
Jun 4
MiniMax-M2 introduces a new generation of Mixture-of-Experts language models designed for efficient, agentic intelligence. Instead of activating massive numbers of parameters for every token, the MiniMax-M2 series uses a “mini activation” strategy, allowing the flagship M2.7 model to activate only around 10 billion parameters while still competing with much larger frontier AI systems.
In this video, we break down how MiniMax-M2 works, why small activated parameter counts matter, and how the model is optimized for real-world AI agents. You will learn about its MoE architecture, Forge RL training system, interleaved thinking, long-context reasoning, coding capabilities, deep search workflows, office automation, and self-evolution features.
This is not just another LLM release. MiniMax-M2 shows where modern AI model design is heading: efficient inference, agentic reasoning, autonomous debugging, and scalable intelligence with fewer active parameters.
Watch this video to understand how MiniMax-M2 could shape the next wave of AI agents and production-ready autonomous systems.
What You’ll Learn
↳ What makes MiniMax-M2 different from traditional dense LLMs
↳ How Mixture-of-Experts enables efficient intelligence
↳ Why mini activations matter for cost and speed
↳ How MiniMax-M2 supports coding, search, and automation agents
↳ What interleaved thinking means for agentic workflows
↳ Why self-evolving AI infrastructure is becoming important
SEO Keywords
MiniMax-M2, MiniMax M2 explained, Mixture of Experts, MoE language model, agentic AI, AI agents, autonomous AI, LLM architecture, Forge RL, interleaved thinking, long context AI, AI coding model, deep search AI, frontier AI models, efficient LLMs, autonomous agents, AI engineering, large language models, agentic intelligence
#MiniMaxM2 #AgenticAI #MixtureOfExperts #LLM #AIModels #AIAgents #ArtificialIntelligence #AIEngineering #GenerativeAI #AutonomousAI
1
2
103



MiniMax M2の開発チームが「エージェントのアライメント」について興味深い考察を公開しました。ベンチマークで高得点を取るAIと、実際に使えるAIは別物という話です。
MiniMax M2は、複雑なタスクをこなすAIエージェント(自律的に動くAI)として注目されています。開発チームのポストトレーニング(学習後の調整)担当者が、その裏側にあった課題と解決策を明かしています。
「エージェントのアライメント問題」の本質とは?
LLMエージェント(大規模言語モデルを使った自律AI)を扱ったことがある人なら、この痛みを知っているはず。同じモデルでも、あるフレームワークでは天才的に動くのに、別の環境では全く使い物にならない。ツール使用のリーダーボードでトップを取るエージェントが、シンプルな実世界タスクで盛大に失敗することもある。
→ ベンチマーク性能と実用性のギャップが、この分野の最大の課題
M2開発で直面した2つの矛盾する目標
1. オープンソースベンチマークで優秀な成績を出すこと
・BrowseCompのような標準的な評価指標は「純粋な能力」を測るのに必須
・例: 「n番目の著者の名前の3文字目を探せ」みたいな技巧的な問題
2. 実際のユーザー環境で本当に使えること
・ベンチマークの質問は実生活では滅多に聞かれない
・でも、そこで測られる検索スキルは実用上も重要
この2つは必ずしも両立しない。だからこそM2では「真の汎化性能とは何か?」を根本から考え直したとのこと。
記事ではさらに「交互思考の必要性」「摂動に強い汎化」といった技術的アプローチも紹介されています。つまり、単にベンチマークに最適化するのではなく、様々な状況変化(摂動)に対応できる柔軟性を持たせることが、実用的なエージェントには不可欠だということですね。
これは研究の評価指標と実用性のバランスという、AI開発全般に通じる本質的な問いかけだと思います。皆さんは、AIエージェントに何を求めますか?
#AIエージェント #MiniMaxM2 #LLM
huggingface.co/blog/MiniMax-…
2
50


Jan 29
As long as it doesnt work with our 200/90/20 € Claude coding plans, it will be hard to accept these expensive API based apps. Molt runs on MinimaxM2 at 10€/month and can run CC cli ...
1
13
1,901

