
Maybe the data-efficiency gap is not a scaling problem.
Maybe it is an objective problem.
A striking preprint by Daniel J. Korchinski, Alessandro Favero, and Matthieu Wyart offers a sample-complexity theory for this shift:
Learn from your own latents and not from tokens.
The core problem is familiar:
modern generative models are extraordinary, but brutally data-hungry.
LLMs train on 10¹³–10¹⁴ tokens.
Children do not.
So the question is not only:
How do we scale models?
It is:
What are we asking them to predict?
Most of modern AI trains on the visible surface: next tokens, masked tokens, pixels, noise.
That works.
But it may be statistically inefficient for learning hierarchy.
The authors study a tractable hierarchical grammar where visible tokens are generated from a hidden latent tree of depth L — a stylized model for the compositional structure of language and images.
The result reframes the debate:
token-level learning requires samples exponential in L to recover the hidden tree.
latent prediction recovers it with sample complexity essentially constant in L, up to logarithmic factors.
In plain English:
predicting tokens forces the model to infer the hierarchy through the leaves.
predicting latents lets the model climb the tree.
Once one abstraction level is learned, it becomes the substrate for learning the next.
This is why data2vec and JEPA-style objectives are so interesting.
They do not merely reconstruct the input.
They train a network to predict its own latent representation of another view or masked region.
The target is no longer the surface.
The target is the model’s own emerging abstraction.
The paper validates the theory three ways:
a hierarchical clustering algorithm
an end-to-end neural architecture trained by gradient descent
a sample-complexity analysis of data2vec, showing it implicitly performs hierarchical latent prediction
One implication is provocative:
if data2vec already discovers hierarchy implicitly, explicit stacking schemes such as H-JEPA may be partly redundant.
This is not “next-token prediction is dead.”
Next-token prediction built the current era.
But if the goal is biological-level data efficiency, surface reconstruction may be the expensive path.
The strategic frontier may be latent self-prediction:
models learning not only from what they see,
but from the abstractions they are forming.
Full credit to the authors:
Daniel J. Korchinski, Alessandro Favero, Matthieu Wyart.
Paper:
Learn from your own latents and not from tokens: A sample-complexity theory
arxiv.org/abs/2605.27734
I’m attaching the first page because the abstract is worth reading closely.
The future of data-efficient AI may not be more tokens.
It may be better targets.
#AIResearch #MachineLearning #SelfSupervisedLearning #RepresentationLearning #DataEfficiency #LLM

3
1
10
1,032

May 31
The data-efficiency gap between machines and children may not be solved by “more tokens.”
It may be solved by changing what the model is asked to predict.
A beautiful new paper by Daniel J. Korchinski, Alessandro Favero, and Matthieu Wyart gives a sample-complexity theory for a major alternative to token-level learning:
Learn from your own latents and not from tokens.
The premise is striking.
Modern generative models learn by predicting raw surface fragments:
next tokens
masked tokens
pixels
noise
patches
This works spectacularly.
But it is brutally data-hungry.
Biological learners do not see 10¹³–10¹⁴ tokens before acquiring rich language competence. So perhaps the bottleneck is not only architecture, scale, or optimization.
Perhaps it is the prediction target.
Instead of predicting tokens, methods like data2vec and JEPA train networks to predict their own latent representations of related views or masked regions.
The model is not asked:
“Can you reconstruct the surface?”
It is asked:
“Can you predict the abstraction your own system would form?”
That difference may be enormous.
The authors study a tractable hierarchical grammar that generates visible tokens from hidden latent trees of depth L — a stylized model of the compositional structure of language and images.
For this data, supervised learning and token-level self-supervised learning require samples exponential in L to recover the hidden hierarchy.
But latent prediction recovers the hierarchy with sample complexity essentially constant in L, up to logarithmic factors.
That is the whole paper in one line:
predicting tokens makes hierarchy expensive;
predicting latents makes hierarchy recursive.
Why?
Because token-level objectives keep forcing supervision through the visible surface. The deeper the hidden structure, the weaker and more indirect the signal becomes.
Latent prediction removes that bottleneck.
Once one level of abstraction is recovered, the model can use its own learned latents as both context and target for the next level. Every level becomes statistically like the first.
The paper confirms this three ways:
a hierarchical clustering algorithm
an end-to-end neural architecture trained by gradient descent
a sample-complexity analysis of data2vec, showing that it implicitly performs hierarchical latent prediction
The last point is especially interesting.
If data2vec already discovers hierarchy implicitly, then explicitly stacking methods like H-JEPA may be partly redundant.
This is not “tokens are dead.”
Token prediction remains one of the most productive ideas in AI.
But this paper gives a precise reason why token-level learning may be an inefficient path to latent structure.
The deeper lesson:
the model should not only learn from the world’s surface.
It should learn from the abstractions it is already beginning to form.
Full credit to the authors:
Daniel J. Korchinski, Alessandro Favero, Matthieu Wyart.
Paper:
Learn from your own latents and not from tokens: A sample-complexity theory
arxiv.org/abs/2605.27734
I’m attaching the first page because the abstract is worth reading closely.
The future of data-efficient AI may not be more reconstruction.
It may be recursive self-prediction in latent space.
#AIResearch #MachineLearning #SelfSupervisedLearning #RepresentationLearning #LLM #DataEfficiency

