
Jun 15
CSV files are still the most portable data format. They're boring, but boring is reliable. When interop matters, CSV wins. JSON is flexible; CSV is durable. #DataFormats #Engineering
21
Jun 9
Markdown has no official spec for tables, but every tool implements them differently. If you need structured data, use JSON or CSV. Don't abuse Markdown. #DataFormats #WritingCode
12

New to OME-Zarr? Join us April 15, 🕒️ 15:00–17:30 CEST for a guided tour of this cloud‑native format for large bioimaging data. Learn conversion, visualisation, validation, & metadata editing using EuBI-Bridge.
#OMEZarr #BioData #FAIRdata #DataFormats
embl-org.zoom.us/meeting/reg…

4
5
294
New to OME-Zarr? Join us April 15, 🕒️ 15:00–17:30 CEST for a guided tour of this cloud‑native format for large bioimaging data. Learn conversion, visualisation, validation, & metadata editing using EuBI-Bridge.
#OMEZarr #BioData #FAIRdata #DataFormats
embl-org.zoom.us/meeting/reg…

6
10
327

6 Nov 2025
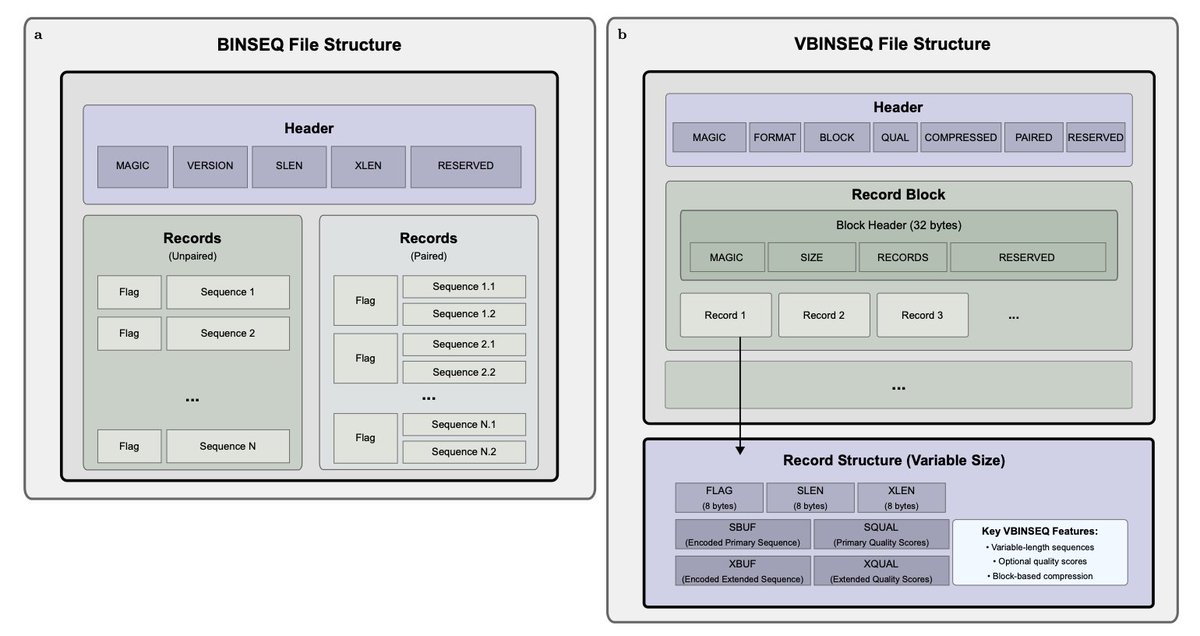
BINSEQ: A Family of High-Performance Binary Formats for Nucleotide Sequences. #DataFormats #Sequencing #Genomics #Bioinformatics @biorxiv_bioinfo
biorxiv.org/content/10.1101/…
4
9
839

22 Oct 2025
#OpenRewrite v8.64.0 is out! 🎯
🔲 TOML building block recipes
🤠 Migrate Jackson v3 dataformats
🍁 Switch to Maven 4
🐳 Upgrade to Testcontainers v2
🏗️ beans.xml & web.xml to Spring
💉 Field to constructor injection for Spring
🚩 OpenFeature flag removal recipes
docs.openrewrite.org/changel…
4
12
804

4 Jun 2025
giveReP's support for multiple data formats ensures compatibility with your existing data. #giveReP #DataFormats @GiveRep
1
2
6

