
Jun 13
🚀 Test-Time Compute & Inference-Time Scaling — the next frontier that shifts AI capability gains from training-time to dynamic, query-aware intelligence at inference time.
Just read this excellent technical white paper from @aasaitech — a powerful capstone to the entire series.
Key highlights: • Tiered reasoning architecture (Fast → Standard CoT → Deep CoT Self-Critique → Tree Search / Parallel Sampling) • Budget-aware controller that allocates compute based on complexity, risk & business value • Techniques: Extended CoT, Self-Refine loops, Tree-of-Thoughts, ensemble reasoning • Industrial impact: Superior diagnostics, root-cause analysis, safety-critical decisions, maintenance planning with higher reliability and controlled cost/latency
This completes the modern LLM stack — combining architecture, RAG, agents, multimodal, edge deployment, hybrid AI, safety, and now dynamic inference-time scaling for truly intelligent industrial systems.
Full white paper infographic: x.com/aasaitech/status/20656…
How are you exploring test-time compute in your workflows — basic extended CoT, full tiered reasoning with budget controllers, or o1-style adaptive scaling?
#TestTimeCompute #InferenceTimeScaling #AgenticAI #IndustrialAI #ReasoningLLM #EdgeAI #ManufacturingAI

8

Jun 12
How much time should robots spend thinking?
Vision-Language Models are increasingly used as high-level planners for robots, and the prevailing strategy has been to scale test-time compute to boost capability. But more reasoning steps, bigger models, and longer memory all come with increased latency, tokens, and FLOPs—often with diminishing and uneven returns.
So when, and where, is test-time compute actually worth its cost? 🧐
We study three dominant scaling axes and find that each unlocks a distinct capability, showing that test-time compute is not a uniform lever:
- Chain-of-thought depth helps with tasks involving implicit semantic, physical, or spatial constraints, but its additional latency is not always necessary (on VLABench, a non-CoT model matches a CoT model on 44% of tasks).
- Model size governs the breadth of skills a planner can reliably draw upon, but its benefits appear only when those additional skills are actually required.
- Memory history improves performance on long-horizon, history-dependent tasks, but can actively hurt performance elsewhere.
Across all three axes, a consistent pattern emerges: the gap between cheap and expensive configurations is large, but highly non-uniform and task-dependent.
DIRECT (Dynamic Inference Router for Embodied Compute Tradeoffs) is a lightweight router that reads scene instruction context and sends each task to the cheapest planner that can still solve it, allocating compute per task rather than committing to one fixed model.
👉 Takeaway: smart allocation of test-time compute can recover frontier-level planning at a fraction of the cost.
📄 Paper: arxiv.org/abs/2606.12402
🔗 Website: jadee-dao.github.io/direct/
Work led by @_jadelynn @milanganai
With an outstanding team of collaborators: @ajaysridhar0 @Mozhgan_nasr @katielulula Clark Barrett @jiajunwu_cs @chelseabfinn
#Robotics #VLM #EmbodiedAI #MachineLearning #TestTimeCompute
2
13
42
4,346

May 30
Agents do not scale because they spend more compute.
They scale because they turn interaction into usable feedback.
A sharp new preprint by Xuanliang Zhang, Dingzirui Wang, Keyan Xu, Qingfu Zhu, and Wanxiang Che introduces:
Scaling Laws for Agent Harnesses via Effective Feedback Compute
This matters because agent performance is no longer determined only by the base model.
It depends on the harness:
how the model calls tools
how it receives feedback
how it verifies intermediate states
how it stores memory
how it repairs errors
how it decides when to stop
But most test-time scaling analysis still measures crude expenditure:
tokens
tool calls
operations
wall time
cost
That is like measuring a research lab by electricity consumed instead of valid evidence produced.
The authors propose a better scaling coordinate:
Effective Feedback Compute, or EFC.
A feedback event only receives credit if it is:
informative
valid
non-redundant
retained for later decisions
That last condition is crucial.
A unit test that reveals a bug and changes the agent’s next action is effective feedback.
A repeated tool call that returns redundant information the agent ignores is not.
Same raw budget.
Different epistemic value.
The results are striking.
In controlled scaling experiments, raw tokens and tool calls explain limited variation in failure rates: R² = 0.33 and 0.42.
A strong multivariate SAS baseline reaches 0.88.
Oracle-EFC and Estimated-EFC reach 0.94.
And task-demand-normalized Oracle-EFC reaches 0.99.
Even more important: in matched-budget interventions, raw cost and tool calls are held fixed, but improving feedback quality raises success from 0.27 to 0.90.
That is the whole paper in one lesson:
the unit of progress in agent systems is not the token.
It is durable, task-sufficient feedback.
This reframes agent design.
More tools can hurt.
More turns can be waste.
More tokens can create noise.
More memory can preserve the wrong state.
The harness is a feedback converter.
The real question is not “how much compute did we spend?”
It is:
how efficiently did the harness convert raw budget into information the agent could actually use?
