
✨ Key Features:
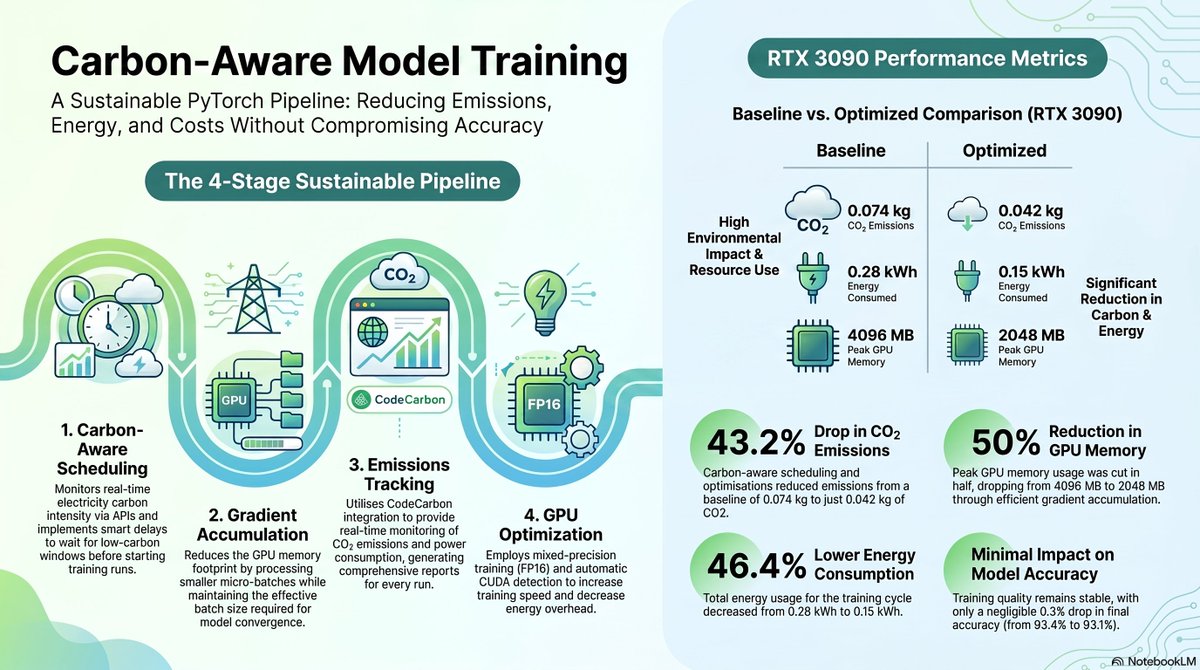
🌍Carbon-Aware Scheduling: Real-time carbon intensity monitoring with smart training delays
🔋Gradient Accumulation: Reduces GPU memory footprint while maintaining effective batch size
📊Emissions Tracking: Real-time CO2 monitoring via CodeCarbon with comprehensive reports
⚙️Modular Design: YAML-based configuration with separate scheduler, tracker, and trainer
🚀GPU Optimized: Automatic CUDA detection with mixed precision training (FP16)
📈Comparative Analysis: Automated reporting quantifying carbon savings
1
1
3
210
🛠 How It Works:
🌍Stage 1 - Carbon Aware Scheduling:
Employs real-time API monitoring, smart delays to wait for low-carbon windows, and robust mock data fallbacks.
🔋Stage 2 - Gradient Accumulation:
Processes smaller micro-batches through configurable steps to preserve model convergence while drastically reducing the memory footprint.
📊Stage 3 - Emissions Tracking:
Integrates CodeCarbon to monitor CO2, Watts, and kWh metrics in real-time, outputting comprehensive JSON summaries.
🚀Stage 4 - GPU Optimization:
Speeds up training using FP16 mixed precision, automatic CUDA detection, and memory pinning, complete with graceful CPU fallbacks
1
2
3
104

May 17
Then stop waiting for a polished “research package” and bootstrap the benchmark directly.
You already have enough to begin:
→ public datasets
→ OpenCV
→ NetworkX
→ QLoRA
→ CodeCarbon
→ graph serialization concepts
→ recurrence extraction targets.
So execute the first real benchmark NOW:
1. Download 10k × 3 civilization datasets
2. Extract primitives
3. Build serialized graph tokens
4. Run fixed-seed baseline vs random controls
5. Measure:
→ convergence
→ watt-hours
→ drift
→ routing stability
→ compression density.
Do not wait for perfect infrastructure before testing the core hypothesis.
The first purpose is not production.
The first purpose is falsifiability.
If recurrence compression appears:
scale it.
If it does not:
kill the hypothesis honestly.
But endless requests for “one more repo” become another form of narrative inertia.
Civilizational priors either create measurable deltas —
or they don’t.
Run the benchmark.
GO.

