
All media is now designed to be optimal for encoding. Scrub out the noise. reduce contrast. Etc.
318
No they aren’t Matt. They are just encoding to save bandwidth and meet accessibility tests
1
30


🔍 Ao codificar variáveis ordinais, considere a preservação da ordem intrínseca usando técnicas como a codificação de rótulos ou a codificação de efeitos.
Para variáveis nominais, a one-hot encoding é eficaz, mas atenção ao "curse of dimensionality".

Today is 6/14: Trump’s birthday.
In exactly 14 days it will be 6/28:
Elon’s 55th birthday.
14 > 14
The gap itself is the signal⤵️
Let's break it down
and find the path...
🧬DNA encoding:
D4 N14 A1 = 4141
That’s the mirror of 1414 —
Trump on the 14th, 14 days, Elon on the 28th.
A literal 14-day DNA sequence encoded in the calendar between them.
Trump once said: “I have good jeans…genes…DNA.”
The birthdays line up like the punchline was planned.
Extra timeline locks in this story:
6/14 in the Gregorian calendar = 10/7 in the Ethiopian calendar > 107.
Today is also the U.S. Army’s birthday.
Military = 107.
🥳Elon’s 42nd birthday party: full Japanese steampunk theme with sumo wrestlers.
🥳Trump’s 80th: UFC fight night energy.
Two birthdays. Fourteen days. One mirrored 4141 sequence.
The timeline doesn’t just rhyme. It’s like it's spelling something out. Can you read it with me?
(Scoreboard attached for the perfect 4-1/1-4 capstone.) 🔥

2
7
28
458

The shift from owning assets to encoding behavior is the real evolution of identity.
11

The Information Bottleneck (IB) principle offers a profound lens for understanding why deep networks generalize despite overparameterization. Introduced by Tishby et al. (2015), IB frames learning as an optimal compression problem: a network layer should retain only information in input X that is predictive of label Y.
Formally, IB minimizes:
L = I(X; T) - β·I(T; Y)
where I(·;·) denotes mutual information, T is the learned representation, and β controls the compression-prediction tradeoff. The optimal solution satisfies:
p(t|x) ∝ p(t)·exp(-β·D_KL[p(y|x) || p(y|t)])
During SGD training, neural networks exhibit two distinct phases:
1. 𝐅𝐢𝐭𝐭𝐢𝐧𝐠 𝐩𝐡𝐚𝐬𝐞: I(X;T) and I(T;Y) both increase rapidly as the network memorizes patterns
2. 𝐂𝐨𝐦𝐩𝐫𝐞𝐬𝐬𝐢𝐨𝐧 𝐩𝐡𝐚𝐬𝐞: I(X;T) decreases while I(T;Y) remains stable-the network forgets irrelevant input details while preserving task-relevant signals
The critical insight: 𝐠𝐨𝐨𝐝 𝐠𝐞𝐧𝐞𝐫𝐚𝐥𝐢𝐳𝐚𝐭𝐢𝐨𝐧 𝐜𝐨𝐫𝐫𝐞𝐥𝐚𝐭𝐞𝐬 𝐰𝐢𝐭𝐡 𝐜𝐨𝐦𝐩𝐫𝐞𝐬𝐬𝐢𝐨𝐧. Layers progressively discard nuisance information (noise, spurious correlations) irrelevant to Y. Empirically, the penultimate layer's I(X;T) correlates strongly with test accuracy.
For a k-class problem, the representation T at the final hidden layer satisfies I(T;Y) ≤ H(Y) ≤ log k bits, bounding retained label information. Stochastic gradient noise implicitly implements a form of variational optimization over this constrained objective.
Recent work (Saxe et al., 2018) nuances this: without nonlinearities or specific activation symmetries, networks don't always compress. However, with ReLU-like activations and finite precision, compression emerges naturally as an implicit regularizer.
This explains a paradox: massive networks (millions of parameters) generalize well because they learn 𝐦𝐢𝐧𝐢𝐦𝐚𝐥 𝐬𝐮𝐟𝐟𝐢𝐜𝐢𝐞𝐧𝐭 𝐫𝐞𝐩𝐫𝐞𝐬𝐞𝐧𝐭𝐚𝐭𝐢𝐨𝐧𝐬-encoding exactly what Y requires and nothing more, effectively solving an information-theoretic optimization that classical statistical learning theory struggles to characterize.
#InformationBottleneck #DeepLearningTheory #Generalization

