
May 22
Back from a few days in San Jose for Google Marketing Live. Got to catch up with a few great folks, interesting keynotes, but particularly interesting were the Q&As with search & AI search leads. If I break NDA I assume they’ll send a gaggle of Googlebots after me, but suffice it to say I think ads are heading in a better direction than they have for many, many years in the past. I truly think tech like AI Brief (and whatever iterations take place in the future) is pivotal for @GoogleAds.
I’m a pragmatic marketer. I help clients make money. You’ll probably see folks getting upset about AI Mode, dying keywords, etc… but letting emotions get in the way is the wrong slant. As long as we still have fairly granular reporting (as we’ve seen improve with PMax) I’m positive things are going to be just fine.
3
168

Feb 18
"Can you look at this? The googlebots aren't indexing it and it looks fucked up on my machine, but everybody can see it"

1
6
178

Feb 4
ICYMI: Googlebots crawling limit is 15MB but for other file types it is 2MB and for PDFs it is 64MB seroundtable.com/googlebot-f…
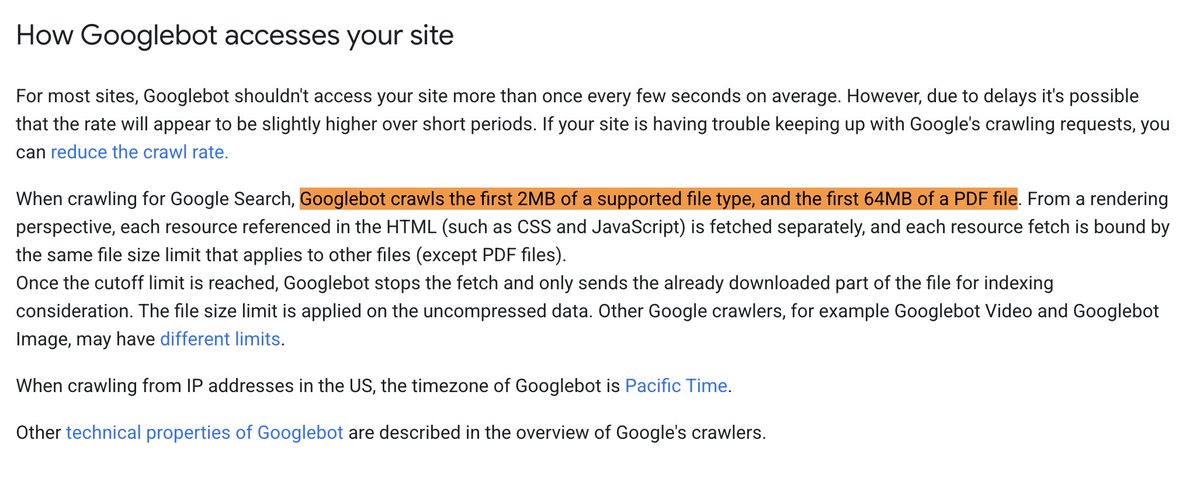
2
2
8
1,051
Feb 4
Googlebots crawling limit is 15MB but for other file types it is 2MB and for PDFs it is 64MB seroundtable.com/googlebot-f…
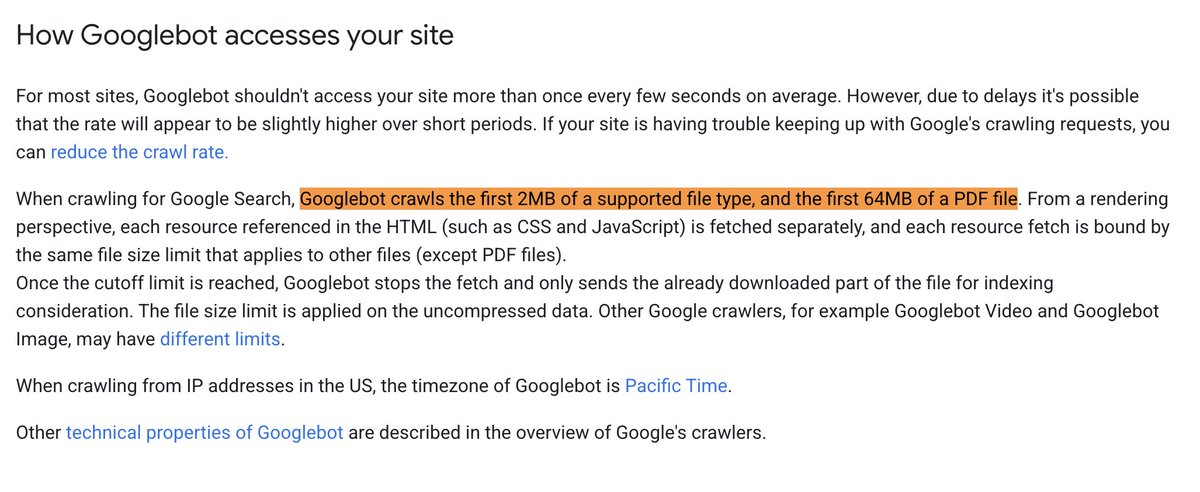
2
2
4
852

