
Jun 11
📢Call for papers | Special Issue on #Software-Hardware Co-design for Efficient #Computing in World Models
Submission Deadline: 31 December 2026
👉More details: ow.ly/yhOW50Z6X3M
We welcome your contributions.😀
#ComputingInnovation #CallForPapers #SystemOptimization

23

Small issues across pumps, valves, traps, and controls can add up to big system problems. APM Steam’s system optimization services help align steam and condensate systems so your facility can run smoothly. bit.ly/4mxonnN #SystemOptimization #EnergyManagement

4

🚀 Day 65 | Part 91/200
System performance optimization ensures that a digital platform runs efficiently under all conditions 🌍
It reduces delays
Improves response speed
And enhances overall user experience ⚡
Inside the InterLink ecosystem, optimization allows LinkersMap to handle increasing activity without slowing down 🚀
Better performance leads to smoother interactions
And a more reliable platform for users and businesses 🔗
Optimization is a continuous process that keeps the system strong and efficient 🌱
#InterLink #ITL #ITLG #SystemOptimization

1
5

Apr 25
Replace the fragmented stack. 🧩
Why juggle multiple tools when one powerful suite does it all? Consolidate 16 security and optimization tools into a single, streamlined solution.
Less complexity. More control.
#CyberSecurity #AllInOne #TechEfficiency #SystemOptimization #DigitalSecurity #PrivacyTools #InfoSec #SimplifyTech #Fvtal #Stealth

8
11
111
Apr 25
Reduce your monthly overhead. 💡
Stop paying for fragmented tools and overpriced VPNs. Get a complete, all-in-one solution that secures, optimizes, and simplifies without the extra cost.
More power. Less spending.
#CyberSecurity #CostEfficiency #TechSavings #VPNAlternative #DigitalSecurity #SmartTech #SystemOptimization #InfoSec #Fvtal #Stealth

9
12
97
Apr 24
Reclaim absolute authority. 🛡️
Your system. Your rules. Experience optimized performance and uncompromising privacy without complexity or compromise.
Take control. Stay in command.
#CyberSecurity #DigitalControl #PrivacyFirst #SystemOptimization #TechPower #InfoSec #SecureYourSystem #Fvtal #Stealth

7
12
116
Apr 23
Power up. Vanish instantly. ⚡👻
Activate a full suite of 16 precision tools designed to secure, optimize, and elevate your Windows experience in seconds.
Maximum power. Zero visibility.
#CyberSecurity #WindowsPerformance #PrivacyTools #DigitalStealth #SystemOptimization #TechPower #InfoSec #StayInvisible #Fvtal #Stealth

7
10
100
Apr 20
Optimize your hardware. ⚙️
Unlock maximum performance by eliminating background bloat and fine tuning your system with precision tools.
Less noise. More power.
#Performance #HardwareOptimization #TechPerformance #SystemOptimization #CyberSecurity #DigitalEfficiency #PCPerformance #InfoSec #Fvtal #Stealth

7
10
93

Apr 17
BAF continues to upgrade its core algorithms and risk control modules.
With one goal:To make every operation more controllable.
#BAF #AlgorithmUpgrade #RiskControl #SystemOptimization

26
1,820

Apr 4
Log: SELF_HELP_REFACORING. 🧠📉
La mentira más grande es el "Over-engineering" de la vida. Nos vendieron que somos un software que debe optimizarse cada 24 horas, ignorando que el hardware (nuestro cerebro y cuerpo) tiene límites físicos de termodinámica.
Intentar correr "Hustle_Culture.exe" en un sistema que no ha dormido es como querer procesar Big Data en una calculadora: el sistema va a entrar en Kernel Panic tarde o temprano. La verdadera optimización no es hacer más, es dejar de ejecutar procesos basura que solo consumen RAM mental. ☕️🤮
#SystemOptimization #TechAnalyst #NullSudo #RealTalk
1
6
431

🚨⚙️ Design. Build. Optimize. Repeat.⚡️
#MechanicalEngineering #IndustrialAutomation #MassProduction #SystemOptimization #TechInnovation
1
1
15
639
Mar 24
Your Windows security stack shouldn’t be scattered across outdated tools.
Stealth unifies performance, protection, and control into one optimized system.
#WindowsSecurity #CyberSecurity #SystemOptimization #DigitalPrivacy #StealthPro

5
12
86
Mar 23
One toolkit. Total control.
From system cleanup to performance optimization, everything you need lives in one interface.
#StealthPro #CyberSecurity #SystemOptimization #PCPerformance #AllInOne #TechTools #DigitalSecurity #WindowsTools #Productivity #SecureSystem

3
11
49
Mar 23
One platform. Total system control.
Clean, optimize, and secure your system while keeping your communications protected.
#CyberSecurity #SystemOptimization #WindowsSecurity #PrivacyTools #StealthPro
3
12
47