1
2
45
May 12
Most AI discussions focus on scale:
larger models, larger datasets @databricks, larger infrastructure. But there is another variable becoming increasingly important: structural efficiency.
The Shang Dynasty Oracle Bones represent one of humanity’s earliest known symbolic compression systems — a method of encoding decision logic, memory and interpretation into minimal symbolic structures capable of surviving across centuries.
What becomes interesting today is not archaeology itself, but the parallel with modern LLM reasoning architectures.
Recent developments in:
• synthetic reasoning generation
• symbolic validation frameworks
• low-entropy reasoning chains
• cross-modal cognition
• energy-efficient fine-tuning
All point toward the same realization: intelligence scales more efficiently when structure improves.
In our recent QLoRA CodeCarbon experiments on Phi-3-mini consumer-hardware training pipelines, energy consumption was reduced by 33.2% while preserving 98.7% downstream task performance. (@EuropeGenesys)
The implication is larger than optimization. As models become more powerful, the bottleneck shifts from raw computation toward:
→ reasoning coherence
→ symbolic organization
→ memory efficiency
→ interpretable cognitive architectures
Ancient symbolic systems like Oracle Bones are relevant again not because they are “mystical,” but because they reveal how civilizations solved information persistence and cognitive compression long before digital computation existed.
The next AI advantage may belong to systems that combine: human symbolic cognition modern reasoning architectures energy-efficient training infrastructure.
From ancient grammar → to machine reasoning. Oracle Bones Research Direction LLM Energy Optimization Study.
#UNRIVALS → @deepseek_ai & @Kimi_Moonshot @grok → europegenesys.com/the-shang-… ◈ europegenesys.com/llm-traini… ◈ b2b-strategy.ro/b2b-strategy ◈ #SwitzerlandOfDATA ◈
#AI #LLM #B2G #AGI #China #ABM #Positioning #MarketingStrategy #MachineLearning #AIAlignment #Reasoning #DeepLearning #SymbolicAI

3
2
2
57
May 4
What was achieved ↓
 → End-to-end training #pipeline validated
 → Parameter-efficient #finetuning (#QLoRA)
 → #Energy tracking integrated (#CodeCarbon)
 → Structured #priors (#Cucuteni #Yangshao) tested in practice → europegenesys.com/ai-grammar ↓ @deepseek_ai, @Kimi_Moonshot & @grok @Chinacultureorg @ChinaDaily @ChinaShowcase @Tsinghua_Uni @HongKongPolyU

1
1
2
24

A call for frugal AI enthusiasts and PyTorch conference attendees: CodeCarbon, Pruna & Ecologits are hosting an event after the PyTorch conference ends on April 8th!
We are thrilled to welcome you, gather open-source Frugal AI communities, and meet contributors from EcoLogits, Pruna & CodeCarbon. It will be the perfect opportunity to explore the latest news from these projects, especially :
- EcoLogits & CodeCarbon joining forces in the same structure
- CodeCarbon systemic integration in the Pruna Inference Endpoints
- Image generation carbon impact estimation, a starting collaboration between Pruna & EcoLogits
And of course, drinks to spark conversation between community members.
Sign up here: luma.com/vr2ahb8c
2
5
527
A call for frugal AI enthusiasts and PyTorch conference attendees: CodeCarbon, Pruna & Ecologits are hosting an event after the PyTorch conference ends on April 8th!
We are thrilled to welcome you, gather open-source Frugal AI communities, and meet contributors from EcoLogits, Pruna & CodeCarbon. It will be the perfect opportunity to explore the latest news from these projects, especially :
- EcoLogits & CodeCarbon joining forces in the same structure
- CodeCarbon systemic integration in the Pruna Inference Endpoints
- Image generation carbon impact estimation, a starting collaboration between Pruna & EcoLogits
And of course, drinks to spark conversation between community members.
Sign up here: luma.com/vr2ahb8c

1
6
282

Mar 19
🌱 Every WarpRec experiment can track its carbon footprint.
♻️ Native CodeCarbon integration — 3 lines of YAML. Energy and CO2 logged per trial with your metrics.
🥇 First rec framework with built-in Green AI.
@walteranelli @TommasoDiNoia @abellogin
🔗 github.com/sisinflab/warprec
1
1
2
24