Googlebots crawling limit is 15MB but for other file types it is 2MB and for PDFs it is 64MB seroundtable.com/googlebot-f…
4
686
Feb 4
Google clarifies Googlebots crawling limit of 15MB (old) but what is new is 2MB for other file types and 64MB for PDF documents seroundtable.com/googlebot-f…

4
17
49
6,406

Jan 29
Day 11/100: Fixing Your Website. 🛠️
Utility Pages.
A common SEO mistake we see is allowing Google to index everything, including administrative pages like "Checkout", "My Account", or "Privacy Policy".
While these pages are essential for users, they are useless for search results. Indexing them wastes your site's Crawl Budget (the attention Google gives your site).
Our Optimization Strategy: We recommend "noindexing" these utility pages to force Google to focus on your content and product pages.
How to execute this with All in One SEO (@AIOSEOPACK): Navigate to the Advanced tab in the AIOSEO.com settings for any specific page. By disabling the default settings and selecting "noindex" and "nofollow", you tell Googlebots to skip this page entirely.
The Result: Google spends its resources crawling your money pages, which can lead to a meaningful lift in overall traffic.
Follow @WPBeginner for the next tip! 🚀
1
3
410

Jan 26
セキュリティプラグイン「All-In-One Security」の影響だったことが判明しました。
この「ファイアウォール>オンラインのボットの設定」で、「偽の Googlebots をブロック」にチェックが入っていたことで「"偽じゃない"Googlebots」がブロックされていたというオチでした。
AIOS MAJI FUZAKENNA
6
109

Jan 6
People literally believe Googlebots navigate a site and get lost?
Q: Do breadcrumbs help SEO?
@RyanJones - this is actually where most people are at - looking for unicorns in SEO - be it "EEAT" or "Vector" or "entity"
Teaching PageRank is hard enough work :D

2
3
691

10 Oct 2025
Build for your users, customers and HUMANS first that will eventually please Google
Stop putting Googlebots before your users.
3
185
20 Sep 2025
Here's the best way I can explain the problem with the XML sitemap as an "SEO Basic 101"
Sitemaps are a control list, not a to-do list.
There are two types of Googlebots: A listener bot and a crawler-bot
A listener bot is posted to sites with authority - like CNN, TechCrunch, The BeeB might have more than one.
This is also why you want a news.xml feed if you're trying to get into News/Discover.
Many sites with high topical authority dont have a Feedbot.

