
2 Dec 2025
🚀 Heading to #NeurIPS 2025 in San Diego!
Proud to present two posters with my students:
• SUMO — “Subspace-Aware Moment-Orthogonalization” — a new optimizer that speeds up convergence, cuts memory demands, and boosts performance. Catch us on Wednesday, Exhibit Hall C,D,E #910, 11:00–14:00 PST. 📈 arXiv: arxiv.org/abs/2505.24749
• TANDEM — “Hybrid Autoencoders for Tabular Data” — a model-based augmentation scheme that combines decision-tree and neural encoders to push the boundaries of NNs in low-label settings. See us on Friday, Exhibit Hall C,D,E #3416, 11:00–14:00 PST. 🚀 NeurIPS page: neurips.cc/virtual/2025/post…
If you’re into tabular data, efficient fine-tuning, or anything close to my line of research, come say hi and chat! 🙌
#machinelearning #tabulardata #LLMs #selfsupervised #NeurIPS25
11
538

Daily Tech Gem #30
How AI learned to see on its own
🎥 Watch: youtu.be/oGTasd3cliM
Dive into DINOv3 and the breakthrough methods of self-supervised vision.
#AI #Vision #SelfSupervised #DINOv3 #DeepLearning #TechGem #DailyTechGem
4
322

9 Sep 2025
Open, strong, and practical: OpenVLA (7B) trains on ~970k demos and beats RT‑2‑X (55B) by ~16.5% on manipulation tasks. Code checkpoints consumer‑GPU fine‑tuning quantized serving.
@svlevine @percyliang @chelseabfinn
@physical_int
arxiv.org/abs/2406.09246
openvla.github.io
#AI #MachineLearning #DeepLearning #GenAI #LLMs #Multimodal #RepresentationLearning #SelfSupervised #CausalML #ProbabilisticML #Optimization #AIResearch
#PhysicalIntelligence #EmbodiedAI #Robotics #RobotLearning #ReinforcementLearning #ImitationLearning #ModelBasedRL #OfflineRL #MultiAgent #Sim2Real #SLAM #Perception #Manipulation #Humanoids #LeggedRobotics
#StanfordAI #StanfordHAI #CSAIL #MITCSAIL #BAIR #BerkeleyAI #BerkeleyRobotics #StanfordRobotics #MITRobotics
#AppliedAI #MLOps #LLMOps #RAG #VectorDB #PromptEngineering #AgenticAI #AIAgents #AIOps #ModelEvaluation #ResponsibleAI #AISafety
1
6
3,905