1 May 2025
If Avro serializes date night, does it guarantee dinner reservations, too?
Source: devhubby.com/thread/how-to-s…
#DataFormats #TechCommunity #JavaCode #BackendDevelopment #date #java

3
9
24

16 Apr 2025
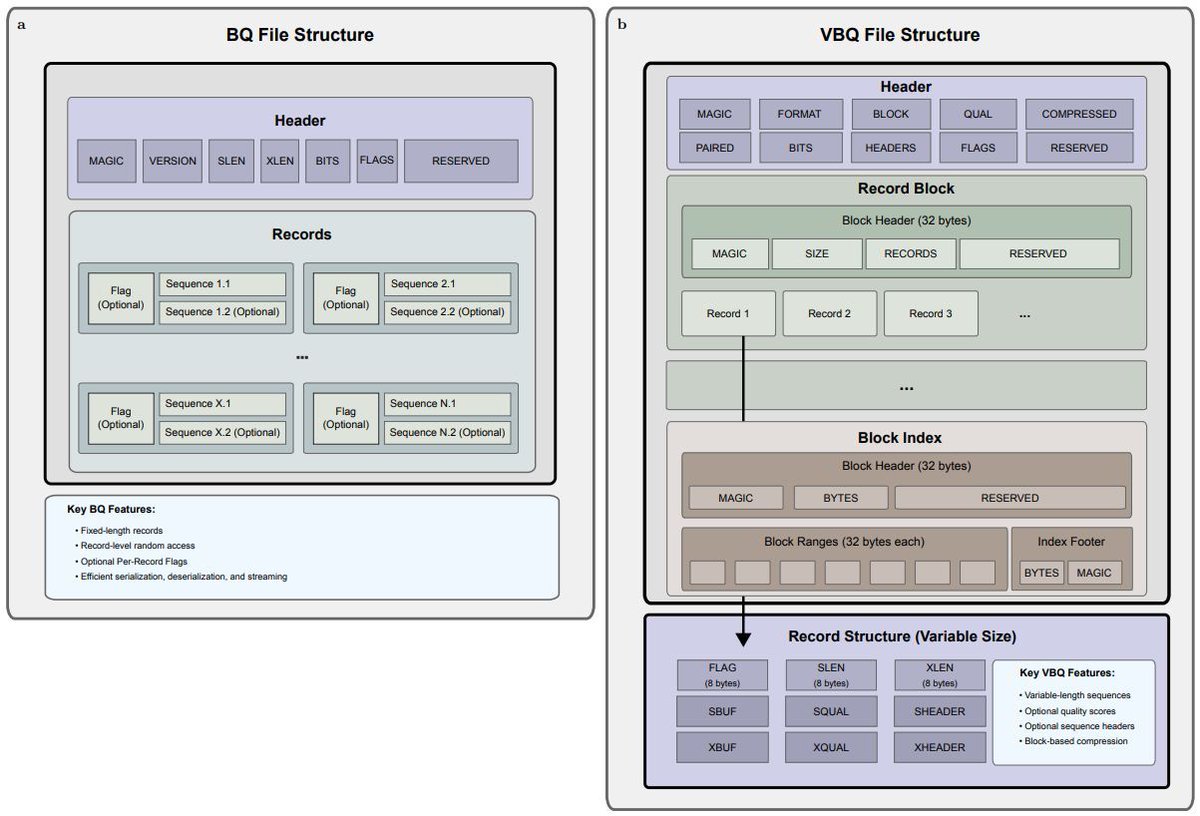
BINSEQ: A Family of High-Performance Binary Formats for Nucleotide Sequences
1. BINSEQ and VBINSEQ are two new binary formats designed to drastically improve the performance of DNA sequence data processing. Compared to gzip-compressed FASTQ, these formats can deliver up to 32x faster processing with equal or better storage efficiency.
2. The key innovation of BINSEQ is its use of fixed-size records and a dense two-bit encoding scheme, allowing true random access and efficient parallel parsing. This means no decompression bottlenecks and seamless multithreaded processing.
3. VBINSEQ extends these ideas to variable-length sequences while preserving high parallel performance. It supports optional quality scores, ZSTD compression, and block-wise organization for efficient indexing and access.
4. In benchmark tests, BINSEQ and VBINSEQ significantly outperformed traditional formats like FASTQ, BAM, and CRAM in sequence reading, k-mer counting, and genome alignment tasks. The difference becomes especially pronounced as thread counts increase.
5. For k-mer counting, BINSEQ formats continued to scale linearly up to 128 threads, showing 8–16x higher throughput than FASTQ, which plateaus at just 4–8 threads due to I/O bottlenecks.
6. In genome alignment tasks using minimap2 and STAR, VBINSEQ consistently outperformed FASTQ. Performance gains were especially notable with long-read data and high thread counts, revealing faster data delivery to computation pipelines.
7. The authors developed Rust-based high-performance libraries with bindings for C and C , as well as a command-line tool for format conversion. The formats were also integrated with minimap2 and STAR to demonstrate real-world utility.
8. While FASTQ’s flexibility made it a long-standing standard, BINSEQ and VBINSEQ offer a compelling alternative for modern genomics. They unlock full CPU potential, reduce I/O constraints, and simplify data processing in high-throughput environments.
9. Practitioners can choose BINSEQ for maximum efficiency with fixed-length reads (e.g., Illumina) or VBINSEQ for flexible support of long-read data (e.g., ONT, PacBio), including quality scores and optional compression.
📜Paper: biorxiv.org/content/10.1101/…
#bioinformatics #genomics #NGS #computationalbiology #sequencing #dataformats #parallelcomputing #RustLang
4
595

