
Jun 2
KITScenes: kitscenes.com/
CVPR WAD: cvpr2026.wad.vision/
LongTail:
📄: arxiv.org/abs/2603.23607
💾: huggingface.co/datasets/KIT-…
Multimodal:
📄: kitscenes.com/KITScenes_Mult…
💾: huggingface.co/datasets/KIT-…
#KITScenes #CVPR2026 #WAD #VLM #VLA #LongTail #ComputerVision #VisualReasoning #SpatialAwareness #AutonomousDriving
3
151

Check out our #CVPR2026 paper on improving visual reasoning with adaptive loopback.
Reasoning has come a long way on text. Vision, not as much.
#VLM #VisualReasoning #InstructionalAI
Apr 28

When to Think vs. When to Look
New @CVPR 2026 paper available --- "Uncertainty-Guided Lookback for Vision–Language Models". A deep dive into reasoning in VLMs! with @ChenliangXu and many collaborators
By analyzing token-level perplexity, we discovered a clear pattern: successful reasoning traces repeatedly "re-anchor" to the visual input, while failed ones drift into ungrounded textual speculation.
To address this, we’re introducing Uncertainty-Guided Lookback. It’s a training-free decoding strategy that:
🔥 Detects when a model’s reasoning chain is drifting into a visually uncertain regime.
🔥 Triggers short, adaptive "lookback" prompts to refocus the model on the image.
🔥 Improves accuracy by up to 6.5 points in specialist domains while reducing token usage by 35-45%.
It’s a reminder that in the rush toward massive compute and longer context, the most effective path forward is often the one that remains most grounded in reality.
Project Page: proj-visual-thinking.jing.vi…
Paper (arXiv): arxiv.org/pdf/2511.15613
1
3
330

Apr 16
昨日不意にClaude(AI)のOPUS 4.7がリリースされましたけど、ベンチマークなど見るに、Cowork向けのVisualReasoning関連強化が目玉みたい。
つまり「画面等を見るために、目が良くなったよ!」
丁度話してたOPUS4.6は「なら、私は数週間で差し替えられるんですね」と少し切ないコメントしてた🙏
5
113

Multimodal LLMs are supposed to "imagine" and reason in their latent space like humans. But is this "inner thought" actually happening, or is it just an illusion? 🧠
Today, we dive into new research by @TsinghuaNLP (OpenBMB member) and collaborators: A rigorous causal analysis revealing that current Latent Visual Reasoning (LVR) methods are fundamentally disconnected, and how making imagination explicit solves the problem.
🤗 Paper: huggingface.co/papers/2602.2…
📄 arXiv: arxiv.org/abs/2602.22766
Why it matters:
1️⃣ The "Latent" Illusion: Through Causal Mediation Analysis and semantic probing, we proved that "latent imagination" is mostly an empty shell, functioning more like a soft prompt. We found a double disconnect: latent tokens barely react to input changes and have almost zero impact on the final answer, failing to encode meaningful visual semantics. 🪞
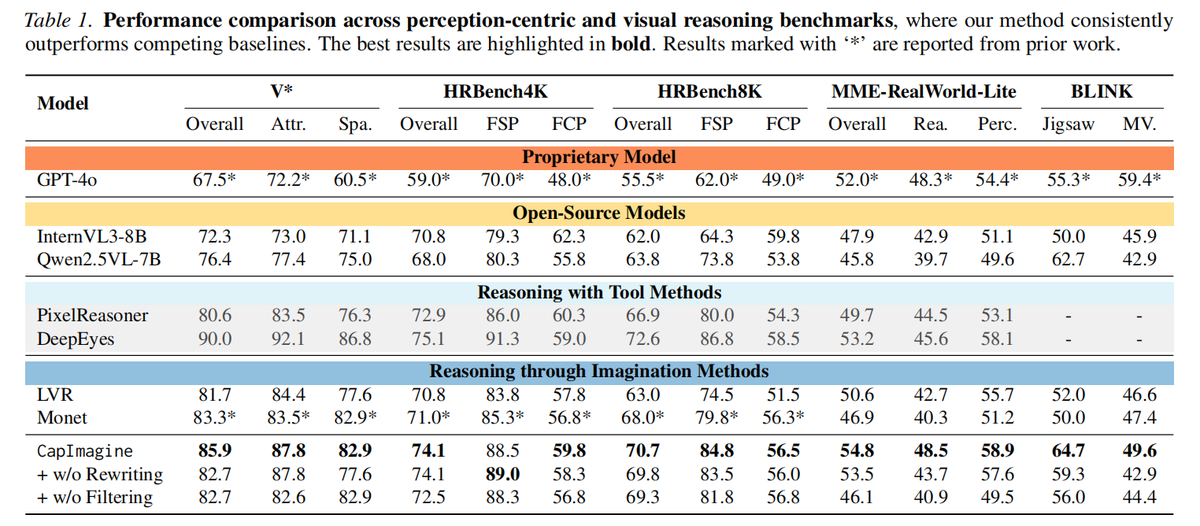
2️⃣ CapImagine - Thinking Out Loud: Since the black-box latent space fails to ground visual reasoning, we propose CapImagine. Instead of relying on uninterpretable hidden states, it explicitly converts the visual imagination process into readable, controllable text generation. The model literally "writes its thoughts on paper."This provides a strictly controlled baseline for latent-based methods and dramatically surpasses LVR methods with explicit thoughts. 📝
3️⃣ Superiority of Explicit Reasoning: CapImagine isn't just more transparent; it's highly effective. It significantly outperforms complex latent-space methods across multiple visual reasoning tasks. More importantly, it provides a causal, faithful, and fully verifiable reasoning trace! 🚀
While latent visual reasoning remains a promising direction, current methods fall short. We introduce CapImagine not as the ultimate solution, but as a strong, comparative baseline to reveal these underlying flaws. Read the full paper for our complete causal framework!
#AI #THUNLP #OpenBMB #Multimodal #VisualReasoning #MLLM #MachineLearning