29 Jun 2025
Bimodal masked language modeling for RNA-seq and DNA methylation representation learning
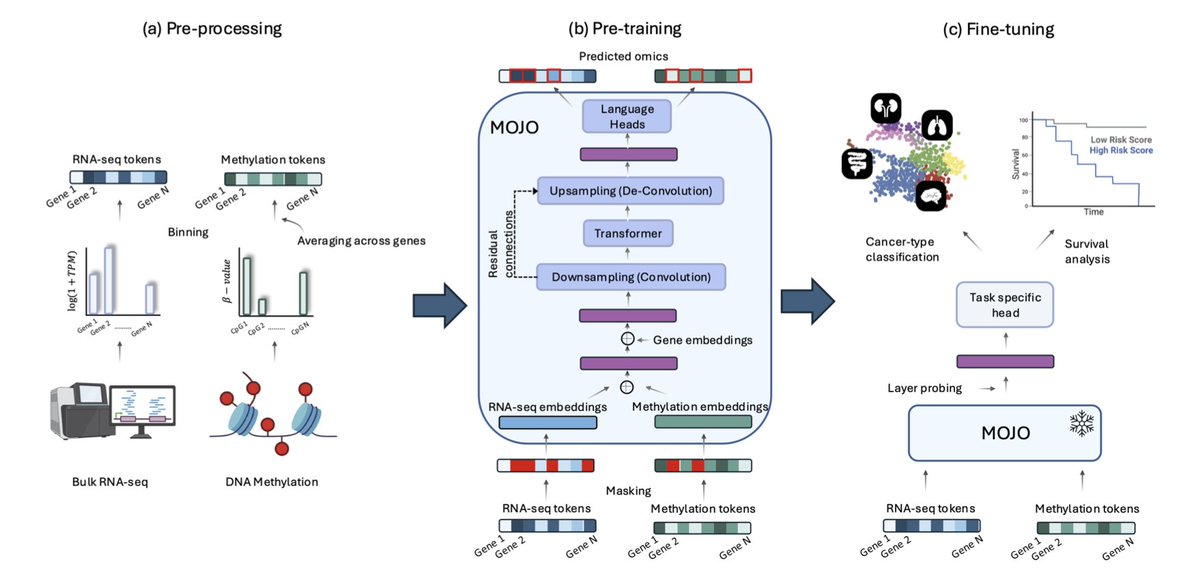
1.This work introduces MOJO, a bimodal masked language model that learns joint representations of bulk RNA-seq and DNA methylation data using self-supervised learning. The model achieves state-of-the-art performance across cancer-type classification, survival prediction, and zero-shot clustering.
2.Unlike late integration approaches that combine separately pretrained models, MOJO is trained end-to-end on both modalities, capturing interactions between RNA-seq and methylation signals from the start. This joint modeling leads to improved generalization and representation quality.
3.MOJO combines convolutional layers with transformers to handle the long-range dependencies and high dimensionality of omics data efficiently. This hybrid architecture enables 100× faster training steps compared to purely transformer-based bimodal models.
4.The model is pre-trained on over 9,000 samples from the TCGA dataset using a bimodal masked language modeling objective, which corrupts 15% of tokens across both modalities to encourage joint representation learning.
5.In pan-cancer classification (33 cancer types), MOJO outperforms strong baselines including BulkRNABert, MethFormer, and CustOmics. It achieves a test macro-F1 of 0.935 and weighted-F1 of 0.952, showing notable gains even over sophisticated late integration methods using cross-attention.
6.For survival analysis, MOJO again outperforms unimodal and late integration baselines, achieving a C-index of 0.771 and weighted C-index of 0.670. These results indicate robust modeling of time-to-event prediction using joint omics embeddings.
7.The learned embeddings show strong zero-shot performance in breast cancer subtyping (PAM50) and pan-cancer cohort clustering, with MOJO achieving 0.777 accuracy for PAM50 and 0.928 for pan-cancer—better than late integration.
8.To tackle the real-world challenge of missing modalities, the authors propose two mechanisms: (i) re-training with incomplete modality samples (MOJO-MMO), and (ii) a mutual information auxiliary loss during fine-tuning, which regularizes the model to produce consistent outputs across partial inputs.
9.When either RNA-seq or methylation is missing at test time, the mutual information strategy allows MOJO to recover performance close to modality-specific models (e.g., from 0.538 to 0.916 weighted-F1 when RNA-seq is absent).
10.Overall, MOJO offers a scalable, performant, and robust approach to multi-omics integration, making it well-suited for clinical applications involving heterogeneous and incomplete datasets.
💻Code: github.com/instadeepai/multi…
📜Paper: biorxiv.org/content/10.1101/…
#RNAseq #DNAmethylation #MultiOmics #MaskedLanguageModel #Cancer #RepresentationLearning #Bioinformatics #SelfSupervised #TCGA #SurvivalAnalysis
3
9
1,001
23 Jun 2025
