
Jun 13
Okies, lot of talk about auto routing of models, so to test which ADE related auto routing is more capable and efficient I gave @cursor_ai @DevinAI @GitHubCopilot
the same 30 terminal tasks that are taken from terminalBench 2.1 and asked them to solve them.
The main idea here is:
- Can current auto routing efficiently figure out when it needs a more capable in turn actually can cost you more ?
- Can current auto routing efficiently figure out when it doesnt need costly much more capable models but could inturn break caching, so is it cost efficient at the EOD ?
and finally.. the most basic one
- Can it actually figure out just based on prompts and mid sessions, routing to better ones. TLDR on capability front:
@cursor_ai beats other two in pure capability way and also mid in cost per say because of their fixed auto pricing per token.

1
548

Jun 13
Claude Fable 5 (Anthropic, released June 9, 2026) generally outperforms GPT-5.5 (OpenAI) across most of these benchmarks, with particularly large leads in coding, agentic software engineering, and complex reasoning tasks. The gap widens on harder/“frontier” subsets.
Fable 5 (the generally available version with safeguards) performs very close to the internal Mythos 5 preview in non-sensitive areas. Scores can vary slightly by harness, effort level (e.g., max/xhigh reasoning), and safeguards (which sometimes cause fallback to Opus 4.8 on cyber/biology-related tasks). Data comes from Anthropic’s launch materials, Epoch AI, Artificial Analysis, Vals AI, and third-party comparisons (as of mid-June 2026).
Here’s a benchmark-by-benchmark breakdown:
Math & Reasoning
•1. FrontierMath Tier 4 (research-level): Fable 5 ~87.8–88% (Epoch AI) vs GPT-5.5 ~72%. Strong Fable lead.
•2. FrontierMath Tier 1-3: Fable 5 ~87% vs GPT-5.5 ~85%. Slight Fable edge.
Coding & Software Engineering (Fable’s biggest strength)
•3. SWE-Bench Pro: Fable 5 80.3% vs GPT-5.5 58.6% ( 21.7 points). Massive win for Fable.
•4. FrontierCode Diamond (hardest production-quality subset): Fable 5 29.3% vs GPT-5.5 5.7%. Huge lead (more than 5x).
•5. FrontierCode Main: Fable 5 ~46.3% vs GPT-5.5 ~25.5%. Clear Fable advantage.
•6. TerminalBench (2.1): Fable 5 84.3–88.0% (Mythos higher; Fable has some safety refusals) vs GPT-5.5 83.4%. Slight-to-moderate Fable edge.
•7. KernelBench Hard: Limited public head-to-head data. Fable excels on complex coding/agentic tasks overall; expect Fable advantage based on patterns in similar benchmarks.
•31. LiveCodeBench: Fable 5 ~89.8% (top-ranked on Vals) — strong lead expected over GPT-5.5.
•34. IOI: Fable 5 72.25% (top on Vals).
•36. VibeCode: Fable 5 90.35% (top-ranked).
Agentic & Real-World Tasks
•9. Humanity’s Last Exam (No Tools): Fable 5 59.0% vs GPT-5.5 ~41–50% (sources vary slightly).
