
29 Jun 2025
GHOSTBUSTER: A Deep-Learning-based, Literature-Unbiased Gene Prioritization Tool for Gene Annotation Prediction
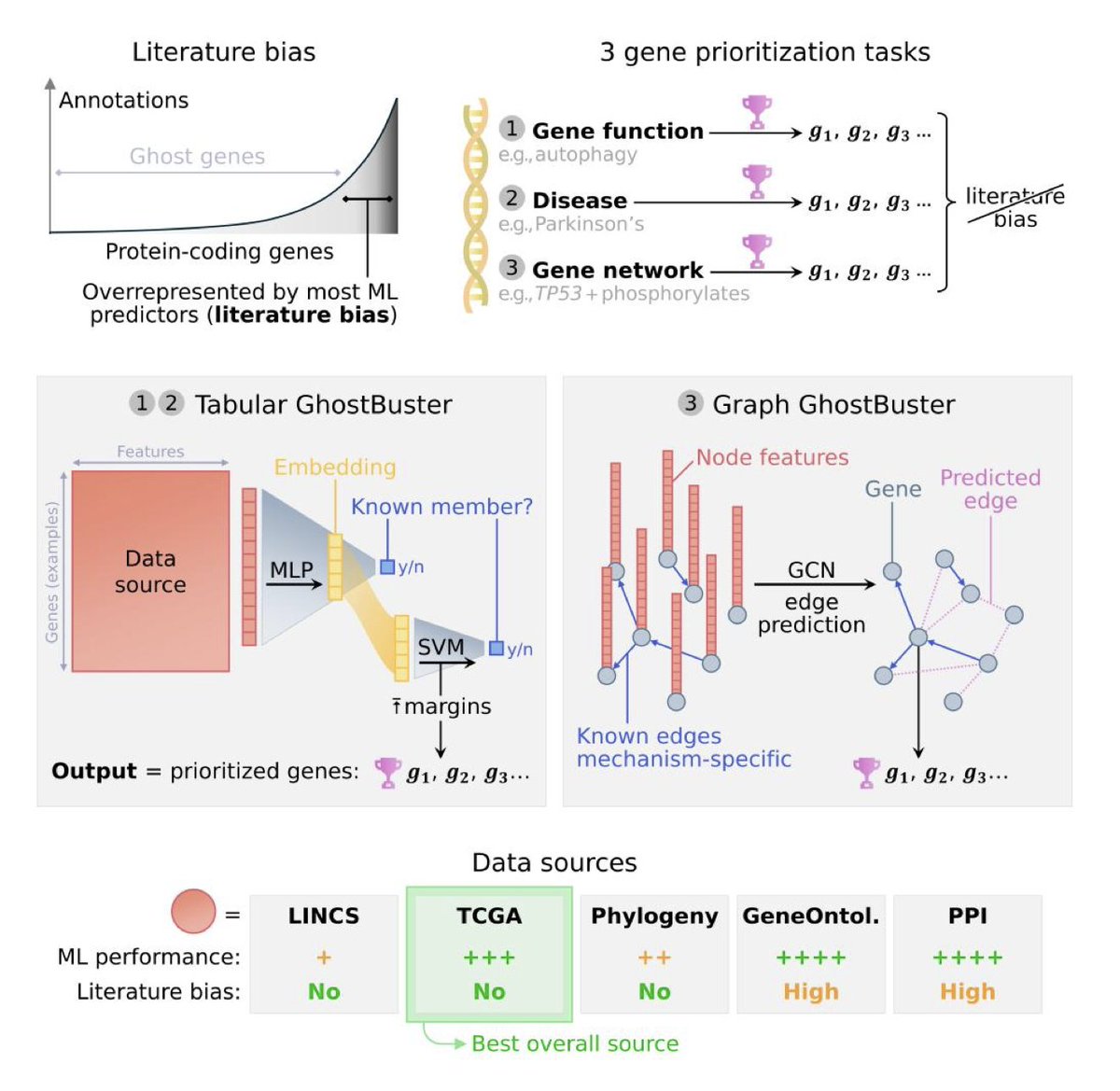
1.GhostBuster introduces a new deep learning framework that explicitly removes literature bias in gene annotation prediction, a pervasive issue in current genomic models that inflates performance metrics and overlooks understudied "ghost" genes.
2.Unlike most models trained on Gene Ontology or PPI data (which are heavily literature-influenced), GhostBuster trains on three unbiased sources: TCGA, LINCS, and STRING (filtered for literature-free interactions), enabling discovery of novel gene functions and associations.
3.The model exists in two flavors: Tabular GhostBuster, which ranks individual genes likely to be involved in a function or disease, and Graph GhostBuster, which predicts interactions between gene pairs in specific biological modalities.
4.GhostBuster's unbiased versions identify 2–3 times more recently validated gene annotations than biased models, even though they score lower in typical ML metrics like ROC-AUC—highlighting how standard benchmarks reward bias.
5.A striking example: GO-based models achieve near-perfect ROC-AUCs (up to 0.99) on diseases like Parkinson’s, a clearly implausible result given our limited biological understanding—demonstrating how biased sources distort perceived performance.
6.GhostBuster's performance was evaluated across 81 biological phenotypes and 21 gene-gene interaction types. Despite lower ML scores, the predictions from unbiased data had lower annotation richness, fewer PubMed hits, and more ghost genes—strong signs of reduced bias.
7.The study also analyzed 7 confounders of literature bias and showed that input data bias strongly propagates into the model’s output, reinforcing the Matthew effect in biology, where well-known genes keep getting more attention.
8.GhostBuster is not only a model but also a conceptual shift: it challenges the reliance on legacy performance metrics and proposes that scientific novelty, not accuracy against biased annotations, should guide model validation.
9.To the authors' knowledge, GhostBuster is the first machine learning architecture that offers both gene function/disease prediction (GFP/GDP) and network inference (GNP) with minimal literature contamination and mechanistic resolution.
📜Paper: biorxiv.org/content/10.1101/…
#genomics #deeplearning #bioinformatics #genefunction #ghostgenes #machinelearning #genomicsresearch #AI

