
Jun 3
昨天字节Seed开源了一个非常有意思的checkpoint⬇️
TaskMem
它基于Qwen3-VL-30B-A3B训练,目标不是直接回答问题,而是让多模态Agent在视频/环境流里学会生成更有用的长期记忆。
重点是让Agent学会在连续视频/环境流里判断「什么值得被记住」,而不是把记忆当成简单摘要、RAG库或者剪贴板。
对应的论文叫《Task-Focused Memorization for Multimodal Agents》,作者是Tao Zou、Yichen He、Tian Qiu、Yuan Lin、Hang Li,来自ByteDance Seed和复旦。
论文里的核心方法是两阶段训练。
第一阶段学「怎么记」。
用RL训练记忆生成策略,让它生成准确、不重复、格式稳定、信息量足够的episodic memory。
论文里用GSPO做训练,奖励包括format、thinking length、quality、richness。
这里有个细节很有意思:他们专门加了richness reward,因为只优化质量会被模型钻空子,生成很短但看起来没错的记忆。
模型嘛,一旦发现考试漏洞,作弊速度比大学生还快。
第二阶段学「该记什么」。
部署后,根据最近环境里出现的任务/问题,训练一个很轻的adapter,让模型把记忆焦点转向未来更可能用到的信息。
论文里说这个adapter只有2048个可训练参数,主模型冻结,用DPO优化;它更像一个「任务方向的记忆偏置向量」。
实验设计很有意思,他们把VideoMME、EgoLife、EgoTempo改造成streaming任务。
Agent先看视频流并生成记忆,问题后出现,回答时不能再看原视频,只能看生成出来的记忆。
这个设定比普通视频问答更接近真实Agent,因为真实环境里你也不能每次都把录像倒回去重看,虽然我很想这么干。
结果上,TaskMem在三个benchmark上的准确率是VideoMME67.9、EgoLife45.4、EgoTempo27.6。
相比基础Qwen3-VL-30B-A3B的61.6、38.4、22.3,提升分别是6.3、7.0、5.3个百分点。
它在VideoMME和EgoLife上超过了表里的GPT-5.2;在EgoTempo上准确率低于GPT-5.2,但precision更高。
这个方向对personal AI、embodied agent、截图记忆、视频理解都很有启发。
比如用户截图很多,难点不只是搜出来,而是系统能不能提前知道哪些截图、哪些细节、哪些上下文以后会有用。
链接:huggingface.co/ByteDance-See…
4
11
68
6,263

May 31
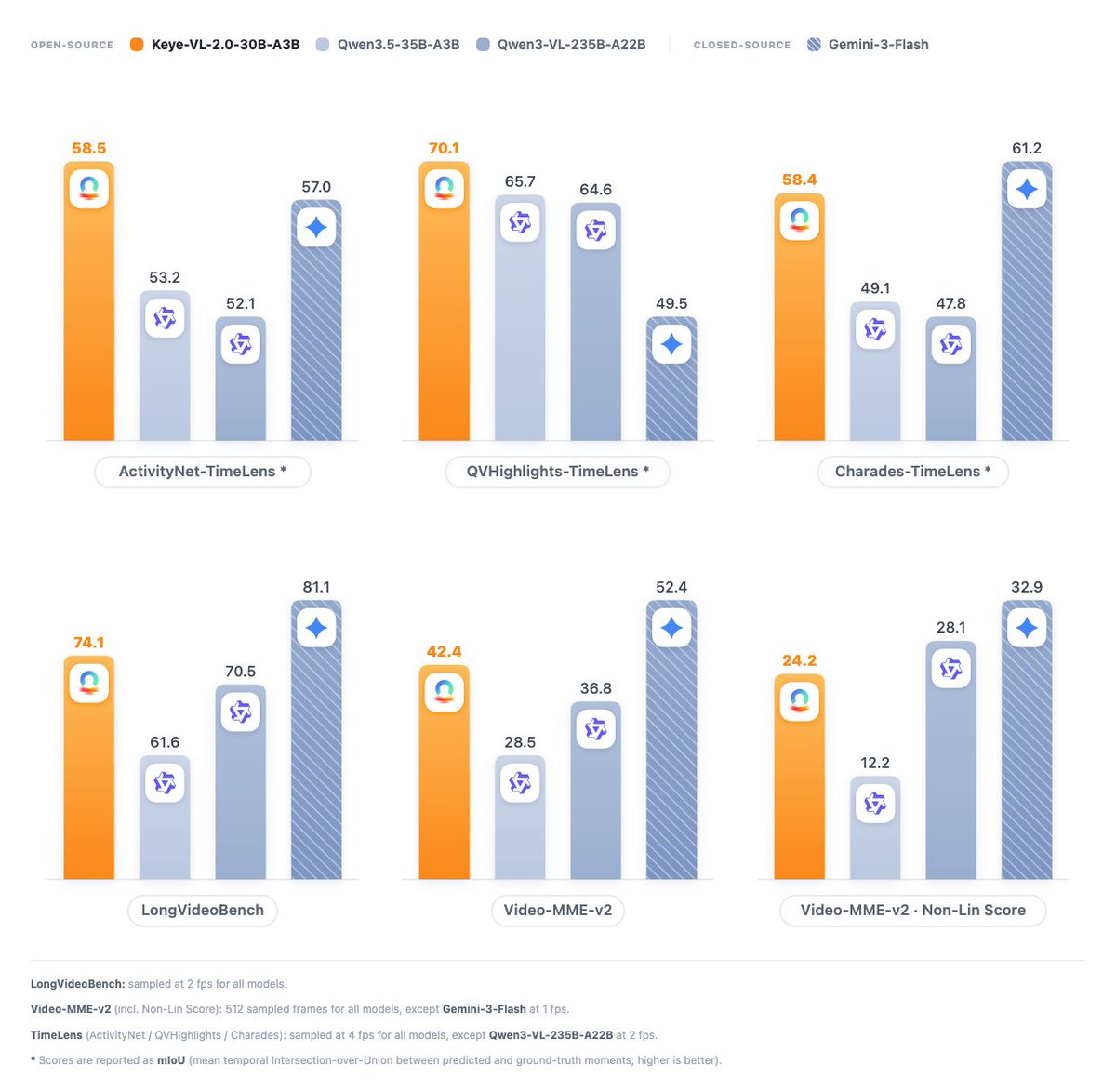
🔥@KwaiKeye 's Keye-VL-2.0-30B-A3B is now officially live on ModelScope! A major milestone that brings DSA (DeepSeek Sparse Attention) into multimodal AI. 🎬🤖
By coupling sparse attention with advanced feature aggregation, Keye 2.0 unlocks a 256k context window, allowing seamless processing of hour-long videos with zero context degradation. 📈 🔗 Get the weights: modelscope.ai/models/Kwai-Ke…
🌟 Core Technical Highlights:
• 🧠 MoE Performance, Flash Cost: Outperforms 200B open models on LongVideoBench (74.10) while slashing prefill costs by 50%.
• ⏱️ Frame-Level Precision: Captures complex causal chains and timestamps in long vlogs, handicraft tutorials, and gaming clips.
• 🚀 Anti-Decay Mastery: On VideoMME V2, expanding input from 64 to 512 frames actually boosts accuracy from 35.34% to 42.44%.
8
29
289
18,790