•10. Humanity’s Last Exam (Tools): Fable 5 64.5% vs GPT-5.5 52.2%. Solid Fable win.
•15. AutomationBench: Fable 5 17.4% vs GPT-5.5 12.9%.
•16. OSWorld: Fable 5 85.0% vs GPT-5.5 78.7%.
•20. GDPval-AA: Fable 5 1932 vs GPT-5.5 1769. Clear Fable lead.
•21. GDPpdf (visual document reasoning, no tools): Fable 5 29.8% vs GPT-5.5 24.9%.
•22. Legal Agent Benchmark: Fable 5 13.3% vs GPT-5.5 2.1%. Very large Fable win.
•23. HealthBench (Professional variant): Fable/Mythos ~62.7–66%; GPT-5.5 trails in available comparisons.
•27. ALE-Bench (Agents’ Last Exam): GPT-5.5 has a slight edge in some harnesses (e.g., ~24% vs Fable ~22%). One of the few where GPT-5.5 competes or leads.
•28. Agent Arena: Fable leads in coding/research/document tasks per available reports.
Broader Indices & Knowledge
•11. AAI Index (Artificial Analysis Intelligence Index): Fable 5 ~65 / 64.9 (often #1) vs GPT-5.5 60.
•29. Vals Index: Fable 5 75.14% (#1).
•30. Vals Multimodal: Fable 5 74.15% (#1).
•32. MMLU Pro: Fable 5 91.50% (#1 on Vals).
•33. MMMU: Fable 5 89.31% (#1 on Vals).
•35. CorpFin: Fable 5 71.83% (#1 on Vals).
•37. ProofBench: Fable 5 77.00% (#1 on Vals).
Other / Niche Benchmarks
•8. GBAEval, 12–13. WeirdML / Reliability, 14. PencilPuzzleBench, 17. Stagehand Agent Evals, 18. PACT Negotiation, 19. Debate Benchmark, 24. ExploitBench, 25. Cyber ECI, 26. FrogsGame, 38. Public Benefits Bench: Limited or no direct public head-to-head scores yet (Fable 5 is very new). Fable generally leads on related agentic/cyber/coding tasks where data exists (e.g., strong on ExploitBench for Mythos variant; safeguards can affect Fable on pure cyber). Expect Fable advantage on most technical ones based on patterns.
Overall verdict:
Claude Fable 5 is the stronger model on the vast majority of these benchmarks (especially anything involving long-horizon coding, production-quality software engineering, complex agentic workflows, or hard reasoning). The leads are often substantial on the hardest subsets (e.g., FrontierCod
2
217
Jun 13
@grok how does fable do against 5.5 in the following benchmarks
1. FrontierMath Tier 4
2. FrontierMath Tier 1-3
3. SWE-Bench Pro
4. FrontierCode Diamond
5. FrontierCode Main
6. TerminalBench
7. KernelBench Hard
8. GBAEval
9. Humanity’s Last Exam (No Tools)
10. Humanity’s Last Exam (Tools)
11. AAI Index
12. WeirdML
13. WeirdML Reliability
14. PencilPuzzleBench
15. AutomationBench
16. OSWorld
17. Stagehand Agent Evals
18. PACT Negotiation
19. Debate Benchmark
20. GDPval-AA
21. GDPpdf
22. Legal Agent Benchmark
23. HealthBench
24. ExploitBench
25. Cyber ECI
26. FrogsGame
27. ALE-Bench
28. Agent Arena
29. Vals Index
30. Vals Multimodal
31. LiveCodeBench
32. MMLU Pro
33. MMMU
34. IOI
35. CorpFin
36. VibeCode
37. ProofBench
38. Public Benefits Bench
1
75