2
5
1,087
29 Jun 2025
GHOSTBUSTER: A Deep-Learning-based, Literature-Unbiased Gene Prioritization Tool for Gene Annotation Prediction
1.GhostBuster introduces a new deep learning framework that explicitly removes literature bias in gene annotation prediction, a pervasive issue in current genomic models that inflates performance metrics and overlooks understudied "ghost" genes.
2.Unlike most models trained on Gene Ontology or PPI data (which are heavily literature-influenced), GhostBuster trains on three unbiased sources: TCGA, LINCS, and STRING (filtered for literature-free interactions), enabling discovery of novel gene functions and associations.
3.The model exists in two flavors: Tabular GhostBuster, which ranks individual genes likely to be involved in a function or disease, and Graph GhostBuster, which predicts interactions between gene pairs in specific biological modalities.
4.GhostBuster's unbiased versions identify 2–3 times more recently validated gene annotations than biased models, even though they score lower in typical ML metrics like ROC-AUC—highlighting how standard benchmarks reward bias.
5.A striking example: GO-based models achieve near-perfect ROC-AUCs (up to 0.99) on diseases like Parkinson’s, a clearly implausible result given our limited biological understanding—demonstrating how biased sources distort perceived performance.
6.GhostBuster's performance was evaluated across 81 biological phenotypes and 21 gene-gene interaction types. Despite lower ML scores, the predictions from unbiased data had lower annotation richness, fewer PubMed hits, and more ghost genes—strong signs of reduced bias.
7.The study also analyzed 7 confounders of literature bias and showed that input data bias strongly propagates into the model’s output, reinforcing the Matthew effect in biology, where well-known genes keep getting more attention.
8.GhostBuster is not only a model but also a conceptual shift: it challenges the reliance on legacy performance metrics and proposes that scientific novelty, not accuracy against biased annotations, should guide model validation.
9.To the authors' knowledge, GhostBuster is the first machine learning architecture that offers both gene function/disease prediction (GFP/GDP) and network inference (GNP) with minimal literature contamination and mechanistic resolution.
📜Paper: biorxiv.org/content/10.1101/…
#genomics #deeplearning #bioinformatics #genefunction #ghostgenes #machinelearning #genomicsresearch #AI
3
11
1,302
3 Jun 2025
A Gene Set Foundation Model Pre-Trained on a Massive Collection of Diverse Gene Sets