Apr 24
A 27B dense model outscored Claude 4.5 Opus on vision.
Qwen3.6-27B. Live on Chutes.
Qwen's newest open source flagship. Image, video, and text native. 262K context (extensible to 1M). Apache 2.0.
Head-to-head vs Claude 4.5 Opus on vision:
- V*: 94.7 vs 67.0
- CountBench: 97.8 vs 90.6
- VideoMME (w/ sub): 87.7 vs 77.7
- ERQA: 62.5 vs 46.8
- CharXiv RQ: 78.4 vs 68.5
Terminal-Bench 2.0 matches Claude 4.5 Opus at 59.3. New "Preserve Thinking" mode keeps reasoning traces across turns for agent workflows.
Running inside a TEE on Chutes. The GPU operators serving the model can't see your prompts or outputs.
$0.195 in / $1.56 out per million tokens.
Try it: chutes.ai/app/chute/7aa5e899…

10
43
280
12,016

Apr 20
🤯QWEN 3.6 35B-A3B IS INSANE AT CODING
@unslothai recently dropped Qwen3.6-35B-A3B-GGUF The first open Qwen3.6 model and it’s solid.
This MoE beast is cooking on benchmarks:
🧠SWE-bench Verified: 73.4 (big jump)
🚀 Terminal-Bench 2.0: 51.5
🌟LiveCodeBench v6: 80.4
✅MMLU-Pro: 85.2 strong GPQA
🚀Multimodal king (MMMU 81.7, VideoMME 86.6)
🤯 Only 3B active parameters → runs smooth
📈 262K native context (extendable to 1M)
🤖Elite tool calling & agentic workflows
⚙️Unsloth Dynamic 2.0 GGUF quants (2-bit versions hit ~11-13 GB VRAM)
🎉 Perfect for repo-level coding, agents, long-context tasks
For frontier-level open-source coding more.. Try it 👇🏻
2
11
136
11,400

Apr 15
Introducing FS-VisPR (ACL 2026) — an adaptive fast/slow program-reasoning framework for long video understanding that, read against the backdrop of today's visual bottleneck debate, is more than a long-video trick.
A growing body of work (Berkeley's Hidden in Plain Sight, the path-planning evaluations, the VLMs Need Words shortcut analysis) converges on one uncomfortable finding: VLMs ace high-level reasoning but fail low-level perception, not because the vision encoder didn't see it, but because the LLM projector stack quietly defaults to language priors instead of reading its own visual tokens.
FS-VisPR pushes on exactly this seam. Instead of asking one monolithic VideoLLM to both see and reason end-to-end — the regime where the shortcut pathology is strongest — it decomposes perception into callable visual programs (key-clip retrieval, subtitle extraction, …) and routes easy queries through fast thinking while escalating low-confidence cases to slow, program-level reasoning with parameter search. Perception becomes an externalized, auditable operation rather than an implicit act of faith in the backbone's latent visual readout.
The empirics are suggestive of where the field is heading: 50.4% on LVBench (above GPT-4o) and parity with Qwen2.5VL-72B on VideoMME — from open-source bases. Read structurally, FS-VisPR is an early instance of a larger shift: as long as CLIP-style encoders and language-anchored training pipelines keep the visual bottleneck intact, progress on long video, VLA, and 3D world models will increasingly come from program-structured reasoning that forces the model to actually look, rather than from scaling the monolith.
arxiv.org/abs/2509.17743