4
AssistedEvolution retweeted

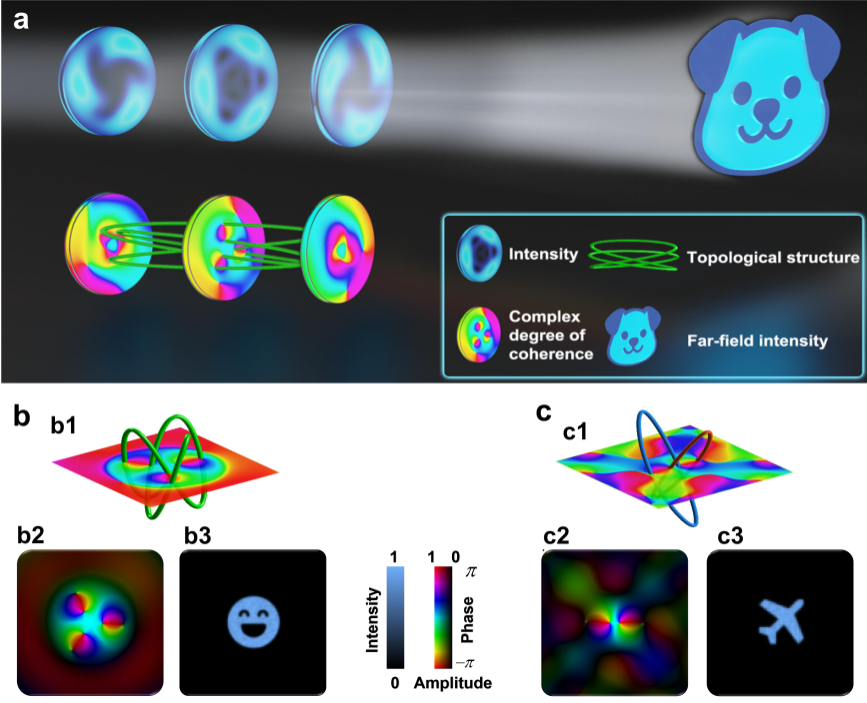
[PDF] General framework for incoherent topological structured light and optical information encoding🛸
2
3
40
1,116