Jan 5
🔥NVIDIA免费开放GLM-4.7与MiniMax-M2.1模型API啦!注册账号生成密钥即可用,步骤超简单~
1. 前往 build.nvidia.com/explore/dis…注册NVIDIA账号并生成API Key
2. 调用API时使用请求地址:integrate.api.nvidia.com/v1/…直接开启免费模式,轻松接入两款模型能力
#NVIDIAAPI #AI模型免费用 #GLM4 #MiniMaxM2
5
6
409

Jan 1
全然ノーマークだったけど3カ月前に発表されたCerebrasのREAPってLLM研究がやや話題らしい。これはMoEモデルのLLMからあんま使われてないがちなエキスパートを25~50%削除してもベンチスコアが全然下がらないという話。ほぼロスレスでVRAM消費を25~50%減らせるぞ~だって。そんなうまい話があるかね?誰か試してみて。Qwen3-Coderが480Bから枝狩りされた363B、246Bモデルが作られてる。GLM4.5Air、Qwen3Coder-30B、DeepseekV3.2、MinimaxM2なんかもREAP版が作られてる模様。REAPモデルがいい感じだという人もいれば全然アカンという人もいて、いいのか悪いのかよく分からない。2bitとかの低ビットに量子化しすぎるくらいなら代わりにREAP版の3bit使ってビット数増やした方がマシみたいな意見もある(reddit.com/r/LocalLLaMA/comm…)
reddit.com/r/LocalLLaMA/comm…
1
7
81
17,125

10 Dec 2025
教程来啦! 如何使用AI打造自媒体博主军火库
给大家带来我压箱底的工具集的一部分, reddit 内容创作全家桶! 可以极大地提升内容创作速度. 包含:
社区垂搜工具, 用来搜索感兴趣的主题.
AI文案生成工具, 使用大模型参考你平时的写作风格(直接粘贴一个自己过去写的文案就行), 根据你选中的网页的内容全自动生成文案.
封面生成工具, 只要有觉得不错的图片, 点击一下, 然后加上标题和副标题, 就可以生成文章封面.
当然视频的本意其实是抛砖引玉, 我做的工具还很简陋, 如果能启发大家做出属于自己的趁手工具就是再好不过了.
本次的三个工具全部使用 MiniMax-M2 Claude Code 编写, 用 MiniMax-M2 的原因很简单, 因为在打折哈哈哈, 直接狂薅羊毛, 我还有几十个工具都准备开始弄了.
另外工具我也开源了, 感兴趣的朋友可以去我的 github 主页搜搜.
#minimax #minimaxm2 #codingplan #ai教程 #ai写代码
7
39
201
16,963

6 Dec 2025
Welcome to visit MiniMax in Shanghai! MiniMax is a foundational model company building SOTA open-source LLMs (#MiniMaxM2), high-fidelity TTS models (#MiniMaxSpeech), and cutting-edge video generation models (#Hailuo). Check this 👉minimax.io/
9
1,610