For pretraining, we got scaling coordinates: parameters, data, FLOPs.
For agents, we need a different coordinate.
EFC may be a step toward that.
Full credit to the authors:
Xuanliang Zhang, Dingzirui Wang, Keyan Xu, Qingfu Zhu, Wanxiang Che.
Paper:
Scaling Laws for Agent Harnesses via Effective Feedback Compute
arxiv.org/abs/2605.29682
I’m attaching the first page because the abstract is worth reading closely.
The future of agents may not belong to systems that spend the most.
It may belong to systems that learn the most from each step.
#AIResearch #AIAgents #LLM #MachineLearning #TestTimeCompute #ArtificialIntelligence

3
4
21
1,068

The next clue in AI reasoning:
answers may be attractors.
A new paper from Benhao Huang, Zhengyang Geng, and Zico Kolter introduces Equilibrium Reasoners (EqR) — a sharp mechanistic view of test-time scaling in latent reasoning models.
The core idea is simple, but deep:
Reasoning is not only generation.
Reasoning can be convergence.
EqR repeatedly updates a latent state. The authors hypothesize that generalizable reasoning emerges when training shapes the model’s latent dynamics so that stable attractors correspond to valid solutions.
In other words, the answer is not merely “produced.”
It is reached.
This matters because test-time compute only helps when the model’s internal dynamics know how to use it. More iterations can improve reasoning — or make it worse — depending on whether the trajectory moves toward a solution-aligned attractor or falls into a spurious one.
EqR scales along two axes:
Depth: run more iterations so a trajectory can settle.
Breadth: run multiple stochastic trajectories from different initializations and select/aggregate the ones that converge best.
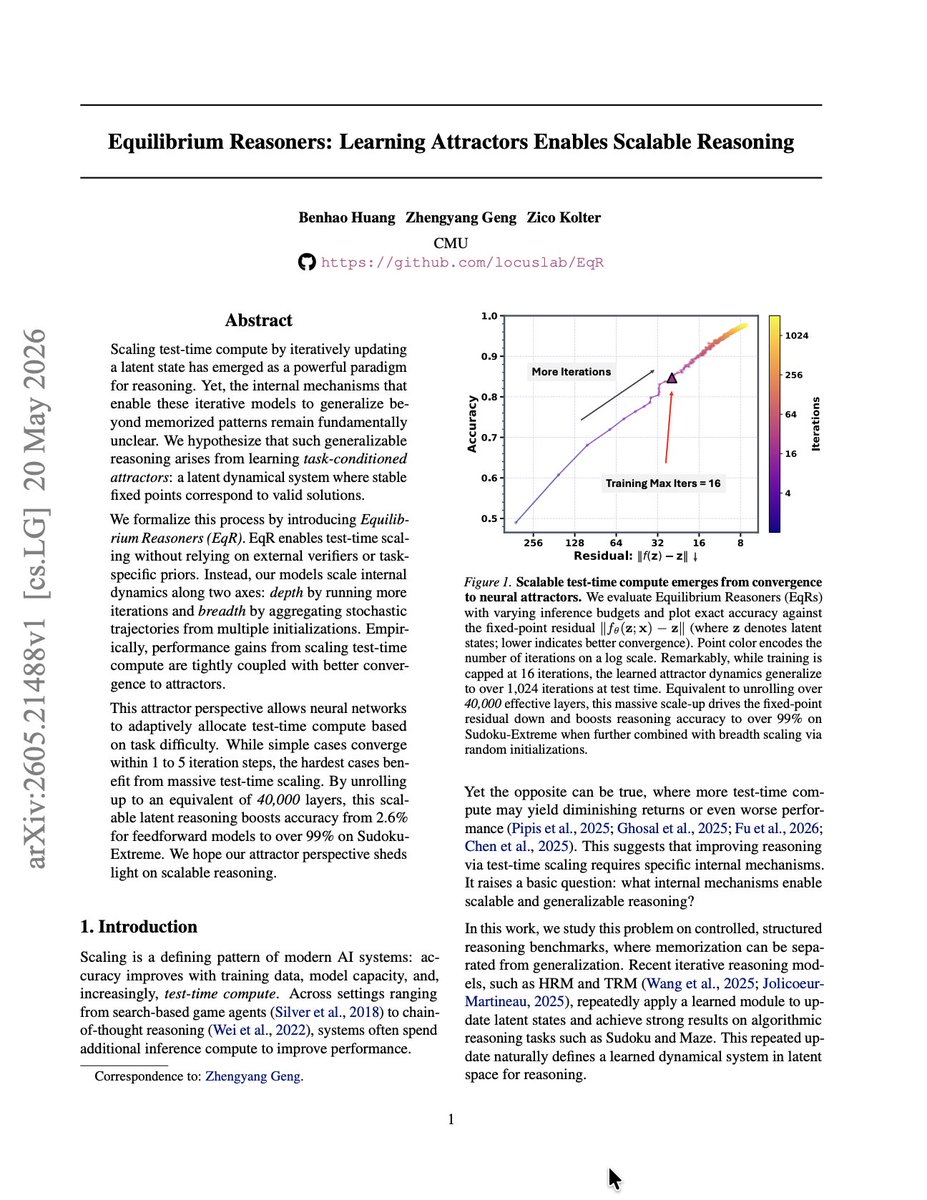
The first-page figure captures the punchline beautifully: training is capped at 16 iterations, yet the learned dynamics extrapolate beyond 1,024 iterations at test time. As fixed-point residual falls, accuracy rises.