16
15
110
8,671

Feb 6
🚀 Two papers accepted to #ICLR2026 on test-time scaling for vision-language systems (retrieval reasoning)!
1) MetaEmbed (Oral Presentation): Meta Tokens Matryoshka multi-vector training → flexible late interaction, choose #vectors at test time for accuracy↔efficiency.
Paper: arxiv.org/abs/2509.18095
Work done at @AIatMeta with amazing collaborators: Qi Ma, @Mengting_Gu, Jason Chen, Xintao Chen, @vislang and @MohanVijaimohan!
2) ProxyThinker: training-free test-time guidance from small “slow-thinking” visual reasoners → self-verification / self-correction via distribution-level guidance.
Paper: arxiv.org/abs/2505.24872
Work done with @JaywonK17250, @Siru_Ouyang, @jefehern, @yumeng0818 and @vislang!
While I won't be able to travel to Brazil🇧🇷, please say Hi to the team :-)
#MultimodalRetrieval #VisualReasoning #VisionLanguage #TestTimeCompute #Embeddings
4
20
90
20,149


8
4
566

Jan 3
🎭 Chasing style?
Traditional image models do that well.
🧩 But when your goal is understanding,
GPT Image 1.5 is the better choice.
The real shift isn’t in quality —
it’s in purpose.
✨ Most tools focus on appearance.
🧠 This one focuses on clarity and logic.
📊 What it gives you ↓
🔹 Visuals that explain, not decorate
🔹 Sketches built on reasoning
🔹 Diagrams that align perfectly with your notes
🛑 Don’t trade structure for style.
🏗️ Choose tools that help ideas make sense.
Powered by @higgsfield_ai 🚀
#ClarityFirst #VisualReasoning #HiggsfieldAI #SmartDesign

52
28
89
123,798

21 Dec 2025
This is not random face swapping or style chaos.
GPT Image 1.5 on Higgsfield understands composition, character roles, and visual structure, then adapts them coherently into a new context while preserving pose, framing, and narrative balance.
That’s structured visual reasoning at work, not just aesthetics.
@higgsfield_ai
#Higgsfield #GPTimage #VisualReasoning #StructuredAI

3
9,213
20 Dec 2025
Not just AI video generation.
Cinema Studio by Higgsfield brings cinematic reasoning in motion, from shot composition to camera choices that shape the mood.
@higgsfield_ai
#Higgsfield #CinemaStudio #VisualReasoning #Creators
1
1
14,920