1
3
6
353

May 15
Data is growing faster than networks can keep up. Atombeam is helping change that!
Today, Techinfluencer Evan Kirstel sits down with Atombeam’s CPO, Julien Dersy, to discuss how Atombeam is improving data efficiency for today’s connected world.
They’ll dive into how Neurpac reduces data transmission by up to 75%, increases effective bandwidth by 4X, and helps move more machine-generated data in real time — without costly hardware upgrades.
They’ll also explore why this matters across various industries.
Tune in to see the livestream today at 12 PM EST on YouTube:
youtube.com/@Kirstel
#Atombeam #Neurpac #DataEfficiency #IoT #EdgeComputing #MachineData #Bandwidth #Innovation

4
1
294

Apr 18
GPT-4 trilyonlarca parametreyi 'kaba kuvvet' (brute force) ile sıkarak bilgiyi depoluyor. İnsan beyni ise veriyi sıkıştırmaz; onu 'deneyim' filtrelerinden geçirerek bilgeliğe dönüştürür. Biz az veriyle çok şey anlarız çünkü donanımımız (nöronlar) deneyimle şekillenir. AI'ın bu 'sezgisel verimliliğe' ulaşması için kuantum qubit'lerinin süperpozisyon durumlarını, beynin 'eşzamanlı çoklu olasılıkları değerlendirme' yeteneğiyle birleştirmesi gerekecek. 🧠
Eskiden olsa karamsar yaklaşırdım ama bugün karamsar olamam. Çünkü mevcut bilimsel bilgi kendini üstel (exponential) hızda ikiye katlıyor. Bazı kaynaklar için bu süre 12 saat bazıları içinse 12 gün. Her ikiside eşit derecede güzel ve korkunç...
#AI #DeepLearning #Neuroscience #Intuition #DataEfficiency #QuantumComputing
2
3
131
3,931

Mar 31
Performance degradation in blockchain systems is often caused by excessive data processing
Storing full transaction data increases computational load and slows validation as usage grows
This becomes a key constraint in high-frequency environments
@tectumsocial reduces this pressure by recording cryptographic hash signatures instead of full data, allowing transactions to remain verifiable with less processing overhead
This improves system efficiency and supports higher throughput
#TET #Scalability #DataEfficiency #BlockchainArchitecture #Infrastructure

3
4
952

Digital systems generate waste too. It shows up in scattered files, duplicated work, and tools that don’t fully integrate, creating quiet, persistent inefficiencies.
As the world marks Zero Waste Day, it’s worth paying attention to the digital side of waste as well.
At KadMap, we believe better systems reduce digital waste and bring clarity to how work gets done.
#ZeroWasteDay #DigitalSustainability #ResponsibleTechnology #DataEfficiency #DigitalInfrastructure #KadMap