JASMINE: A powerful representation learning method for enhanced analysis of incomplete multi-omics data
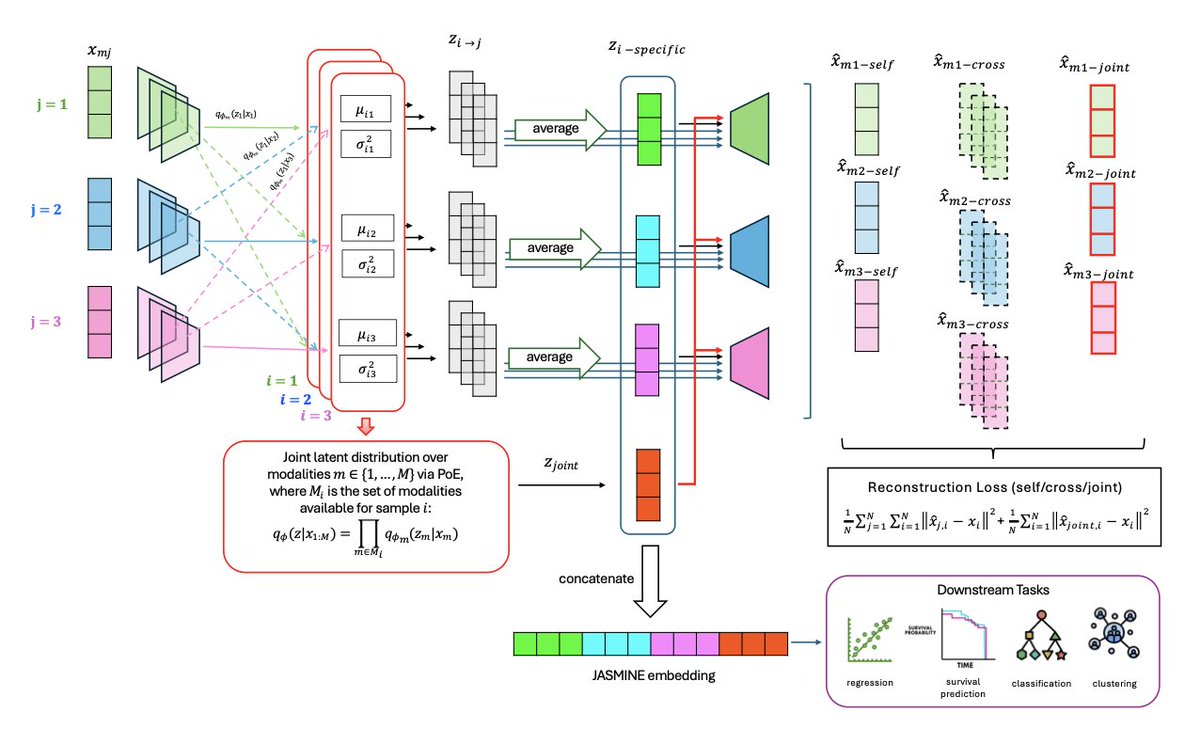
1.JASMINE is a new self-supervised representation learning framework designed to handle incomplete multi-omics data. Its key strength lies in learning compact embeddings that retain both shared and modality-specific information, enabling robust performance across diverse downstream tasks even under high rates of missing data.
2.Unlike many existing methods, JASMINE does not require retraining for each prediction task. A single training run per dataset produces task-agnostic embeddings that can be directly applied to classification, regression, survival prediction, or clustering.
3.To handle missing modalities, JASMINE combines cross-encoders (for modality-specific embeddings) and product-of-experts (PoE) models (for joint embeddings). These components are concatenated to form the final representations, allowing flexible integration of arbitrarily missing data.
4.JASMINE introduces dual contrastive learning: modality-level CL enforces consistency across modalities of the same sample, while sample-level CL uses deep clustering to preserve inter-sample relationships. This enhances the discriminative structure of the learned embeddings.
5.Orthogonality constraints are applied between joint and modality-specific representations to reduce redundancy and encourage the learning of complementary features, aligning with biological principles like consensus and complementarity.
6.In simulation studies, JASMINE outperformed baselines (MVAE, CLUE, IntegrAO, DCCA, GCCA) especially under extreme missingness (up to 99%) and unbalanced missing patterns. It was particularly robust when the number of modalities increased and the sample size was small.
7.In real-world data from TCGA (cancer) and ADNI (Alzheimer’s), JASMINE achieved top or near-top performance in all tasks.
8.Interpretability analyses revealed that the most predictive embedding feature (for cancer survival) aligned with known biological mechanisms. Enriched pathways included MAPK and Wnt signaling, GABA synthesis, and interleukin signaling—all well-documented in cancer progression literature.
9.JASMINE also revealed inter-modality biological correspondences. Key genes such as MAP2K1 and MAPK9 were identified across mRNA, methylation, proteomics, and miRNA layers, confirming that the model captures biologically meaningful cross-modal associations.
10.Overall, JASMINE presents a scalable, flexible, and biologically grounded solution for multi-omics integration, addressing both missing data and task generalization challenges in a principled manner.
💻Code: github.com/PennBBL/JASMINE
📜Paper: biorxiv.org/content/10.1101/…
#MultiOmics #RepresentationLearning #Bioinformatics #Alzheimers #CancerResearch #MachineLearning #DeepLearning #SelfSupervised #ContrastiveLearning #ComputationalBiology
3
592
23 Jun 2025