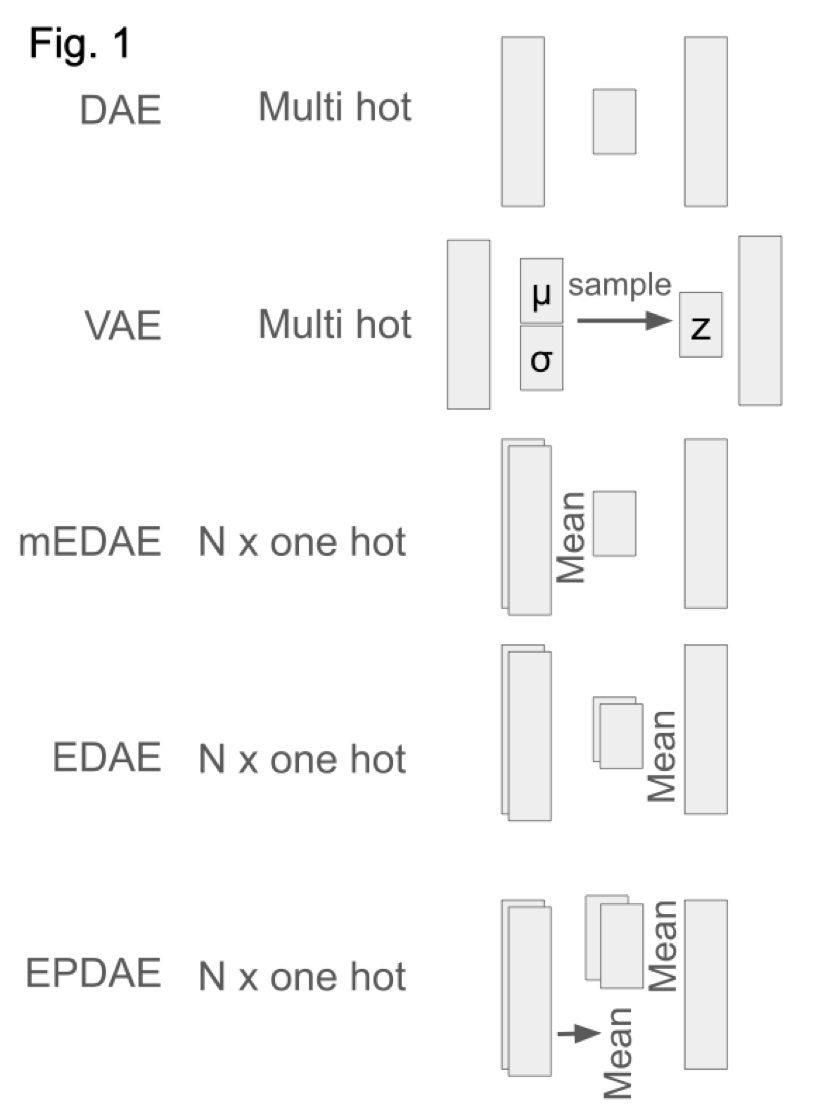
1.A new gene set foundation model (GSFM) is introduced, trained on over one million gene sets mined from two large resources—Rummagene and RummaGEO—offering a wide, unlabeled view of biological knowledge without relying on single-cell data.
2.GSFM outperforms state-of-the-art methods like PrismEXP and GenePT in gene function prediction across both curated gene libraries (like KEGG and GO BP) and data-driven ones (like ChEA and GWAS).
3.Rummagene, a key data source, extracts gene sets from supplementary tables of PMC papers, capturing diverse biological contexts. RummaGEO contributes sets derived from differential expression analysis of thousands of RNA-seq studies in GEO.
4.The top-performing GSFM architecture is a simple multi-hot encoded Denoising Autoencoder (DAE), trained to predict held-out genes in gene sets using self-supervised learning. It achieves robust generalization and interpretability.
5.Extensive benchmarking shows that training on Rummagene alone leads to superior results compared to using RummaGEO or the combined dataset, likely due to the greater diversity and sparsity of the gene set space captured.
6.GSFM enables zero-shot predictions—no retraining required—by completing partially known gene sets or predicting gene membership for arbitrary sets across a wide variety of libraries.
7.The model supports several downstream applications: gene function annotation, gene set enrichment augmentation, and even protein-protein interaction or kinase-substrate relationship inference.
8.GSFM predictions are hosted at gsfm.maayanlab.cloud, offering precomputed gene pages with functional predictions, AUROC confidence scores, and optional LLM-generated gene summaries based on literature.
9.The model weights, training code, and inference tools are publicly released on HuggingFace and GitHub, enabling integration into custom pipelines or embedding-based transfer learning.
10.GSFM is currently trained on coding genes, but future directions include incorporating non-coding genes, additional omics layers, and vector-valued gene set signatures (e.g., logFC or p-values).
💻Code: huggingface.co/maayanlab/gsf…
📜Paper: biorxiv.org/content/10.1101/…
#Bioinformatics #GeneFunction #FoundationModels #Transcriptomics #MachineLearning #SystemsBiology
3
583
25 May 2025
RL-Finetuning of OpenAI o1-mini to Enhance Biomedical Reasoning
1.This study explores whether reinforcement learning (RL) finetuning can improve the biomedical reasoning of OpenAI’s o1-mini model, which was originally optimized for complex multi-step tasks like math and code.