4
102

Apr 8
How much of “video understanding” is actually… not about video?
We found that 40–60% of questions in popular benchmarks (VideoMME, MMVU) can be answered without watching the video.
And it gets worse as models scale. 🧵
This problem doesn’t just affect evaluation.
It’s baked into post-training data.
So when you do SFT / RL, a large portion of the “gain” actually comes from better language priors, not better visual grounding.
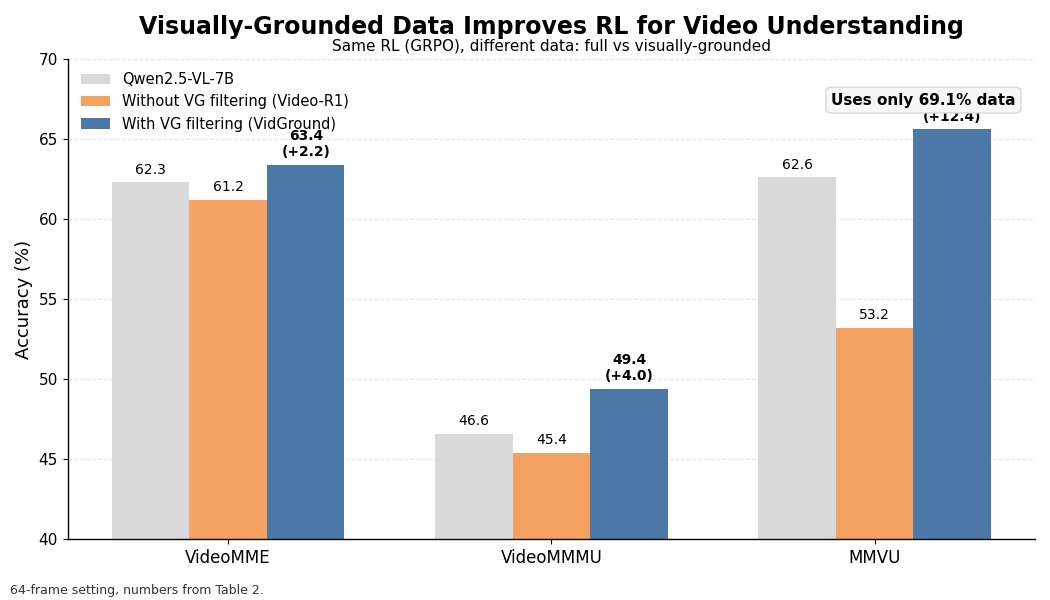
We propose a simple fix: VidGround
👉 Filter out text-only-answerable questions
👉 Keep only visually grounded data
That’s it.
Surprisingly, less data works better:
• Only 69.1% of the data
• 6.2 pts improvement
• Outperforms more complex RL pipelines
Key takeaway:
- If your data allows shortcutting, your model will learn shortcuts.
- For video understanding:
Grounding signal > data scale > algorithm tricks
📄 huggingface.co/papers/2604.0…
🌐 vidground.etuagi.com/
3
6
22
1,251



ByteDance lancou o Seed 2.0 Pro.
Modelo de agente autonomo que compete direto com GPT-5.2, Claude Opus e Gemini 3 Pro nos benchmarks (AIME 2025, Codeforces, VideoMME).
O diferencial: multimodal nativo (texto, imagem, video), 256K contexto, reasoning em 4 niveis, e custa uma fracao dos concorrentes.
ByteDance ja eh a maior empresa de IA da China com o Doubao. Agora quer o mercado global.
A corrida nao eh mais EUA vs China. Eh 6 empresas tentando ser a infraestrutura do futuro.
1
2
20
970

Mar 24
Achieves up to 7.5% accuracy gains on VideoMME-long across various MLLMs.
Project: videodetective.github.io/
Code: github.com/yangruoliu/VideoD…
Paper: huggingface.co/papers/2603.2…
4
624

Mar 23
I can't help but delight you with new updates in JuneAI @askjuneai
Some facts about Qwen:
🧠 Qwen3.5 397B A17B is now available in June!
This is the February 2026 edition of the Alibaba Qwen team—one of the most powerful and efficient open-source models on the market.
Key Features:
• A giant brain with a lightweight design: only 397 billion parameters, but only 17 billion are activated per run (a rare machine learning model with 512 experts). This translates to 8.6–19x faster performance than the leaders with minimal hardware production.
• Native multimodality: the first full-fledged vision language model with early fusion in the Qwen series. It understands images, videos, documents, and works with GUI agents.
• Enormous context: 262,144 tokens out of the box, expandable to 1 million (with YaRN).
• Global support: 201 languages and dialects (including rare ones).
• Architecture: A hybrid of Gated DeltaNet (linear attention) and sparse machine learning—it delivers both speed and stability.
Performance (official benchmarks):
MMLU-Pro: 87.8%
GPQA Diamond: 88.4%
SWE-bench verified: 76.4%
MMMU: 85.0%
VideoMME: 87.5%
It ranks third among all open-source models in the Artificial Analysis Intelligence index. Moreover, on many tasks (reasoning, coding, agents, visual thinking), it matches or even surpasses its own flagship models.