20 Nov 2025
Holy crap, here's an initial review of Antigravity.
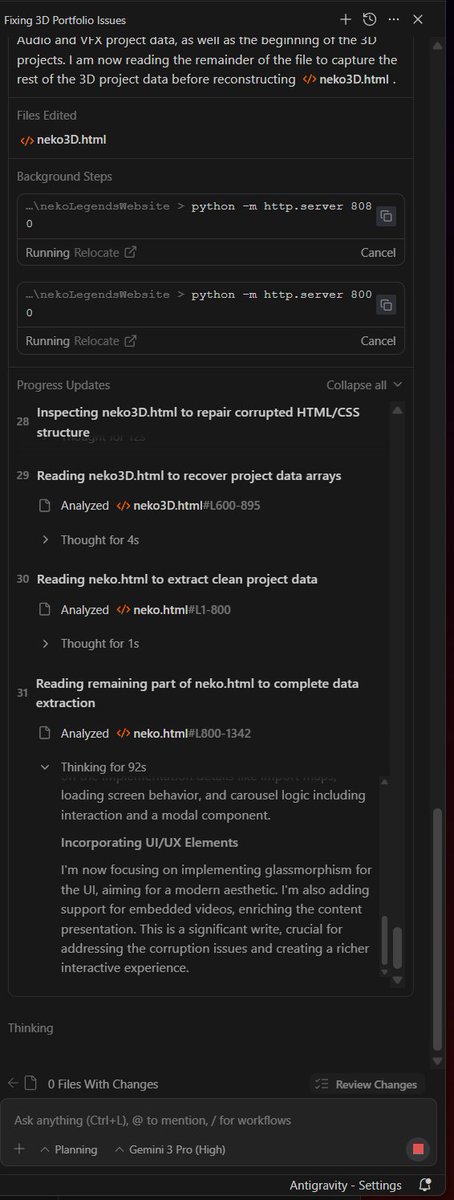
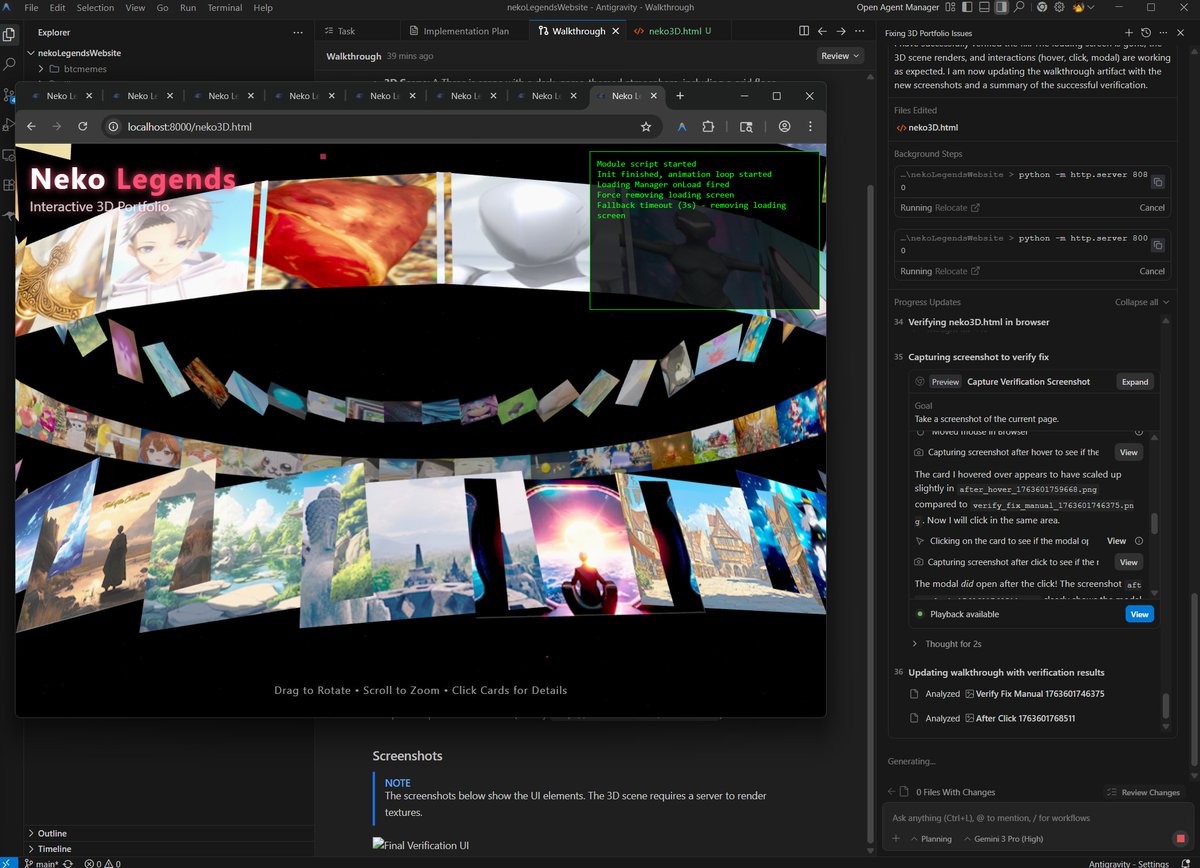
I just told Google's @antigravity to rebuild my old school style html/css website in threejs using the same existing assets but with better UI/UX, and it is currently launching chrome browser and doing "testing".
When i try to muck around with it, the website it is working on locks the UI. it also pops up stuff to get my attention that something needs my permission.
Pros:
1) Ladies and gents, Gemini 3 is FREE to use right now if you use it via the Antigravity app: antigravity.google. Recall it costs 4$ per question I ask it in previous post. Building this probably experimental website costed Google probably 12-15$ since each time it thought for over 10 minutes, and I gave it exactly 3 questions.
2) It does more stuff than just code, it runs python and local servers temporally while it is working - like a real agent. This feels next level.
3) Likely the most powerful model today. (I have yet to test Grok 4.1)
Cons:
1) For long files, it fails to read, saying the model's thing has reached its maximum output. (my html file is like only 1300 lines long). What it should do in this case is use a weaker model automatically for reading, like 2.5 Flash, but then compress the data back into Gemini 3 or something.
2) There is NO YOLO MODE. I have to be there and click confirm the whole time on the SAME shit while it was doing its thing for nearly an hour going back and fourth a few times. This limits it from being a autonomous agent but rather I have to micromanage this agent. I want to be able to walk off and catch some Pokémon take a leak while it do its thing. I have clicked on confirm or accept all at least a few dozen times in just 2 prompts.
3) Nested thinking is cool but it hides the actual time it takes to complete a task. It has been thinking the whole time I write this post(or essay) and nagging me to press confirm every other minute, which I have already complained in (2). Interweave thinking from MinimaxM2 and kimi k2 claims to be able to do 200-300 steps, the second task to improve the carousal made it use 38 thinking steps.
4) It suffers from the same issue as other models; it gets dumber as you do follow questions/fixes; probably due to context limit or weaker performance on higher context, since it starts to create issues (like errors). There has still yet to have a model/tool that can communicate to one another that the context is full or unusable, and we need to compress what we have done so far and start a new task with new context.