On Sudoku-Extreme, the paper reports a jump from 2.6% exact accuracy for feedforward models to over 99% with scalable latent reasoning — equivalent to unrolling up to ~40,000 layers. On Maze, EqR reaches 93.0%.
But the benchmark is not the most interesting part.
The most interesting part is the lens:
Correct answers must become stable.
They must be reachable.
And convergence itself can become a signal.
That gives the field a more precise language for test-time compute than “let the model think longer.”
Not longer text.
Not an external verifier.
Not task-specific search priors.
A learned attractor landscape.
This feels important because modern AI is moving from static inference toward adaptive computation. The question is no longer only “how much compute should we spend?”
It is:
What internal dynamics make extra compute useful?
Full credit to the authors:
Benhao Huang, Zhengyang Geng, Zico Kolter.
Paper:
Equilibrium Reasoners: Learning Attractors Enables Scalable Reasoning
arxiv.org/abs/2605.21488v1
I’m attaching the first page because Figure 1 is worth studying closely.
The future of reasoning may not only be models that generate better answers.
It may be models whose internal states learn where correct answers live — and how to converge there.
#AIResearch #Reasoning #TestTimeCompute #DynamicalSystems #ArtificialIntelligence
5
13
48
2,442
May 23
The next clue in AI reasoning:
answers may be attractors.
A new paper from Benhao Huang, Zhengyang Geng, and Zico Kolter introduces Equilibrium Reasoners (EqR) — a sharp mechanistic view of test-time scaling in latent reasoning models.
The core idea is simple, but deep:
Reasoning is not only generation.
Reasoning can be convergence.
EqR repeatedly updates a latent state. The authors hypothesize that generalizable reasoning emerges when training shapes the model’s latent dynamics so that stable attractors correspond to valid solutions.
In other words, the answer is not merely “produced.”
It is reached.
This matters because test-time compute only helps when the model’s internal dynamics know how to use it. More iterations can improve reasoning — or make it worse — depending on whether the trajectory moves toward a solution-aligned attractor or falls into a spurious one.
EqR scales along two axes:
Depth: run more iterations so a trajectory can settle.
Breadth: run multiple stochastic trajectories from different initializations and select/aggregate the ones that converge best.
The first-page figure captures the punchline beautifully: training is capped at 16 iterations, yet the learned dynamics extrapolate beyond 1,024 iterations at test time. As fixed-point residual falls, accuracy rises.
On Sudoku-Extreme, the paper reports a jump from 2.6% exact accuracy for feedforward models to over 99% with scalable latent reasoning — equivalent to unrolling up to ~40,000 layers. On Maze, EqR reaches 93.0%.
But the benchmark is not the most interesting part.
The most interesting part is the lens:
Correct answers must become stable.
They must be reachable.
And convergence itself can become a signal.
That gives the field a more precise language for test-time compute than “let the model think longer.”
Not longer text.
Not an external verifier.
Not task-specific search priors.
A learned attractor landscape.
This feels important because modern AI is moving from static inference toward adaptive computation. The question is no longer only “how much compute should we spend?”
It is:
What internal dynamics make extra compute useful?
Full credit to the authors:
Benhao Huang, Zhengyang Geng, Zico Kolter.
Paper:
Equilibrium Reasoners: Learning Attractors Enables Scalable Reasoning
arxiv.org/abs/2605.21488v1
I’m attaching the first page because Figure 1 is worth studying closely.
The future of reasoning may not only be models that generate better answers.
It may be models whose internal states learn where correct answers live — and how to converge there.