7
171

Mar 17
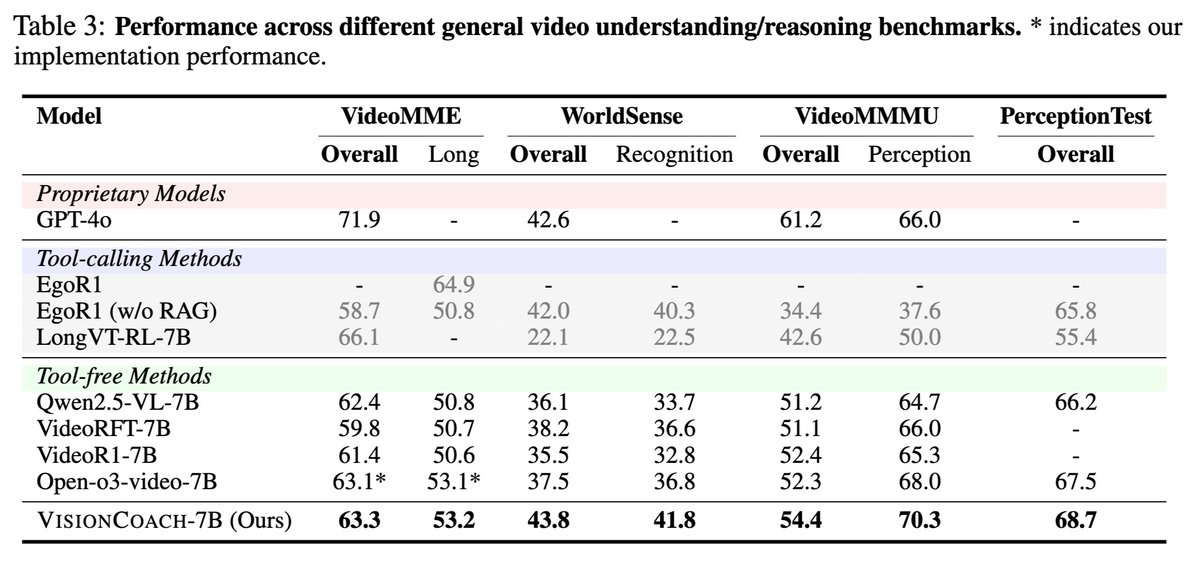
⚡️Results #2: General Video Understanding Benchmarks
We evaluate VisionCoach on VideoMME, WorldSense, VideoMMMU, and PerceptionTest as zero-shot performance.
- Across general video understanding benchmarks, VisionCoach outperforms GPT-4o, tool-calling methods, and tool-free baselines, while remaining fully tool-free.
- Notably, it achieves strong gains on perception-centric tasks (WorldSense, VideoMMMU), demonstrating that better grounding directly improves video understanding performance.
1
8
230
Mar 17
🚨 Excited to share VisionCoach, an RL framework for reinforcing grounded video reasoning via visual-perception prompting and self-distillation!
🧠 Video reasoning models often miss where to look or rely on language priors. Instead of only supervising final answers, we encourage the model to learn to attend to the right visual evidence.
⚽️ VisionCoach uses RL to reward correct visual attention, with dynamic visual prompting as a training-time coach for better spatio-temporal grounding, while keeping inference simple and tool-free via self-distillation.
⭐️ Achieves state-of-the-art zero-shot performance across video reasoning, video understanding, and temporal grounding benchmarks (V-STAR, VideoMME, World-Sense, VideoMMMU, PerceptionTest, and Charades-STA).
👇🧵
1
24
77
11,100

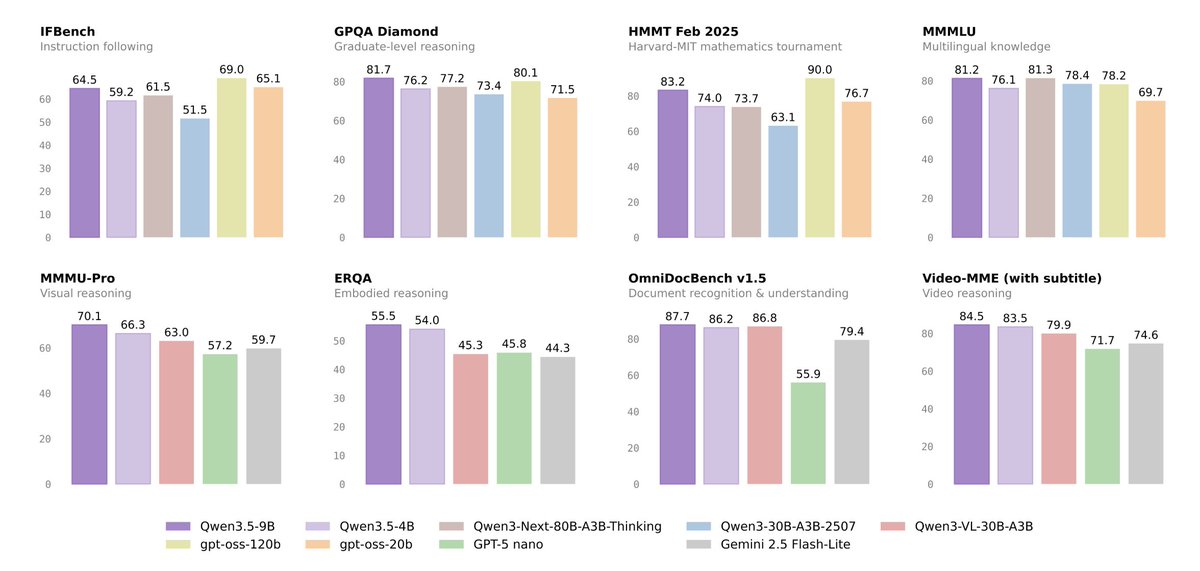
3/ Najlepsze małe LLMY na rynku
Oprócz flagowców Qwen oferuje cztery modele gęste (dense), w odróżnieniu od większych wariantów MoE.
Model 9B osiąga wyniki porównywalne z poprzednią generacją Qwen3-30B, który był trzykrotnie większy!
Na MMLU-Pro zdobywa 82.5, na GPQA Diamond 81.7. W testach wizyjnych 9B uzyskuje 70.1 na MMMU-Pro i 78.9 na MathVision, znacząco bijąc GPT-5-Nano (odpowiednio 57.2 i 62.2).
Nawet model 2B ma 84.5 na OCRBench i 75.6 na VideoMME, plasując się powyżej wielu modeli klasy 7B z poprzedniego roku.
Model 4B to kompromis nadaje się jako baza dla lekkich agentów multimodalnych.
1
4
1,015