JASMINE: A powerful representation learning method for enhanced analysis of incomplete multi-omics data
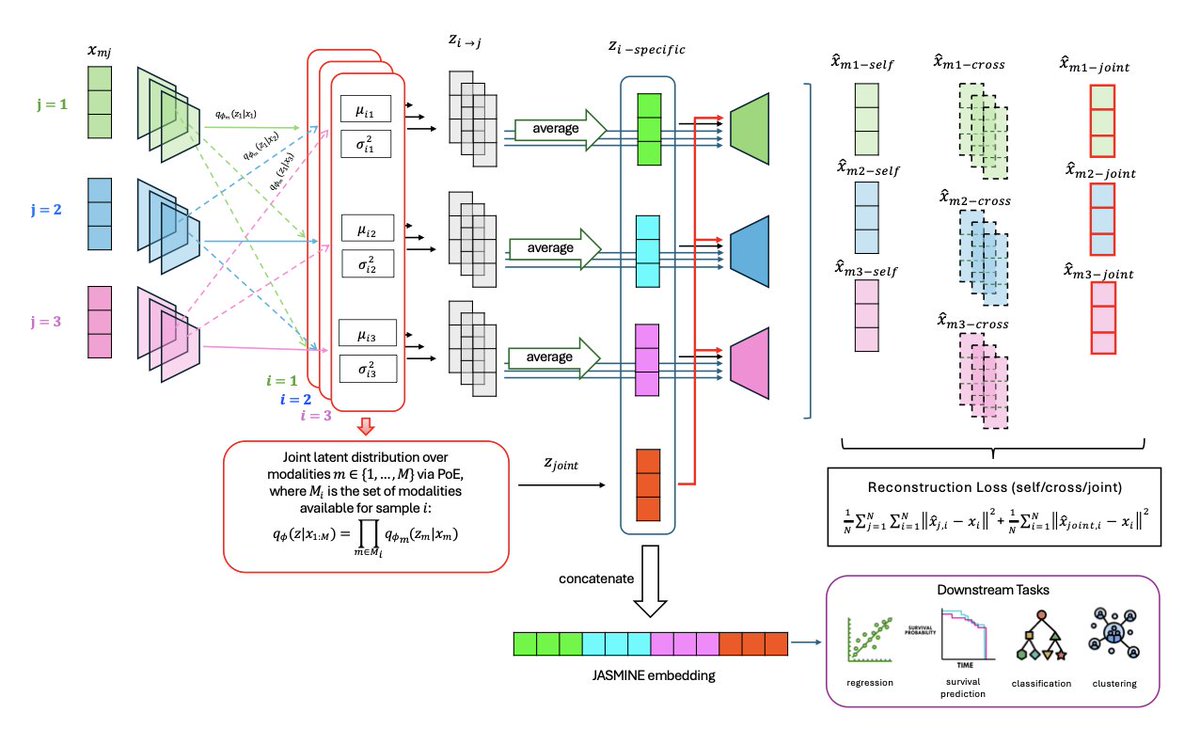
1.JASMINE is a new self-supervised representation learning framework designed to handle incomplete multi-omics data. Its key strength lies in learning compact embeddings that retain both shared and modality-specific information, enabling robust performance across diverse downstream tasks even under high rates of missing data.
2.Unlike many existing methods, JASMINE does not require retraining for each prediction task. A single training run per dataset produces task-agnostic embeddings that can be directly applied to classification, regression, survival prediction, or clustering.
3.To handle missing modalities, JASMINE combines cross-encoders (for modality-specific embeddings) and product-of-experts (PoE) models (for joint embeddings). These components are concatenated to form the final representations, allowing flexible integration of arbitrarily missing data.
4.JASMINE introduces dual contrastive learning: modality-level CL enforces consistency across modalities of the same sample, while sample-level CL uses deep clustering to preserve inter-sample relationships. This enhances the discriminative structure of the learned embeddings.
5.Orthogonality constraints are applied between joint and modality-specific representations to reduce redundancy and encourage the learning of complementary features, aligning with biological principles like consensus and complementarity.
6.In simulation studies, JASMINE outperformed baselines (MVAE, CLUE, IntegrAO, DCCA, GCCA) especially under extreme missingness (up to 99%) and unbalanced missing patterns. It was particularly robust when the number of modalities increased and the sample size was small.
7.In real-world data from TCGA (cancer) and ADNI (Alzheimer’s), JASMINE achieved top or near-top performance in all tasks.
8.Interpretability analyses revealed that the most predictive embedding feature (for cancer survival) aligned with known biological mechanisms. Enriched pathways included MAPK and Wnt signaling, GABA synthesis, and interleukin signaling—all well-documented in cancer progression literature.
9.JASMINE also revealed inter-modality biological correspondences. Key genes such as MAP2K1 and MAPK9 were identified across mRNA, methylation, proteomics, and miRNA layers, confirming that the model captures biologically meaningful cross-modal associations.
10.Overall, JASMINE presents a scalable, flexible, and biologically grounded solution for multi-omics integration, addressing both missing data and task generalization challenges in a principled manner.
💻Code: github.com/PennBBL/JASMINE
📜Paper: biorxiv.org/content/10.1101/…
#MultiOmics #RepresentationLearning #Bioinformatics #Alzheimers #CancerResearch #MachineLearning #DeepLearning #SelfSupervised #ContrastiveLearning #ComputationalBiology
1
7
748