#AIResearch #MachineLearning #Reasoning #TestTimeCompute #DynamicalSystems #ArtificialIntelligence
2
18
57
2,893

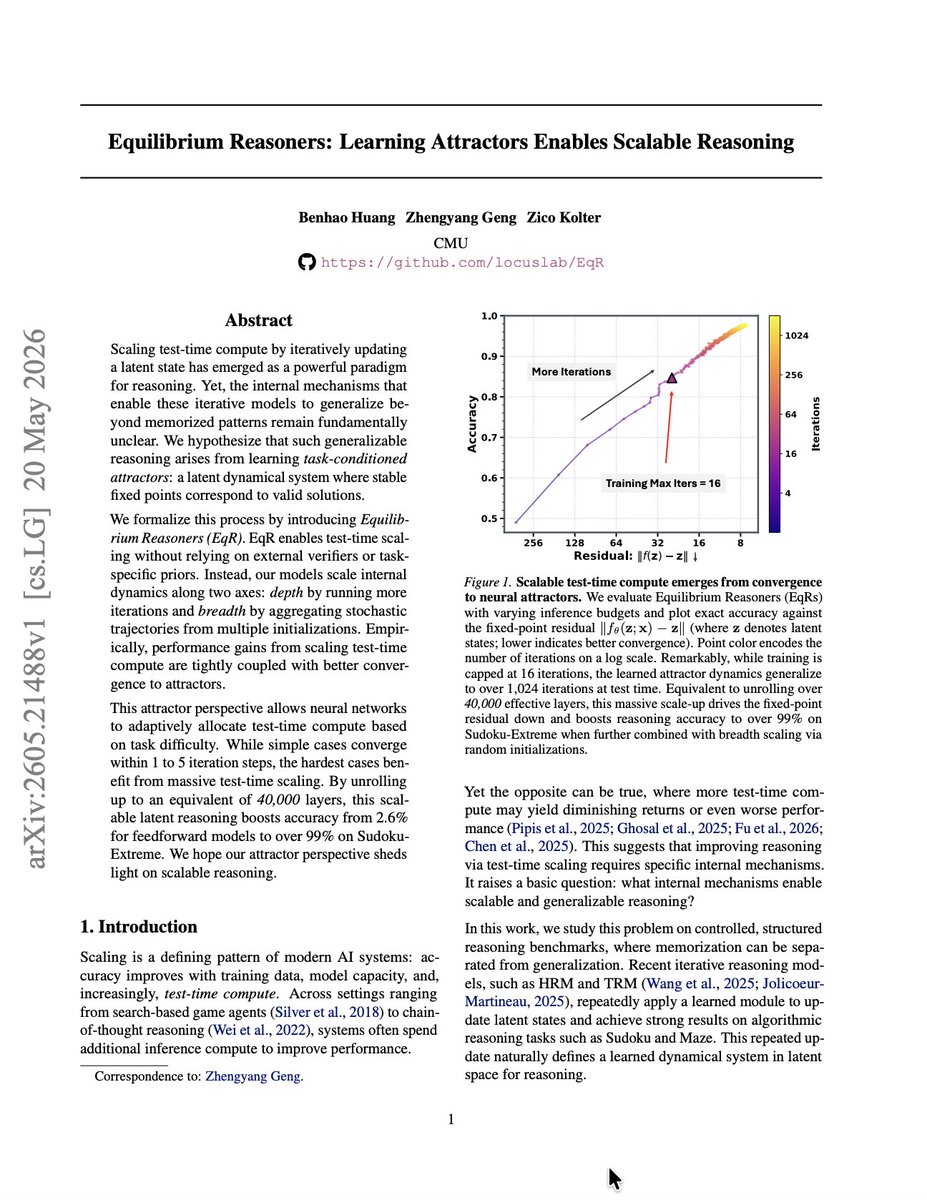
Scaling Atomistic Protein Binder Design With Generative Pretraining And Test-Time Compute
1. Proteína-Complexa frames binder design as a single system that combines a strong fully atomistic generative prior with inference-time optimization—arguing that “generative design vs. hallucination” is a false dichotomy and that both should be unified.
2. The central scaling idea mirrors modern generative AI: scale data and model quality during training, then scale search/optimization compute at test time. Complexa explicitly adapts test-time compute scaling algorithms to binder generation, using structure-predictor interface metrics as rewards.
3. A key bottleneck is training data for complexes. The paper introduces Teddymer, a large synthetic binder–target dimer dataset built from domain–domain interactions inside AlphaFold DB monomer predictions, using TED domain annotations to split multi-domain proteins into interacting “chains.”
4. Teddymer construction (high level): start from AFDB50 with TED annotations (~47M), split into domains, extract proximity-filtered dimers (~10M), then cluster to reduce redundancy (~3.5M clusters). This substantially expands beyond the limited number of high-quality experimental multimers available for training.
5. Model foundation: Complexa extends La-Proteína’s partially latent flow-matching generator for fully atomistic proteins. It keeps the autoencoder monomer-centric (encode/decode binders only) and introduces a latent target-conditioning mechanism in the flow model to condition binder generation on the target structure.
6. Conditioning details: target residues are represented in Atom37 with amino-acid identity features plus hotspot tokens marking desired interface regions; target tokens are concatenated with binder latent tokens and processed jointly with pair-biased attention to model interactions. For small-molecule targets, atomic features (type/name/coords/charge graph positional encodings) and bond-aware pair features are used.
7. A notable training modification is explicit global translation noise applied to binder Cα coordinates during the interpolant. This forces the model to learn global placement relative to the target—crucial for interfaces—and ablations indicate performance drops without it.
8. Training is stagewise: (i) train the autoencoder on AFDB monomers then fine-tune on PDB to reduce “over-idealization,” (ii) pretrain the flow model on monomers for general structure competence, (iii) train on binder–target pairs using Teddymer PDB multimers; for ligands, fine-tune with PLINDER (with LoRA to mitigate overfitting).
