
1
4
62

13 Jan 2025
(Legally FREE, Open Access) Introduction to Statistics and Data Analysis - freecomputerbooks.com/Introd…
Look for "Read and Download Links" section to download.
#Statistics #DataAnalysis #DataScience #DataMining #StatisticalInference #StatisticalThinking #StatisticalThought

25
23 Dec 2024
R for Statistical Modelling and Computing - freecomputerbooks.com/An-Int…
Look for "Read and Download Links" section to download.
#StatisticalModelling #StatisticalComputing #StatisticalInference #programming #DataAnalysis #DataScience
16

16 Oct 2024
Excited to put the second edition of '#StatisticalInference via #DataScience: A @ModernDive into #RStats and the #Tidyverse' by @old_man_chester, @rudeboybert, and Arturo Valdivia into production to publish in Spring 2025! routledge.com/Statistical-In…

24
125
7,994

30 Aug 2024
Master the art of making statistical inferences with this comprehensive online resource by Daniël Lakens! 📊 Dive deep into statistical concepts and improve your research: buff.ly/3JIGTnP #Stats #Research #DataScience #StatisticalInference #RStats #Python #DataAnalytics #DataViz
1
888

16 Aug 2024
"A parameter is an unknown numerical summary of the population. A statistic is a known numerical summary of the sample which can be used to make inference about parameters." -Agresti & Finlay, (1997)
#StatisticalInference #PopulationParameter #SampleStatistic #DataAnalysis #ResearchMethods #AgrestiAndFinlay #QuantitativeResearch #Statistics #DataScience #InferentialStatistics

4
5
2,380
16 Aug 2024
"Inferential statistics consist of methods for drawing and measuring the reliability of conclusions about population based on information obtained from a sample of the population." -Weiss, (1999)
#InferentialStatistics #DataAnalysis #StatisticalMethods #PopulationSampling #ResearchMethods #DataScience #QuantitativeResearch #Weiss #DataInterpretation #StatisticalInference

5
4
2,342

25 Jul 2024
#Quantumerrormitigation has been proposed as a means to combat unwanted and unavoidable #errors in near-term #quantumcomputing without the heavy resource overheads required by fault-tolerant schemes. Recently, error mitigation has been successfully applied to reduce noise in near-term applications.
In this work, however, we identify strong limitations to the degree to which quantum noise can be effectively ‘undone’ for larger system sizes. Our framework rigorously captures large classes of error-mitigation schemes in use today. By relating error mitigation to a #statisticalinference problem, we show that even at shallow circuit depths comparable to those of current experiments, a superpolynomial number of samples is needed in the worst case to estimate the expectation values of noiseless observables, the principal task of error mitigation.
Notably, our construction implies that #scrambling due to noise can kick in at exponentially smaller depths than previously thought. Noise also impacts other near-term applications by constraining kernel estimation in #quantummachinelearning, causing an earlier emergence of noise-induced barren plateaus in variational #quantumalgorithms and ruling out exponential quantum speed-ups in estimating expectation values in the presence of noise or preparing the ground state of a Hamiltonian.
1
10
854

2 Jul 2024
Revealing gene function with statistical inference at single-cell resolution. #SingleCell #GeneFunction #StatisticalInference @NatureRevGenet
nature.com/articles/s41576-0…
1
6
21
1,359
19 Jun 2024
A reminder that if you are teaching #StatisticalInference next academic year, you can grab an inspection copy of #CasellaBerger - now published by @CRC_MathStats! routledge.com/textbooks/eval… #Statistics #DataScience #RStats

14
36
3,019
22 May 2024
The week of publication has arrived, and the classic textbook on #StatisticalInference by Casella & Berger is now officially a @CRC_MathStats book! Our version of the existing second edition has now published; request an inspection copy here: routledge.com/textbooks/eval… #Statistics

1
14
64
9,817
23 Apr 2024
Excited to announce that @CRC_MathStats is to become the publisher of the classic #StatisticalInference textbook by Casella & Berger. Our reprint of the existing second edition publishes next month, and the third edition is coming in 2026! routledge.com/Statistical-In… #Statistics

7
16
141
8,710
20 Mar 2024
Unveil the mystery of P-values with crystal-clear insights! Explore Nitin Kumar Sharma's enlightening explanation at buff.ly/4ahO8Rk. 📊🔍 #rstats #Rstudio #Statistics #DataScience #HypothesisTesting #DataAnalytics #StatisticalInference #ResearchMethods #PValues
41
130
9,632

📚 Read about the evolution of statistical inference from Khanh Dinh (@khanh_n_dinh) , Simon Tavaré, and Zijin Xiang! Read here: bit.ly/4anR1At #StatisticalInference #ColumbiaUniversity
1
341
29 Feb 2024
Unveil the mystery of P-values with crystal-clear insights! Explore Nitin Kumar Sharma's enlightening explanation at link.medium.com/QalB09VoIFb. 📊🔍 #rstats #Rstudio #Statistics #DataScience #HypothesisTesting #DataAnalytics #StatisticalInference #ResearchMethods #PValues
1
61
235
17,676