26 May 2025
*Hits bong* Maps of Meaning can be reexpressed as a selfsupervised, variational autocatalytic loop where myths are decoder weights, heroes are optimization paths, dragons are KL spikes, and “meaning” is the subjective Hessian of surprise reduction
8
189

6位:自己教師あり学習 & Few-shot
→ ラベルなし・少量データでの学習がより実用レベルに
#SelfSupervised #FewShotLearning
7位:ロバスト性 & セキュリティ
→ 敵対的攻撃やノイズへの耐性を強化する研究が進行中
#AIセキュリティ #AdversarialAI
8位:軽量モデル(エッジ向け)
→ モバイルやARグラス時代を見据えた軽量化が進む
#EdgeAI #軽量モデル
9位:セマンティックセグメンテーション
→ Dense predictionの精度も処理速度もさらに進化
#SemanticSegmentation #CVPR
10位:合成データ & 拡張技術
→ 合成データで訓練→現実へ、という流れが当たり前に
#SyntheticData #データ拡張
3
995

Hi! This week in the robot learning seminar, we will have @Vinc3nt_Leroy from @naverlabseurope. His talk is titled "From CroCo to MASt3R: A Paradigm Change in 3D Vision?". See you at 11:30AM ET!
YouTube.com/@MontrealRobotic…
#foundationModels #vision
#selfSupervised

1
3
29
1,634

28 Oct 2024
I find the paper of Model Swarm quite insightful! @shangbinfeng
My thoughts:
- We might be able to finetune a group of models ASYNC
- These models, when selfsupervised, may model the world in a way that just like us exchanging info
Check out my blog: ideas.reify.ing/en/blog/mode…
1
3
477

19 Jun 2024
自己教師あり学習により 紙(可変形物体)を連続でめくるソフトグリッパー
youtu.be/1PJBxLhUe6g
#Flipbot #Paper_Flipping #learn #selfsupervised #soft_gripper #UR
8
30
1,960

12 Jun 2024
Huge congratulations to Ziang Xu to have successfully published his work (@IEEE_TMI) on #selfsupervised #learning for #endoscopic #imageanalysis. Limited data and #generalisation is a huge bottleneck for clinical translation.
Read here: ieeexplore.ieee.org/document…
1
4
374

22 May 2024
selfsupervisedでなんかしてオリエンテーションバイアスの影響減らしてるんですね。引退してあんまり追ってなかったので暇なときに読んでみます!
個人的には薬剤とかはちゃんと見えて確からしく置けてそうなケースなんて稀ですし、ルール理解してない解析にAF2の構造フィットしてるから(ry
2
87

27 Mar 2024
האם הלייבלים שלך אמינים? אם לא, נסי לטייב את התיוג. אם כן, 500 תצפיות זה מעט. תנסי להתחיל מ pretraining במודל שהוא selfsupervised. כמובן בהנחה שיש לך גישה לכמות גדולה של דאטה לא ממתוייג מאותו דומיין.
1
2
220

26 Feb 2024
Dr. @pascalefung’s #keynote talk at #AAAI2024: “Machines Make Up Stuff: Why Do Generative Models Hallucinate?” @RealAAAI #LLMs #GenerativeAI #LargeVisionModels #multimodal #AI #AAAI #SelfSupervised #MachineLearning #transformers #RLHF #MLbias #AIrisks #AIharms #AIethics #AIsafety
3
3
7
945

27 Oct 2023
Selfsupervised is basically renamed unsupervised. That is why we dont hear unsupervised that often.
2
2
1,292

27 Oct 2023
Isn't that usually a form of selfsupervised training? For LLMs that's the form it takes.
1
2
304

10 Oct 2023
The exciting journey at our #AI4EOSymposium2023 @ai4eo_de continues with the last keynote. Super curious to hear from @blesa_ux (@ESA_EO Phi Lab) about the next generation #AI4EO ! My guess of the keywords will be #PaML, #Selfsupervised learning, #QML, #edgecomputing #DTE



1
3
16
2,521

10 Oct 2023
Our PhD student Yi Wang talks about #selfsupervised #learning with #Sentinels at our #AI4EOSymposium2023

3
353
10 Oct 2023
A big thanks to Yi who step in on a short notice to give a talk on #selfsupervised #learning replacing a canceled talk at our event #AI4EOSymposium2023. Take a look at our SSL4WO-S12 dataset! @ai4eo_de

4
679