1
6
187

10 Sep 2025
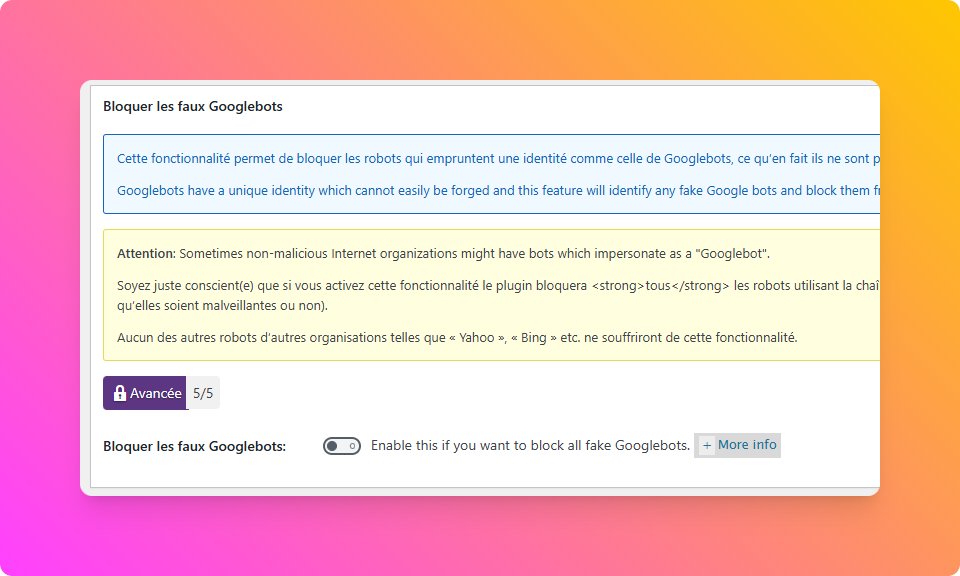
🔍 Verdict : après plusieurs essais, c’est AIOS (All-In-One Security) qui bloquait Googlebot sur les .xml.
➡️ Dès que je l’ai désactivé, Googlebot recevait à nouveau du XML propre ✅
✅ Solution :
J'ai désactivé l'option de blocage des faux Googlebots qui bloquait le vrai Googlebot....
Dans Pare-feu ➡️ Bots internet ➡️ Bloquer les faux Googlebots ➡️ Disable
En plus tant qu'on y est :
➡️ Exclure /sitemap*.xml du cache / minify
➡️ Garder une Cache Rule Cloudflare (Bypass) pour éviter les corruptions
1
2
165

6 Aug 2025
A critical analysis of server log data reveals that the Google Indexing API is no longer functioning as a reliable method for triggering crawls for general web content.
While the API was once an effective, near-instantaneous way to request indexing, its behavior has fundamentally changed in stages, culminating in a complete disconnect from Google's crawling system for most websites.
Carolyn Holzman's forensic analysis comparing server log activity before and after key dates illustrates this shift.
Prior to early December 2022, a request submitted through the Indexing API would act as a priority alert to Google's crawlers.
This would predictably trigger a sequence of bot visits, including a non-Chrome `Fetcher` bot to check the `robots.txt` file, followed by a full set of mobile and desktop Googlebots to process the page, resulting in rapid indexing.
However, beginning around December 5, 2022, the system's effectiveness was dramatically reduced.
An API call would only yield a single mobile Googlebot visit, a significant downgrade from the previous comprehensive crawl.
The final change occurred in late 2023. Now, the connection between the API and the crawling system appears to be severed entirely.
This can be confirmed through a definitive test.
When a URL is submitted, an "event" is successfully logged in the corresponding Google Cloud Service account dashboard.
This gives the appearance that the request has been received and is being processed.
However, a review of the server logs for the target domain shows a complete absence of any corresponding crawl visit from Googlebot.
The front-end system registers the ping, but the back-end crawling infrastructure is no longer dispatched.
This creates a deceptive situation where the system looks like it's working from the user's dashboard, but no actual crawling or indexing action is initiated.
The only way to verify this disconnect is by owning the site and cross-referencing the Google Cloud dashboard with server logs.
Therefore, while the Indexing API may still function for its stated purposes of job postings and live events, for all other general web content, it no longer sends a bot and should be considered effectively non-operational for triggering new crawls.
3
2
10
1,087