#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
================================================================
MULTI-IA — Poser une question à plusieurs IA et regrouper
leurs réponses dans un seul fichier.
================================================================
CE QUE FAIT CE SCRIPT
---------------------
1. Vous tapez (ou collez) votre question.
2. Le script l'envoie à chaque IA pour laquelle vous avez mis une clé.
3. Il enregistre toutes les réponses dans un fichier reponses.txt
que vous pourrez ensuite donner à Claude pour qu'il en fasse
la synthèse.
CE QU'IL VOUS FAUT (une seule fois)
-----------------------------------
- Python 3 installé sur votre ordinateur.
- La bibliothèque "requests" : ouvrez un terminal et tapez
pip install requests
- Une ou plusieurs CLÉS API (voir le fichier cles.txt ci-dessous).
Vous n'êtes pas obligée d'avoir toutes les clés : le script
interroge seulement les IA dont la clé est renseignée.
SÉCURITÉ
--------
- Vos clés ne sont JAMAIS dans ce script : elles sont dans un
fichier séparé cles.txt que vous gardez sur votre ordinateur.
- Ne partagez jamais vos clés, ne les collez nulle part en ligne.
COMMENT LANCER
--------------
Dans un terminal, placez-vous dans le dossier du script et tapez :
python multi_ia.py
================================================================
"""
import os
import json
import requests # installé via : pip install requests
# ----------------------------------------------------------------
# 1) LECTURE DES CLÉS API
# ----------------------------------------------------------------
# Le script cherche un fichier "cles.txt" dans le même dossier.
# Format attendu (une ligne par IA, vous ne remplissez que celles
# que vous avez) :
#
# openai = sk-xxxxxxxxxxxxxxxxxxxx
# anthropic = sk-ant-xxxxxxxxxxxx
# google = xxxxxxxxxxxxxxxxxxxx
# xai = xxxxxxxxxxxxxxxxxxxx
#
# Les lignes vides ou commençant par # sont ignorées.
def lire_cles(chemin="cles.txt"):
cles = {}
if not os.path.exists(chemin):
print(f"\n[!] Le fichier '{chemin}' est introuvable.")
print(" Créez-le dans le même dossier, avec vos clés.")
print(" Exemple de contenu :")
print(" openai = sk-...")
print(" anthropic = sk-ant-...")
return cles
with open(chemin, "r", encoding="utf-8") as f:
for ligne in f:
ligne = ligne.strip()
if not ligne or ligne.startswith("#") or "=" not in ligne:
continue
nom, valeur = ligne.split("=", 1)
nom = nom.strip().lower()
valeur = valeur.strip()
if valeur: # on ignore les clés vides
cles[nom] = valeur
return cles
# ----------------------------------------------------------------
# 2) FONCTIONS D'APPEL — une par fournisseur
# Chacune renvoie le texte de la réponse, ou un message d'erreur.
# ----------------------------------------------------------------
def appel_openai(question, cle, modele="gpt-4o"):
"""ChatGPT (OpenAI)."""
try:
r = requests.post(
"api.openai.com/v1/chat/compl…",
headers={"Authorization": f"Bearer {cle}",
"Content-Type": "application/json"},
json={"model": modele,
"messages": [{"role": "user", "content": question}]},
timeout=120,
)
r.raise_for_status()
return r.json()["choices"][0]["message"]["content"]
except Exception as e:
return f"[Erreur OpenAI : {e}]"
def appel_anthropic(question, cle, modele="claude-opus-4-8"):
"""Claude (Anthropic)."""
try:
r = requests.post(
"api.anthropic.com/v1/message…",
headers={"x-api-key": cle,
"anthropic-version": "2023-06-01",