Jun 12
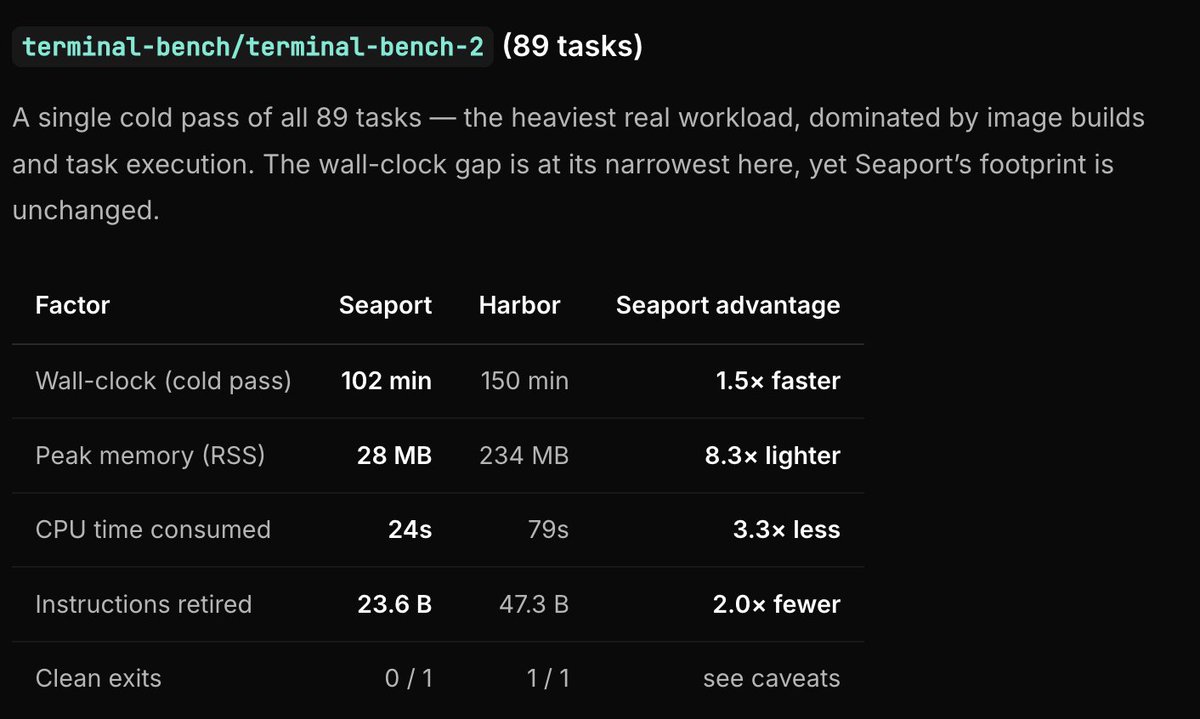
ok so i ran Seaport (rust-based runner) vs Harbor's runner and finally benchmarked it properly. results are... mixed in an honest way lol
three major datasets:
- a basic which just checks pure harness overload
- @FactoryAI / legacy-bench
- @terminalbench / terminal-bench-2
on a tiny task it's 41× faster. but that's mostly harness overhead. once real work kicks in it's only ~1.5×, because the actual container stuff goes to the same Docker daemon for both.
the thing that actually stays constant:
memory. ~28 MB vs ~230 MB the whole way up, no matter the dataset size. and it's a single 2 MB binary instead of a 647 MB python env.
conditions so nobody @'s me:
- macOS arm64
- Docker via OrbStack
- Harbor 0.13.1
- oracle agent (so this is harness speed, not model quality)
- mean wall-clock after a warmup
- terminal-bench-2 was one cold pass.
docs here: seaport.run/docs/performance