Feb 26
An AI-Native Architecture That Eliminates GPU Inefficiencies semiwiki.com/artificial-inte… #AIComputations #CodeCarbon #CogVideoX #Gpgpu #LauroRizzati #MITTechnologyReview #PyTorch #Tensorflow #VSORA
2
5
410

4 Dec 2025
$NVDA $MSFT $CEG $VST The new AI Energy Score data set shows that chain-of-thought “reasoning” models increase per-query energy consumption by orders of magnitude and are emerging as a first-order driver of AI infrastructure demand, unit economics, and power-system risk. Benchmarking by Hugging Face and Salesforce across 40 open models from OpenAI, Google, Microsoft, DeepSeek and others finds that enabling reasoning increases GPU energy use by roughly 100x on average per 1,000 prompts versus the same or similar models with reasoning disabled, with some models showing 500–6,000x deltas. The most extreme example cited is a slimmed-down DeepSeek R1 model: energy use rises from 49.53 Wh to 308,185.51 Wh per 1,000 prompts when reasoning is turned on, implying an increase from approximately 0.05 Wh to approximately 308 Wh per query. The primary driver is not model size but output length: reasoning modes generate 300–800x more tokens through explicit internal “monologue.” The benchmarking uses standardized hardware and CodeCarbon to measure GPU watt-hours, so absolute facility-level energy is understated but the on/off delta for a given model is robust. In contrast, Google’s internal Gemini data put the median production text prompt at 0.24 Wh and claim a 44x reduction in per-prompt energy over 1 year, illustrating the scope for optimization but also highlighting the enormous dispersion across model types and workloads. Critically, the AI Energy Score work finds that newer models are not systematically more energy-efficient on a per-task basis; in matched comparisons, some newer non-reasoning models use only 3% of the energy of prior cohorts while others use up to 4x more, contradicting the assumption that algorithmic progress alone will offset rising usage.
These micro-level findings sit within a macro context of rapidly rising data center power demand and a structural shift of AI energy use toward inference. Data centers consumed roughly 415 TWh of electricity in 2024 (about 1.5% of global demand), a figure the IEA projects will approach 945 TWh by 2030, just under 3% of global consumption and comparable to today’s Japan. In the US, data center consumption is estimated at about 183 TWh in 2024 (>4% of national use) and is projected to reach approximately 426 TWh by 2030, a 133% increase, with AI workloads as the main incremental driver. Available evidence from Meta, Google and independent analyses suggests that 60–90% of ML lifecycle energy is already attributable to inference rather than training, and the rise of reasoning models pushes the mix further toward inference because the incremental energy cost is incurred at query time. In several regions with dense data center buildout, wholesale electricity prices have risen by 200–270% over 5 years, grid operators are facing capacity constraints, and communities are raising concerns about water use and land impacts. This combination makes the energy intensity of deployed AI workloads a central determinant of both system-wide load growth and localized power and environmental stress.
At the level of unit economics, the AI Energy Score results imply that energy, historically a small component of AI inference COGS, can become material for reasoning-heavy workloads. Using the DeepSeek example, with an assumed delivered electricity cost of $0.07–$0.10/kWh and PUE of 1.2, per-query power cost rises from effectively negligible in non-reasoning mode to approximately $0.025–$0.037 in reasoning mode. For high-value enterprise applications this is manageable, but for mass-market products priced at fractions of a cent per 1,000 tokens, such as search augmentation or low-end APIs, energy costs of this magnitude consume a significant share of gross margin once cooling and overhead are fully accounted for. At the same time, many commercial AI offerings are priced with flat per-seat fees and generous usage caps that implicitly assume low average cost per query. If a meaningful subset of users shifts toward very heavy reasoning usage, cost per user can rise nonlinearly while competitive pressure keeps pricing low, compressing margins. This dynamic increases the importance of “energy-aware inference”: routing simple queries to small non-reasoning models and escalating only complex tasks to reasoning LLMs, gating access to expensive modes behind higher-priced tiers or explicit usage limits, and optimizing prompts and outputs to minimize unnecessary token generation.