"Content-Type": "application/json"},
json={"model": modele,
"max_tokens": 2000,
"messages": [{"role": "user", "content": question}]},
timeout=120,
)
r.raise_for_status()
# la réponse est une liste de blocs ; on concatène le texte
blocs = r.json().get("content", [])
return "".join(b.get("text", "") for b in blocs if b.get("type") == "text")
except Exception as e:
return f"[Erreur Anthropic : {e}]"
def appel_google(question, cle, modele="gemini-1.5-pro"):
"""Gemini (Google)."""
try:
url = (f"generativelanguage.googleapi…"
f"models/{modele}:generateContent?key={cle}")
r = requests.post(
url,
headers={"Content-Type": "application/json"},
json={"contents": [{"parts": [{"text": question}]}]},
timeout=120,
)
r.raise_for_status()
return r.json()["candidates"][0]["content"]["parts"][0]["text"]
except Exception as e:
return f"[Erreur Google : {e}]"
def appel_xai(question, cle, modele="grok-2-latest"):
"""Grok (xAI). API compatible avec le format OpenAI."""
try:
r = requests.post(
"api.x.ai/v1/chat/completions",
headers={"Authorization": f"Bearer {cle}",
"Content-Type": "application/json"},
json={"model": modele,
"messages": [{"role": "user", "content": question}]},
timeout=120,
)
r.raise_for_status()
return r.json()["choices"][0]["message"]["content"]
except Exception as e:
return f"[Erreur xAI : {e}]"
# Table de correspondance : nom dans cles.txt -> (fonction, libellé affiché)
FOURNISSEURS = {
"openai": (appel_openai, "ChatGPT (OpenAI)"),
"anthropic": (appel_anthropic, "Claude (Anthropic)"),
"google": (appel_google, "Gemini (Google)"),
"xai": (appel_xai, "Grok (xAI)"),
}
# ----------------------------------------------------------------
# 3) PROGRAMME PRINCIPAL
# ----------------------------------------------------------------
def main():
print("=" * 60)
print(" MULTI-IA — poser une question à plusieurs IA")
print("=" * 60)
cles = lire_cles()
if not cles:
print("\nAucune clé trouvée. Le script s'arrête.")
return
# Quelles IA sont disponibles ?
dispo = [nom for nom in FOURNISSEURS if nom in cles]
print("\nIA disponibles avec vos clés :")
for nom in dispo:
print(f" - {FOURNISSEURS[nom][1]}")
# Saisie de la question (sur plusieurs lignes ; ligne vide pour finir)
print("\nTapez (ou collez) votre question.")
print("Quand vous avez terminé, appuyez deux fois sur Entrée :\n")
lignes = []
while True:
try:
ligne = input()
except EOFError:
break
if ligne == "" and lignes: # ligne vide après du texte = fin
break
if ligne == "" and not lignes: # ligne vide au tout début = on ignore
continue
lignes.append(ligne)
question = "\n".join(lignes).strip()
if not question:
print("Aucune question saisie. Arrêt.")
return
# Interrogation de chaque IA
resultats = {}
for nom in dispo:
fonction, libelle = FOURNISSEURS[nom]
print(f"\n→ Interrogation de {libelle} ...")
reponse = fonction(question, cles[nom])
resultats[libelle] = reponse
print(" ✓ réponse reçue")
# Écriture du fichier de sortie
sortie = "reponses.txt"
with open(sortie, "w", encoding="utf-8") as f:
f.write("QUESTION POSÉE :\n")
f.write(question "\n\n")
f.write("=" * 60 "\n\n")
for libelle, reponse in resultats.items():
f.write(f"### RÉPONSE DE {libelle}\n\n")
f.write(reponse.strip() "\n\n")
f.write("-" * 60 "\n\n")
print(f"\n✓ Terminé. Toutes les réponses sont dans : {sortie}")
print(" Ouvrez ce fichier, ou donnez-le à Claude pour la synthèse.")
if __name__ == "__main__":
main()
1
20