Feb 17
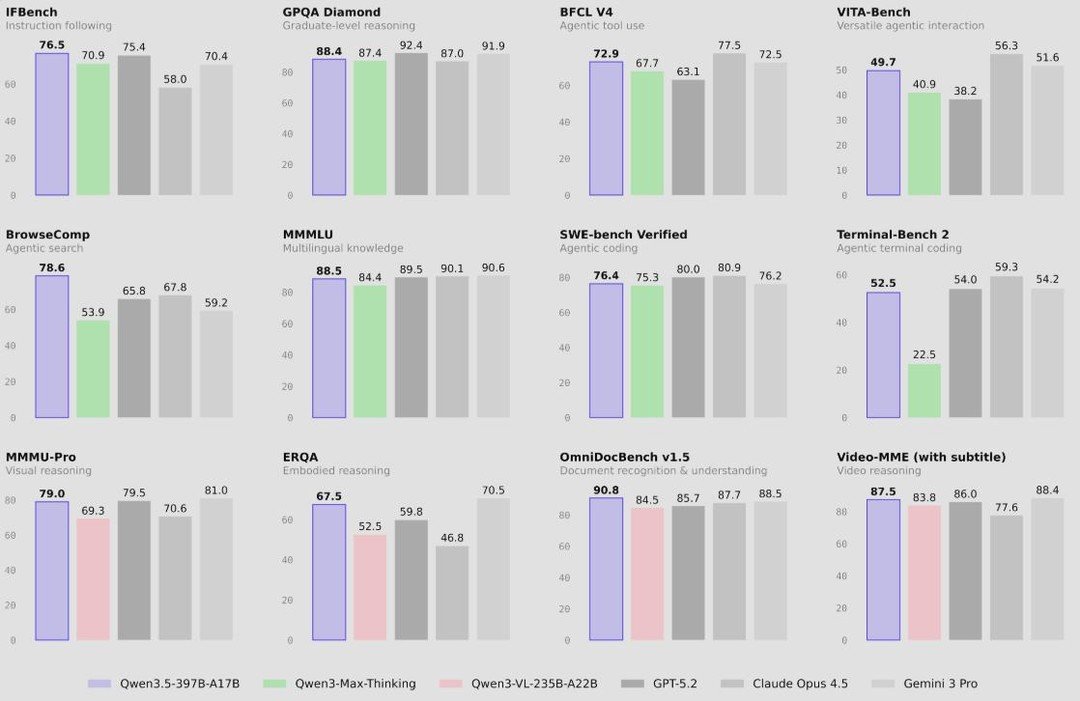
Qwen3.5 emerges as Alibaba's first open-weight native vision-language model with 397 billion parameters.
- Combines gated delta networks and sparse mixture-of-experts, activating only 17 billion parameters per pass for 3.5x to 7.2x faster inference.
- Achieves state-of-the-art scores like 87.8% on MMLU-Pro and 87.5% on VideoMME, outperforming models in multimodal tasks.
- Supports 201 languages, expanded visual and STEM data, and capabilities in GUI automation and video-to-code generation.
1
3
117

Feb 17
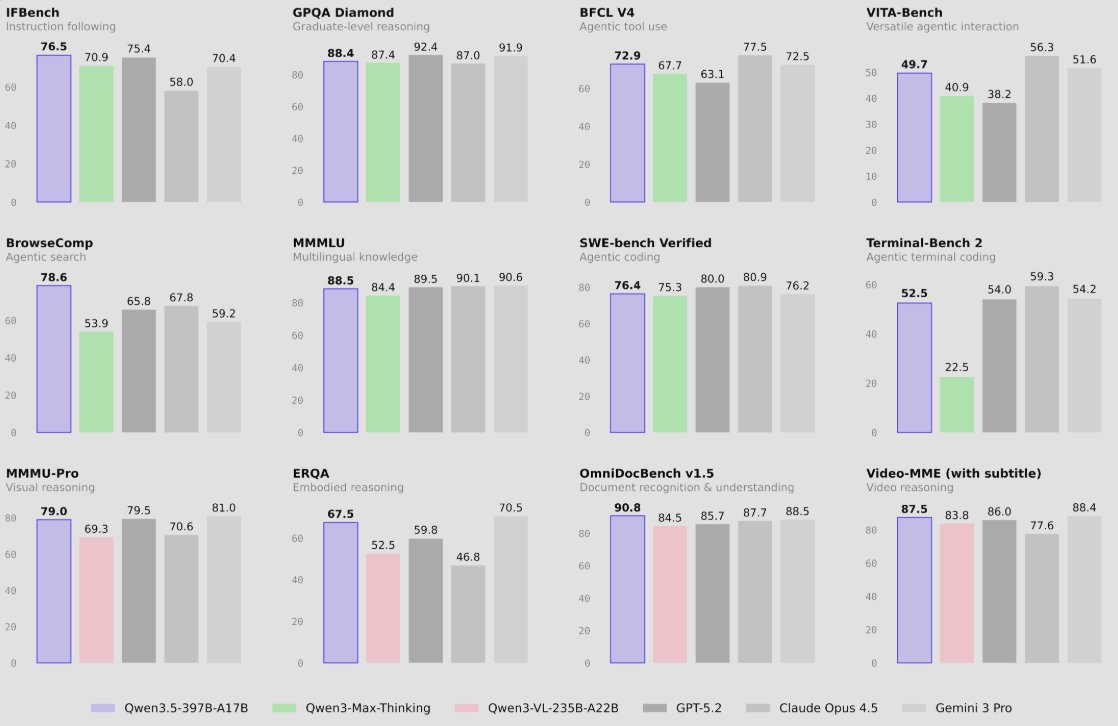
Qwen3.5 emerges as Alibaba's first open-weight native vision-language model with 397 billion parameters.
- Combines gated delta networks and sparse mixture-of-experts, activating only 17 billion parameters per pass for 3.5x to 7.2x faster inference.
- Achieves state-of-the-art scores like 87.8% on MMLU-Pro and 87.5% on VideoMME, outperforming models in multimodal tasks.
- Supports 201 languages, expanded visual and STEM data, and capabilities in GUI automation and video-to-code generation.
- Released openly via Hugging Face and ModelScope, with Qwen3.5-Plus available on Alibaba Cloud.
Qwen3.5 advances efficient multimodal AI for agentic workflows and developer tools.
Feb 16