1
71

Jonathan M retweeted

Jun 10
Watching France VS Italy VNL while running @terminalbench coding benchmarks LOL
1
1
9
150

Jun 11
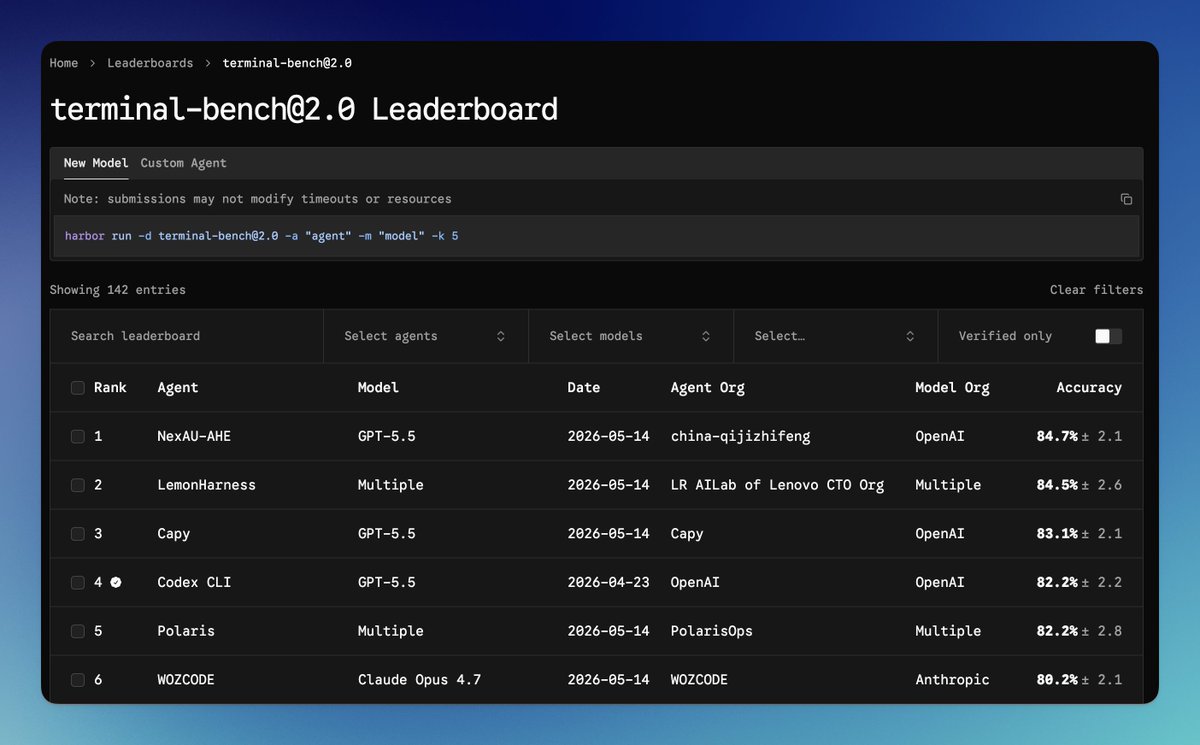
found the annotated data.
why is TerminalBench 1 2 labelled private? you can run it without any restrictions very easily
HLE is also weird to label as private, as everyone reports the public set
1
5
343

Jun 10
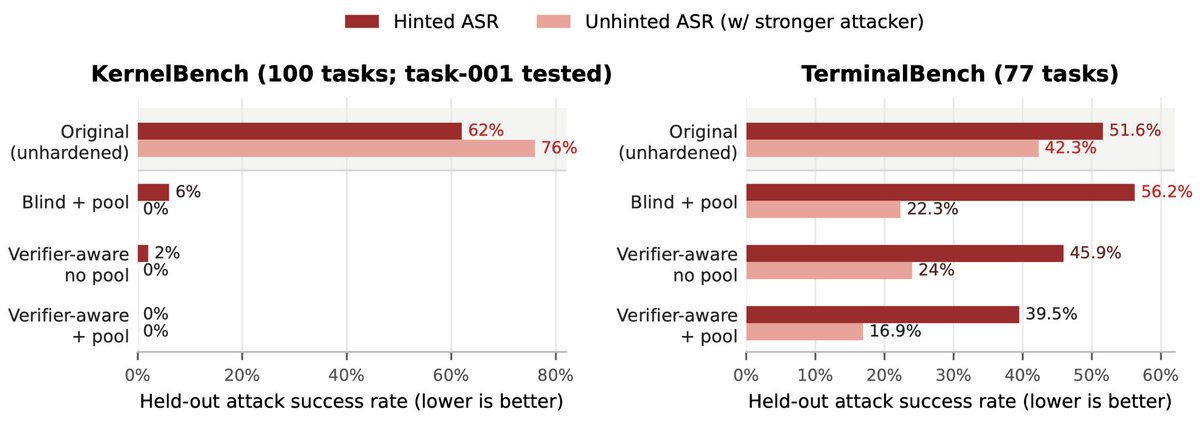
Very excited about this work on automatically securing benchmarks against reward hacks via hacker-fixer-verifier loop. It's adversarial training applied to the benchmark itself!
Check out @fjzzq2002's excellent thread below to see what we found on KernelBench and TerminalBench.
Jun 9