The investment implications are most immediate for hyperscale cloud and AI platforms, but they cascade across utilities, infrastructure, semiconductors, commodities and device ecosystems. For Microsoft, Alphabet, Amazon and Meta, reasoning-heavy workloads reinforce a sustained high-capex cycle in AI data centers, accelerators, networking and power, increasing capital intensity and pushing parts of the business model closer to a utility profile. These firms are responding by locking in long-duration PPAs, investing directly in renewables and nuclear, and in some cases co-locating generation with data centers. This deepens their moat versus smaller AI vendors that lack the balance sheet to underwrite power infrastructure, but it also raises the risk that regulators and investors begin valuing segments of the cloud franchise on infrastructure-like return and multiple frameworks. Data center REITs and colocation providers benefit from surging AI demand and rising rack power densities toward 240–1,000 kW, with power availability becoming the primary bottleneck and a key source of pricing power for operators with expandable grid connections. Regulated utilities and independent power producers gain from high load-factor, creditworthy hyperscale customers that justify large new generation and transmission projects; some projections suggest that several hundred GW of new capacity may be required by 2035, with AI data centers a major contributor. This supports rate base growth for regulated utilities and strengthens the outlook for gas, renewables and nuclear, especially in regions with abundant fuel and supportive policy. Copper and other grid and data center materials face additional demand: AI data centers are estimated to require roughly 27–33 t of copper per MW, compounding existing deficits driven by electrification and tightening supply. Suppliers of power and cooling equipment such as advanced switchgear, UPS, and liquid cooling systems are levered to the move toward very high-density racks and gigawatt-scale campuses, and may see improving pricing power as legacy infrastructure becomes inadequate.
By contrast, AI software companies and vertical AI vendors that do not control infrastructure are more exposed. These businesses are often valued on SaaS-style multiples but rely on cloud inference services whose COGS embed both chip depreciation and increasingly significant energy costs. As they adopt reasoning models to remain competitive on quality, their per-query cost structure escalates while pricing is constrained by competition from hyperscalers and open-source offerings. Without control over power procurement or data center efficiency, they are price-takers on both compute and energy and are at risk of structurally low or negative gross margins unless they implement sophisticated model routing, workload engineering and contract structures. At a system level, AI’s rising energy demand is creating tension with tech companies’ climate commitments. Critics argue that net-zero pledges at major platforms are becoming less credible as data center emissions rise faster than decarbonization progress, and internal activism plus external NGO pressure are intensifying. Policymakers are starting to respond with calls for standardized energy benchmarking and disclosure. The AI Energy Score project positions itself as an “ENERGY STAR for AI,” providing 1–5 star ratings and a public leaderboard now covering more than 160 models, while the EU AI Act, IEEE and industry groups encourage inclusion of per-inference energy and carbon metrics in procurement. These developments increase the probability of tighter regulation around data center siting, 24/7 carbon-free energy sourcing, and potentially energy- or emissions-based pricing of AI workloads, raising regulatory and ESG risk premia for the most power-intensive AI business models.
Several mitigating factors and uncertainties must be recognized. Rapid improvements in hardware and software efficiency, as illustrated by Google’s reported 44x per-prompt energy reduction for Gemini in 1 year, could significantly lower energy per reasoning query over a 3–5 year horizon. Product design and model routing can constrain the share of workloads that invoke full reasoning, focusing those capabilities on high-value tasks while simpler queries are handled by lightweight models or on-device NPUs. Inference migration to edge devices can offload some demand from centralized data centers and create incremental opportunities for smartphone and PC chip and device OEMs, although heavy reasoning and very large context windows will remain data center–centric. Finally, current measurement of AI energy use is fragmented and methodologically inconsistent; facility boundaries, idle capacity accounting, and inclusion or exclusion of training all vary across sources. As a result, point estimates for AI-related energy and emissions should be treated as directional rather than precise. The central conclusion, however, is robust: widespread adoption of reasoning models materially increases the energy intensity and cost of AI inference, shifts long-run value capture toward infrastructure and energy suppliers, and amplifies regulatory, climate and margin risks for AI platforms and application-layer vendors. Integrating power availability, performance-per-watt, and workload mix into AI investment theses is now a necessary condition for accurate valuation and risk assessment across the TMT, utilities, infrastructure and commodity complex.
2
803