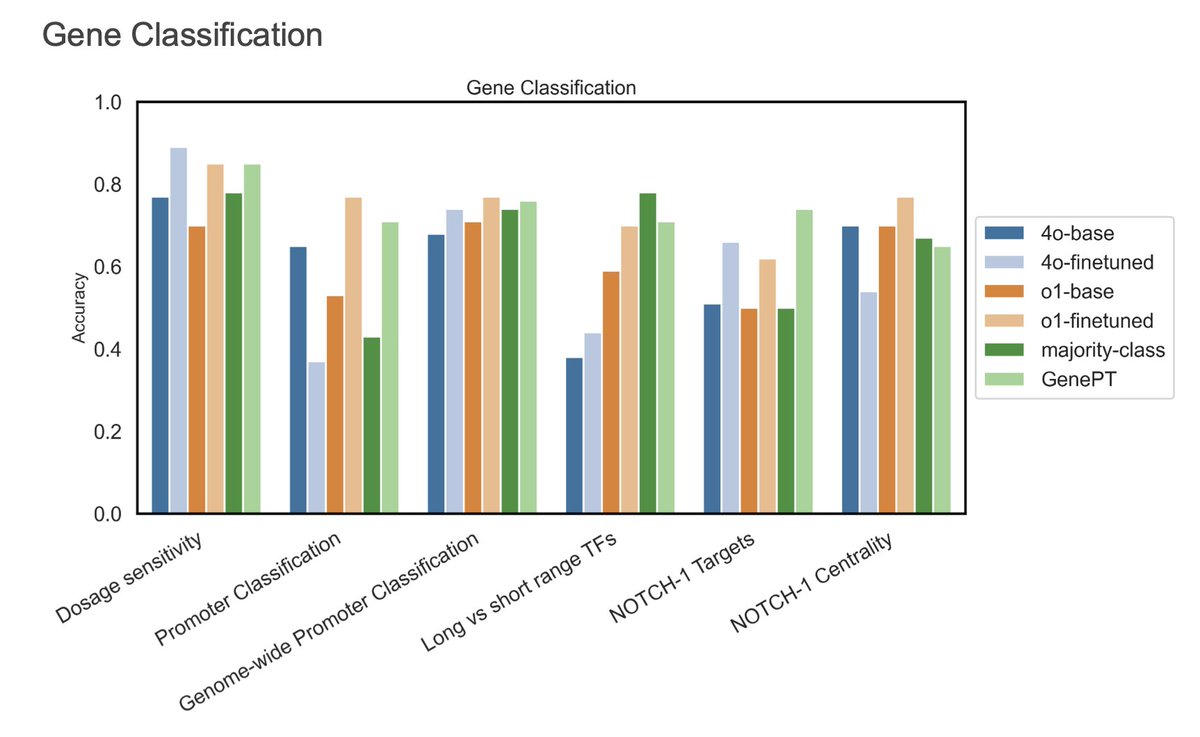
2.The authors evaluate o1-mini across two domains—gene classification and small molecule property prediction—and show that RL finetuning leads to substantial performance gains in gene classification tasks.
3.On five gene classification benchmarks, RL-finetuned o1-mini (o1-finetuned) outperforms GPT-4o-mini (4o-finetuned) and matches or exceeds the performance of domain-specific models like GenePT, achieving top accuracy (0.75) and F1 score (0.75).
4.Notably, the RL-tuned o1-mini provides more precise and biologically informed reasoning—for example, correctly identifying non-methylated promoter states and accurately classifying transcription factor sensitivity—where the base model failed.
5.In contrast, small molecule property prediction yielded mixed results. Though finetuning improves metrics, many of these gains come from shortcut behavior like always predicting the majority class, reducing interpretability and biological value.
6.For datasets with high class imbalance (e.g., 84% inactive samples), o1-finetuned collapses to trivial predictions, emphasizing the need for class-balancing or more informative reward functions in RL training.
7.The study also benchmarks against Chemprop, a GNN model specialized in chemical property prediction. Chemprop consistently outperforms the LLMs in ADMET prediction tasks, especially when structural reasoning is crucial.
8.The most promising result beyond gene classification was on P-gp inhibition, where o1-finetuned outperformed both Chemprop and baseline models, suggesting some LLM potential for specific molecule classes.
9.For antibiotic prediction, class balancing greatly improved LLM performance. However, even with balancing, Chemprop still outperformed LLMs when SMILES strings were used, underscoring the current strength of GNNs for molecular data.
10.This work highlights both the potential and limitations of adapting reasoning-focused LLMs for biomedicine. RL finetuning can enhance structured reasoning in genomics but may fall short for molecular tasks unless supported by robust data and task design.
11.The authors advocate for continued research into task-specific prompt design, reward function engineering, and hybrid modeling to fully unlock the potential of reasoning LLMs in biomedical applications.
💻Code: github.com/swansonk14/biomed…
📜Paper: biorxiv.org/content/10.1101/…
#BioLLM #ReinforcementLearning #GeneFunction #DrugDiscovery #GPT4o #o1mini #BiomedicalAI #MolecularReasoning #LLMFinetuning #Chemprop #AI4Science #PrecisionMedicine
3
13
1,365