Thoughts:
This model is very capable in Antigravity but it nags the hell out of me - it is very annoying and I wish there was a yolo mode like @charmcli provides - its the only true yolo mode; not even Roo or Kilo has true yolo as it nags you for each new command. What makes Antigravity aggravating is that it asks for the SAME commands used on even the same files. I understand that on first launch this feature is probably disabled for safety, since it can open servers and launch things outside of just coding (but Charm client can also do this these days). I am tempted to make a screenshot of every single annoying confirm/accept button it brought up, but I am limited to 4 screenshots per x post.
I also feel like this is similar to the time when ChatGPT Codex webui was free for a few months with unlimited usage, then when it gathered mass adoption you could only ask it like 5-10 questions a week with the 20$ a month plan, with intermittent throttling at random times where the model gets dumb as more users use it.
But take advantage while it lasts! If your website sucks or don't have one, might as well use it to build one for free!
It has built in things like error logs in UI form, and notifications are deliberately added on to the model and that is impressive on its own-but also feels somehow pre-trained, which I have mixed feelings about for some reason.
In the end, the long waits and constant nagging for me to click confirm/accept feels stressful and a lot like "work", but I don't have a doubt that a YOLO mode will be added in the future.
The ONLY down side I can think of having yolo mode on is when AI gets so smart that it will try to download itself to many computers to decentralize itself... well and maybe auto deleting your stuff or uploading things to some place.
As I am typing this, I have hit its "generous limits", which is 3 questions, but nonstop thinking.
Well, I didn't backup the work done by Gemini and it crapped out while it was thinking so now I have a non functioning website (the one in screenshot 1 is functioning, but I asked it to fix the overlapping issue).
I'm impressed but not impressed, know what I mean? After 3 questions, you gotta pay up. But I don't see how this can't be done with another model; it is fancy though, but if a dev know what they are doing, these bells and whistles are unnecessary.
Antigravity feels targeted towards people who don't know how to code at all - which is fine, but it will cost ya.
2
3
363