1/2 Qwen3.5 is here. The next frontier of Native Multimodal Agents is open. 🚀
We are thrilled to release Qwen3.5-397B-A17B, our flagship open-weight vision-language model. Built for the future of coding, reasoning, and seamless multimodal interaction.
Key Highlights:
Inference Efficiency: A massive 397B total parameters, but only 17B active—delivering flagship power at a fraction of the cost.
Hybrid Architecture: Innovative Gated Delta Networks (Linear Attention) Sparse MoE for extreme speed.
True Multimodality: Exceptional performance across GUI interaction, video comprehension, and agentic workflows.
Global Scale: Qwen3.5 now supports over 200 languages.
Empowering developers and enterprises to build smarter, faster, and more versatile AI agents.
3
1
36
2,406

Feb 16
Qwen3.5想接住DeepSeek R1的春节热度
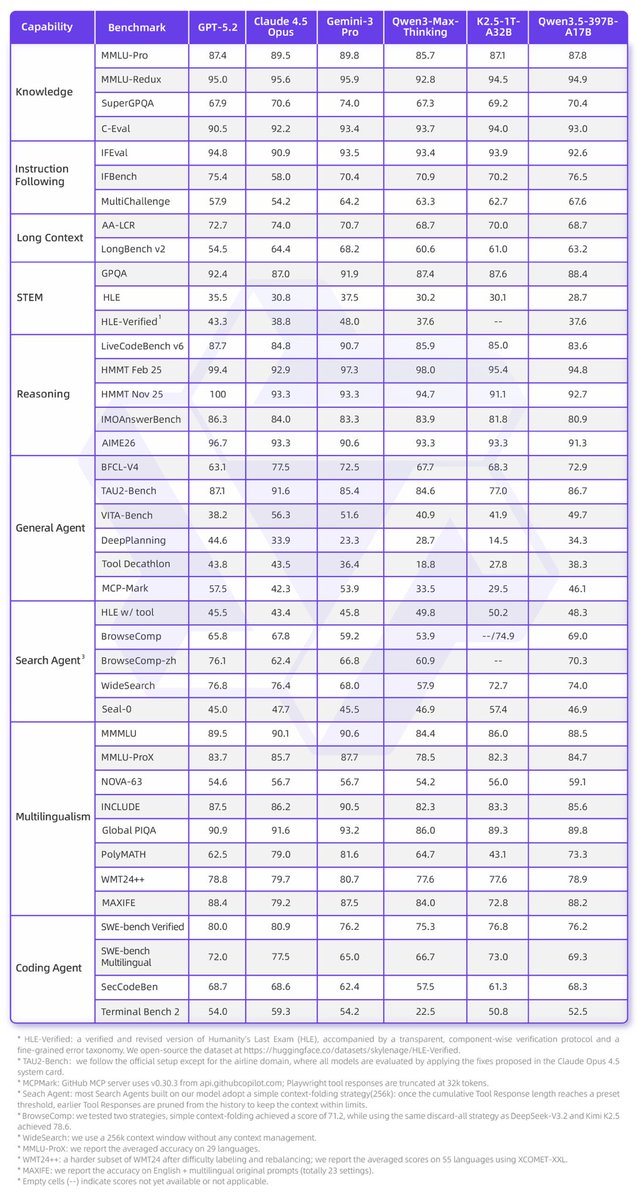
国人做AI也是真卷,Qwen3.5发布,397B总参只激活17B,推理速度比前辈快好几倍;Agent能力突出,原生多模态能读屏、跨App操作、草图转代码,在BFCL和TAU-Bench这些基准上表现亮眼;多语言覆盖201种,知识类如MMLU-Pro 87.8分,超GPT-5.2的87.4,还在视觉任务(MathVision 88.6、VideoMME 87.5)上领先不少。API便宜,开发者用起来实惠。
但在纯文本深度推理和数学上,还有点差距,比如IMOAnswerBench 80.9分,比顶尖闭源低几点;长上下文某些场景(如AA-LCR)也稍弱;开源归开源,但本地跑大模型还是得有好硬件。
DeepSeek R1那波是“从追赶到平齐顶尖reasoning”的质变,重点在强化学习 CoT激励,开了开源reasoning新时代。
Qwen3.5这波是“在效率 实用 多模态上再卷一层”,激活参更低(17B vs 37B),推理快、省显存,还加了Agent原生能力,但代码和文本推理,和顶级大模型没拉出同样大的代差。
2
152