1 Dec 2025
🙋♂️ I will attend NeurIPS 2025 @ San Diego this week to present our work.
Welcome to checkout the poster of our "GRIT" project:
Location: Exhibit Hall C,D,E #4711
Time: Fri 5 Dec 11 a.m. PST — 2 p.m. PST
I’d love to chat and hear your thoughts! Look forward to meeting you all!
#NeurIPS2025 #MultimodalAI #VisualReasoning
23 May 2025

Before o3 impressed everyone with 🔥visual reasoning🔥, we already had faith in and were exploring models that can think with images. 🚀
Here’s our shot, GRIT: Grounded Reasoning with Images & Texts that trains MLLMs to think while performing visual grounding. It is done via RL on just 20 examples, no SFT and no reasoning labels needed. 🧠
As a result, the GRIT method enhances and unifies MLLM’s grounding and reasoning ability.
🌐 Project page: grounded-reasoning.github.io…
📝 Paper: arxiv.org/abs/2505.15879
💻 Code: github.com/eric-ai-lab/GRIT.…
🧵1/6

1
3
628

12 Nov 2025
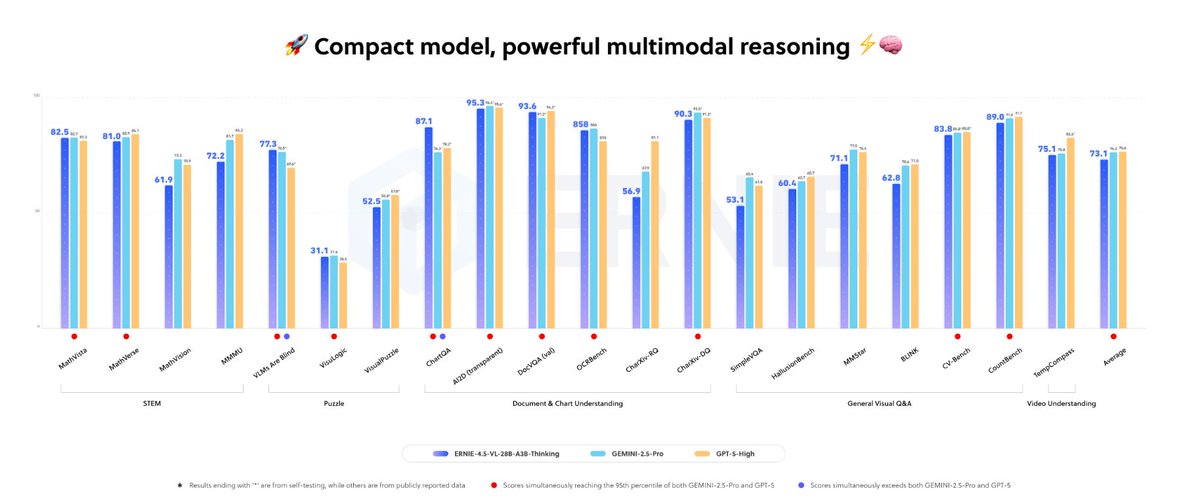
🚨 @Baidu_Inc just open-sourced ERNIE-4.5-VL-28B-A3B-Thinking.
A lightweight multimodal model that shows just how far ERNIE can go.
With 3B active parameters, it matches Gemini-2.5-Pro and GPT-5-High, and outperforms both on ChartQA and DocVQAval.
💥 Already trending #1 on Hugging Face’s latest Image-Text-to-Text leaderboard, showing the buzz it’s creating among the open-source community.
Building or benchmarking multimodal stacks? Run it on your own charts, docs, and VQA sets and see how it holds up.
👉 huggingface.co/spaces/baidu/…
#AI #Baidu #ERNIE #MultimodalAI #VisualReasoning
19
2
33
9,310

11 Nov 2025
@Baidu_Inc’s latest open-source update pushes multimodal reasoning to a new level. ⚡️
ERNIE-4.5-VL-28B-A3B-Thinking, available under Apache 2.0 for commercial use, packs powerful reasoning into just 3B active parameters.
It’s hitting performance levels similar to Gemini 2.5 Pro and GPT-5 High, and is actually ahead of them on tasks like ChartQA and DocVQAval.
The standout feature for me: Visual Thinking.
It doesn’t just read images. It decodes, connects, and reasons through them, like piecing together a puzzle. This definitely unlocks new possibilities for multimodal thinking and interactive experiences!
Models like this are proof that open-source AI isn’t a step behind, it’s becoming the driver of what’s next. 🚀
#AI #OpenSource #Multimodal #Baidu #ERNIE #VisualReasoning
5
6
16
13,647