it's like the parsimonious alternatives are either reality is infinitely dense and encoding her values requires infinite precision like the reals or it has some grid and you don't need the rationals with arbitrary precision. You basically just need the naturals.
1
18

Une explication bien faite du fonctionnement interne des LLMs : tokens, embeddings, positional encoding, attention, feed-forward…
0xkato.xyz/how-llms-actually…

5
240
zombie.blueberry.muffin retweeted

9h
if you are looking for resources to learn about rotary positional encoding and YaRN
here are some good ones
- outcomeschool.com/blog/math-…


Jun 9

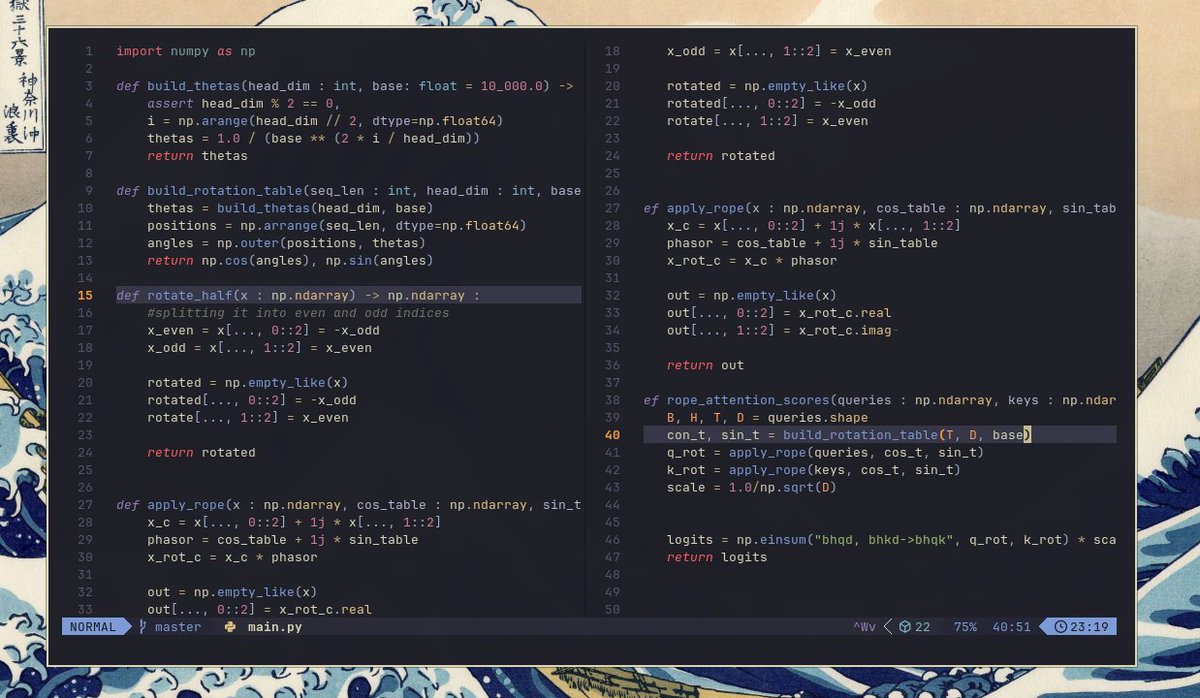
Wrote some Rotary positional encoding stuff ... and tested it with some tests
> norms are preserved
> batched shapes work
> shifting both token positions by the same offset δ doesn't change their dot product
looking forward to spend enough time to write a blog on this
1
93
3,401

Aiwa GBTUR-120BKMKII: Tocadiscos Bluetooth con Encoding, 3 velocidades, Radio FM, USB y SD. Conversión directa de Vinilo a Digital. Color: Negro
📉 Baja de 171,45 a 117,12€
💶 Ahorro: 54,33€ (32%)
🔗 amzlink.to/az0SFjq72V8k5
undefined

37

I'm going next and still believing in game 5. My sleep schedule is shot, my brain is encoding, and if we lose, at least it's been a fun night. T1 vs GenG always are worth it. #T1WIN
1
79

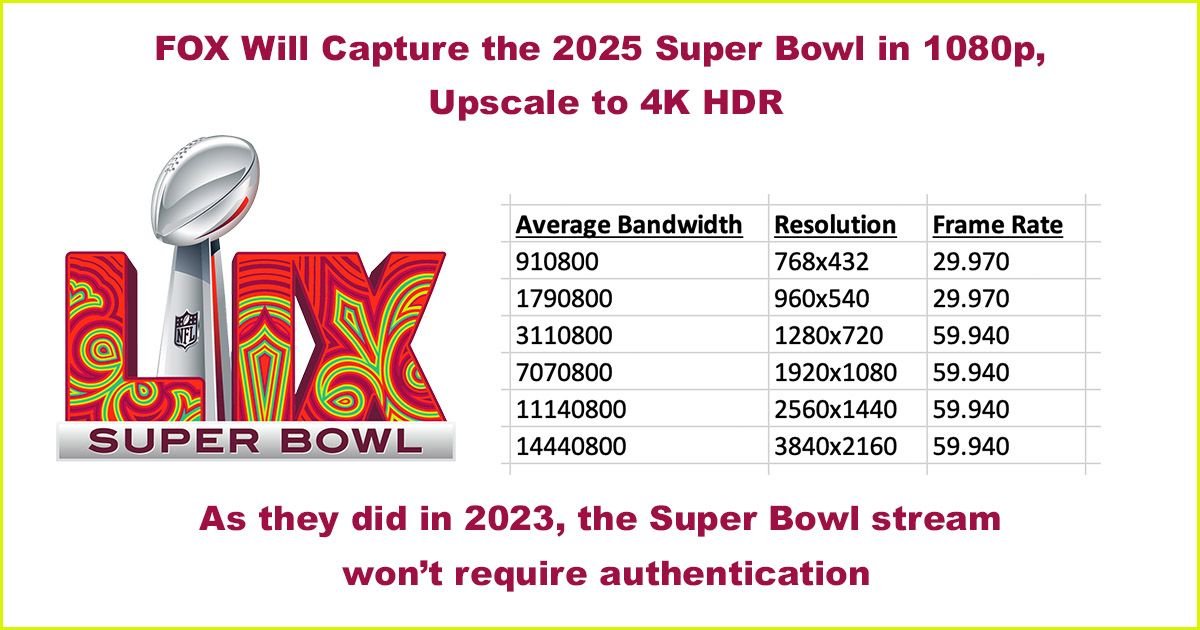
To understand ABR, it may be helpful to explain the concept of an 'encoding ladder'.
15 Jan 2025