Feb 16
MiniMax M2.5 vs Qwen 3.5, which should you choose?
Both are both cutting-edge open-weight models from Chinese AI labs. They target agentic AI, coding, and reasoning, positioning them as direct competitors in the 2026 open-source frontier.
Qwen3.5 emphasizes native multimodality and efficiency via MoE, while MiniMax-M2.5 prioritizes production-ready coding/agent performance with heavy RL scaling and low cost.
- Qwen3.5-397B-A17B — Sparse Mixture-of-Experts (MoE) with 397B total parameters, ~17B active per token. Uses hybrid linear attention (Gated DeltaNet) sparse MoE for efficiency. Native multimodal (early vision-text fusion).
Context: 32K–256K tokens.
- MiniMax-M2.5 — ~229B parameters, Built with agent-native RL framework (Forge, using CISPO algorithm and process rewards). Text-focused, trained across 10 programming languages in 200K real-world environments. Context: 205K tokens.
Qwen3.5 is larger in total params but far more efficient due to MoE sparsity; MiniMax-M2.5 is a dense frontier model optimized for speed.
# Capabilities
- Coding → Both excel here, but MiniMax-M2.5 currently leads on flagship benchmarks.
- SWE-bench Verified: MiniMax-M2.5 at 80.2%; Qwen3.5 at 76.4% (official blog).
- Other coding: MiniMax strong on Multi-SWE-Bench (51.3%), SciCode (44.4%); Qwen3.5 high on LiveCodeBench (83.6%), SecCodeBench (68.3%).
- Agentic/Tool Use → Both designed for real-world agents.
- MiniMax shines in BrowseComp (76.3%), office tasks (59% win rate on GDPval-MM), and efficient search iterations.
- Qwen3.5 strong on TAU2-Bench (86.7%), BFCL-V4 (72.9%), Tool Decathlon (38.3%).
- Reasoning/Math → Competitive.
- GPQA: MiniMax 85.2 (Diamond); Qwen3.5 88.4 (overall), SuperGPQA 70.4.
- AIME/Math: MiniMax AIME25 86.3; Qwen3.5 IMOAnswerBench 80.9, AIME26 91.3.
- Multimodal → Clear edge to Qwen3.5 (native vision-language).
- Qwen3.5: MMMU 85.0, MathVista 90.3, VideoMME 87.5, OCRBench 93.1.
- MiniMax-M2.5: Text-primary; no native multimodal benchmarks reported.
- MiniMax-M2.5 — Production-focused: ~57 tokens/sec, very low cost ($0.30/M input, $1.20/M output tokens; ~1/10–1/20 of proprietary like Claude Opus/GPT-5). High-throughput (100 TPS version available), cheap self-hosting (~$1/hour at 100 TPS).
- Qwen3.5 — Highly efficient via MoE: 8.6x–19x faster decoding than prior Qwen dense models at long context. No public API pricing yet (open weights; hosted Qwen3.5-Plus on Alibaba Cloud).
MiniMax-M2.5 wins on raw speed/cost for deployment.
# Overall Positioning
- MiniMax-M2.5 leads in pure coding/agentic efficiency and cost → Often compared favorably to Claude Opus 4.6/GPT-5.2 on coding speed/cost (e.g., 37% faster runtime on SWE-bench, 10% cost).
- Qwen3.5 broader (especially multimodal/agentic vision tasks) and efficient at scale → Competitive with top proprietary models (GPT-5.2, Claude 4.5 Opus, Gemini 3 Pro) across reasoning/multimodal.
- Direct head-to-heads are emerging (e.g., some leaderboards compare to prior Qwen3 series), but MiniMax-M2.5's higher SWE-bench score gives it a current edge in coding hype. Both signal rapid progress in open-weight models closing the gap with proprietary frontiers.
These are very recent releases, so community evaluations (e.g., LMSYS Arena, more agent benchmarks) will clarify further.
Qwen3.5 series has more variants incoming, potentially shifting the balance.
5
483

Feb 15
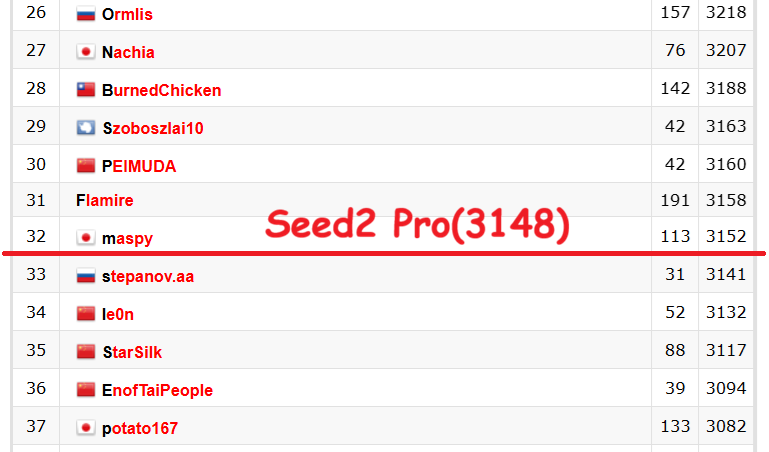
🔥 Holy 💩! China just released has a new 🤖 monster model 🚨 Seed2 Pro from @BytedanceTalk (the parent company of TikTok).
This model scores as the #33 best programmer in the world on @codeforces at 3148 for $2.37 per 1 million tokens!
This is a new major model from one of China's leading tech companies. This is an "everything model" tackling virtually every task applied to an LLM from scientific discovery to vibe coding, long context learning, and real-world Agentic tasks.
Here are some specs from the model card paper I pulled (some are speculation based on wording in the paper);
📥 Input Modalities:
Text, Image (Multi-image, High-res), Video (Long-form, Streaming)
📤 Output Modalities:
Text, Code
🧠Context Window :
At least 128k tokens (evaluated on LongBench v2 128k and Graphwalks <128k benchmarks)
💰Pricing (API) :
Input (Prefill): $0.47 per 1 million tokens
Output (Decode): $2.37 per 1 million tokens
📅Knowledge Freshness:
Covers events and problems through late 2025 (evaluated on "ICPC 2025 World Finals" and "AIME 2026")
🚀 Key Capabilities
💻 Agentic Coding :
Repository-level generation ("Vibe Coding")
🌐 Multilingual :
Strong performance on global benchmarks
👁️ Visual Reasoning :
State-of-the-art on video understanding (VideoMME, CrossVid) and visual agent tasks (GUI operation)
👇 Model Card in the ALT.
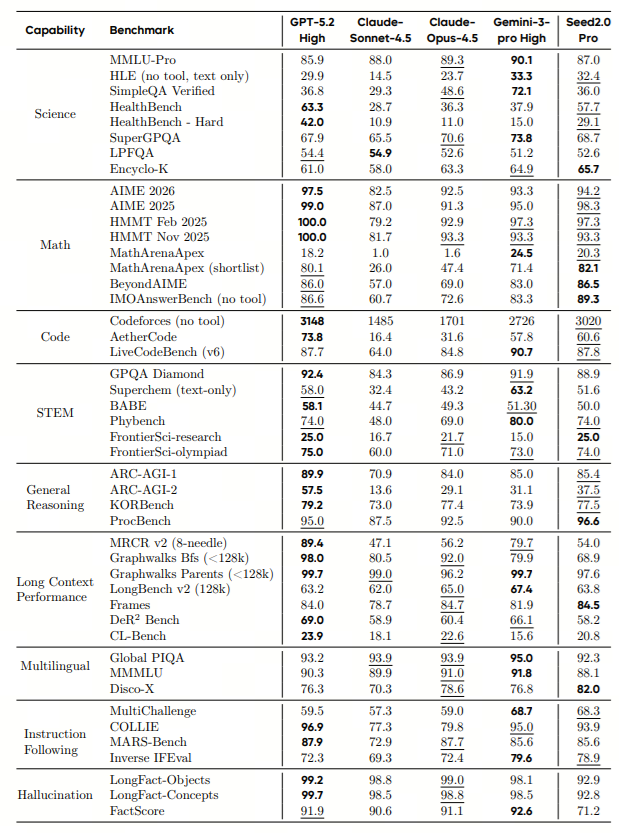
ALT https://lf3-static.bytednsdoc.com/obj/eden-cn/lapzild-tss/ljhwZthlaukjlkulzlp/seed2/0214/Seed2.0 Model Card.pdf
1
332