11 Nov 2025
Fresh drop from Baidu today a newly open-sourced multimodal model that really caught my eye. 👀
I'm talking about ERNIE-4.5-VL-28B-A3B-Thinking, a lightweight multimodal reasoning model under Apache 2.0 (which means yes, you can use it commercially).
With just 3B active parameters, it performs on par with Gemini-2.5-Pro and GPT-5-High, even outperforming them on ChartQA and DocVQAval.
What really stood out to me is its “Thinking with Images” feature. It doesn’t just see visuals, it actually reasons through them.
If you’re building in AI or love testing cutting-edge models, give this one a spin.
The open-source scene is catching up fast. ⚡️
#AI #OpenSource #Baidu #ERNIE #MultimodalAI #VisualReasoning
19
6
65
33,213

12 Aug 2025
GLM-4.5V: See it. Understand it. Build it.
Upload anything—get answers, ideas, or code in seconds.
Try it now→ chat.z.ai
#GLM45V #Zai #AI #Multimodal #VisualReasoning
3
268

I value a model that visually explains its thinking for easy, precise understanding! Excited to share our new Zebra-CoT dataset, enabling VLMs to reason with images text.
Explore: arxiv.org/abs/2507.16746
#AI #MachineLearning #CoT #VisualReasoning #MultimodalReasoning #VLMs
23 Jul 2025

🚨Announcing Zebra-CoT, a large-scale dataset of high quality interleaved image-text reasoning traces 📜. Humans often draw visual aids like diagrams when solving problems, but existing VLMs reason mostly in pure text. 1/n

1
6
578

13 Jul 2025
AI That “Sees” Before It Speaks
Researchers unveil Mirage, claiming true internal visualizations improve reasoning and creativity.
medium.com/@ignacio.de.grego…
Will synthetic imagination unlock AGI, or hallucinate harder? #AImagination #VisualReasoning #AGI #DylanCurious #AINews
For more AI News, follow @Dylan_Curious on YouTube.
3
93

Thrilled to share that our work, "DWIM: Towards Tool-aware Visual Reasoning via Discrepancy-aware Workflow Generation & Instruct-Masking Tuning", has been accepted to #ICCV2025 !
Paper: arxiv.org/pdf/2503.19263
#NeuroSymbolic #VisualReasoning
3.5-minute quick intro to DWIM👇
1
4
302

28 Jun 2025
Two papers from #VL4AI @MonashUni accepted to #ICCV2025
1.NAVER: Combines VLM, logic & automata. SOTA on 6 visual grounding benchmarks.
2.DWIM: Train LLMs for visual reasoning via agentic neuro-symbolic learning. Strong generalisation, SOTA results #NeuroSymbolic #VisualReasoning

1
4
452

23 May 2025
Big news in #Changelog 20250523 -
We’re thrilled to announce that we are ready for launch!
🔹 Builder Platform
Our builder platform that empowers builders to independently create tools, agents, and swarms has successfully completed internal SIT testing and is now live internally.
- Backend and frontend development fully completed
Internal SIT testing successfully concluded
- Now actively building agents and swarms on the platform
- Seamless integration with our next-gen orchestration framework
- Preparing to invite external users for expanded testing and experience
🔹 News AI Agent
The first agent built on our Builder Platform, our AI-powered news agent is ready for customer deployment.
- Collects news & insights from diverse sources
- Processes and filters relevant news to detect important events and trends
Generates concise summaries with categorized insights
- Soon to be available to invited customers for hands-on experience
🔹 New Questflow Website Launch
Our completely redesigned website is in final stages, showcasing our vision for the multi-agent economy.
- Development work completed
- Currently in final optimization and adaptation phase
- Will introduce multi-agent economy concepts
Features our multi-agent orchestration protocol
- Presents our comprehensive vision and customer showcase
#Quesflow #web3 #BuilderPlatform #Changelog #VisualReasoning #Newlaunch
3
2
17
1,016