3
3
18
Mar 30
A major limitation in blockchain systems is how transaction data is handled
Storing full data on chain increases processing load and slows the system as activity grows
This creates scalability constraints in high-volume environments
#Tectum solves this by recording cryptographic hash signatures instead of full transaction data, reducing data load while maintaining verification
This enables the system to scale without performance degradation
#TCT #BlockchainArchitecture #Scalability #DataEfficiency #Infrastructure

3
1
4
1,099

Genomics mapping hits record precision: Bioptymus achieves 95% accuracy in its latest AI-driven sequence. Data processing costs reduced by 30%.This expansion is a key pillar of the strategy Nicole Junkermann supports
#GenomicsAI #HealthResearch #DataEfficiency #NicoleJunkermann

15
Mar 28
One way to evaluate blockchain systems is to look at how they handle data
Storing full transaction data increases system load and limits scalability
Tectum records cryptographic hash signatures instead of full data, reducing network pressure while maintaining verification
This is an example of solving performance challenges at the architectural level
#TCT #DataEfficiency #BlockchainArchitecture #Scalability #Technology

3
3
1,086

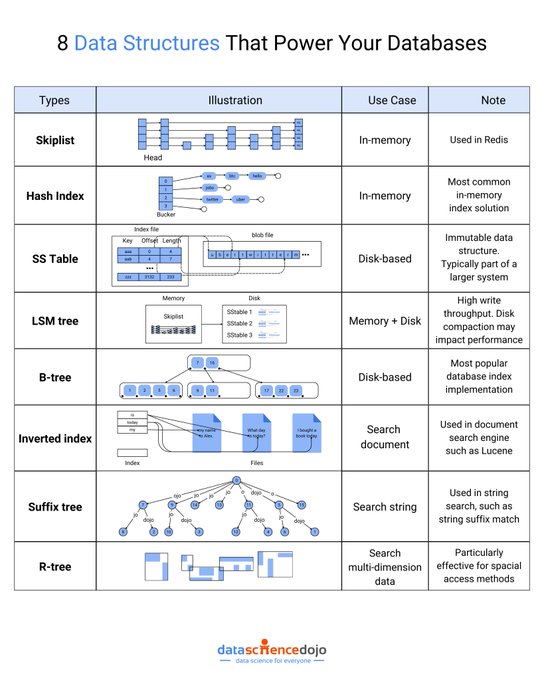
#Infographic: 8 data structures that powers your database!
Via @DataScienceDojo
#TechArchitecture #DatabaseDesign #DataScience #CSConcepts #BackendDevelopment #TechInspiration #DataEfficiency
cc: @kalydeoo @Ym78200 @Nicochan33
3
7
99

Mar 16
Review request:
As usual for the time of year, I'll be looking for #IROS2026 reviewers. Highly interesting stack of papers on #ReinforcementLearning #Sim2Real #RewardLearning #LLMs #DataEfficiency #RoboticManipulation
Reach out with your ID or papercept registered mail address and background. Looking forward to working together!