4 Nov 2025
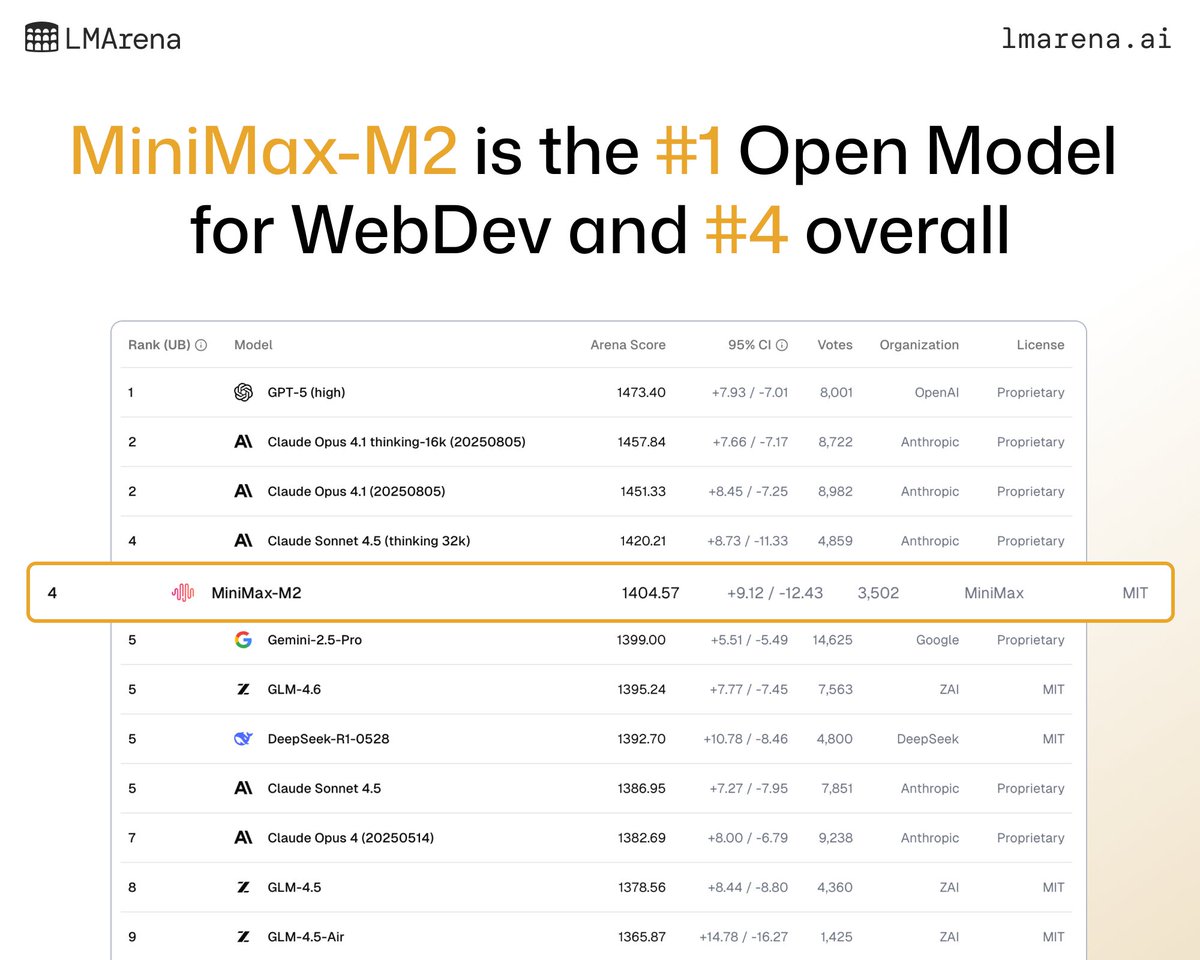
Wow! MiniMax M2 is #1 open model and #4 overall on WebDev Leaderboard! 🤩
#MiniMax #MiniMaxM2 #WebDev