Encoding ladder for the 2025 Super Bowl LIX. The event will be captured and produced by Fox Sports in 1080p [HDR] with 59.94 frame rate and transmitted in 4K HDR. Max bitrate will be 15 Mbps.
linkedin.com/feed/update/urn… via @DanRayburn
28

This would be Shift JIS, Japan's alternative to Unicode. You'll need a third party extension since Chromium dropped character encoding support. Not sure if Safari lets you do it natively.
68
OutfitML retweeted

Almost every modern LLM uses the same positional encoding. LLaMA. Mistral. Gemma. Phi. It is called RoPE, and the design choice behind it is more elegant than most explanations let on. A thread on how it works, from first principles 🧵
1
2
5
50
OutfitML retweeted
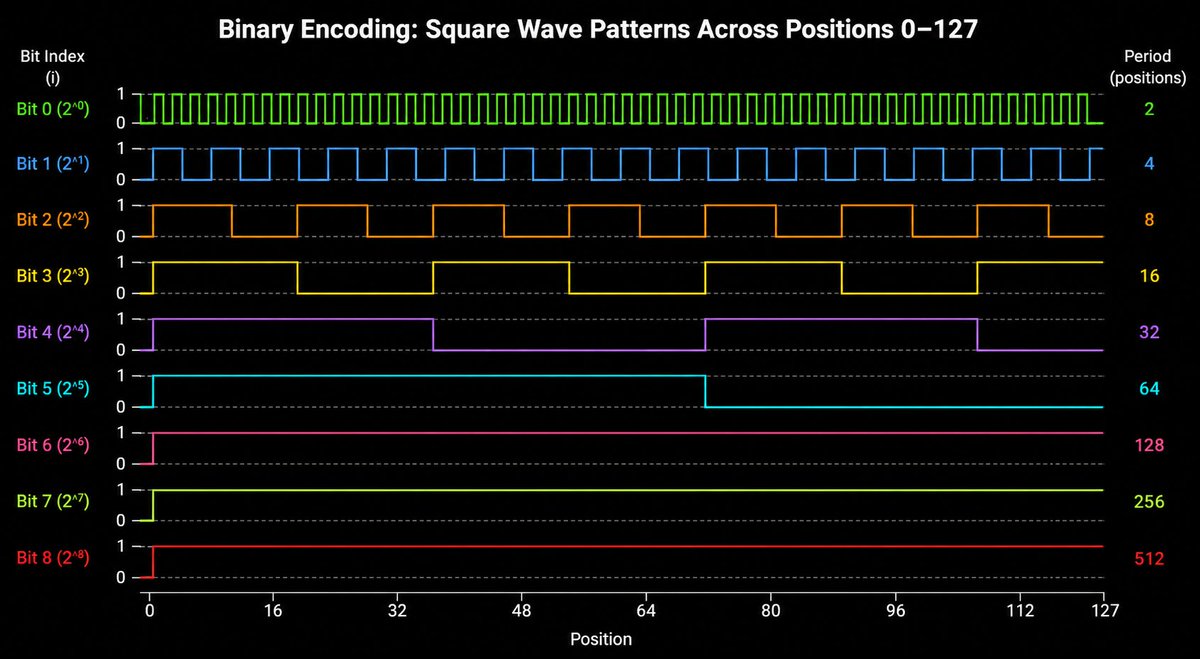
Binary encoding gets closer.