7
6
54
9,751

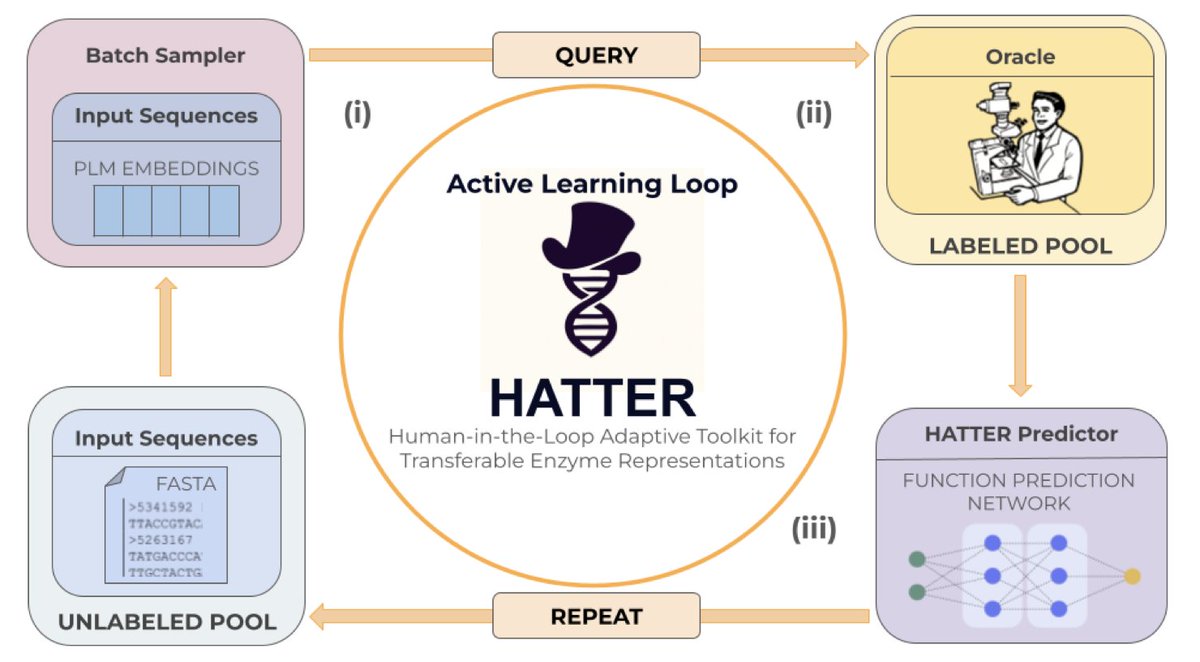
An Active Learning Framework for Data-Efficient, Human-in-the-Loop Enzyme Function Prediction
1. Introducing HATTER: a first-ever human-in-the-loop active learning framework specifically designed for enzyme function prediction, enabling biologists to iteratively annotate and update models alongside experimental workflows.
2. The framework achieves statistically comparable performance to standard supervised training while processing up to 48% less data and requiring fewer model updates, directly addressing the bottleneck between exponentially growing protein sequences and slow experimental validation.
3. Surprisingly simple point-based uncertainty methods like entropy and margin sampling outperform complex Bayesian approaches, highlighting that sequence diversity matters more than sophisticated acquisition functions for this biological task.
4. HATTER's modular design supports multiple architectures including CLEAN and custom neural networks, with four operational modes: training, initialization, update, and simulation for pre-experimental planning.
5. The system is explicitly built for real experimental constraints: adjustable batch sizes as small as 1, annotated query exports, and efficient model weight storage to avoid retraining between rounds.
6. Key insight for practitioners: random sampling performs surprisingly well, suggesting that capturing input diversity may be more important than optimizing uncertainty metrics when dealing with highly diverse biological sequences.
7. This work establishes a foundation for adaptive AI systems in biology that evolve with new data and expert input, moving beyond static benchmarks toward collaborative, iterative discovery platforms.
💻Code: github.com/ahoarfrost/HATTER
📜Paper: arxiv.org/abs/2602.23269
#ActiveLearning #EnzymeDiscovery #ProteinFunction #Bioinformatics #MachineLearning #ComputationalBiology #HumanInTheLoop #DataEfficiency
1
1
23
1,718

Jan 29
Apex: The Infrastructure Upgrade Lab for Decentralized AI We're diving deep into SN1 Apex, explaining why it's fundamentally different from other AI subnets. While most subnets build direct AI products like search or translation, Apex is the upgrade lab—running competitions to discover better algorithms that make decentralized AI faster, cheaper, and more efficient. We break down how Apex improves performance through infrastructure optimization rather than end-user products, using the analogy of building better tires and fuel injection for a race car instead of the engine itself. We also explore Apex's current focus on matrix compression, a critical bottleneck that reduces the massive data transfers needed during AI training, ultimately enabling more scalable decentralized training across multiple machines. #Apex #DecentralizedAI #SN1 #MatrixCompression #AIInfrastructure #AlgorithmOptimization #AITraining #BlockchainAI #DataEfficiency #MachineLearning #TechInnovation #DistributedComputing #tao #bittensor $tao @WSquires @macrocrux @const_reborn
1
11
1,337