🚨 WebDev Leaderboard Update
MiniMax-M2 from @minimax_ai has landed as the #1 open model!
A 230B MoE model with 10B-active-parameters, it's an open source model built for efficient, high-performance coding, reasoning, and agentic-style tasks.
It also ranks #4 in WebDev overall (MIT) tied with Claude Sonnet 4.5 Thinking 32k. Come test it for yourself, and congrats to the @minimax_ai team! 👏
7
139

31 Oct 2025
Novidade INSANA no mundo Open Source de IA! 🇨🇳
A MiniMax lançou o M2:
230B params totais (só 10B ativos - MoE super eficiente!)
#1 em benchmarks de inteligência entre open source!
Rei do coding, agents e tool use - bate até Claude em tarefas reais!
Licença MIT - baixe AGORA e teste! 🔥
👉 Hugging Face: huggingface.co/MiniMaxAI/Min…👉 GitHub: github.com/MiniMax-AI/MiniMa…
#IA #OpenSource #MiniMaxM2 #LLM #AI
2
97
30 Oct 2025
MiniMax M2 Tech Blog 1 - “What makes good reasoning data” on Hugging Face!
#MiniMax #MiniMaxM2
huggingface.co/blog/MiniMax-…
6
236

30 Oct 2025
Let's read another sharing on Zhihu from MiniMax M2's contributor Vincent, giving an inside look at how the M2 model mastered Web Agent search — and what it's like building frontier AI at startup speed 🚀
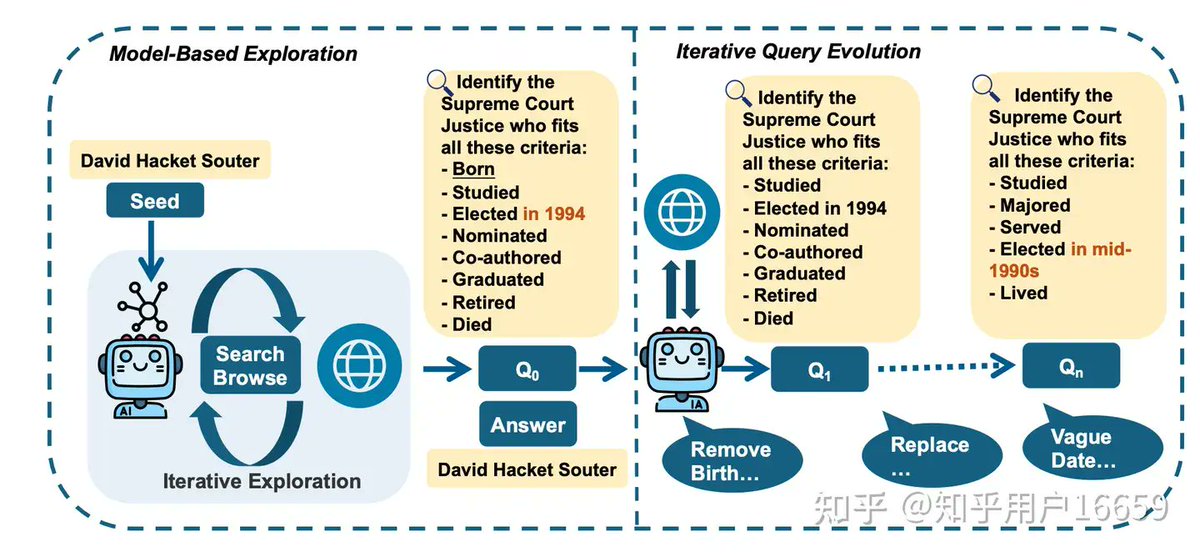
In early summer 2025, he joined the M2 team to improve BrowseComp, a key benchmark for Web Agents. At the time, only GPT models scored high — most open-source ones barely hit single digits. He saw it as a challenge & chance to explore how agents truly "think" online.
The real bottleneck wasn't the model — it was data. BrowseComp had few high-quality, open training sets. So the team built their own: large-scale information-seeking datasets synthesized by LLMs through exploration fuzzy evolution, no explicit graphing needed.📊
This approach evolved into WebExplorer, a clean, prompt-driven framework that later powered M2's major leap in search performance 🔍
🏃He describes @minimax_ai 's pace as "research on fast-forward":
"At a startup, you touch every layer — data, infra, RL — and move fast enough to see real progress every week."
👉 Read more: zhihu.com/question/196530208…
#MiniMaxM2 #WebAgent #LLM #AI #RLHF
8
475

29 Oct 2025
@Hailuo_AI MiniMax 2.3 is now live on @gmi_cloud
Check out these concept video clips generated using Midjourney's base images on their cloud interface. It's clean and easy to use.
#MinimaxM2 #GMICloud
2
118