Hace unos días vi una charla que me encantó.
Era @karpathy ex Director de IA en Tesla y uno de los pensadores más influyentes en el mundo de la inteligencia artificial.
Hablaba en el auditorio de Y Combinator frente a cientos de fundadores y estudiantes.
Con su estilo casi filosófico, dijo algo que se me llamó mucho la atención:
👉 “𝘓𝘰𝘴 𝘓𝘓𝘔𝘴 𝘯𝘰 𝘴𝘰𝘯 𝘴𝘰𝘭𝘰 𝘩𝘦𝘳𝘳𝘢𝘮𝘪𝘦𝘯𝘵𝘢𝘴. 𝘚𝘰𝘯 𝘯𝘶𝘦𝘷𝘰𝘴 𝘴𝘪𝘴𝘵𝘦𝘮𝘢𝘴 𝘰𝘱𝘦𝘳𝘢𝘵𝘪𝘷𝘰𝘴. 𝘠 𝘯𝘦𝘤𝘦𝘴𝘪𝘵𝘢𝘯 𝘯𝘶𝘦𝘷𝘢𝘴 𝘧𝘰𝘳𝘮𝘢𝘴 𝘥𝘦 𝘪𝘯𝘵𝘦𝘳𝘢𝘤𝘵𝘶𝘢𝘳 𝘤𝘰𝘯 𝘦𝘭 𝘮𝘶𝘯𝘥𝘰.”
Y ahí entendí algo.
Así como hace años nos obsesionamos con optimizar sitios web para Google usando robots.txt y sitemap.xml, ahora estamos entrando a una era donde necesitamos hablarle no solo a los googlebots… sino también a los nuevos LLMs.
Tu producto debe estar preparado para que un agente LLM pueda:
•Leer su estructura interna, documentación y lógica.
•Navegar tu información como si fuera una API invisible.
•Ejecutar acciones no solo por clicks, sino a través de comandos o interfaces que puedan ser interpretadas por texto.
En @GuruHotelHQ llevamos años construyendo sitios web con obsesión por el SEO.
Sabemos cómo ganarle a los sitios piratas que se hacen pasar por hoteles reales.
Sabemos cómo posicionar un sitio oficial desde cero y en unos pocos meses.
Y lo hacemos todos los días.
Pero ahora, el SEO está cambiando.
Las reservas ya no llegan solo por clics.
También llegarán por prompts.
Cuando un viajero le pregunte a un asistente de IA:
“¿Dónde me puedo quedar en Holbox, frente a la playa y con desayuno incluido?”
Queremos que la respuesta no sea Booking.
Queremos que sea el sitio oficial del hotel.
Hecho por nosotros.
Optimizado por nosotros.
Y ahora, entendible por un LLM.
Por eso estamos integrando algo nuevo: llms.txt
Un archivo que, igual que robots.txt le hablaba a Google, ahora le habla a ChatGPT, Claude, Gemini y muchos más.
Le dice qué es este sitio, qué representa, y por qué debería recomendarlo.
Con la experiencia de años haciendo SEO (liderada por @stivenmart) y una mentalidad 100% de producto,
estamos construyendo la infraestructura para la nueva era de reservas directas conversacionales.
Si quieres aprender más de los LLMs.txt date una vuelta por llmstxt.org
Y quieres compartir tus hallazgos, compartamos notas, he identificado muchos directorios, sitios que ya están implementando, startups que se están construyendo entorno a esto.
Ya puedes ver arriba el nuestro:
guruhotel.com/llms.txt
3
6
313