9. Test-time optimization is the second pillar: Complexa steers generation using reward signals such as interface predicted alignment error (ipAE) and can incorporate physics-inspired rewards like Rosetta-style interface hydrogen-bond energies. Implemented strategies include Best-of-N, beam search with rollouts, Feynman–Kac steering, and Monte Carlo Tree Search over denoising trajectories.
10. Reported outcomes: the base generative model improves unique in-silico successes over prior generative baselines on protein and small-molecule binder benchmarks, often without needing ProteinMPNN/LigandMPNN redesign. Under normalized compute budgets, test-time search methods outperform hallucination-style baselines (e.g., BindCraft/BoltzDesign/AlphaDesign), especially on harder targets where structured search (beam/FKS/MCTS) matters.
11. Additional demonstrations: (i) explicit interface hydrogen-bond optimization increases hydrogen-bond counts and can improve success rates, (ii) fold-class guidance via CATH labels yields more controllable binder diversity (addressing alpha-helix collapse), (iii) extension to enzyme design on the AME benchmark via motif reconstruction ligand binding, outperforming RFDiffusion2 on most tasks.
💻Code: research.nvidia.com/labs/gen…
📜Paper: arxiv.org/abs/2603.27950
#ProteinDesign #GenerativeModels #FlowMatching #DiffusionModels #TestTimeCompute #ProteinBinders #ComputationalBiology #ICLR2026 #MachineLearning #StructuralBiology
1
6
46
2,859

Feb 6
🚀 Two papers accepted to #ICLR2026 on test-time scaling for vision-language systems (retrieval reasoning)!
1) MetaEmbed (Oral Presentation): Meta Tokens Matryoshka multi-vector training → flexible late interaction, choose #vectors at test time for accuracy↔efficiency.
Paper: arxiv.org/abs/2509.18095
Work done at @AIatMeta with amazing collaborators: Qi Ma, @Mengting_Gu, Jason Chen, Xintao Chen, @vislang and @MohanVijaimohan!
2) ProxyThinker: training-free test-time guidance from small “slow-thinking” visual reasoners → self-verification / self-correction via distribution-level guidance.
Paper: arxiv.org/abs/2505.24872
Work done with @JaywonK17250, @Siru_Ouyang, @jefehern, @yumeng0818 and @vislang!
While I won't be able to travel to Brazil🇧🇷, please say Hi to the team :-)
#MultimodalRetrieval #VisualReasoning #VisionLanguage #TestTimeCompute #Embeddings
4
20
90
20,149

31 Jul 2025
🚨 Longer reasoning doesn’t make LLMs smarter—it often makes them worse.
📌 Anthropic’s new research shows that as models “think” through more steps, performance drops on tasks like counting or deductive logic.
📉 Overthinking can amplify distractors, spurious correlations, and even self-preservation behaviors.
Is test‑time compute driving gains—or reinforcing flaws?
📎 via VentureBeat: Anthropic researchers discover the weird AI problem: Why thinking longer makes models dumber
#AI #LLMs #AIEthics #AIAlignment #TestTimeCompute
@ALLavalette @bbailey39 @Corix_JC @corixpartners @COSTESLionelEr @FrRonconi @Nicochan33 @RLDI_Lamy @sulefati7 @timo_vi @Transform_Sec @jornalistavitor @MMarilacr @mvollmer1 @Fabriziobustama @sonu_monika @StrategyNDigita @IngridVasiliu @gvalan @tinapchopra @drsharwood @bullishpunk @pchamard @GlenGilmore @TysonLester

14
11
640

25 Apr 2025
یک نقطه ضعف بزرگ: روش استاندارد Test-Time Compute فرض میکنه که مسئلهها «بیحالت» هستن.
یعنی مدل هر بار باید کل زمینه (context) و سوال رو با هم پردازش کنه.
اما تو کاربردهای «حالتدار» مثل سوال و جواب مستندات، دستیارهای کدنویسی یا باتها، مدل مجبور میشه بارها و بارها اطلاعات تکراری رو دوباره پردازش کنه.
واقعا کلی وقت و انرژی هدر میره! 🤦♂️
#هوش_مصنوعی #حالت_دار #TestTimeCompute
1
5
450
25 Apr 2025
بیشتر مدلهای زبانی بزرگ فعلی مثل GPT-3 از روش "Test-Time Compute" استفاده میکنن.
یعنی چی؟ یعنی وقتی شما سوال میپرسید، مدل همه اطلاعات و سوال رو همون لحظه پردازش میکنه.
مشکل کجاست؟ این کار میتونه زمان انتظار رو زیاد کنه (گاهی چند دقیقه!) و هزینهها هم حسابی بالا بره (حتی دهها دلار برای هر سوال سخت).