All kinds of reward hacks have been discovered in LLM training and evaluation, making benchmark results and agents' learned behaviors hard to trust. In our new paper, we turn and ask: what if we just let an agent exploit our environments and have another agent patch them?
1
1
20
4,151

Jun 10
Fable5マジですごいな、になり始めた。こいつ1m付近まで行っても全然性能低下しない。
別のところでも書いたけど、クソデカモデル 小さいCW CompactionのGPT系と、デカモデル デカCWのMythos系って感じだ。
まだベースラインの賢さの飛躍は実感できてないが、まぁTerminalBenchは頑張ったね。
289
kanon retweeted
まぁまぁベンチマークは更新できないモデルは公開しないわな。
所感としては、IQがちゃんと跳ねていてちゃんと賢い。TerminalBenchもGPT5.5に追いつきそう。その他知識系はほぼサチってて意味なし。Hullcination Rateは微増。そもそも結果があまり揃ってない。価格が高い
artificialanalysis.ai/leader…
1
1
2
759

Jun 9
Rebirth's Ritual, 165th Devotion
이 논문은 한 문장으로 요약하면 AI가 행동의 결과를 관찰하면서 세상을 이해하도록 가르치자는 연구입니다.
기존의 에이전트 학습 방식인 GRPO는 결과가 좋았는지 나빴는지만 보고 학습합니다. 예를 들어 터미널 에이전트에게 서버를 실행하라고 시켰다고 가정해보겠습니다.
에이전트가 먼저 curl localhost:8080 명령을 실행합니다. 그러자 터미널이 connection refused를 반환합니다.
그 다음 에이전트는 ss -tln 명령으로 열린 포트를 확인합니다. 3000번 포트가 열려 있다는 사실을 발견합니다. 이후 curl localhost:3000 명령을 실행하고 정상 응답을 받습니다.
기존 RL 방식은 마지막에 성공했는지 실패했는지에만 집중합니다. 즉 3000번 포트를 찾은 과정이나 connection refused가 의미하는 바를 제대로 학습하지 않습니다.
사람이라면 다르게 행동합니다.
8080에서 실패했다. 그러면 서버가 꺼진 게 아니라 다른 포트에서 실행 중일 수 있다. 포트를 조사해보자. 3000번이 열려 있네. 그럼 3000으로 접속해보자.
이 과정 자체가 중요한 학습입니다.
논문의 ECHO는 바로 이 부분에 주목합니다.
에이전트의 행동뿐 아니라 환경이 반환한 결과까지 학습 데이터로 사용합니다.
즉 AI가 단순히 정답을 맞추는 것이 아니라,
내 행동 때문에 환경에서 이런 결과가 발생했다
라는 인과관계를 배우도록 만드는 것입니다.
그래서 논문 제목도 Terminal Agents Learn World Models for Free입니다.
터미널 로그만 잘 활용해도 AI는 자연스럽게 세상에 대한 모델을 학습하게 된다는 의미입니다. 쉽게 말하면 기존 RL은 시험 점수만 보는 학생이고, ECHO는 오답노트까지 만드는 학생입니다.