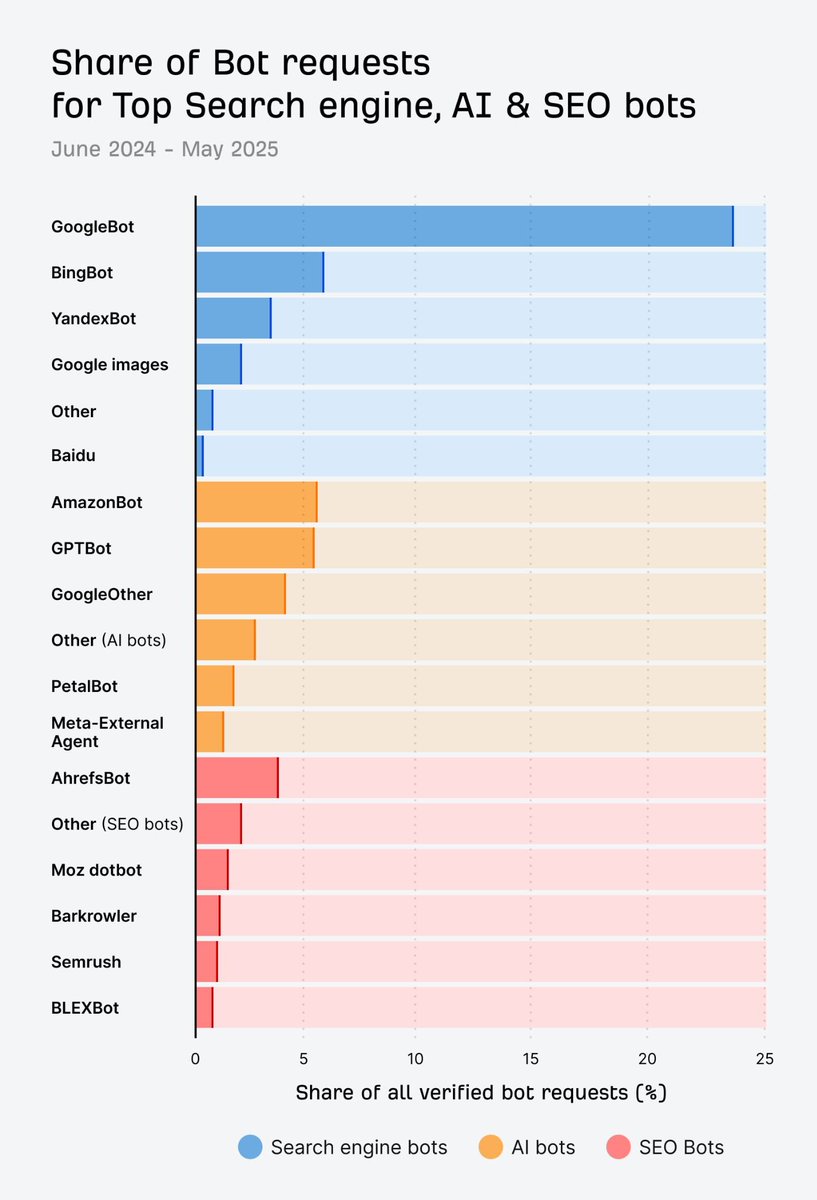
18 Jun 2025
Google bots crawl the web far more than any other company. Googlebot, Google Images, GoogleOther (their AI bot), and a ton more Googlebots. Insane.
ahrefs.com/blog/search-engin…
2
7
804


26 Apr 2025
BS, over 10,000 species, only 2700 have been named and classified / studied. Want to get an animal named after you ? Your best bet is finding a new species of spider in Australia.
Googlebots are so dumb.

Do you know:
-Australia Has Over 2,400 Species of Spiders 🌏
-The Sydney Funnel-Web Spider Is One of the Most Venomous Spiders ☠️

1
26

14 Jan 2025
What is Crawling?
Crawling is performed by Google's automated programs known as Googlebots or spiders. These bots systematically explore the internet by following links from one page to another, gathering data about the content, structure, and updates of web pages
6

1 Jan 2025
I bet the water cooler chat would be more interesting with an AI robot dog than with most Googlebots.
1
220

16 Dec 2024
The Crawl Stats reporting is great, but server logs can be super powerful -> New from Google: 3 Tips for Crawling Errors
*Make sure Googlebot can access your pages (and your content).
*Review the Crawl Stats reporting for various errors.
*Analyze log files.
*Tip: Not all Googlebots you see are from Google...
youtube.com/watch?v=e0wnYVsI…



1
1
4
1,621