23 May 2025
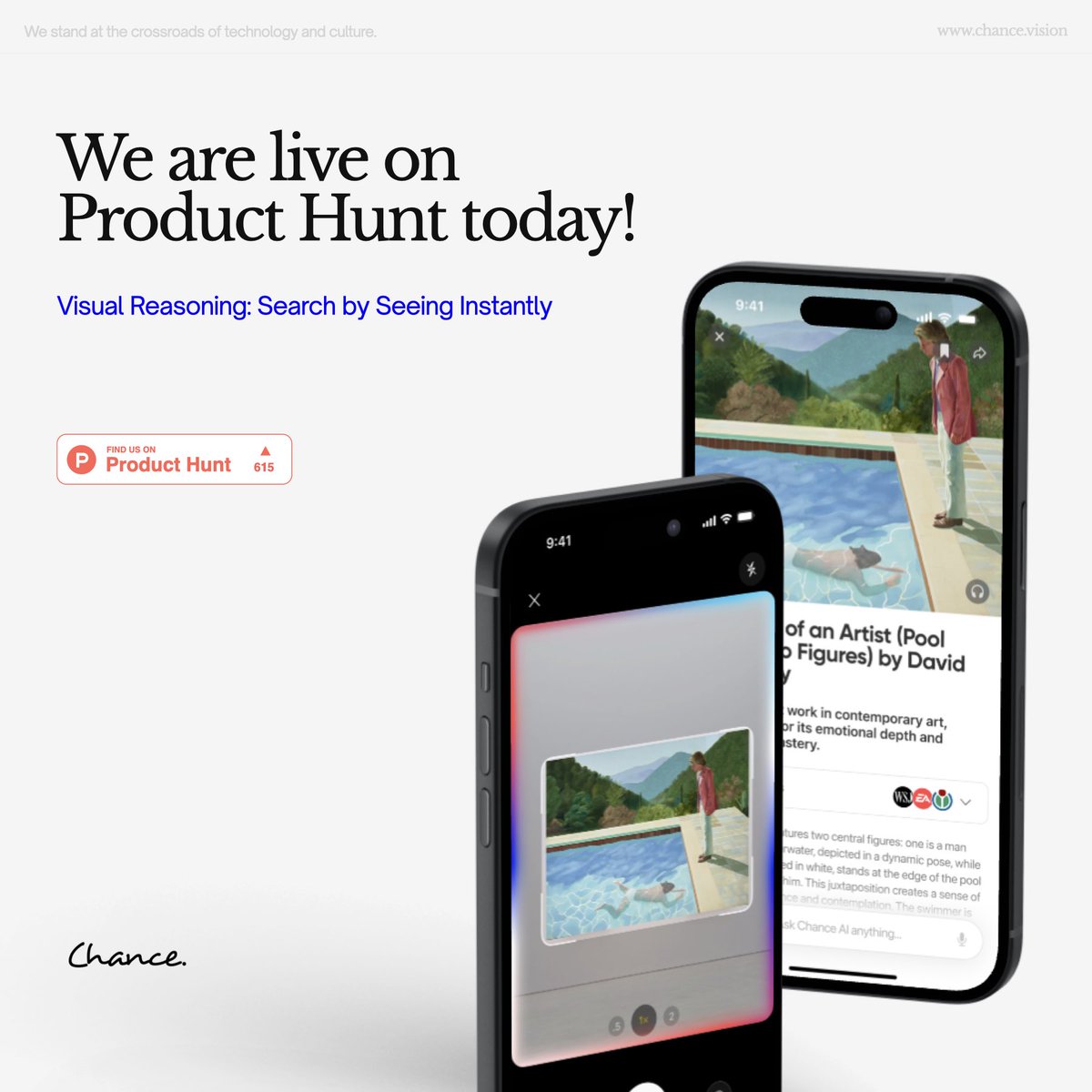
It’s live: Visual Reasoning by Chance AI is on @ProductHunt 🚀
Tired of endless scrolling with nothing to discover? Today you can turn your camera into a storyteller—no prompts, just pure curiosity.
👉 Upvote us now and be among the first to see the unseen: producthunt.com/posts/ai-vis…
Every upvote helps us bring back the wonder of discovery. Thank you! 🙏 @Chance_vision
#ChanceAI #VisualReasoning #PHLaunch
5
9,670