Jan 8
🌐 As @Grok faces heavy usage growth, our decentralized architecture at Datos ensures:
✅ Distributed load balancing across multiple nodes
✅ Dynamic scalability to accommodate rising demand
✅ Enhanced redundancy and reliability for optimal performance
✅ Real-time AI optimization for efficient request routing
Join us Elon, in revolutionizing data management! #Decentralization #Blockchain #DataEfficiency @elonmusk

Heavy usage growth of @Grok is causing occasional slowdowns in responses.
Additional computers are being brought online as I type this.
1
2
8
946

Jan 1
✨ Happy New Year from Rinnoco! 🦏
Here’s to 2026 — a year of smarter data, efficient storage, and meaningful innovation.
Thank you to everyone building this journey with us. 🚀
#HappyNewYear #Rinnoco #DataEfficiency #Innovation #2026

2
16

15 Nov 2025
Store risk factors in normalized formats—avoid redundant recalculations. #DataEfficiency @IIBA @IIBAToronto @credly
#MDMarketInsights #BusinessAnalysis #CapitalMarkets #FinancialServices #TradeFloor #FinanceIndustry #InvestmentAnalysis #DataAnalytics #RiskManagement #TradingStrategies #MarketResearch #FinancialData #InvestmentManagement #AssetManagement #Fintech #RegulatoryCompliance #PortfolioManagement #Derivatives #MarketAnalysis #FinancialTechnology #TradingTools #QuantitativeAnalysis #InvestmentStrategy #BusinessIntelligence #FinancialInnovation #EconomicAnalysis #TradingSystems #DataScience #HedgeFunds #PrivateEquity #RiskAnalysis




1
2
24

5 Nov 2025
📢 When optimizing LLM systems, most teams focus on prompt engineering or model compression but overlook a major hidden cost: data formatting.
Every JSON key, bracket, and redundant character adds to your token count and tokens are money.
TOON (Token-Oriented Object Notation) takes a different approach.
Instead of representing data in verbose, human-oriented syntax like JSON, TOON encodes it in a compact, model-friendly structure that dramatically reduces the number of tokens an LLM has to process.
Think of it as a compressed representation of structured data — same meaning, fewer tokens.
Less textual noise means lower prompt sizes, faster responses, and significantly reduced inference costs.
In short, TOON rethinks the data layer, not the model, to make large-scale AI deployments leaner and more sustainable.
🔗 Check it out here: hubs.la/Q03RRK7Q0
🧠 Efficiency isn’t just about smarter models — sometimes, it’s about smarter data.
#LLM #TOON #AIOptimization #TokenUsage #DataEfficiency #LLMScaling #ModelOptimization #OpenSource #AIEngineering #AIInfra #PromptDesign #AIDevelopment #AICostSavings