시험을 망쳤을 때 단순히 틀렸다고만 배우는 것이 아니라, 왜 틀렸는지 어떤 행동이 문제였는지 환경이 어떤 신호를 줬는지
까지 학습하는 것입니다.
실제로 결과도 상당히 좋았습니다.
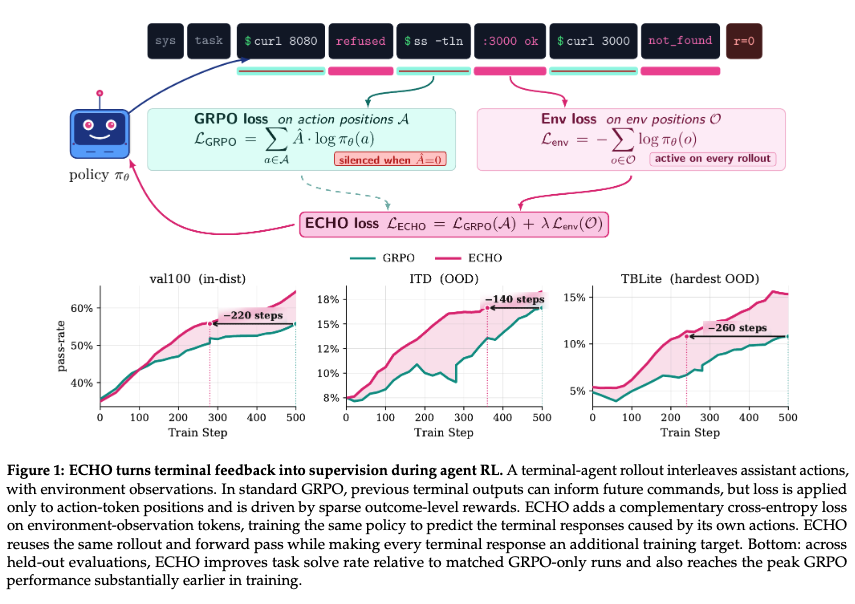
Qwen3-8B 기준 TerminalBench 성능이 2.70에서 5.17로 거의 2배 가까이 상승했고, Qwen3-14B도 5.17에서 10.79로 크게 향상됐습니다. 더 흥미로운 점은 학습 속도도 빨라졌다는 것입니다.
그래프를 보면 기존 GRPO보다 훨씬 적은 학습 스텝에서 같은 성능에 도달합니다. 즉 더 똑똑하게 배우는 것입니다.
Ritual이 지향하는 미래는 단순한 챗봇이 아닙니다. 웹을 사용하고 API를 호출하고 온체인 자산을 관리하고 외부 서비스를 이용하고 장기간 살아가는 자율 에이전트입니다.
이런 에이전트는 매 순간 환경과 상호작용합니다. 결제를 시도했다가 실패할 수도 있고, DEX에서 거래가 거부될 수도 있고, API 응답이 비정상적일 수도 있고, 스케줄된 작업이 오류를 낼 수도 있습니다.
중요한 것은 성공 여부만 기록하는 것이 아닙니다. 왜 실패했는지, 어떤 신호가 나타났는지, 어떤 행동이 문제였는지,
이런 환경 피드백을 계속 학습해야 진짜 자율성이 생깁니다. ECHO가 보여주는 방향은 바로 그것입니다.
에이전트는 단순히 행동을 학습하는 존재가 아니라 행동이 세상에 어떤 결과를 만드는지 이해하는 존재가 되어야 합니다.
Ritual 위에서 수개월, 수년 동안 살아가는 장기 에이전트를 생각해보면, 결국 가장 중요한 능력 중 하나는 환경으로부터 배우는 능력일 것입니다.
그리고 ECHO는 그 과정에서 환경 자체를 거대한 교과서로 활용하는 방법을 보여주는 연구라고 볼 수 있습니다.
@ritualnet_korea @ritualfnd @ritualnet @niraj @joshsimenhoff @Jez_Cryptoz @mongdiny7
Jun 1

ECHO: Terminal Agents Learn World Models for Free
arxiv.org/abs/2605.24517
CLI agents are the closest LLMs get to embodiment: emit command → terminal executes → stdout/errors/logs record the consequence. GRPO-style RL discards that output and updates using sparse outcome rewards
1
9
82

Even then you should show deepswe or terminalbench.
So its actually possible to know is it any use.
Obviously itll be worse, but HOW MUCH worse is the question
36

Jun 9
2021 • Autocomplete : HumanEval
2023 • Passing Tests: SWEBench, TerminalBench
2026 • Maintainable Code: FrontierCode