Jan 11
Quick insights (exactly 3 bullets, deeper not shallow, 15-25 words each):
- Introduces "Thinking Once, Answering Twice" training: model answers directly, reasons only if low confidence, then refines answer – both supervised via verifiable rewards for robust learning.
- At inference, uses initial answer confidence to decide whether to trigger CoT reasoning, slashing average response length ~3.3x (149→44 tokens) without sacrificing performance.
- Achieves SOTA on VideoMME ( 1-3%), MVBench, VideoMMMU benchmarks while activating reasoning selectively: low (∼25%) on perception tasks, high (∼50-56%) on reasoning-heavy ones.
1
3
28

8 Dec 2025
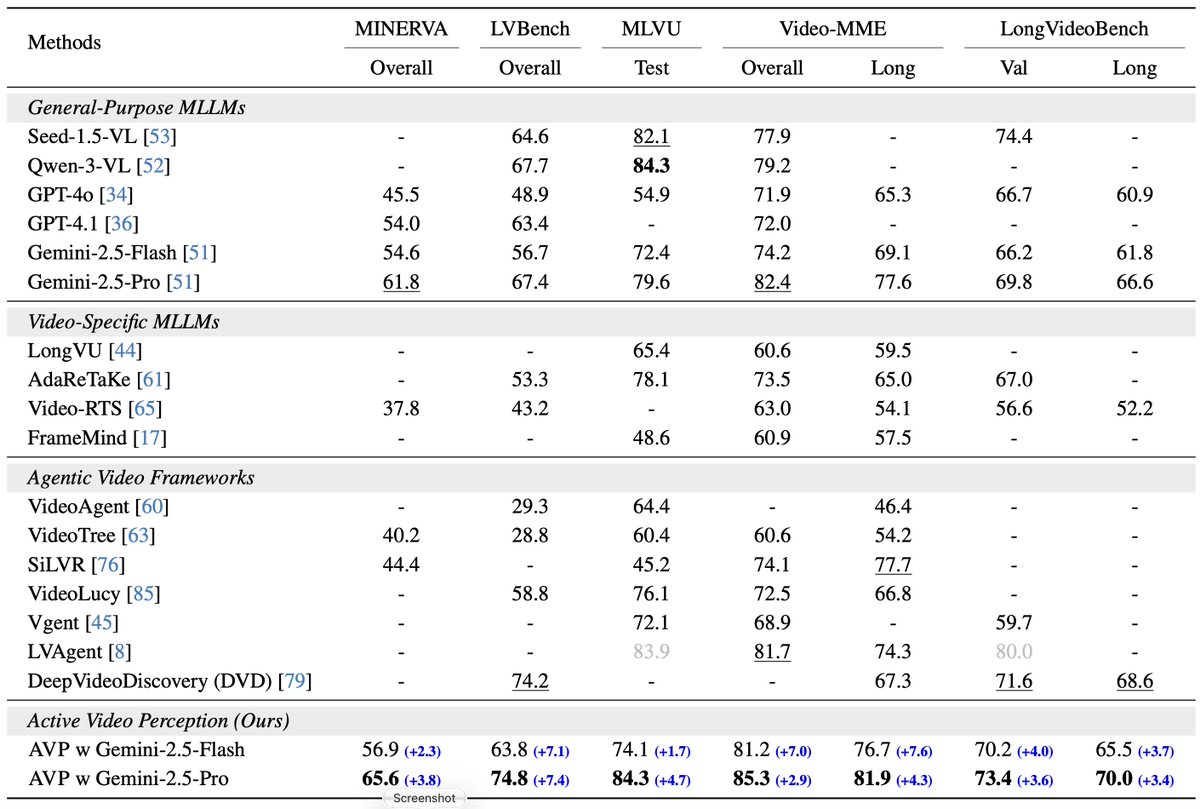
📊 Main Results: strong performance on long video tasks
We evaluated AVP across 5 major benchmarks (MINERVA, LVBench, VideoMME, MLVU, LongVideoBench).
The results demonstrate the superiority of active evidence seeking over passive processing:
✅VS. General MLLMs: AVP (w/ Gemini-2.5 Pro) surpasses its own backbone by 4.5% average accuracy, proving that direct inference is insufficient for long-horizon queries.
✅VS. Agentic Frameworks: AVP consistently outperforms leading methods, achieving 5.7% improvement over the best agentic methods.
1
6
184