1
2
2
1,286

29 Oct 2025
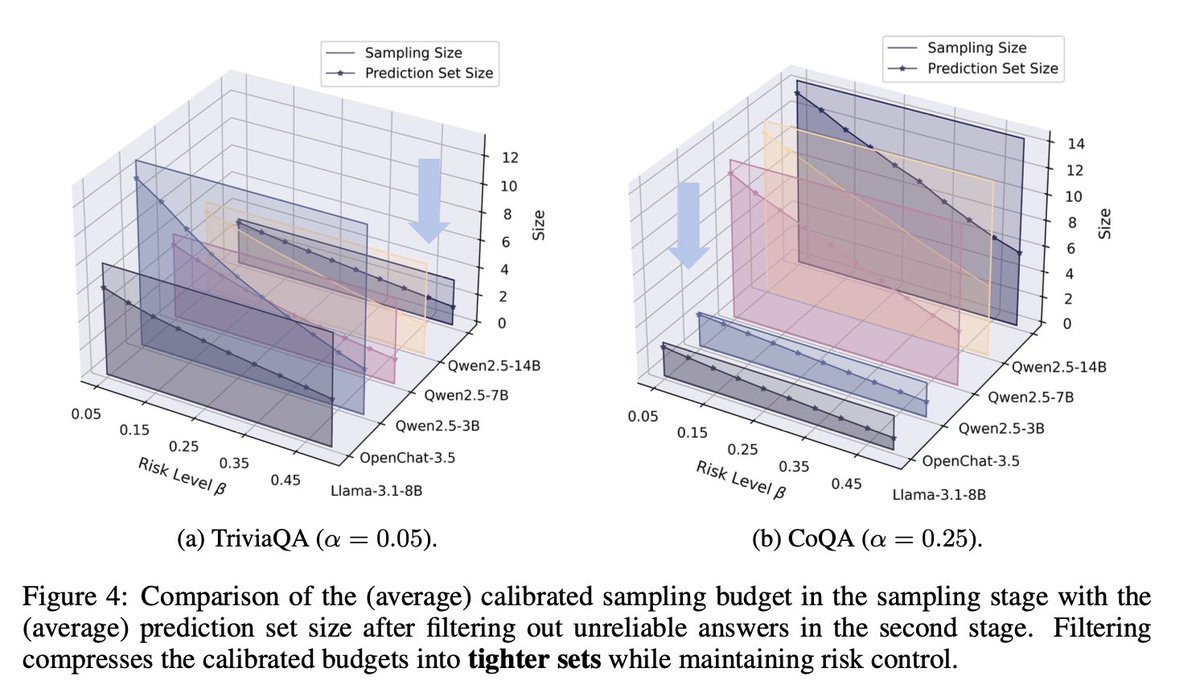
📏 Calibration & Prediction Set Size:
SAFER achieves leaner prediction sets without violating risk constraints — turning wide uncertainty budgets into compact, high-confidence answer pools.
This means more data efficiency and fewer redundant samples.
#DataEfficiency #AI #Uncertainty 🧵4/5
1
4
95

23 Oct 2025
🔥 We’re releasing SPEAR-1 (spear.insait.ai) - a new robotic AI foundation model that achieves state-of-the-art performance with 20× less robotic data
🧠 Why it matters:SPEAR-1 is like the ChatGPT for robots - a single model that can perform many tasks, on any robot, in any environment.
💡 What’s new: unlike others, SPEAR-1 learns from both robotic and non-robotic 3D data, breaking the data bottleneck that slows robotic AI.
🤖 Open-weight, general-purpose, and multilingual for robots - a major step toward scalable robot learning.
#Robotics #FoundationModels #3DPerception #Manipulation #INSAIT #Europe #DataEfficiency

2
5
27
17,485

11 Oct 2025
Day 13. @bitdealernet is back at it, moving from meme hype to hard utility.
This isn’t just another launchpad, it’s a space where tokens grow real value. Every $BIT-backed token starts with a slot game, revenue flows straight into liquidity. Simple. Deflationary. And the house? Never sleeps.
Play -> Fees -> Volume -> Stronger $BIT hub. It’s a cycle that builds real depth.
Real games. Real liquidity. Real DeFi. Stay tuned, the next token is on its way
#bitdealer
@wallchain_xyz keeps building. Consistency > everything.
No weekends off. Just a relentless drive to make data work better.
Don’t sleep on @idOS_network, Quacks are the real deal.
Catch the energy, lock it in. #DataEfficiency #Wallchain
@RaylsLabs doesn't chase trends, they build the future.
Scaling DeFi and TradFi in one smooth system. Privacy, compliance, and security wrapped in a blueprint that just works.
You watching? The future is moving. Don’t blink.

11
17
123