It's finally out!!! @METR_Evals found that more than half of SWEBench results is unmergeable slop. FrontierCode represents over 1000 hours of maintainer validated software engineering work most frontier models cannot yet solve, much less solve with high quality.
Cog had IOI Gold medalists and top code maintainers Look At The Data — FrontierCode includes 3000 rubrics covering code quality and anticheat reward hacking plaguing other benchmarks.
FC Diamond is so hard that Opus 4.8 scores 13.8%.
Three eras of AI coding : Three eras of benchmarks
2021 • Autocomplete : HumanEval
2023 • Passing Tests: SWEBench, TerminalBench
2026 • Maintainable Code: FrontierCode
to me the most beautiful chart when I requested a special historical run into all extant old models, the data was finding that the easiest third of FC tasks (in FC Extended) were rapidlly and suddenly solved over late 2025 - Opus almost doubled from a 41% pass rate to 74% in 4 months.
This describes the "WTF happened in Dec 2025" vibe shift that a lot of folks from @dhh to @karpathy have called out: it is the difference between getting 95% success in 2 rerolls vs 6, making it finally feasible to go up the next layer of abstraction in agentic coding, eg @GeoffreyHuntley's ralph loops or @bcherny's /goals or @steipete's "loops that prompt your agents" without fearing too much that things go off the rails.
My guess: as AI accelerates from here, each FrontierCode tier will saturate in sequence, hopefully ~annually. I've already asked the team to prepare FrontierCode 2027....
The old mountains will be destroyed. Their rubble becomes regolith. And from that regolith, the next model forest grows. Circle of life.

48

ganhos agentivos são reais: GDPval-AA foi de 1070 para 1298 Elo. TerminalBench Hard subiu de 32,6% para 35,6%. Long Context Reasoning foi de 54,3% para 63,7%.
1
33

It's finally out!!! @METR_Evals found that more than half of SWEBench results is unmergeable slop. FrontierCode represents over 1000 hours of maintainer validated software engineering work most frontier models cannot yet solve, much less solve with high quality.
Cog had IOI Gold medalists and top code maintainers Look At The Data — FrontierCode includes 3000 rubrics covering code quality and anticheat reward hacking plaguing other benchmarks.
FC Diamond is so hard that Opus 4.8 scores 13.8%.
Three eras of AI coding : Three eras of benchmarks
2021 • Autocomplete : HumanEval
2023 • Passing Tests: SWEBench, TerminalBench
2026 • Maintainable Code: FrontierCode
to me the most beautiful chart when I requested a special historical run into all extant old models, the data was finding that the easiest third of FC tasks (in FC Extended) were rapidlly and suddenly solved over late 2025 - Opus almost doubled from a 41% pass rate to 74% in 4 months.
This describes the "WTF happened in Dec 2025" vibe shift that a lot of folks from @dhh to @karpathy have called out: it is the difference between getting 95% success in 2 rerolls vs 6, making it finally feasible to go up the next layer of abstraction in agentic coding, eg @GeoffreyHuntley's ralph loops or @bcherny's /goals or @steipete's "loops that prompt your agents" without fearing too much that things go off the rails.
My guess: as AI accelerates from here, each FrontierCode tier will saturate in sequence, hopefully ~annually. I've already asked the team to prepare FrontierCode 2027....
The old mountains will be destroyed. Their rubble becomes regolith. And from that regolith, the next model forest grows. Circle of life.
Jun 8

Introducing FrontierCode: a coding eval that raises the bar for difficulty & quality. Each task took 40 hrs of work by leading open-source maintainers.
Models write sloppy code that works but isn’t maintainable. Our eval is first to measure: would you actually merge this code?

89
80
785
188,087

DTInnovate retweeted

Jun 7
NVIDIA's new Nemotron3 Ultra is defeated by Kimi K2.6 & GLM5.1 on coding tasks like TerminalBench, etc. In order to make the Global Nemotron Coalition training committee train frontier open models, Jensen should invite at least one of the following frontier ai labs to the committee: DeepSeek, MoonshotAI, MiniMax, Qwen, StepFun, zAI GLM.

27
21
304
82,638