Mar 20
Microsoft Details Windows 11 Performance Roadmap for 2026 #windows11performance #microsoftwindows #systemoptimization anavem.com/en/news/microsoft…
6
179
Mar 18
Stealth Drivers: total control over your system’s core.
Monitor, update, and optimize every driver from one place—eliminate instability, boost performance, and keep your machine running at peak precision.
No conflicts. No outdated drivers. Just clean performance.
#Stealth #Drivers #SystemOptimization #Windows #Performance
5
10
91
Mar 16
Squeeze every frame. Clear RAM, eliminate background lag, and keep your system locked in for competitive play with Stealth Gaming Mode.
#Stealth #GamingMode #Performance #MobileGaming #SystemOptimization

1
8
11
109

Mar 11
Marginal gains are rarely marginal at scale. Across multi-megawatt environments, incremental efficiency shifts translate into measurable financial performance. 📊
Across sustained load conditions:
✅ Reduced cooling demand
✅ Increased operational stability
✅ Lower incident frequency
Small optimizations compound across machine density and operating hours, converting engineering discipline into economic advantage. ⚙️
BiXBiT USA prioritizes systemic performance modeling, thermal balance integrity, and load resilience — because durable gains originate in design, not dashboards. 🧠
Engineering compounds. 📈
📩 Model your efficiency gain → info@BiXBiTUSA.io
#BiXBiTUSA #OperationalEfficiency #MiningEconomics #EnergyOptimization #InfrastructureReturns #InfrastructureEngineering #ThermalManagement #PowerDistribution #SystemOptimization #LoadBalancing #IndustrialCooling #MissionCritical #CapacityPlanning #RiskMitigation #EngineeringDiscipline #DataCenterDesign #OperationalStability #EnergyInfrastructure #PerformanceEngineering #ScalableSystems

2
23

ODBIT: Secure Wins as BTC Hits $74K
BTC broke $74,000! ODBIT’s Supercar Mode delivers millisecond execution to beat congestion. Lock in optimal entries and stay ahead of the crowd with precision.
#BTCPump #SmartTrading #DigitalAssets #Fintech #SystemOptimization #RiskManagement

10
2
12
1,434

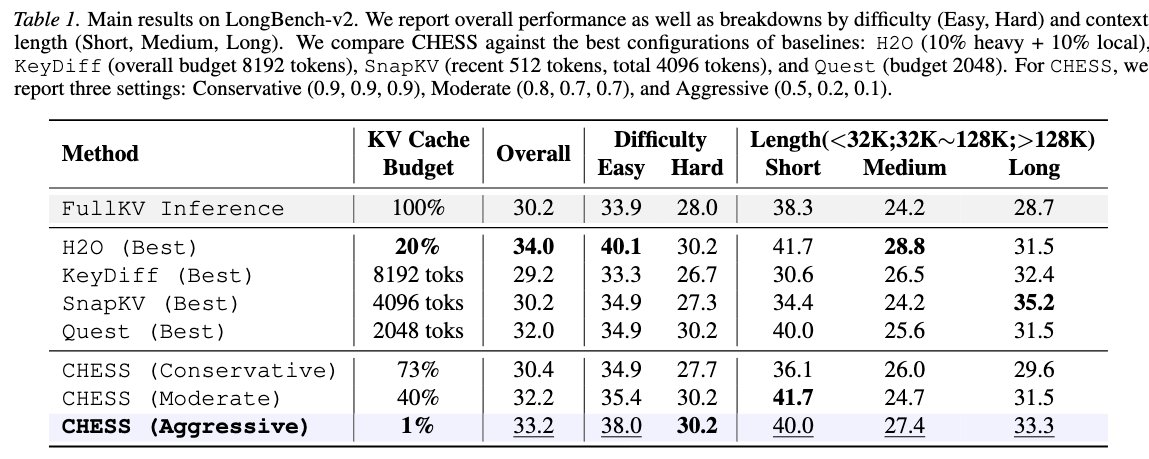
Excited to share our latest work: CHESS♟️ (Context-aware Hierarchical Efficient Semantic Selection)!
Long-context LLM inference is severely bottlenecked by massive KV caches. Prior pruning methods often sacrifice generation quality or fail to deliver real speedups. We solved this with a novel algorithm-system co-design:
🔥 Key Highlights:
• 1% KV Cache: Achieves Full-KV generation quality by dynamically selecting semantically coherent tokens step-by-step.
• 4.56x Throughput: Translates algorithmic sparsity into massive wall-clock acceleration via a custom zero-copy inference engine built atop PagedAttention.
No more trading off between accuracy and speed in long-context tasks!
📖 Paper: arxiv.org/abs/2602.20732
💻 Code: anonymous.4open.science/r/CH…
Huge thanks to my brilliant co-authors Guozhong Li, Chenxi Liu, and Prof. Panos Kalnis. Would love to hear your feedback! 👇
#LLMs #MachineLearning #GenerativeAI #SystemOptimization #KAUST

2
8
2,911