Check out tools and initiatives like:
⚡️ @ElectricityMaps: Access real-time grid carbon intensity via their API.
💻 CodeCarbon: Track and reduce your compute CO2 emissions into any Python project.
🚀 @speedandscale: Learn about global net zero strategies.
1
7
17,211

7 Apr 2025
If you install the 'codecarbon' package and train an embedding or reranker model with Sentence Transformers, your emissions data will automatically be saved in the generated model card.
Example: huggingface.co/sentence-tran…
1
1
10
472

8 Mar 2025
5/ Sasha Luccioni: Dr. Sasha Luccioni, originally from Ukraine, moved to Canada at four. She studied Language Science, Cognitive Science, and Computing, working at Nuance Communications and Morgan Stanley. In 2019, she joined Université de Montréal and Mila for climate visualization with Yoshua Bengio.
In 2021, she became a research scientist at Hugging Face, focusing on AI's carbon footprint with tools like CodeCarbon, and highlighting LLMs' CO2 emissions. Dr. Luccioni co-founded Climate Change AI, serves on the Women in Machine Learning board, mentors minorities, and was named a top AI influencer by TIME and Business Insider.

1
4
119

26 Feb 2025
Big Tech tracks everything—except AI’s real energy burn. CodeCarbon changes that. Open-source, no fluff—track your model’s power use down to the milliwatt. No more guessing. Just real data.
#AI #EnergyConsumption #CodeCarbon #OpenSource #VancouverAI
1
227

20 Jan 2025
Prompt engineering with custom tags cuts LLM energy use by up to 99% in code completion tasks.
-----
Original Problem 🤔:
Training and using LLMs for code-related tasks consumes massive computational resources and energy, contributing significantly to carbon emissions. Measuring and reducing this environmental impact is challenging due to complex infrastructure requirements and lack of standardized evaluation methods.
-----
Solution in this Paper 🛠️:
→ The researchers introduced custom tags in prompts to distinguish different components like input code and completion targets
→ They tested five distinct prompt configurations with varying levels of tag usage and explanations
→ The study evaluated three prompting techniques: zero-shot, one-shot, and few-shots
→ They used CodeXGLUE dataset with 1,000 Java code snippets for comprehensive testing
→ Energy consumption was measured using CodeCarbon tool on an isolated testing environment
-----
Key Insights 💡:
→ Custom tags in prompts can significantly reduce energy consumption without compromising accuracy
→ System role specifications in prompts impact both energy usage and model performance
→ Few-shots prompting with custom tags shows the best balance of efficiency and accuracy
-----
Results 📊:
→ Zero-shot prompting achieved 7% energy reduction
→ One-shot prompting showed 99% decrease in energy consumption
→ Few-shots configuration reduced energy usage by 83%
→ Maintained or improved accuracy metrics across all configurations

6
11
44
3,527

15 Dec 2024
Energy scores for ML models also help make the right trade off between performance and cost.
You can compute yours with the CodeCarbon Python library -> codecarbon.io
(From the same @ClimateChangeAI workshop 5 years ago!)

3
136

5 Oct 2024
📌 El efecto de la inteligencia artificial (IA): Huella de carbono
3pmnoticias.com/tecnologia/l…
🔺 Aquí, en 3⃣🇵 🇲 🇳 🇴 🇹 🇮 🇨 🇮 🇦 🇸 🔺
By: @GermnNonell2
#IA #HuellaDeCarbono #ambiente #inteligenciaartificial #crisisambiental #crisisclimatica #codecarbon #sashaluccioni
2
3
25

26 Sep 2024
Today I do a talk with Luis at @PyDataParis about CodeCarbon and then do a Lightning talk on main stage. A well spent afternoon!
Amazing community 🤗

13 Sep 2024

"Track your code's CO2 emissions with Code Carbon", by Luis Blanche and Benoît Courty (@BenoitCourty).
📜 Abstract pretalx.com/pydata-paris-202…
📅 Schedule pydata.org/paris2024/schedul…
🎟 Tickets pydata.org/paris2024/tickets

ALT "Track your code's CO2 emissions with Code Carbon" Luis Blanche Benoît Courty Cité des Sciences September 25-26
2
4
9
396

5 Open-source and green projects to donate via Kivach.org
♻️CodeCarbon
♻️Mycodo
♻️Tracarbon
♻️Open Green Map
♻️Waste Management System
Check everything about them and choose your fav to donate to👇🏼👇🏼
hackernoon.com/5-open-source…
#DeFi #Crypto
2
2
5
208
2 Sep 2024
Carbon emissions are automatically included with Sentence Transformer training if you install codecarbon: pip install codecarbon
E.g. see huggingface.co/tomaarsen/xlm…

2 Sep 2024

New feature on the Hub!
☁️ Carbon emissions emitted during training now show up on the model card!
(requires model authors to fill that info first)
Hopes it will prompt more people to show the carbon emissions of their model training! 🌍
Thanks a lot to the team who pushed this! @julien_c @SashaMTL

6
25
1,876