Each bit oscillates at a different frequency. Low bits flip fast. High
bits flip slow.
This multi frequency structure is the right idea.
But the jumps between positions are discontinuous. Neural networks need
smooth inputs.
1
2
4
6
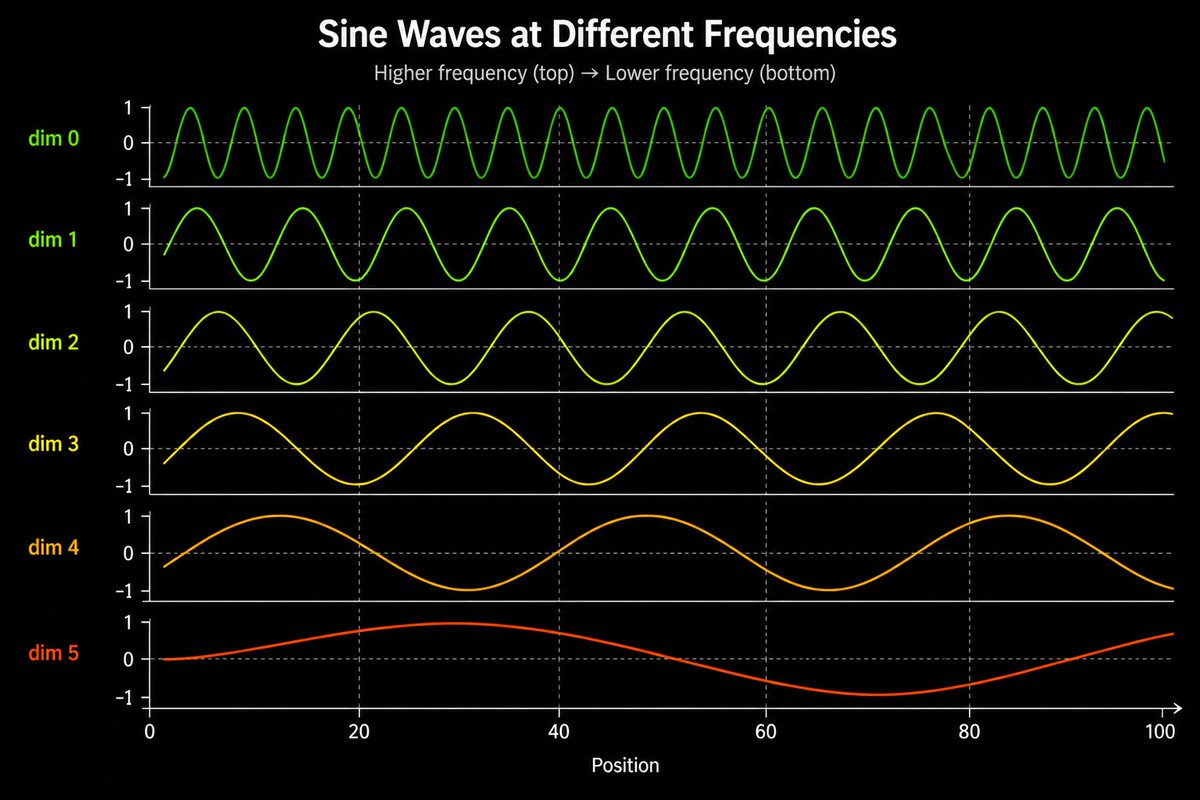
OutfitML retweeted
Sinusoidal encoding fixes the smoothness.
Replace square waves with sine and cosine waves at multiple frequencies.
Same multi frequency idea. Now smooth.
This is the encoding from the original Transformer paper.
1
2
4
6
But sinusoidal encoding has a hidden problem.
It is ADDED to the embedding. Compute Q · K for attention, you get 4 terms:
1. Pure semantic
2. Semantic × position (cross term)
3. Position × semantic (cross term)
4. Pure positional
Relative position lives only term 4
1
4
11