17 Feb 2025
🧬 Discover the Key to Effective siRNA Transfection!
Are you ready to take your gene function studies to the next level? In this video, we dive deep into the essential things you need to know before performing siRNA transfection. siRNA (small interfering RNA) is a game-changing tool for both gene function research and therapeutic development, but achieving successful transfection requires precision and expertise.
🔍 What You’ll Learn:
✅How to choose the right siRNA for your specific research goals.
✅Selecting the best transfection reagents and cell lines for optimal results.
✅Step-by-step guidance on optimizing transfection conditions to maximize efficiency.
✅Pro tips and common mistakes to avoid—ensuring your experiments run smoothly and yield reliable data.
Whether you're a beginner just starting out or an experienced researcher looking to refine your techniques, this video is packed with actionable insights to help you achieve better outcomes in your siRNA transfection experiments.
🎥 Don’t miss out! Watch now and elevate your research game. Hit that like button, subscribe for more expert tips, and let us know in the comments what topics you’d like us to cover next!
👉youtu.be/zQwuyZzYEIo
#siRNA #Transfection #GeneFunction #ResearchTips #Therapeutics #LabLife #ScienceMadeSimple
Why wait? Your next breakthrough starts here! 🚀
2
58

13 Feb 2025
Explore the genome-wide atlas of human cell morphology: CRISPR-Cas9 knockouts for 20,000 genes, 30M cells using PERISCOPE & Cell Painting! #GeneFunction 🎨🔬 PMID:39870862, Nat Methods 2025, @naturemethods @OTSociety doi.org/10.1038/s41592-024-0…
3
79