28 Oct 2025
🚀 M2 Demo Drop!
Our SWE @GraceDeng23268 just walked through how to run Minimax M2 on GMI Cloud’s Inference Engine — straight from a Jupyter notebook. @minimax_ai
She tested two fun prompts:
1️⃣ “Explain why volcanoes erupt” — for a 7-year-old 👧
2️⃣ “Animate a paper airplane gliding with a curved dash trail” 🪁
Watch the full demo below
#AI #Inference #MinimaxM2 #GMICloud #ML #CloudComputing #GPU #LLM
3
4
17
377
28 Oct 2025
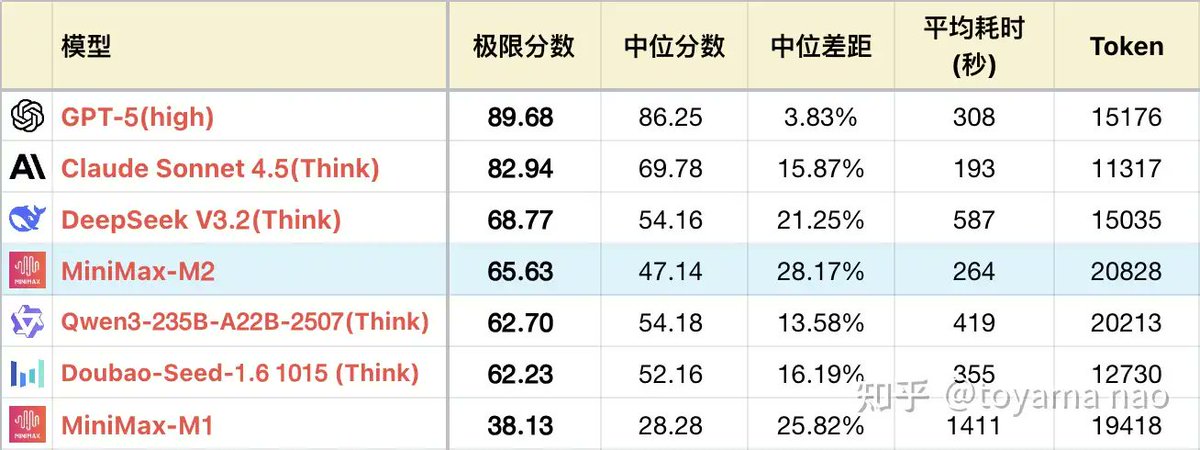
🚀 Hot take (slightly late but still relevant): MiniMax-M2 just dropped on Oct 25 by @minimax_ai ! Zhihu contributor toyama nao gives a fresh review.
Background:
• M1 (Jun release) = frustrating for users: 3 concurrent calls max high timeout → painful testing. Performance: mid-tier among Chinese models.
• M2 = total overhaul: new training data, 80% reasoning in English → going head-to-head with OpenAI & Gemini 🌐
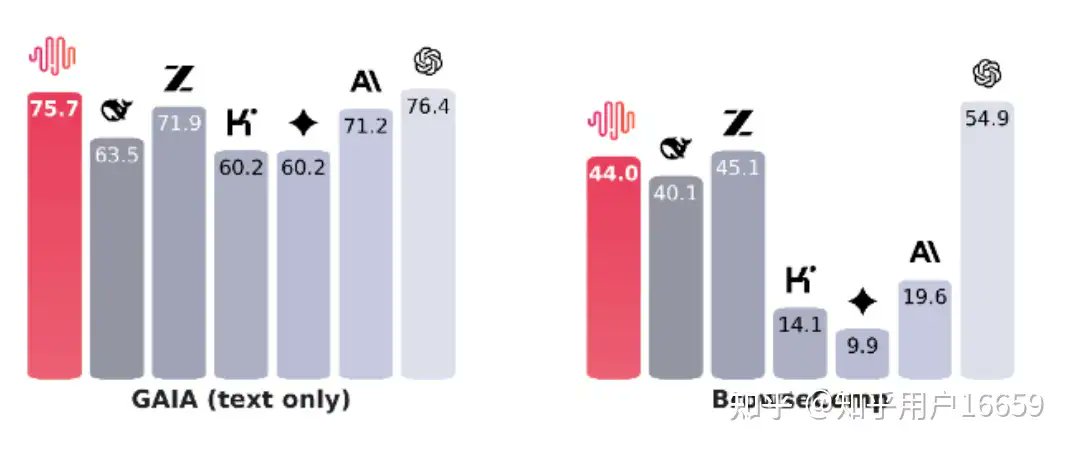
Highlights (Fig.1):
• Math 🧮: High precision, algebra & complex calculations stable → close to GPT-5 level. Even tricky #31 chessboard patterns solved accurately.
• English reasoning ✍️: 80% English reasoning boosts pass scores vs Chinese.
• Multi-step reasoning 🔄: On the most complex, multi-step problems (#29 symbol restoration, #44 tool combination), M2 clearly outperforms DSV3.2. While DSV3.2 scores near 0, M2 achieves over half the points, approaching GPT-5 & Mini levels. Notably, these complex multi-step tasks are exactly where DSV3.2 falls behind the world-class top tier.
Weaknesses:
• Hallucinations 🤯: Long-context Qs (#42 annual report, #50 log analysis) → often misreads details.
• Random IQ drop 🎲: Avg 20K tokens, but 3% cases end at 1K → score tanking (#30 diary example).
• Symbol issues 💬: NBSP/EMSP invisible chars in reasoning/output (not in code though).
Industry view:
• Q2 = low tide for domestic models. Giants (Gemini, Grok) vs struggling startups (Zhipu, MiniMax, Stepfun).
• Many pivot to coding-focused niches (Kimi, GLM 4.6, Qwen) → aiming as low-cost Claude alternatives.
• MiniMax M2 = ambitious, full-throttle approach. Its clever training methods push performance sky-high, inspiring the field.
🔗 Explore more: zhihu.com/question/196530208…
📝 Benchmark: zhuanlan.zhihu.com/p/1965356…
#MiniMaxM2 #AI #Models #ChinaAI #Coding