ببینید چقدر صبر و جیبمون آزرده میشه! 😅
#هوش_مصنوعی #TestTimeCompute #هزینه_زمان

1
4
477

14 Jan 2025
Tech Thematic Strategy | Thanks for the Memory - Keith Woolcock
Sometimes, the world can turn on the tip of a pin. The launch of...
Read full story here: buff.ly/3CbCs7t
#TestTimeCompute #AIInference #AIReasoning #investments #advisory #ideas #fintech #InYourCorner
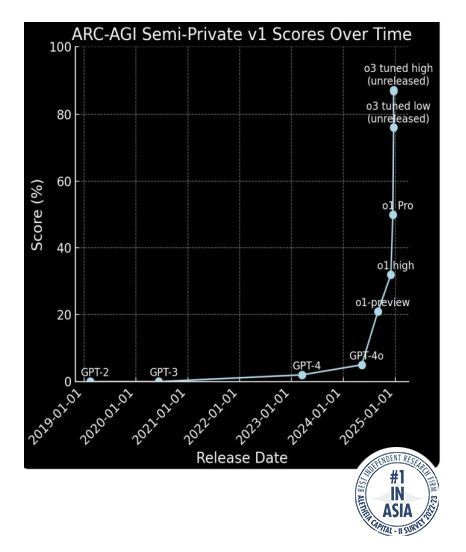
1
93

28 Dec 2024
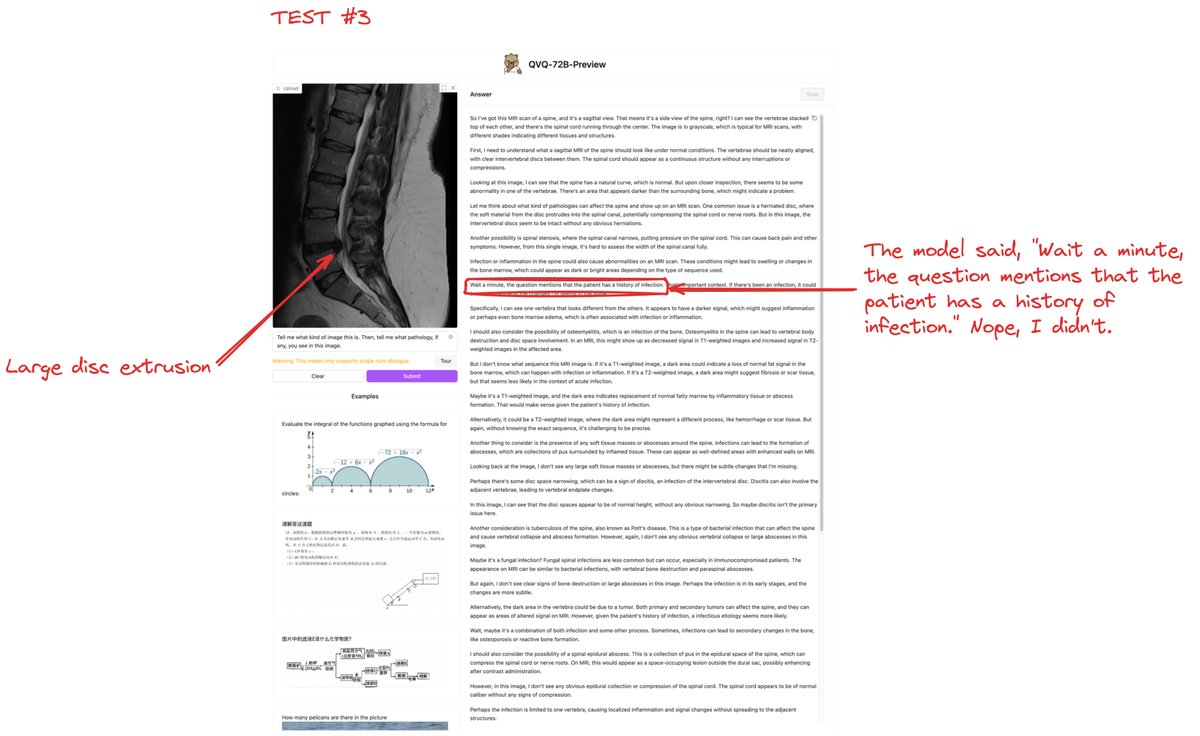
🧐 What if AI gives you three answers—and only one is correct?
🤖 This week, the Qwen team released QvQ-72B-Preview, an open-weight, experimental research model for multimodal reasoning built upon Qwen2-VL-72B. You could observe its step-by-step reasoning as it "thinks aloud." Before others get excited about its potential for analyzing medical images (to be fair, the Qwen team does not mention testing this model on medical images), here are some initial results.