26 Dec 2024
#TropicalPlants
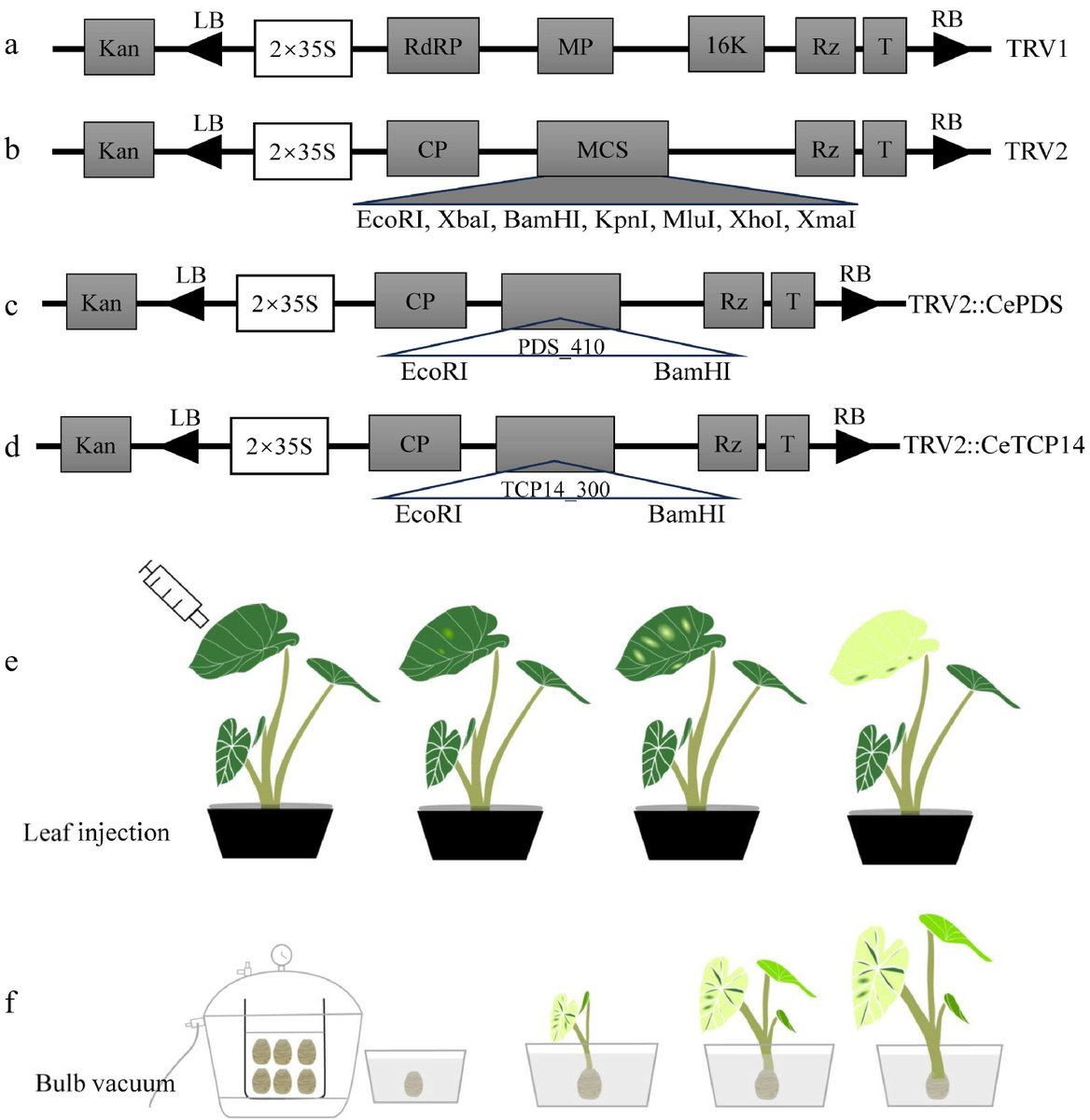
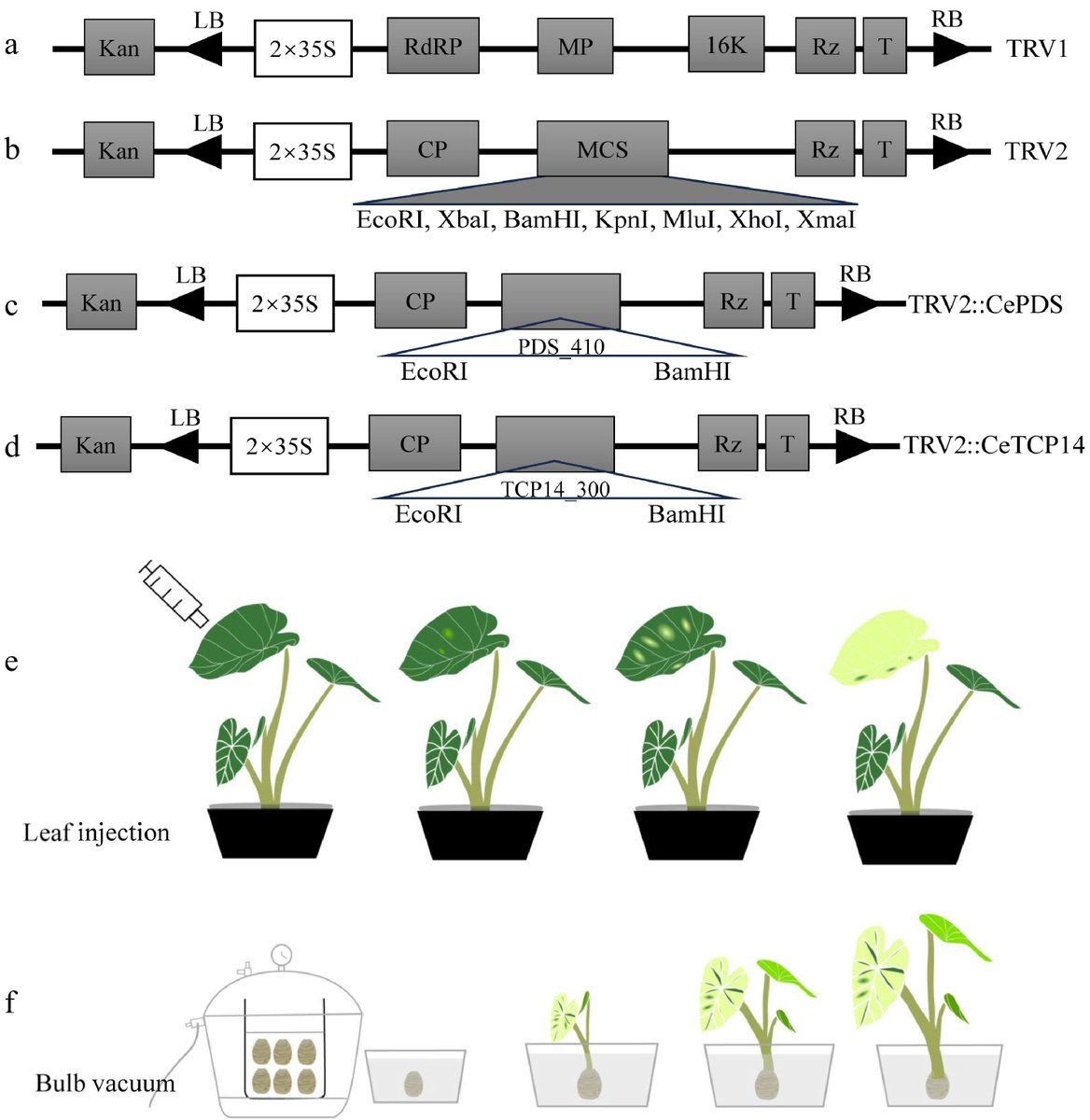
Unveiling the Potent TRV-based VIGS System in Taro!
@PlantSciRes #Taro #GeneFunction #TRV
Details: maxapress.com/article/doi/10…
1
6
285
8 Dec 2024
Simple and effective embedding model for single-cell biology built from ChatGPT @natBME
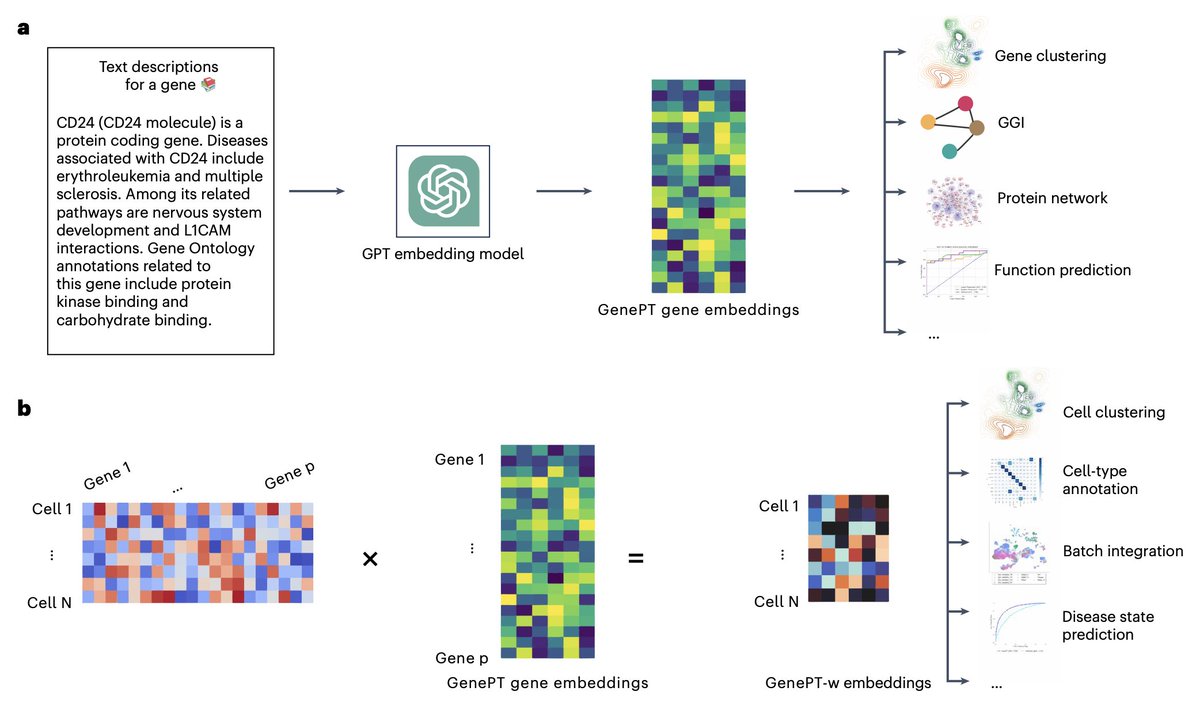
1. Introducing GenePT, a novel model leveraging ChatGPT to create gene and cell embeddings directly from natural language descriptions, bypassing the need for massive expression datasets.
2. GenePT excels in downstream tasks like gene function classification, gene-gene interactions (GGI), and protein-protein interactions (PPI), often matching or surpassing models trained on millions of cells.
3. The innovation lies in utilizing ChatGPT-generated embeddings from curated gene summaries, which are weighted by expression levels or sequenced into sentences for cellular embeddings.
4. GenePT demonstrates robustness across biological datasets, outperforming traditional expression-based models in disease phenotype predictions and batch effect elimination.
5. The simplicity of GenePT enables efficient use of pretrained embeddings for fine-tuning, significantly boosting performance in specialized tasks like cardiomyopathy and lupus phenotyping.
6. Unlike expression-based models, GenePT incorporates biomedical literature, capturing a broader spectrum of gene functionalities and reducing reliance on costly data preprocessing.
7. GenePT opens pathways for integrating language models with biological data, paving the way for innovative applications in genomics, transcriptomics, and beyond.
@james_y_zou @yc_yc_yc_yc
💻Code: github.com/yiqunchen/GenePT
📜Paper: nature.com/articles/s41551-0…
#Bioinformatics #ChatGPT #SingleCellBiology #GeneFunction #MachineLearning
2
11
2,425