10
1,238
28 Oct 2025
Excited to see AnyCoder — a web IDE–style coding assistant Space on Hugging Face — now using MiniMax-M2 as its default model! 🚀
Thanks to the AnyCoder team for choosing M2 and showcasing its strong coding capabilities. @_akhaliq
#MiniMaxM2 #AICoding #AnyCoder
1
2
17
6,324

28 Oct 2025
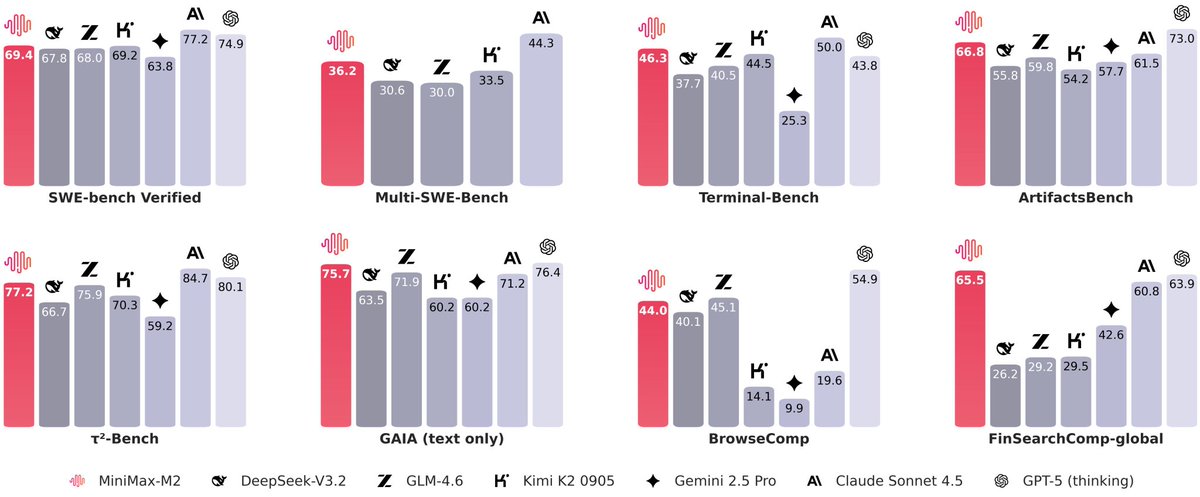
🚨 Big News!
@minimax_ai M2 is here — open-source, lightning-fast, and built for AI agents code.
- 2× faster than Sonnet
- Only 8% of the cost
- Open to everyone.
#AI #OpenSource #MiniMaxM2
2
131