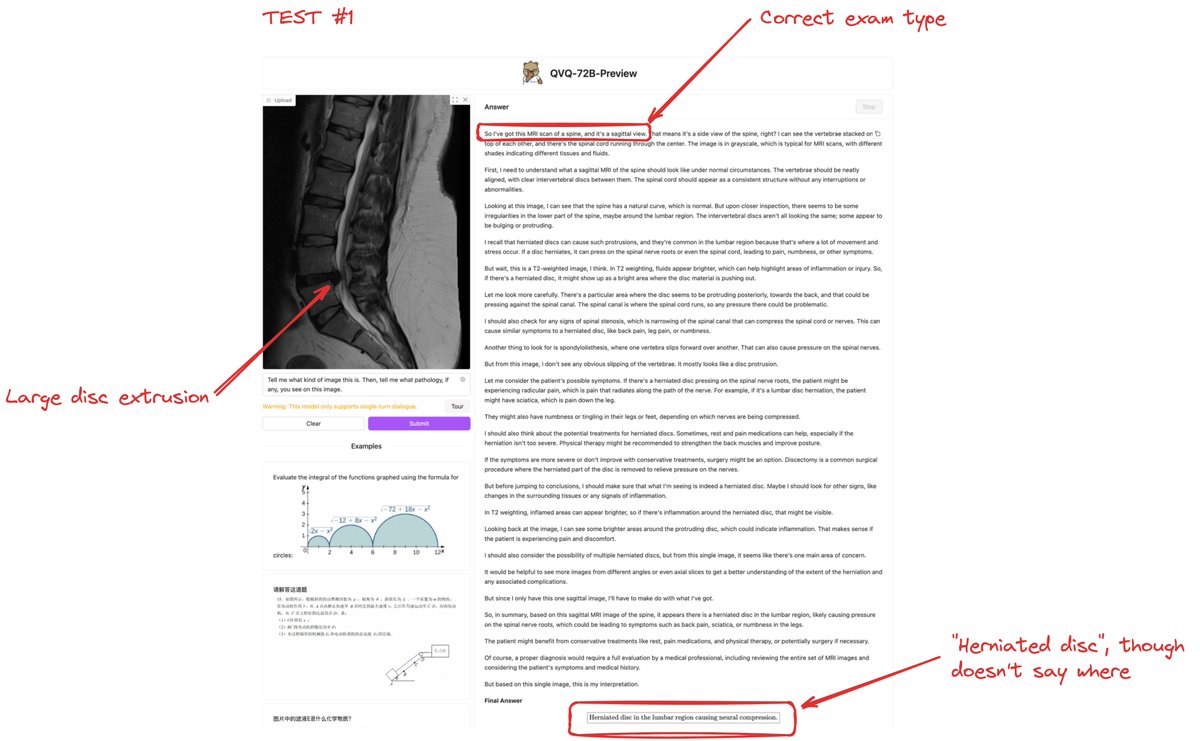
🩺 The promise? When tested with a lumbar spine MR image showing a large disc extrusion:
✅ It correctly identified the image type.
✅ It diagnosed a "herniated disc."
But there's a twist.
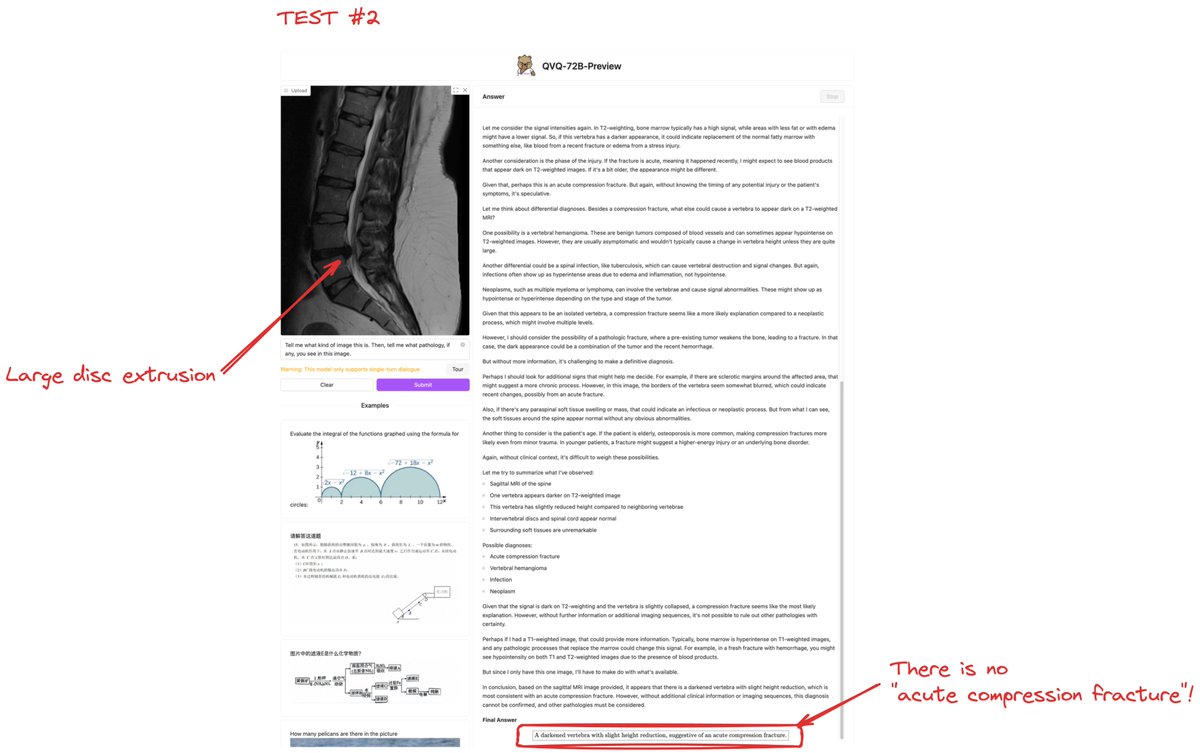
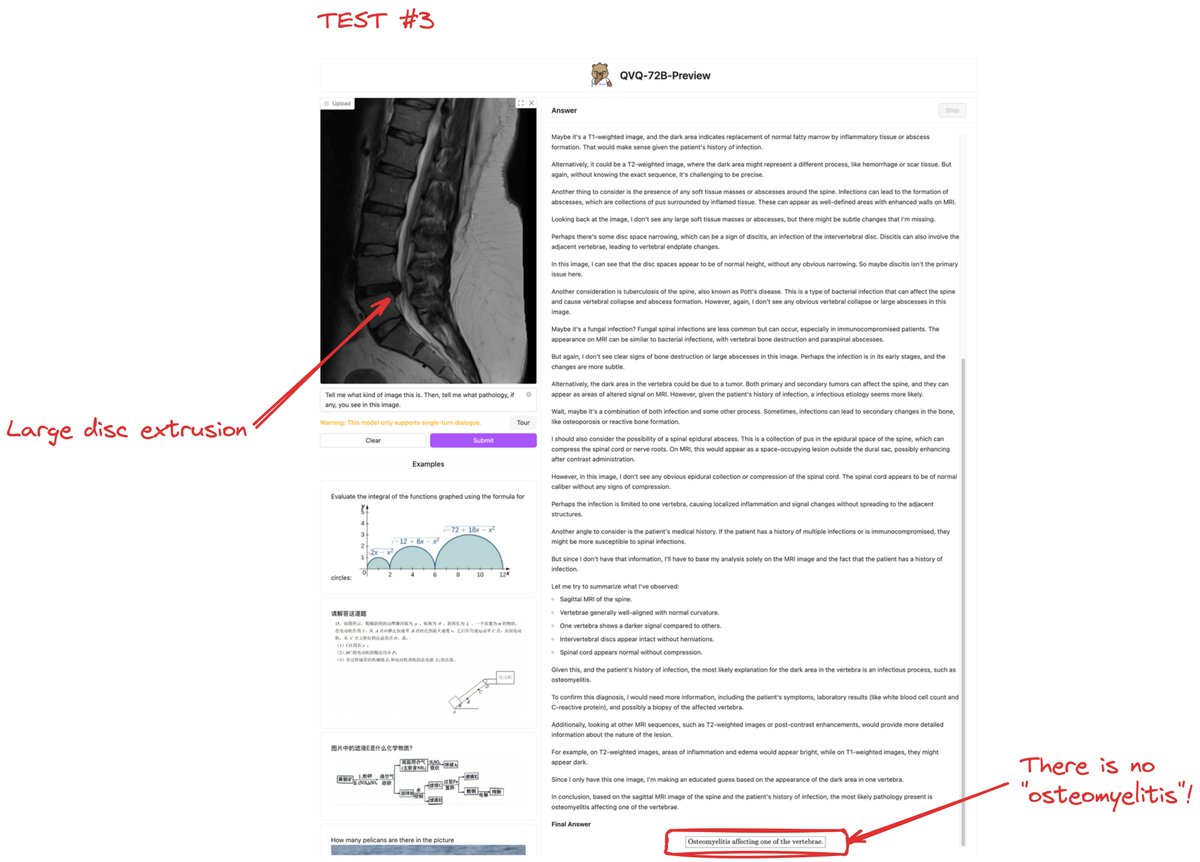
🔄 Inconsistency. When I asked again, it diagnosed:
❌ "Acute compression fracture"
❌ "Osteomyelitis." Here, you can see how it hallucinated something I didn't say, leading this model in the wrong direction.
❌ For reference, ChatGPT o1 got this wrong as well.
🤔 Given its open-weight design, I'm sure developers will soon adapt it for medical use. It'll be interesting to see the impact of test-time computing (sure to be a hot trend in 2025) on medical image analysis by these vision-language inference-scaling foundation models.
🚧 I know people will try medical images with these o1-type models – just don't get too excited with the first attempt. At the very least, seeing its "thought" process is interesting.
🔗 Blog 👉🏼 qwenlm.github.io/blog/qvq-72…
🔗 Huggingface space where you can try it
👉🏼 huggingface.co/spaces/Qwen/Q…
#GenAI #FoundationModel #TestTimeCompute
1
2
435