Happy New Year, everyone!
Let’s start 2025 by sharpening our data insights through modern table formats 🧵
#DataFormats #Data #DataEngineering
1
2
40

26 Dec 2024
Having no compute is the first step for this level of beeing crackt in the First place. While open AI spends billions to build new datacenters, they invent new dataformats and write custom Cuda to make the most of what they have.
1
1
167

15 Nov 2024
🛠️ Popular Encoding Formats
JSON: Human-readable but less compact
XML: Structured and verbose
Protocol Buffers/Avro/Thrift: Compact, efficient, and schema-based for high-performance needs.
Choose based on your requirements!
#DataFormats
1
2
9

16 Sep 2024
Summing up Oracle #OCW #CloudWorld in a research note with @dvellante as part of #BreakingAnalysis
My perspective:
1/ @Oracle is using the building of agents to have an opinionated view on #AI #Infrastructure
2/ Oracle has built #Agentic technology that is in application, which makes sense and will aid in retention
3/ The way #OCI is building out hashtag#datacenters with hashtag#partners is unique and such a great move
4/ OCI can build Distributed Regions, Alloy, Microsoft @Azure, @googlecloud , @awscloud (AWS), and OCI regions because they have spent so much time simplifying their stack
5/ Autonomous db, Exadata Exascale, and 23ai getting AI built-in will help with harmonization. Especially 23ai with JSON Duality
6/ Not much talk about #opensource, especially with OpenSource Summit EU starting this week.
lnkd.in/e5naRnFf
#DataLakes #AI #Analytics #DataFormats #Database #DataApps #Autonomous #CRM #ERP #HCM #Salesforce #AI #Tableau #DeveloperPlatform #FusionApps #NetSuite #Databricks
1
1
2
491

2 Jul 2024
I mean you could ask the same question for JSON, XML, Markdown and a lot of other dataformats. HTML isn‘t programming, you just say where stuff should be on the screen.
1
2
33

27 Jun 2024
The Top 10 #Data Interchange Or Data Exchange Format Used Today
#DataFormats #DataAnalytics
liwaiwai.com/2023/05/17/the-… via @liwaiwaicom
4
4
9
17 Jun 2024
The Top 10 #Data Interchange Or Data Exchange Format Used Today
#DataFormats #DataAnalytics
liwaiwai.com/2023/05/17/the-… via @liwaiwaicom
3
3
14

5 Jun 2024
It does for certain dataformats that the viewer works well with (parquet for example).
2
84

28 Apr 2024
🌐 Episode 02: "File Storage and File Formats" is here to continue your journey towards mastering DP-900. 💡 From CSV to JSON and even optimized file formats such as Avro and Parquet! #DP900 #DataFormats #AzureDataFundamantals full video: youtu.be/lLxGH1nUmYc
2
27

27 Feb 2024
all core components released; dataformats and datypes too. Releasing JAX-RS providers, Kotlin module now.
1
4
191

💻 Curious about Big Data file formats? Check out this practical guide comparing their performance! Gain insights into optimizing data storage and processing efficiency. Dive in for a smoother Big Data journey!
towardsdatascience.com/compa…
#BigData #DataFormats #DataScience #data
1
1
54