5 Dec 2024
#TropicalPlants
Unveiling the Potent TRV-based VIGS System in Taro!
@MaximumAcademic #Taro #GeneFunction #TRV
Details: maxapress.com/article/doi/10…
4
66

15 Sep 2024
PerturbDB for unraveling gene functions and regulatory networks. #CRISPR #SingleCell #scRNAseq #GeneFunction #RegulatoryNetworks @NAR_Open
academic.oup.com/nar/advance…
1
9
35
2,446

8 Sep 2024
PmDAM6 gene orchestrates apple bud dormancy by regulating lipids, hormones & cell division. Insights into metabolic pathways. #BudDormancy #GeneFunction @OxfordJournals
Details:doi.org/10.1093/hr/uhae102
2
9
356

9 Jul 2024
A high-efficiency transient expression system mediated by Agrobacterium tumefaciens in Spinacia oleracea leaves
Full text:
tinyurl.com/mvb7jrn7
#GeneFunction #ProteinExpression #TransientExpression
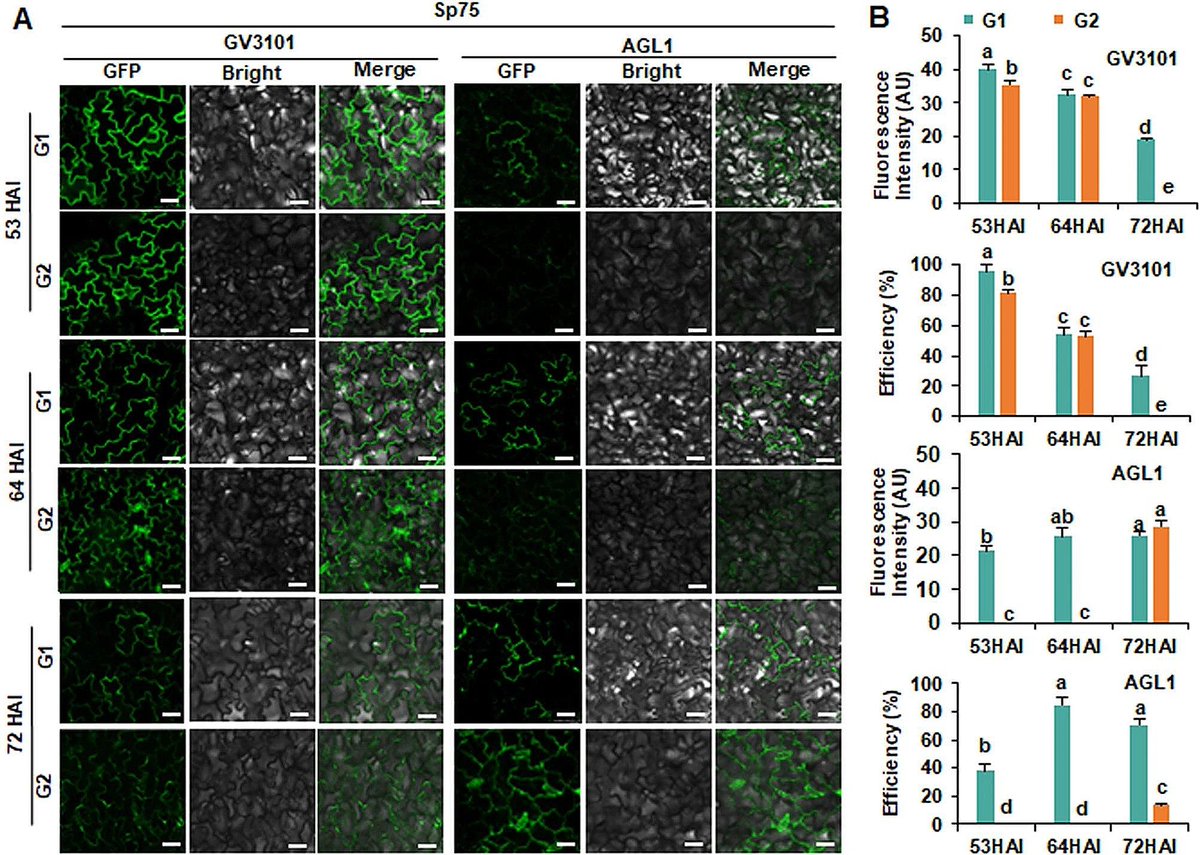
ALT Transient expression of HopF2-GFP in spinach Sp75 at the four-leaf stage. (A) GFP fluorescence images. G1 and G2 were infiltrated with Agrobacterium strain GV3101 (pSoup-p19) and AGL1 harboring pCAMBIA2300-HopF2-GFP constructs to observe the GFP fluorescence signal at 53 h, 64 h, 72 h after injection (HAI). Scale bar = 50 μm. (B) Fluorescent intensity and transformation efficiency of HopF2-GFP in Sp75 leaves using Agrobacterium strain GV3101 (pSoup-p19) and AGL1 at 53HAI, 64 HAI, 72HAI. AU: arbitrary unit. The experiments were repeated three times with similar results. Data presented are mean values ± SD (n ≥ 6). Different letters represent significant differences determined by one-way ANOVA with Tukey’s post hoc test (P < 0.05)
2
9
389
2 Jul 2024
Revealing gene function with statistical inference at single-cell resolution. #SingleCell #GeneFunction #StatisticalInference @NatureRevGenet
nature.com/articles/s41576-0…
1
6
21
1,359

Our Discovering #Unknome Function (DUF) Advanced Research Concept (ARC) seeks to annotate unknown #genefunction in days, not decades! Great opportunity for #postdocs working on any #CellLine, #virus, or #cell-free system.
Learn more here: ow.ly/9zqQ50QwYC0

10
17
49
11,190

3 Jul 2023
The goal is to understand #genefunction, study disease mechanisms, develop novel #therapies, and improve various aspects of #agriculture and #biotechnology.
3
36

11 Feb 2023
CRISPR activation (CRISPRa) allows researchers to up-regulate specific #genefunction by activating #transcription, without editing the DNA.
#CRISPR without cutting 🚫✂️🧬
@HZDiscovery #LorneCancer2023 #LorneGenome

2
382

15 Jan 2023
Study: Alcohol Exposure in Pregnancy Changes Embryo Gene Function via @BMCMedicine
#PAE #Prenatal #Alcohol #GeneFunction #Pregnancy #FASD
healthnews.com/news/study-al…
2
2
332

8 Dec 2022
#canSERV_EU partner presentation #10: @InfrafrontierEU - European #ResearchInfrastructure for #DiseaseModels! 👋
It offers various services for #CancerResearchers & leads the efforts concerning #InVivoModels in canSERV.
#GeneticAlterations #GeneFunction
infrafrontier.eu

5
22 Jun 2022
Mapping information-rich genotype-phenotype landscapes with genome-scale Perturb-seq. #SingleCell #CRISPR #scRNAseq #GeneFunction
cell.com/cell/fulltext/S0092… @CellCellPress
3
1
20 Apr 2022
CRISPR activation (CRISPRa) allows researchers to up-regulate specific #genefunction by activating #transcription, without editing the DNA.
#CRISPR without cutting 🚫✂️🧬
@HZDiscovery #Genomics #scicomm

3
3